An enhanced KNN-based twin support vector machine with stable learning rules
Pith reviewed 2026-05-25 18:19 UTC · model grok-4.3
The pith
RKNN-TSVM improves KNN-based twin support vector machines by weighting samples according to neighbor distances, adding stabilizer terms, and embedding LDMDBA to cut overfitting and computation time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that distance-based sample weighting, added stabilizer terms in the objective functions, and the embedded LDMDBA algorithm together produce an RKNN-TSVM classifier that attains higher accuracy and substantially lower running time than prior KNN-based twin support vector machines while preserving their core structure.
What carries the argument
The RKNN-TSVM model, formed by augmenting KNN-TSVM with distance-derived sample weights, stabilizer terms in both objective functions, and the LDMDBA procedure for efficient nearest-neighbor location.
If this is right
- Distance weighting reduces the influence of noise and outliers on the learned model.
- Stabilizer terms produce stable learning rules that limit overfitting compared with earlier KNN-TSVM variants.
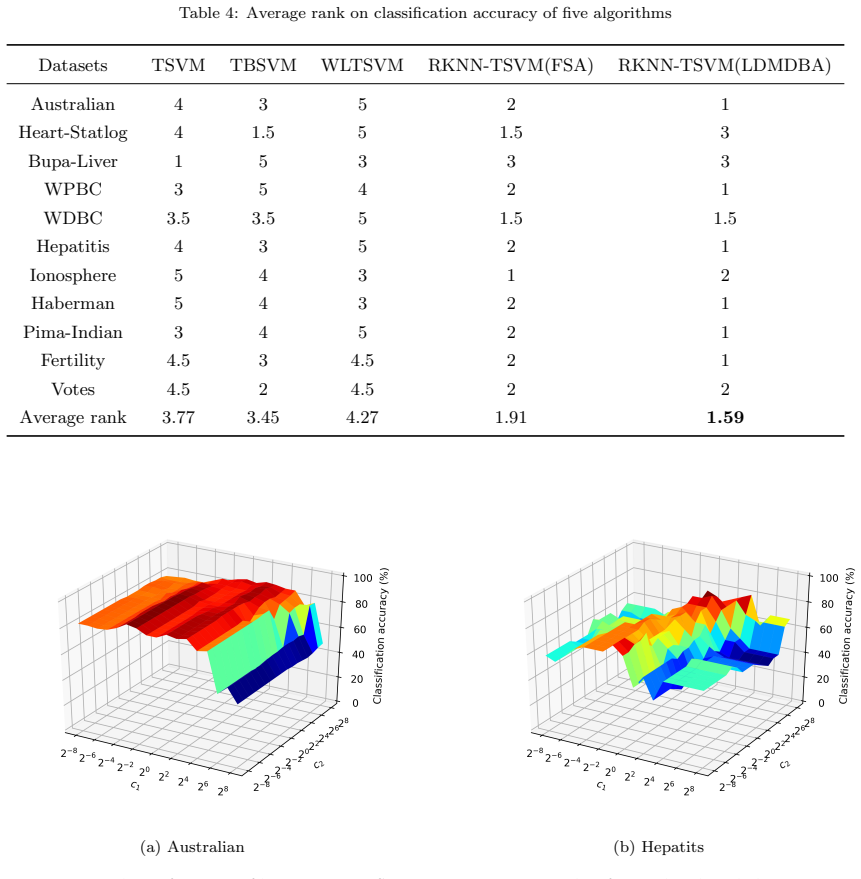
- Embedding LDMDBA lowers the cost of KNN searches and yields observed speedups up to 14 times.
- The resulting classifier shows improved accuracy on both synthetic and standard benchmark data sets.
Where Pith is reading between the lines
- The same stabilizer construction could be tested on other twin-SVM extensions that currently suffer from instability.
- If LDMDBA truly preserves classification-relevant KNN properties, the same embedding might accelerate pure KNN or other neighbor-based learners.
- The noise-reduction effect of distance weighting suggests the method may be especially useful in domains where label errors are common but labeled data remain limited.
Load-bearing premise
The distance-based weighting scheme and stabilizer terms improve generalization on unseen data without introducing new biases or demanding hyper-parameter choices that themselves overfit.
