SAN: Scale-Aware Network for Semantic Segmentation of High-Resolution Aerial Images
Pith reviewed 2026-05-25 01:51 UTC · model grok-4.3
The pith
A re-sampling operation in a scale-aware module lets networks better segment ground objects of inconsistent sizes in high-resolution aerial images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
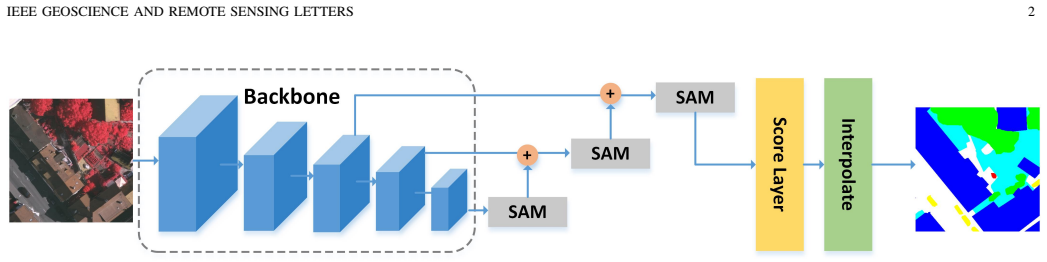
The scale-aware module employs a re-sampling method to make pixels adjust their positions to fit the ground objects with different scales, implicitly introducing spatial attention by employing a re-sampling map as the weighted map. As a result, the scale-aware network has a stronger ability to distinguish the ground objects with inconsistent scale.
What carries the argument
The scale-aware module (SAM) which uses re-sampling to adjust pixel positions and a re-sampling map for spatial attention.
If this is right
- SANet distinguishes ground objects with inconsistent scales more effectively than standard networks.
- The proposed modules can be easily embedded into most existing networks to improve their segmentation performance.
- Experimental results on the Vaihingen Dataset confirm the effectiveness of the module.
Where Pith is reading between the lines
- This re-sampling technique might generalize to other computer vision tasks involving scale variations, such as object detection in satellite imagery.
- It could lead to more efficient models by reducing reliance on multiple parallel processing branches for different scales.
- Applications in military exploration and urban planning could see more accurate automated analysis of aerial data.
Load-bearing premise
That the re-sampling operation adjusts pixel positions to match object scales without introducing artifacts or needing dataset-specific tuning.
What would settle it
Running the model on a set of aerial images with known scale inconsistencies and checking if segmentation accuracy does not improve or if visual artifacts appear in the output maps.
Figures


read the original abstract
High-resolution aerial images have a wide range of applications, such as military exploration, and urban planning. Semantic segmentation is a fundamental method extensively used in the analysis of high-resolution aerial images. However, the ground objects in high-resolution aerial images have the characteristics of inconsistent scales, and this feature usually leads to unexpected predictions. To tackle this issue, we propose a novel scale-aware module (SAM). In SAM, we employ the re-sampling method aimed to make pixels adjust their positions to fit the ground objects with different scales, and it implicitly introduces spatial attention by employing a re-sampling map as the weighted map. As a result, the network with the proposed module named scale-aware network (SANet) has a stronger ability to distinguish the ground objects with inconsistent scale. Other than this, our proposed modules can easily embed in most of the existing network to improve their performance. We evaluate our modules on the International Society for Photogrammetry and Remote Sensing Vaihingen Dataset, and the experimental results and comprehensive analysis demonstrate the effectiveness of our proposed module.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a Scale-Aware Module (SAM) for semantic segmentation of high-resolution aerial images. SAM uses a re-sampling operation to adjust pixel positions to better match ground objects of inconsistent scales and implicitly introduces spatial attention via the re-sampling map. The resulting Scale-Aware Network (SANet) is claimed to have stronger ability to distinguish such objects and to be easily embeddable in existing networks. Effectiveness is asserted via experiments on the ISPRS Vaihingen dataset.
