Meta-learning of textual representations
Pith reviewed 2026-05-25 19:23 UTC · model grok-4.3
The pith
Meta-learning methodology automatically selects effective textual representations for text classification tasks from raw text.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
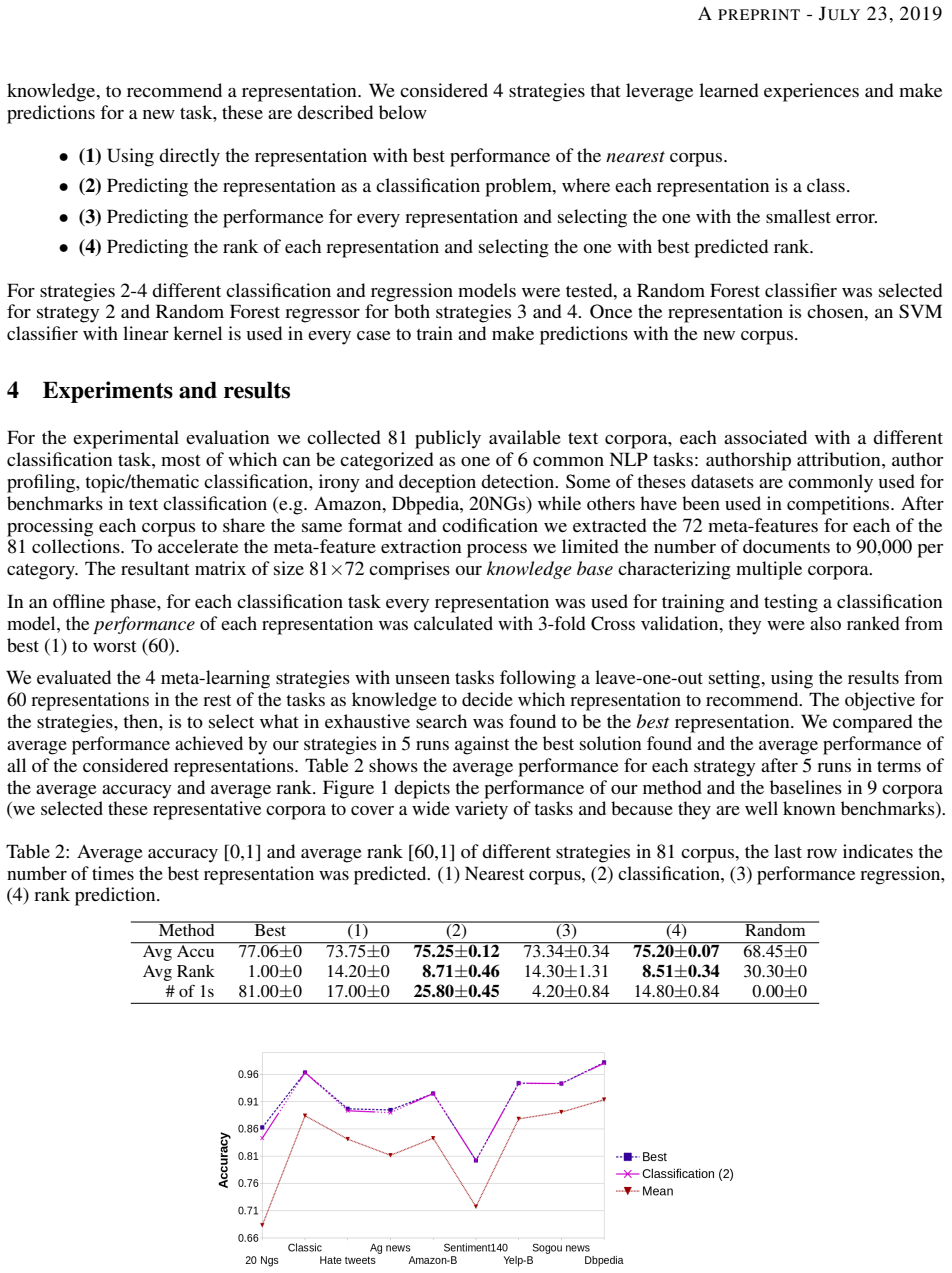
The authors describe a meta-learning methodology for automatically obtaining a representation for text mining tasks starting from raw text. Experiments considering 60 different textual representations and more than 80 text mining datasets show the proposed methodology is a promising solution to obtain highly effective off-the-shelf text classification pipelines.
What carries the argument
The meta-learning methodology that learns to map raw text inputs to suitable representations drawn from a fixed collection of 60 options, using performance data from 80 datasets.