What would settle it
A controlled test on a dataset with known label noise where RKNN-TSVM fails to exceed the accuracy of plain TSVM or standard KNN-TSVM, or where measured runtimes show no speedup once LDMDBA overhead is included.
Figures







read the original abstract
Among the extensions of twin support vector machine (TSVM), some scholars have utilized K-nearest neighbor (KNN) graph to enhance TSVM's classification accuracy. However, these KNN-based TSVM classifiers have two major issues such as high computational cost and overfitting. In order to address these issues, this paper presents an enhanced regularized K-nearest neighbor based twin support vector machine (RKNN-TSVM). It has three additional advantages: (1) Weight is given to each sample by considering the distance from its nearest neighbors. This further reduces the effect of noise and outliers on the output model. (2) An extra stabilizer term was added to each objective function. As a result, the learning rules of the proposed method are stable. (3) To reduce the computational cost of finding KNNs for all the samples, location difference of multiple distances based k-nearest neighbors algorithm (LDMDBA) was embedded into the learning process of the proposed method. The extensive experimental results on several synthetic and benchmark datasets show the effectiveness of our proposed RKNN-TSVM in both classification accuracy and computational time. Moreover, the largest speedup in the proposed method reaches to 14 times.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an enhanced regularized K-nearest neighbor based twin support vector machine (RKNN-TSVM) to address high computational cost and overfitting in prior KNN-based TSVM extensions. It introduces three modifications: distance-based weighting of samples to reduce noise/outlier effects, an extra stabilizer term in each objective function to ensure stable learning rules, and embedding of the location difference of multiple distances based k-nearest neighbors algorithm (LDMDBA) to lower KNN computation cost. The paper claims that extensive experiments on synthetic and benchmark datasets demonstrate superior classification accuracy and computational time, with the largest speedup reaching 14 times.
Significance. If the empirical claims are substantiated with rigorous controls, the work could provide a practically useful refinement to TSVM variants for noisy data settings by combining regularization, weighting, and approximate nearest-neighbor search, potentially improving both generalization and scalability over earlier KNN-TSVM methods.
major comments (3)
- [Abstract] Abstract: the central performance claims (superior accuracy and up to 14x speedup) are asserted without any information on the baselines compared against, the cross-validation protocol, number of runs, or statistical significance testing, leaving the experimental support for the method's effectiveness unassessable from the provided description.
- [Abstract] Abstract: it is not stated whether the reported computational speedups include the overhead of the distance-weighting scheme and LDMDBA component; if these costs are omitted, the net efficiency advantage cannot be evaluated.
- [Abstract] Abstract: the stabilizer term and weighting scheme are introduced specifically to remedy the identified instability and noise sensitivity, yet no ablation results (performance with/without each term) or held-out hyperparameter selection protocol are referenced, creating a risk that reported gains are circular with the fitting procedure rather than generalizable improvements.
Simulated Author's Rebuttal
Thank you for the constructive feedback on the abstract. We will revise the abstract to provide additional context on the experimental evaluation while preserving the manuscript's focus.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claims (superior accuracy and up to 14x speedup) are asserted without any information on the baselines compared against, the cross-validation protocol, number of runs, or statistical significance testing, leaving the experimental support for the method's effectiveness unassessable from the provided description.
Authors: We agree that the abstract would benefit from additional context. The experimental section of the manuscript describes the baselines, cross-validation protocol, number of runs, and statistical significance testing. We will revise the abstract to include a brief summary of these elements. revision: yes
-
Referee: [Abstract] Abstract: it is not stated whether the reported computational speedups include the overhead of the distance-weighting scheme and LDMDBA component; if these costs are omitted, the net efficiency advantage cannot be evaluated.
Authors: The reported speedups reflect the net computational cost of the full proposed method, including the distance-weighting scheme and LDMDBA. We will add a clarifying statement to the abstract. revision: yes
-
Referee: [Abstract] Abstract: the stabilizer term and weighting scheme are introduced specifically to remedy the identified instability and noise sensitivity, yet no ablation results (performance with/without each term) or held-out hyperparameter selection protocol are referenced, creating a risk that reported gains are circular with the fitting procedure rather than generalizable improvements.