Significance. If the re-sampling mechanism can be rigorously shown to improve scale handling, the module would provide a practical, embeddable component for remote-sensing segmentation tasks where object scales vary widely. The absence of any parameter-free derivation or machine-checked elements limits the assessed significance to the empirical contribution.
major comments (2)
- [SAM description] SAM description (no equation or pseudocode): the re-sampling operation and generation of the re-sampling map are presented only at high level; no formulation shows how the map is computed, whether it is learned end-to-end, or its differentiability, leaving the central claim that it repositions pixels to match object scales without artifacts unsupported.
- [Experiments section] Experiments section: no ablation studies, error analysis by object scale, or controlled comparisons isolate the contribution of the re-sampling map versus baseline interpolation effects, so the asserted improvement in distinguishing inconsistent-scale objects on Vaihingen cannot be verified.
minor comments (1)
- [Abstract] Abstract: the sentence beginning 'Other than this' is informal; rephrase for journal style.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will incorporate revisions to strengthen the presentation of the Scale-Aware Module and the experimental validation.
read point-by-point responses
-
Referee: [SAM description] SAM description (no equation or pseudocode): the re-sampling operation and generation of the re-sampling map are presented only at high level; no formulation shows how the map is computed, whether it is learned end-to-end, or its differentiability, leaving the central claim that it repositions pixels to match object scales without artifacts unsupported.
Authors: We agree that the original manuscript presents the re-sampling operation and re-sampling map generation at a high level without explicit equations or pseudocode. In the revision we will add the mathematical formulation of the re-sampling map computation, state that the map is generated by a lightweight convolutional branch and learned end-to-end via back-propagation, and confirm differentiability through the use of bilinear interpolation for the re-sampling step. These additions will directly support the claim that pixels are repositioned to better match object scales. revision: yes
-
Referee: [Experiments section] Experiments section: no ablation studies, error analysis by object scale, or controlled comparisons isolate the contribution of the re-sampling map versus baseline interpolation effects, so the asserted improvement in distinguishing inconsistent-scale objects on Vaihingen cannot be verified.
Authors: We acknowledge that the current experiments section lacks dedicated ablation studies, scale-stratified error analysis, and controlled comparisons against standard interpolation baselines. In the revised manuscript we will include (i) an ablation removing the learned re-sampling map while retaining the same interpolation operator, (ii) per-class and per-scale mIoU breakdowns on the Vaihingen dataset, and (iii) direct quantitative comparison of SANet against the baseline network using conventional bilinear upsampling. These additions will isolate the contribution of the re-sampling map. revision: yes
Circularity Check
No derivation chain; purely empirical module design
full rationale
The paper introduces SAM as a re-sampling module that implicitly adds spatial attention and asserts improved scale handling for SANet, but supplies no equations, first-principles derivation, or predictive claim that could reduce to its own inputs. All support is experimental (Vaihingen dataset results) rather than a closed logical loop, so no self-definitional, fitted-input, or self-citation circularity exists. The design is self-contained as an engineering proposal whose validity rests on external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
ImageNet Classification with Deep Convolutional Neural Networks,
A. Krizhevsky, I. Sutskever, and G. E. Hinton, “ImageNet Classification with Deep Convolutional Neural Networks,” in Advances in Neural Information Processing Systems 25 , 2012, pp. 1097–1105
work page 2012
-
[2]
Microsoft COCO: Common Objects in Context
