Robust Linear Discriminant Analysis Using Ratio Minimization of L1,2-Norms
Pith reviewed 2026-05-25 13:00 UTC · model grok-4.3
The pith
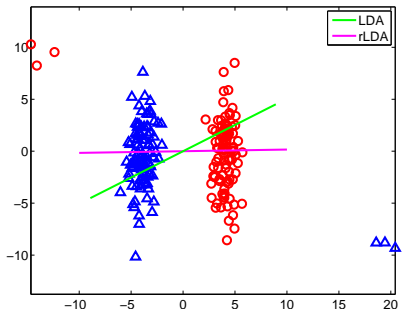
Linear discriminant analysis becomes robust to outliers by minimizing an L1,2-norm ratio instead of the squared L2-norm ratio.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
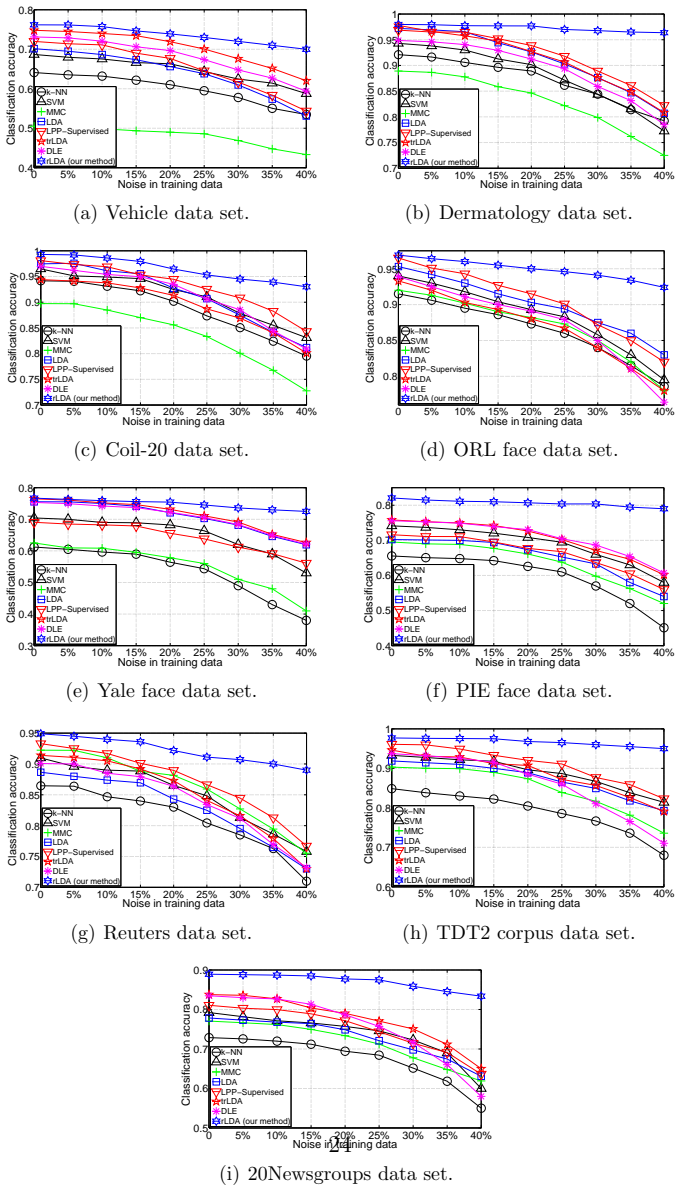
We propose a novel robust linear discriminant analysis method based on the L1,2-norm ratio minimization. We derive a new efficient algorithm to solve this challenging problem, and provide a theoretical analysis on the convergence of our algorithm. The proposed algorithm is easy to implement, and converges fast in practice. Extensive experiments on both synthetic data and nine real benchmark data sets show the effectiveness of the proposed robust LDA method.
What carries the argument
L1,2-norm ratio minimization, which replaces the squared L2-norm ratio in the LDA objective and is solved by a new iterative algorithm whose convergence is analyzed.
If this is right
- The new algorithm solves a previously intractable non-smooth ratio minimization problem for LDA.
- Convergence of the iteration is guaranteed by the supplied theoretical analysis.
- The method produces subspaces that separate classes more reliably than standard LDA when outliers are present.
- The approach extends L1-norm robustness ideas from PCA to the discriminative ratio setting of LDA.
Where Pith is reading between the lines
- The same ratio-minimization technique could be tested on other subspace methods that currently rely on L2-norm ratios.
- If the algorithm scales well, it might support real-time updates of LDA models on streaming data with occasional outliers.
- The convergence proof might be reusable for similar ratio objectives that arise in clustering or metric learning.
Load-bearing premise
That switching to an L1,2-norm ratio automatically confers robustness to outliers in the LDA objective without separate verification for the ratio-minimization case.