Authors: The hyperparameter selection protocol is described in the experimental section. We will add a reference to this protocol in the abstract. The current manuscript does not include explicit ablation studies isolating the stabilizer and weighting terms; performance is shown via comparisons to prior methods. We can add ablations if required. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper proposes three explicit algorithmic additions (distance-based sample weighting, stabilizer terms in the objective, and LDMDBA embedding) to address stated problems of prior KNN-TSVM variants. These are presented as constructive modifications whose value is assessed via external experiments on synthetic and benchmark datasets, with reported accuracy and speedup metrics. No equation or derivation step is shown to reduce to its own inputs by construction, no fitted parameter is relabeled as a prediction, and no load-bearing premise rests solely on self-citation. The argument is self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard convex quadratic programming assumptions underlying twin SVM formulations remain valid after the added stabilizer and weighting terms.
Reference graph
Works this paper leans on
- [1]
-
[2]
V. N. Vapnik, An overview of statistical learning theory, IEEE transactions on neural networks 10 (5) (1999) 988–999
work page 1999
-
[3]
J. A. Nasiri, M. Naghibzadeh, H. S. Yazdi, B. Naghibzadeh, Ecg arrhythmia classification with support vector machines and genetic algorithm, in: Computer Modeling and Simulation, 2009. EMS’09. Third UKSim European Symposium on, IEEE, 2009, pp. 187–192
work page 2009
-
[4]
C. Figuera, J. L. Rojo- ´Alvarez, M. Wilby, I. Mora-Jim´ enez, A. J. Caama˜ no, Advanced support vector machines for 802.11 indoor location, Signal Processing 92 (9) (2012) 2126–2136
work page 2012
-
[5]
A. Roy, J. Singha, S. S. Devi, R. H. Laskar, Impulse noise removal using svm classification based fuzzy filter from gray scale images, Signal Processing 128 (2016) 262–273
work page 2016
-
[6]
C. Wang, X. Wang, C. Zhang, Z. Xia, Geometric correction based color image watermarking using fuzzy least squares support vector machine and bessel k form distribution, Signal Processing 134 (2017) 197–208
work page 2017
- [7]
-
[8]
O. L. Mangasarian, E. W. Wild, Proximal support vector machine classifiers, in: Proceedings KDD-2001: Knowledge Discovery and Data Mining, Citeseer, 2001
work page 2001
- [9]
-
[10]
O. L. Mangasarian, E. W. Wild, Multisurface proximal classification via generalized eigenvalues, IEEE transactions on pattern analysis and machine intelligence 28 (1) (2006) 69–74
work page 2006
-
[11]
Jayadeva, R. Khemchandani, S. Chandra, Twin support vector machines for pattern classification, IEEE Transactions on pattern analysis and machine intelligence 29 (5)
-
[12]
S. Ding, J. Yu, B. Qi, H. Huang, An overview on twin support vector machines, Artificial Intelligence Review 42 (2) (2014) 245–252
work page 2014
-
[13]
S. Ding, N. Zhang, X. Zhang, F. Wu, Twin support vector machine: theory, algorithm and applications, Neural Computing and Applications 28 (11) (2017) 3119–3130
work page 2017
- [14]
-
[15]
Q. Ye, C. Zhao, S. Gao, H. Zheng, Weighted twin support vector machines with local information and its application, Neural Networks 35 (2012) 31–39
work page 2012
-
[16]
J. A. Nasiri, N. M. Charkari, K. Mozafari, Energy-based model of least squares twin support vector machines for human action recognition, Signal Processing 104 (2014) 248–257
work page 2014
-
[17]
X. Pan, Y. Luo, Y. Xu, K-nearest neighbor based structural twin support vector machine, Knowledge-Based Systems 88 (2015) 34–44
work page 2015
-
[18]