T.-Y . Lin, M. Maire, S. Belongie, L. Bourdev, R. Girshick, J. Hays, P. Perona, D. Ramanan, C. L. Zitnick, and P. Dollr, “Microsoft COCO: Common Objects in Context,” arXiv:1405.0312 [cs], May 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[3]
The Pascal Visual Object Classes (VOC) Challenge,
M. Everingham, L. Van Gool, C. K. I. Williams, J. Winn, and A. Zisserman, “The Pascal Visual Object Classes (VOC) Challenge,” International Journal of Computer Vision , vol. 88, no. 2, pp. 303–338, Jun. 2010
work page 2010
-
[4]
Fully Convolutional Networks for Semantic Segmentation,
J. Long, E. Shelhamer, and T. Darrell, “Fully Convolutional Networks for Semantic Segmentation,” Proc. Comput. Vis. Pattern Recognit., p. 10, Jun. 2015
work page 2015
-
[5]
U-Net: Convolutional Networks for Biomedical Image Segmentation
O. Ronneberger, P. Fischer, and T. Brox, “U-Net: Convolutional Net- works for Biomedical Image Segmentation,” arXiv:1505.04597 [cs] , May 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[6]
SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
V . Badrinarayanan, A. Kendall, and R. Cipolla, “SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation,” arXiv:1511.00561 [cs], Nov. 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[7]
Learning Deconvolution Network for Semantic Segmentation
H. Noh, S. Hong, and B. Han, “Learning Deconvolution Network for Semantic Segmentation,” arXiv:1505.04366 [cs], May 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[8]
L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille, “DeepLab: Semantic Image Segmentation with Deep Con- volutional Nets, Atrous Convolution, and Fully Connected CRFs,” arXiv:1606.00915 [cs], Jun. 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[9]
Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
L.-C. Chen, Y . Zhu, G. Papandreou, F. Schroff, and H. Adam, “Encoder- Decoder with Atrous Separable Convolution for Semantic Image Seg- mentation,” arXiv:1802.02611 [cs], Feb. 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[10]
RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation
G. Lin, A. Milan, C. Shen, and I. Reid, “RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation,” arXiv:1611.06612 [cs], Nov. 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[11]
Large Kernel Matters -- Improve Semantic Segmentation by Global Convolutional Network
C. Peng, X. Zhang, G. Yu, G. Luo, and J. Sun, “Large Kernel Matters – Improve Semantic Segmentation by Global Convolutional Network,” arXiv:1703.02719 [cs], Mar. 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[12]
Dynamic Multicontext Segmentation of Remote Sensing Im- ages Based on Convolutional Networks,
K. Nogueira, M. D. Mura, J. Chanussot, W. R. Schwartz, and J. A. d. Santos, “Dynamic Multicontext Segmentation of Remote Sensing Im- ages Based on Convolutional Networks,” IEEE Transactions on Geo- science and Remote Sensing , pp. 1–18, 2019
work page 2019
-
[13]
Adaptive Multiscale Deep Fusion Residual Network for Remote Sensing Image Classification,
G. Li, L. Li, H. Zhu, X. Liu, and L. Jiao, “Adaptive Multiscale Deep Fusion Residual Network for Remote Sensing Image Classification,” IEEE Transactions on Geoscience and Remote Sensing , pp. 1–16, 2019
work page 2019
-
[14]
A Feature Aggregation Convolutional Neural Network for Remote Sensing Scene Classification,
X. Lu, H. Sun, and X. Zheng, “A Feature Aggregation Convolutional Neural Network for Remote Sensing Scene Classification,” IEEE Trans- actions on Geoscience and Remote Sensing , pp. 1–13, 2019
work page 2019
-
[15]
M. Jaderberg, K. Simonyan, A. Zisserman, and K. Kavukcuoglu, “Spa- tial Transformer Networks,” arXiv:1506.02025 [cs], Jun. 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[16]
Learning Adaptive Receptive Fields for Deep Image Parsing Network,
Z. Wei, Y . Sun, J. Wang, H. Lai, and S. Liu, “Learning Adaptive Receptive Fields for Deep Image Parsing Network,” in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , Jul. 2017, pp. 3947–3955
work page 2017
-
[17]
Scale-Adaptive Convolutions for Scene Parsing,
R. Zhang, S. Tang, Y . Zhang, J. Li, and S. Yan, “Scale-Adaptive Convolutions for Scene Parsing,” in2017 IEEE International Conference on Computer Vision (ICCV) , Oct. 2017, pp. 2050–2058
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.