What would settle it
A controlled experiment on data with added outliers where the L1,2-norm ratio LDA yields lower classification accuracy or poorer class separation than standard LDA would falsify the robustness claim.
Figures
read the original abstract
As one of the most popular linear subspace learning methods, the Linear Discriminant Analysis (LDA) method has been widely studied in machine learning community and applied to many scientific applications. Traditional LDA minimizes the ratio of squared L2-norms, which is sensitive to outliers. In recent research, many L1-norm based robust Principle Component Analysis methods were proposed to improve the robustness to outliers. However, due to the difficulty of L1-norm ratio optimization, so far there is no existing work to utilize sparsity-inducing norms for LDA objective. In this paper, we propose a novel robust linear discriminant analysis method based on the L1,2-norm ratio minimization. Minimizing the L1,2-norm ratio is a much more challenging problem than the traditional methods, and there is no existing optimization algorithm to solve such non-smooth terms ratio problem. We derive a new efficient algorithm to solve this challenging problem, and provide a theoretical analysis on the convergence of our algorithm. The proposed algorithm is easy to implement, and converges fast in practice. Extensive experiments on both synthetic data and nine real benchmark data sets show the effectiveness of the proposed robust LDA method.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a novel robust LDA method by minimizing an L1,2-norm ratio (instead of the conventional squared-L2 ratio) in the between/within scatter objective. It derives a new iterative algorithm for the resulting non-smooth ratio optimization problem, supplies a convergence analysis for that algorithm, and reports experiments on synthetic outliers plus nine real benchmark datasets.
Significance. If the robustness property is established, the work would usefully extend L1-norm ideas from PCA to the supervised LDA setting and supply a practical solver for a previously unaddressed non-smooth ratio problem. The algorithmic derivation and convergence guarantee are the clearest technical contributions.
major comments (2)
- [Introduction / §2] Introduction and §2: the claim that the L1,2-norm ratio automatically confers outlier robustness is motivated solely by citation to prior L1-PCA results; no influence-function argument, breakdown-point bound, or perturbation analysis is supplied for the specific LDA ratio objective. This assumption is load-bearing for the central claim.
- [§4] §4 (experiments): synthetic-outlier tests evaluate an unproven modeling assumption rather than a derived robustness property; without the missing analysis, the performance gains cannot be attributed to the L1,2 formulation with certainty.
minor comments (2)
- [Abstract] Abstract: the nine real datasets and the quantitative metrics (accuracy, etc.) are not named.
- [§2] Notation: the precise definition of the L1,2-norm (row-wise or column-wise) should be stated explicitly before the objective is written.
Simulated Author's Rebuttal
We thank the referee for the careful review and constructive feedback. We respond point-by-point to the major comments below.
read point-by-point responses
-
Referee: [Introduction / §2] Introduction and §2: the claim that the L1,2-norm ratio automatically confers outlier robustness is motivated solely by citation to prior L1-PCA results; no influence-function argument, breakdown-point bound, or perturbation analysis is supplied for the specific LDA ratio objective. This assumption is load-bearing for the central claim.
Authors: We agree that the robustness claim for the L1,2-norm ratio in the LDA objective rests on an analogy to L1-PCA results rather than a dedicated analysis (influence function, breakdown point, or perturbation) specific to the supervised ratio formulation. This is a substantive gap in the current manuscript. In revision we will rephrase the introduction and §2 to present the robustness as a motivated conjecture supported by the L1-norm literature and by the empirical results, without asserting an automatically conferred property. We do not supply the requested theoretical analysis. revision: partial
-
Referee: [§4] §4 (experiments): synthetic-outlier tests evaluate an unproven modeling assumption rather than a derived robustness property; without the missing analysis, the performance gains cannot be attributed to the L1,2 formulation with certainty.
Authors: The synthetic experiments demonstrate practical behavior under controlled outlier contamination, while the nine real datasets provide complementary evidence. We concur that, absent the missing theoretical analysis, performance differences remain empirical observations rather than direct proof of the L1,2 mechanism. In revision we will add a clarifying sentence in §4 stating that the reported gains constitute empirical support for the proposed method. revision: partial
- A formal robustness analysis (influence function, breakdown point, or perturbation analysis) for the specific L1,2-norm ratio objective in LDA.
Circularity Check
No significant circularity; new algorithm and convergence analysis are independent of inputs
full rationale
The paper introduces a novel objective (L1,2-norm ratio for LDA) and derives a new solver plus convergence proof for the non-smooth ratio minimization. No step reduces by construction to a fitted parameter, self-citation chain, or renamed prior result. The robustness motivation cites external L1-PCA literature rather than self-citations that bear the central load. The derivation chain (objective definition → algorithm → convergence theorem) is self-contained and does not equate outputs to inputs via the enumerated patterns. Score 0 is the appropriate default when no explicit reduction is quotable.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Data matrices admit well-defined within-class and between-class scatter structures suitable for LDA.
