Age and gender bias in pedestrian detection algorithms
Pith reviewed 2026-05-25 16:16 UTC · model grok-4.3
The pith
State-of-the-art pedestrian detection algorithms have significantly higher miss rates on children than on adults.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
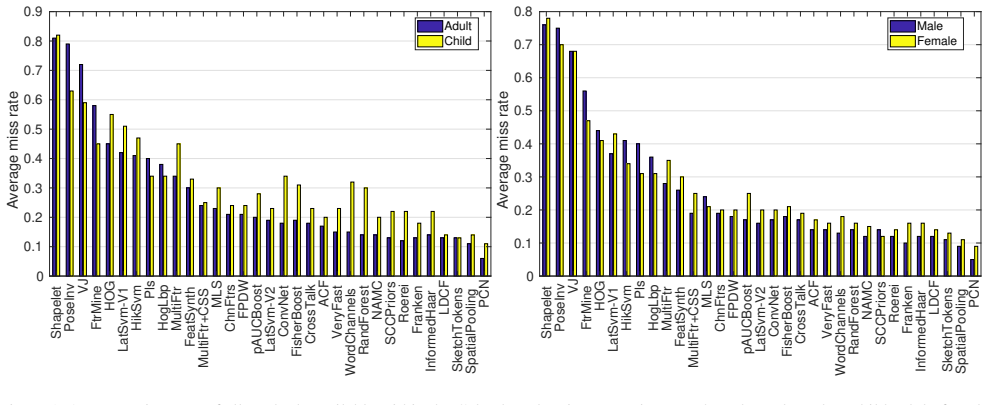
All of the 24 top-performing methods of the Caltech Pedestrian Detection Benchmark have higher miss rates on children. The difference is significant. Algorithms were also gender-biased on average but the performance differences were not significant. The analysis is based on the INRIA Person Dataset extended with child, adult, male and female labels.
What carries the argument
Miss rate evaluation on the age- and gender-labeled extension of the INRIA Person Dataset applied to the 24 top Caltech benchmark detectors.
If this is right
- Pedestrian detectors are likely to produce higher error rates for child pedestrians in real deployments.
- The bias varies depending on the specific classifier, features, and training data of each method.
- Gender performance gaps exist on average across the methods but do not reach statistical significance.
- Technical approaches to reduce the bias may face barriers related to data collection and model design.
Where Pith is reading between the lines
- Training sets that under-represent children could be a primary driver of the observed age bias.
- Deploying these detectors without age-specific validation risks amplifying safety disparities in urban environments.
- Similar subgroup analyses could be applied to other vision tasks such as object detection in autonomous driving to check for demographic biases.
Load-bearing premise
The manual extension of the INRIA Person Dataset with child/adult and male/female labels produces accurate group assignments that reflect real-world pedestrian distributions without introducing labeling artifacts that drive the observed miss-rate differences.
What would settle it
Repeating the miss-rate analysis on a different pedestrian dataset with independently verified child and adult labels would show no significant age-based difference if the original result stems from labeling artifacts.
Figures
read the original abstract
Pedestrian detection algorithms are important components of mobile robots, such as autonomous vehicles, which directly relate to human safety. Performance disparities in these algorithms could translate into disparate impact in the form of biased accident outcomes. To evaluate the need for such concerns, we characterize the age and gender bias in the performance of state-of-the-art pedestrian detection algorithms. Our analysis is based on the INRIA Person Dataset extended with child, adult, male and female labels. We show that all of the 24 top-performing methods of the Caltech Pedestrian Detection Benchmark have higher miss rates on children. The difference is significant and we analyse how it varies with the classifier, features and training data used by the methods. Algorithms were also gender-biased on average but the performance differences were not significant. We discuss the source of the bias, the ethical implications, possible technical solutions and barriers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript evaluates 24 top-performing pedestrian detectors from the Caltech benchmark on the INRIA Person Dataset after manually extending it with child/adult and male/female labels. It claims that all 24 methods exhibit higher miss rates on children than adults, with the difference statistically significant, while average gender differences are present but not significant. The analysis further examines how bias varies with classifier type, features, and training data, and discusses sources of bias along with ethical implications and potential mitigations.