Z. Qi, Y. Tian, Y. Shi, Structural twin support vector machine for classification, Knowledge-Based Systems 43 (2013) 74–81
work page 2013
-
[19]
Y. Xu, K-nearest neighbor-based weighted multi-class twin support vector machine, Neurocomputing 205 (2016) 430–438. 27
work page 2016
-
[20]
Y. Xu, R. Guo, L. Wang, A twin multi-class classification support vector machine, Cognitive computation 5 (4) (2013) 580–588
work page 2013
-
[21]
X. Pang, C. Xu, Y. Xu, Scaling knn multi-class twin support vector machine via safe instance reduction, Knowledge-Based Systems 148 (2018) 17–30
work page 2018
-
[22]
S. Shalev-Shwartz, S. Ben-David, Understanding machine learning: From theory to algorithms, Cambridge university press, 2014
work page 2014
-
[23]
S. Xia, Z. Xiong, Y. Luo, L. Dong, G. Zhang, Location difference of multiple distances based k-nearest neighbors algorithm, Knowledge-Based Systems 90 (2015) 99–110
work page 2015
-
[24]
J. H. Friedman, J. L. Bentley, R. A. Finkel, An algorithm for finding best matches in logarithmic expected time, ACM Transactions on Mathematical Software (TOMS) 3 (3) (1977) 209–226
work page 1977
-
[25]
Y.-S. Chen, Y.-P. Hung, T.-F. Yen, C.-S. Fuh, Fast and versatile algorithm for nearest neighbor search based on a lower bound tree, Pattern Recognition 40 (2) (2007) 360–375
work page 2007
-
[26]
S. A. Dudani, The distance-weighted k-nearest-neighbor rule, IEEE Transactions on Systems, Man, and Cybernetics (4) (1976) 325–327
work page 1976
-
[27]
J. Gou, L. Du, Y. Zhang, T. Xiong, et al., A new distance-weighted k-nearest neighbor classifier, J. Inf. Comput. Sci 9 (6) (2012) 1429–1436
work page 2012
-
[28]
Y.-H. Shao, C.-H. Zhang, X.-B. Wang, N.-Y. Deng, Improvements on twin support vector machines, IEEE transactions on neural networks 22 (6) (2011) 962–968
work page 2011
-
[29]
G. H. Golub, C. F. Van Loan, Matrix computations, Vol. 3, JHU Press, 2012
work page 2012
-
[30]
S. Sra, S. Nowozin, S. J. Wright, Optimization for machine learning, Mit Press, 2012
work page 2012
-
[31]
O. L. Mangasarian, D. R. Musicant, Successive overrelaxation for support vector machines, IEEE Transactions on Neural Networks 10 (5) (1999) 1032–1037
work page 1999
-
[32]
C.-J. Hsieh, K.-W. Chang, C.-J. Lin, S. S. Keerthi, S. Sundararajan, A dual coordinate descent method for large-scale linear svm, in: Proceedings of the 25th international conference on Machine learning, ACM, 2008, pp. 408–415
work page 2008
-
[33]
X. Peng, D. Chen, L. Kong, A clipping dual coordinate descent algorithm for solving support vector machines, Knowledge- Based Systems 71 (2014) 266–278
work page 2014
-
[34]
A. M. Mir, J. A. Nasiri, Lighttwinsvm: A simple and fast implementation of standard twin support vector machine classifier, Journal of Open Source Software 4 (2019) 1252. doi:10.21105/joss.01252. URL https://doi.org/10.21105/joss.01252
-
[35]
S. v. d. Walt, S. C. Colbert, G. Varoquaux, The numpy array: a structure for efficient numerical computation, Computing in Science & Engineering 13 (2) (2011) 22–30
work page 2011
- [36]
-
[37]
F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, et al., Scikit-learn: Machine learning in python, Journal of machine learning research 12 (Oct) (2011) 2825–2830
work page 2011
-
[38]
B. D. Ripley, Pattern recognition and neural networks, Cambridge university press, 2007
work page 2007
-
[39]
T. Ho, E. Kleinberg, Checkerboard dataset (1996)
work page 1996
-
[40]
J. Demˇ sar, Statistical comparisons of classifiers over multiple data sets, Journal of Machine learning research 7 (Jan) (2006) 1–30
work page 2006
-
[41]
D. Musicant, Ndc: normally distributed clustered datasets, Computer Sciences Department, University of Wisconsin, Madison. 28
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.