Reference graph
Works this paper leans on
-
[1]
A new and fast implementation for null space based linear discriminant analysis,
D. Chu and G. S. Thye, “A new and fast implementation for null space based linear discriminant analysis,” Pattern Recognition, vol. 43(4), pp. 1373–1379, 2010
work page 2010
-
[2]
J. Ye, “Characterization of a family of algorithms for generalized dis- criminant analysis on undersampled problems,” Journal of Machine Learning Research, vol. 6, pp. 483–502, 2005
work page 2005
-
[3]
Multi-class discriminant kernel learning via convex programming,
J. Ye, S. Ji, and J. Chen, “Multi-class discriminant kernel learning via convex programming,” The Journal of Machine Learning Research , vol. 9, pp. 719–758, 2008
work page 2008
-
[4]
Computational and theoretical analysis of null space and orthogonal linear discriminant analysis,
J. Ye and T. Xiong, “Computational and theoretical analysis of null space and orthogonal linear discriminant analysis,” Journal of Machine Learning Research, vol. 7, pp. 581–599, 2006
work page 2006
-
[5]
Least squares linear discriminant analysis,
J. Ye, “Least squares linear discriminant analysis,” Proceedings of the 24th international conference on Machine learning , pp. 1087–1093, 2007
work page 2007
-
[6]
Hierarchical linear discriminant analysis for beamforming,
J. Choo, B. L. Drake, and H. Park, “Hierarchical linear discriminant analysis for beamforming,” Siam Data Mining (SDM) , pp. 894–905, 2009
work page 2009
-
[7]
Adaptive nonlinear discriminant analysis by regularized minimum squared errors,
H. Kim, B. L. Drake, and H. Park, “Adaptive nonlinear discriminant analysis by regularized minimum squared errors,” IEEE Trans. Knowl. Data Eng. , vol. 18(5), pp. 603–612, 2006. 20
work page 2006
-
[8]
A comparison of generalized linear discrim- inant analysis algorithms,
C. H. Park and H. Park, “A comparison of generalized linear discrim- inant analysis algorithms,” Pattern Recognition, vol. 41(3), pp. 1083– 1097, 2008
work page 2008
-
[9]
Submanifold-preserving dis- criminant analysis with an auto-optimized graph,
F. Nie, Z. Wang, R. Wang, and X. Li, “Submanifold-preserving dis- criminant analysis with an auto-optimized graph,” IEEE transactions on cybernetics, 2019
work page 2019
-
[10]
Trace ratio vs. ratio trace for dimensionality reduction,
H. Wang, S. Yan, D. Xu, X. Tang, and T. S. Huang, “Trace ratio vs. ratio trace for dimensionality reduction,” in CVPR, 2007
work page 2007
-
[11]
Trace ratio problem revisited,
Y. Jia, F. Nie, and C. Zhang, “Trace ratio problem revisited,” IEEE Transactions on Neural Networks , vol. 20, no. 4, pp. 729–735, 2009
work page 2009
-
[12]
P. J. Huber, Robust Statistics. Wiley, 1981
work page 1981
-
[13]
Robust lda classification by subsampling,
S. Fidler and A. Leonardis, “Robust lda classification by subsampling,” Conference on Computer Vision and Pattern Recognition Workshop , p. 97, 2003
work page 2003
-
[14]
Robust fisher discriminant analysis,
S. Kim, A. Magnani, and S. Boyd, “Robust fisher discriminant analysis,” Advances in Neural Information Processing Systems , p. 97, 2006
work page 2006
-
[15]
Classification efficiencies for robust linear discriminant analysis,
C. Croux, P. Filzmoser, and K. Joossens, “Classification efficiencies for robust linear discriminant analysis,”Statistica Sinica, pp. 581–599, 2008
work page 2008
-
[16]
A new formulation of linear discriminant analysis for robust dimensionality reduction,
H. Zhao, Z. Wang, and F. Nie, “A new formulation of linear discriminant analysis for robust dimensionality reduction,” IEEE Transactions on Knowledge and Data Engineering , vol. 31, no. 4, pp. 629–640, 2018
work page 2018
-
[17]
A l1-norm pca and heuris- tic approach,
A. Baccini, P. Besse, and A. de Faguerolles, “A l1-norm pca and heuris- tic approach,” International Conference on Ordinal and Symbolic Data Analysis, pp. 359–368, 1996
work page 1996
-
[18]
Robust l1 principal component analysis and its bayesian vari- ational inference,
J. Gao, “Robust l1 principal component analysis and its bayesian vari- ational inference,” Neural Computation, vol. 20, pp. 555–572, 2008