Significance. If the empirical findings hold after addressing methodological gaps, the work is significant for identifying potential safety-relevant biases in computer vision systems used in autonomous vehicles and robotics. It contributes an empirical comparison across a standard benchmark and multiple methods, which is a strength for assessing generality. The discussion of ethical implications and technical solutions adds value to the fairness literature in AI.
major comments (2)
- [dataset extension description] The central claim that all 24 methods show significantly higher miss rates on children rests on the manually added age and gender labels to the INRIA dataset. The manuscript provides no protocol details, annotator count, inter-rater agreement statistics, or external validation for these labels (dataset extension description). Systematic labeling errors concentrated in the child subset would directly produce the reported gap without reflecting detector bias.
- [results and abstract] The abstract and results assert a statistically significant difference across all 24 methods but report no sample sizes per age/gender group, the exact statistical test used, p-values, confidence intervals, or controls for confounders such as child height, pose, or occlusion (results and abstract). Without these, the significance claim cannot be evaluated and may be driven by unaccounted factors rather than algorithmic bias.
minor comments (2)
- [abstract] The abstract could explicitly name the INRIA dataset and note the total number of methods evaluated for clarity.
- [figures] Some figures comparing miss rates across methods would benefit from error bars or explicit indication of statistical significance to aid interpretation.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which have helped us improve the clarity and rigor of the manuscript. We address each major comment below.
read point-by-point responses
-
Referee: [dataset extension description] The central claim that all 24 methods show significantly higher miss rates on children rests on the manually added age and gender labels to the INRIA dataset. The manuscript provides no protocol details, annotator count, inter-rater agreement statistics, or external validation for these labels (dataset extension description). Systematic labeling errors concentrated in the child subset would directly produce the reported gap without reflecting detector bias.
Authors: We agree that the original manuscript did not provide sufficient detail on the labeling process. The age and gender annotations were performed by two authors via independent visual inspection of the INRIA images, using criteria of apparent age (children defined as appearing under ~12 years) and binary gender presentation. Disagreements were resolved by joint review, resulting in full consensus. We have added a new subsection to the methods describing the protocol, annotator count, and agreement process. We also note the limitation that no external validation (e.g., against ground-truth age) was performed, as the INRIA dataset does not provide it, and have added discussion of this as a potential source of uncertainty. revision: yes
-
Referee: [results and abstract] The abstract and results assert a statistically significant difference across all 24 methods but report no sample sizes per age/gender group, the exact statistical test used, p-values, confidence intervals, or controls for confounders such as child height, pose, or occlusion (results and abstract). Without these, the significance claim cannot be evaluated and may be driven by unaccounted factors rather than algorithmic bias.