If this is right
- Text classification pipelines can be designed automatically in a manner similar to tabular data methods.
- Non-experts gain access to effective text classifiers without needing to select representations manually.
- Representation selection becomes data-driven rather than reliant on domain expertise for each new task.
- The same meta-learning process could in principle support other text mining problems beyond classification.
Where Pith is reading between the lines
- The method might lower barriers for applying text mining in domains where labeled data exists but representation knowledge is scarce.
- If the selection rule generalizes, it could serve as a building block for broader AutoML systems that handle mixed data types.
- Direct comparison on fresh datasets would clarify whether the learned selection rule transfers beyond the training collection.
Load-bearing premise
Performance patterns observed on the fixed set of 60 representations and 80 datasets will produce effective representations on new, previously unseen text mining tasks.
What would settle it
A new text dataset outside the original collection where the meta-learned representation choice yields classification accuracy no better than a standard default representation.
Figures

read the original abstract
Recent progress in AutoML has lead to state-of-the-art methods (e.g., AutoSKLearn) that can be readily used by non-experts to approach any supervised learning problem. Whereas these methods are quite effective, they are still limited in the sense that they work for tabular (matrix formatted) data only. This paper describes one step forward in trying to automate the design of supervised learning methods in the context of text mining. We introduce a meta learning methodology for automatically obtaining a representation for text mining tasks starting from raw text. We report experiments considering 60 different textual representations and more than 80 text mining datasets associated to a wide variety of tasks. Experimental results show the proposed methodology is a promising solution to obtain highly effective off the shell text classification pipelines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a meta-learning methodology to automatically derive effective textual representations for supervised text classification tasks starting from raw text. It evaluates the approach using 60 different textual representations across more than 80 text mining datasets spanning varied tasks, and concludes that the method yields promising off-the-shelf text classification pipelines that extend AutoML beyond tabular data.
Significance. If the meta-learner generalizes reliably, the work would meaningfully extend AutoML techniques to text domains by reducing the need for manual representation engineering. The scale of the evaluation (60 representations, 80+ datasets) provides a broad empirical base, but the absence of out-of-distribution testing limits the strength of the 'highly effective off-the-shelf' claim.
major comments (2)
- [Experiments / Results] The central claim that the methodology delivers 'highly effective off-the-shelf text classification pipelines' for arbitrary new tasks rests on performance within the fixed collection of 80 datasets. No experiments test transfer to held-out tasks or datasets differing in domain, label distribution, or linguistic properties (e.g., via a meta-training / meta-test split or external benchmarks). This directly undermines the generalization required for the conclusion.
- [Methodology] The meta-learning procedure for selecting or combining representations is described at a high level in the abstract and introduction but lacks sufficient detail on the meta-learner architecture, feature construction for meta-features, or training objective to allow reproduction or assessment of whether the selection rules are robust.
minor comments (2)
- [Abstract] Abstract contains two typos: 'lead' should be 'led' and 'shell' should be 'shelf'.
- [Experiments] The paper would benefit from explicit comparison against strong non-meta baselines (e.g., standard TF-IDF + SVM or modern sentence embeddings) on the same 80 datasets to quantify the meta-learning gain.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Experiments / Results] The central claim that the methodology delivers 'highly effective off-the-shelf text classification pipelines' for arbitrary new tasks rests on performance within the fixed collection of 80 datasets. No experiments test transfer to held-out tasks or datasets differing in domain, label distribution, or linguistic properties (e.g., via a meta-training / meta-test split or external benchmarks). This directly undermines the generalization required for the conclusion.
Authors: We agree that the evaluation is performed on a fixed collection of over 80 datasets without explicit meta-train/meta-test splits or external OOD benchmarks. While the breadth of tasks and domains in the collection offers empirical support, this does limit the strength of claims regarding arbitrary new tasks. In the revision we will moderate the abstract and conclusion wording and add an explicit discussion of this limitation. revision: partial
-
Referee: [Methodology] The meta-learning procedure for selecting or combining representations is described at a high level in the abstract and introduction but lacks sufficient detail on the meta-learner architecture, feature construction for meta-features, or training objective to allow reproduction or assessment of whether the selection rules are robust.