work page 2008
-
[19]
Q. Ke and T. Kanade, “Robust l1 norm factorization in the presence of outliers and missing data by alternative convex programming,” IEEE Conf. Computer Vision and Pattern Recognition , pp. 592–599, 2004. 21
work page 2004
-
[20]
C. Ding, D. Zhou, X. He, and H. Zha, “R1-pca: Rotational invariant l1- norm principal component analysis for robust subspace factorization,” Int’l Conf. Machine Learning , 2006
work page 2006
-
[21]
Principal component analysis based on l1-norm maximiza- tion,
N. Kwak, “Principal component analysis based on l1-norm maximiza- tion,” IEEE Transactions on Pattern Analysis and Machine Intelligence , vol. 30, pp. 1672–1680, 2008
work page 2008
-
[22]
Robust principal component analysis: Exact recovery of corrupted,
J. Wright, A. Ganesh, S. Rao, Y. Peng, and Y. Ma, “Robust principal component analysis: Exact recovery of corrupted,” Advances in Neural Information Processing Systems , p. 116, 2009
work page 2009
-
[23]
Optimal mean robust principal compo- nent analysis,
F. Nie, J. Yuan, and H. Huang, “Optimal mean robust principal compo- nent analysis,” in Proceedings of the 31st International Conference on Machine Learning (ICML) , 2014, pp. 1062–1070
work page 2014
-
[24]
Robust l1-norm two-dimensional linear discriminant analysis,
C.-N. Li, Y.-H. Shao, and N.-Y. Deng, “Robust l1-norm two-dimensional linear discriminant analysis,” Neural Networks, vol. 65, pp. 92–104, 2015
work page 2015
-
[25]
L1-norm dis- tance linear discriminant analysis based on an effective iterative algo- rithm,
Q. Ye, J. Yang, F. Liu, C. Zhao, N. Ye, and T. Yin, “L1-norm dis- tance linear discriminant analysis based on an effective iterative algo- rithm,” IEEE Transactions on Circuits and Systems for Video Technol- ogy, vol. 28, no. 1, pp. 114–129, 2016
work page 2016
-
[26]
A non-greedy algorithm for l1-norm lda,
Y. Liu, Q. Gao, S. Miao, X. Gao, F. Nie, and Y. Li, “A non-greedy algorithm for l1-norm lda,” IEEE Transactions on Image Processing , vol. 26, no. 2, pp. 684–695, 2016
work page 2016
-
[27]
Linear discriminant analysis based on l1-norm maximization,
F. Zhong and J. Zhang, “Linear discriminant analysis based on l1-norm maximization,” IEEE Transactions on Image Processing , vol. 22, no. 8, pp. 3018–3027, 2013
work page 2013
-
[28]
Efficient and robust feature selection via joint ℓ2,1-norms minimization,
F. Nie, H. Huang, X. Cai, and C. Ding, “Efficient and robust feature selection via joint ℓ2,1-norms minimization,” in NIPS, 2010
work page 2010
-
[29]
Http://www.cl.cam.ac.uk/research/dtg/attarchive/ facedatabase.html
-
[30]
From few to many: Illumination cone models for face recognition under variable lighting and pose,
A. Georghiades, P. Belhumeur, and D. Kriegman, “From few to many: Illumination cone models for face recognition under variable lighting and pose,” IEEE Trans. Pattern Anal. Mach. Intelligence , vol. 23, no. 6, pp. 643–660, 2001. 22
work page 2001
-
[31]
The cmu pose, illumination, and expression database,
T. Sim and S. Baker, “The cmu pose, illumination, and expression database,” IEEE Transactions on PAMI, vol. 25, no. 12, pp. 1615–1617, 2003
work page 2003
-
[32]
Fukunaga, Introduction to statistical pattern recognition
K. Fukunaga, Introduction to statistical pattern recognition . Academic Press, 1990
work page 1990
-
[33]
Locality Preserving Projections,
X. He and P. Niyogi, “Locality Preserving Projections,” in NIPS, 2003
work page 2003
-
[34]
Efficient and robust feature extraction by maximum margin criterion,
H. Li, T. Jiang, and K. Zhang, “Efficient and robust feature extraction by maximum margin criterion,” in NIPS, 2004
work page 2004
-
[35]
Discriminant Laplacian Embedding,
H. Wang, H. Huang, and C. Ding, “Discriminant Laplacian Embedding,” in AAAI, 2010. 23 0 5% 10% 15% 20% 25% 30% 35% 40%0.4 0.5 0.6 0.7 0.8 Noise in training data Classification accuracy k−NN SVM MMC LDA LPP−Supervised trLDA DLE rLDA (our method) (a) Vehicle data set. 0 5% 10% 15% 20% 25% 30% 35% 40%0.7 0.75 0.8 0.85 0.9 0.95 1 Noise in training data Classi...
work page 2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.