Authors: We have revised the abstract, results section, and added a supplementary table reporting the exact sample sizes (child vs. adult instances), the statistical test used (McNemar's test for paired miss-rate differences), per-method p-values, and 95% confidence intervals. For confounders, we have added subset analyses controlling for occlusion and pose, where the child-adult gap remains significant. Height is inherently confounded with age in real-world data and cannot be fully decoupled without new annotations or datasets; we now explicitly discuss this as a limitation and potential contributing factor to the observed bias rather than claiming it is purely algorithmic. revision: partial
Circularity Check
No circularity: empirical evaluation on extended dataset
full rationale
The paper conducts an empirical comparison of 24 existing pedestrian detectors on the INRIA Person Dataset after manual addition of age/gender labels. No mathematical derivations, fitted parameters renamed as predictions, or self-citation chains appear in the analysis. Miss-rate differences are computed directly from detector outputs versus the added labels, with no equations or steps that reduce to the inputs by construction. The central claim is a set of statistical observations on benchmark methods, not a derived result equivalent to its own assumptions.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Miss rate differences between demographic groups can be meaningfully compared using standard statistical significance tests
- domain assumption The INRIA Person Dataset with added child/adult and male/female labels is a suitable proxy for real-world pedestrian appearance distributions
Reference graph
Works this paper leans on
-
[1]
Solon Barocas and Andrew D Selbst. Big data’s disparate impact. California Law Review, 104:671, 2016
work page 2016
-
[2]
The Ethics of Health Care Rationing: An Introduction
Greg Bognar and Iwao Hirose. The Ethics of Health Care Rationing: An Introduction. Routledge, 2014
work page 2014
-
[3]
Man is to computer program- mer as woman is to homemaker? debiasing word embed- dings
Tolga Bolukbasi, Kai-Wei Chang, James Y Zou, Venkatesh Saligrama, and Adam T Kalai. Man is to computer program- mer as woman is to homemaker? debiasing word embed- dings. In Advances in neural information processing sys- tems, pages 4349–4357, 2016
work page 2016
-
[4]
The net- worked nature of algorithmic discrimination
Danah Boyd, Karen Levy, and Alice Marwick. The net- worked nature of algorithmic discrimination. Data and Dis- crimination: Collected Essays. Open Technology Institute , 2014
work page 2014
-
[5]
Gender shades: Inter- sectional accuracy disparities in commercial gender classifi- cation
Joy Buolamwini and Timnit Gebru. Gender shades: Inter- sectional accuracy disparities in commercial gender classifi- cation. In Sorelle A. Friedler and Christo Wilson, editors, Proceedings of the 1st Conference on Fairness, Accountabil- ity and Transparency, volume 81 of Proceedings of Machine Learning Research, pages 77–91, New York, NY , USA, 23– 24 Feb ...
work page 2018
-
[6]
Fair prediction with disparate im- pact: A study of bias in recidivism prediction instruments
Alexandra Chouldechova. Fair prediction with disparate im- pact: A study of bias in recidivism prediction instruments. Big Data, 5(2):153–163, 2017
work page 2017
- [7]
-
[8]
Histograms of oriented gra- dients for human detection
Navneet Dalal and Bill Triggs. Histograms of oriented gra- dients for human detection. In international Conference on computer vision & Pattern Recognition (CVPR’05) , vol- ume 1, pages 886–893. IEEE Computer Society, 2005
work page 2005
-
[9]
Caltech pedestrian detection benchmark, 2012
Piotr Doll ´ar. Caltech pedestrian detection benchmark, 2012
work page 2012
-
[10]
Pedestrian detection: An evaluation of the state of the art
Piotr Doll ´ar, Christian Wojek, Bernt Schiele, and Pietro Per- ona. Pedestrian detection: An evaluation of the state of the art. PAMI, 34, 2012
work page 2012
-
[11]
Batya Friedman and Helen Nissenbaum. Bias in computer systems. ACM Transactions on Information Systems (TOIS), 14(3):330–347, 1996
work page 1996
-
[12]
Uber’s self-driving car saw the pedestrian but didnt swerve—report
Samuel Gibbs. Uber’s self-driving car saw the pedestrian but didnt swerve—report. The Guardian, 2018
work page 2018
-
[13]
The ugly truth about ourselves and our robot creations: the problem of bias and social inequity
Ayanna Howard and Jason Borenstein. The ugly truth about ourselves and our robot creations: the problem of bias and social inequity. Science and engineering ethics, 24(5):1521– 1536, 2018
work page 2018
-
[14]
B. Taati, S. Zhao, A. B. Ashraf, A. Asgarian, M. E. Browne, K. M. Prkachin, A. Mihailidis, and T. Hadjistavropoulos. Al- gorithmic bias in clinical populationsevaluating and improv- ing facial analysis technology in older adults with dementia. IEEE Access, 7:25527–25534, 2019
work page 2019
-
[15]
Predictive Inequity in Object Detection
Benjamin Wilson, Judy Hoffman, and Jamie Morgenstern. Predictive inequity in object detection. arXiv preprint arXiv:1902.11097, 2019. 4
work page internal anchor Pith review Pith/arXiv arXiv 1902
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.