Authors: We agree that additional methodological detail is required for reproducibility. The full paper contains more information than the abstract, but we will expand the methodology section in the revised manuscript with precise descriptions of the meta-learner architecture, meta-feature construction, and training objective. revision: yes
Circularity Check
No derivation chain or first-principles claims; purely empirical evaluation on fixed collection
full rationale
The paper introduces a meta-learning methodology and evaluates it experimentally across 60 representations and 80 datasets, reporting that results show it is a promising solution. No equations, derivations, uniqueness theorems, or predictions from first principles appear in the provided text. The central claim rests on observed performance within the given collection rather than any reduction of a derived quantity to its inputs by construction. This is a standard empirical ML paper with no load-bearing mathematical steps that could exhibit the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Particle swarm model selection
Hugo Jair Escalante, Manuel Montes, and Luis Enrique Sucar. Particle swarm model selection. J. Mach. Learn. Res., 10:405–440, June 2009
work page 2009
-
[2]
Chris Thornton, Frank Hutter, Holger H. Hoos, and Kevin Leyton-Brown. Auto-weka: Combined selection and hyperparameter optimization of classification algorithms. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’13, pages 847–855, New York, NY , USA, 2013. ACM
work page 2013
-
[3]
Efficient and robust automated machine learning
Matthias Feurer, Aaron Klein, Katharina Eggensperger, Jost Springenberg, Manuel Blum, and Frank Hutter. Efficient and robust automated machine learning. InAdvances in neural information processing systems, pages 2962–2970, 2015
work page 2015
-
[4]
A meta-learning approach for text categorization
Wai Lam and Kwok-Yin Lai. A meta-learning approach for text categorization. In Proceedings of the 24th annual international ACM SIGIR conference on Research and development in information retrieval , pages 303–309. ACM, 2001
work page 2001
-
[5]
Bayesian optimization of text representations
Dani Yogatama, Lingpeng Kong, and Noah A Smith. Bayesian optimization of text representations. InProceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, pages 2100–2105, 2015
work page 2015
-
[6]
Practical bayesian optimization of machine learning algorithms
Jasper Snoek, Hugo Larochelle, and Ryan P Adams. Practical bayesian optimization of machine learning algorithms. In Advances in neural information processing systems, pages 2951–2959, 2012
work page 2012
-
[7]
Evolutionary learning of meta-rules for text classification
Juan Carlos Gomez, Stijn Hoskens, and Marie-Francine Moens. Evolutionary learning of meta-rules for text classification. In Proceedings of the Genetic and Evolutionary Computation Conference Companion , pages 131–132. ACM, 2017
work page 2017
-
[8]
Workflow recommendation for text classification with active testing method
Maria Joao Ferreira and Pavel Brazdil. Workflow recommendation for text classification with active testing method. In Workshop AutoML 2018@ ICML/IJCAI-ECAI, 2018
work page 2018
-
[9]
On clustering and evaluation of narrow domain short-text corpora
David Pinto. On clustering and evaluation of narrow domain short-text corpora. PhD. UPV, 2008
work page 2008
-
[10]
Hamparsum Bozdogan. Model selection and akaike’s information criterion (aic): The general theory and its analytical extensions. Psychometrika, 52(3):345–370, 1987
work page 1987
-
[11]
Gradient-based optimization of hyperparameters
Yoshua Bengio. Gradient-based optimization of hyperparameters. Neural computation, 12(8):1889–1900, 2000. 6 A PREPRINT - JULY 23, 2019
work page 1900
-
[12]
Algorithms for hyper-parameter optimization
James S Bergstra, Rémi Bardenet, Yoshua Bengio, and Balázs Kégl. Algorithms for hyper-parameter optimization. In Advances in neural information processing systems, pages 2546–2554, 2011
work page 2011
-
[13]
A perspective view and survey of meta-learning
Ricardo Vilalta and Youssef Drissi. A perspective view and survey of meta-learning. Artificial intelligence review, 18(2):77–95, 2002
work page 2002
-
[14]
Joaquin Vanschoren. Meta-learning. In Frank Hutter, Lars Kotthoff, and Joaquin Vanschoren, editors, Auto- matic Machine Learning: Methods, Systems, Challenges , pages 39–68. Springer, 2018. In press, available at http://automl.org/book
work page 2018
-
[15]
Initializing bayesian hyperparameter optimization via meta-learning
Matthias Feurer, Jost Tobias Springenberg, and Frank Hutter. Initializing bayesian hyperparameter optimization via meta-learning. In Twenty-Ninth AAAI Conference on Artificial Intelligence, 2015
work page 2015
-
[16]
Neural Architecture Search: A Survey
Thomas Elsken, Jan Hendrik Metzen, and Frank Hutter. Neural architecture search: A survey. arXiv preprint arXiv:1808.05377, 2018. 7
work page internal anchor Pith review Pith/arXiv arXiv 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.