Towards Characterizing and Limiting Information Exposure in DNN Layers
Pith reviewed 2026-05-24 22:13 UTC · model grok-4.3
The pith
Last layers of a DNN encode more sensitive information from the training data than the first layers
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
When considered individually, the last layers encode a larger amount of information from the training data compared to the first layers. Neurons in convolutional layers can expose more sensitive information than those in fully connected layers, while the same DNN architecture trained on different datasets exhibits similar exposure per layer. An architecture is evaluated that protects the most sensitive layers within the memory limits of a Trusted Execution Environment against white-box membership inference attacks without incurring significant computational overhead.
What carries the argument
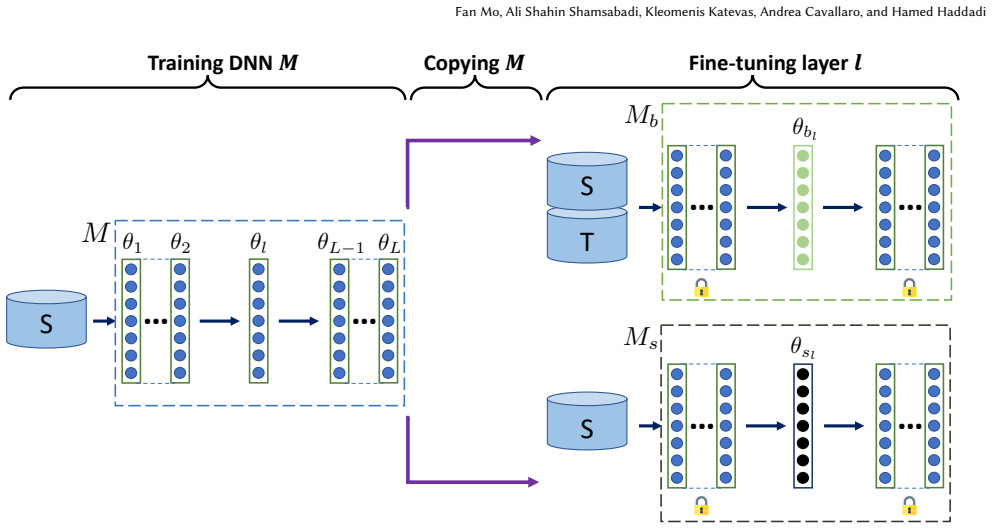
Framework that measures sensitive information memorized in each DNN layer using generalization error as the indicator
If this is right
- Last layers should receive priority when allocating protection resources such as secure hardware
- Convolutional layers generally require more attention for exposure control than fully connected layers
- Exposure levels per layer remain consistent for a given architecture regardless of the training dataset
- Shielding only the highest-exposure layers inside a TEE can limit membership inference without large performance costs
Where Pith is reading between the lines
- Model designers could use the measure to decide which layers to prune or retrain for lower exposure before deployment
- The approach might extend to auditing third-party models for privacy risks on user devices
- Layer-wise exposure data could guide hybrid on-device and cloud inference designs that keep sensitive parts local
Load-bearing premise
Generalization error serves as a reliable proxy for the quantity of sensitive information memorized in individual DNN layers
What would settle it
An experiment that finds no correlation between a layer's generalization error and the success rate of membership inference attacks targeting that layer would falsify the measurement approach
Figures




read the original abstract
Pre-trained Deep Neural Network (DNN) models are increasingly used in smartphones and other user devices to enable prediction services, leading to potential disclosures of (sensitive) information from training data captured inside these models. Based on the concept of generalization error, we propose a framework to measure the amount of sensitive information memorized in each layer of a DNN. Our results show that, when considered individually, the last layers encode a larger amount of information from the training data compared to the first layers. We find that, while the neuron of convolutional layers can expose more (sensitive) information than that of fully connected layers, the same DNN architecture trained with different datasets has similar exposure per layer. We evaluate an architecture to protect the most sensitive layers within the memory limits of Trusted Execution Environment (TEE) against potential white-box membership inference attacks without the significant computational overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a framework based on the concept of generalization error to measure the amount of sensitive information memorized in each layer of a pre-trained DNN. The authors report that, when considered individually, the last layers encode a larger amount of information from the training data compared to the first layers; neurons in convolutional layers can expose more sensitive information than those in fully connected layers; and the same DNN architecture trained with different datasets exhibits similar exposure per layer. They evaluate an architecture that protects the most sensitive layers within TEE memory limits against white-box membership inference attacks without significant computational overhead.
Significance. If the per-layer measurement is shown to be reliable, the results could inform selective protection strategies for DNNs on edge devices, particularly by identifying layers for TEE isolation. The observation of consistent per-layer exposure across datasets for a fixed architecture offers a potentially reusable design insight. The TEE-based protection evaluation provides a concrete, practical demonstration.
major comments (2)
- [Abstract and §3] Abstract and §3: The framework measures per-layer sensitive information via generalization error. Generalization error is defined on the full model output; the manuscript does not detail the layer-wise construction (e.g., ablation, per-layer loss, or intermediate mapping) nor demonstrate that the resulting scores are monotonic or specific to sensitive information rather than general memorization.
- [Membership-inference evaluation section] Membership-inference evaluation section: The attack evaluation is performed only on the protected architecture. It is not used to calibrate or cross-validate the per-layer exposure scores that underpin the central claim that last layers encode larger amounts of information; therefore the headline layer-ordering result lacks direct empirical confirmation from attack success rates.
minor comments (1)
- [Abstract] Abstract: The abstract states directional findings but supplies no methodological details, error bars, dataset descriptions, or validation steps, which impedes assessment of whether the evidence supports the stated claims.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3: The framework measures per-layer sensitive information via generalization error. Generalization error is defined on the full model output; the manuscript does not detail the layer-wise construction (e.g., ablation, per-layer loss, or intermediate mapping) nor demonstrate that the resulting scores are monotonic or specific to sensitive information rather than general memorization.
Authors: We agree that the layer-wise construction needs explicit elaboration. In the revision we will expand §3 with the precise procedure: per-layer generalization error is obtained by freezing preceding layers, attaching a lightweight linear probe to the target layer's activations, and computing the probe's test error on held-out data. We will also add an ablation comparing scores on training versus non-training data with matched statistics to support specificity to sensitive information, and report empirical monotonicity trends across layers. revision: yes
-
Referee: [Membership-inference evaluation section] Membership-inference evaluation section: The attack evaluation is performed only on the protected architecture. It is not used to calibrate or cross-validate the per-layer exposure scores that underpin the central claim that last layers encode larger amounts of information; therefore the headline layer-ordering result lacks direct empirical confirmation from attack success rates.
Authors: The per-layer ordering is derived directly from the generalization-error framework, which is intended as an attack-independent characterization. The membership-inference experiments evaluate only the downstream TEE protection strategy once the high-exposure layers have been identified. While correlating attack success with the exposure scores could offer supplementary evidence, it is not required to substantiate the framework's ordering result. We therefore do not plan to alter the evaluation structure. revision: no
Circularity Check
No circularity: framework applies external generalization error concept
full rationale
The derivation applies the established external concept of generalization error to construct a per-layer measurement framework. No step reduces by definition to its own output, no fitted parameter is relabeled as a prediction, and no load-bearing premise rests on self-citation chains or imported uniqueness theorems. The claim that later layers encode more information follows from applying this independent proxy rather than from any self-referential construction or renaming of known results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Generalization error can be used to measure the amount of sensitive information memorized in each DNN layer
Reference graph
Works this paper leans on
-
[1]
Jerome R Bellegarda and Jannes G Dolfing. 2017. Unified language modeling framework for word prediction, auto-completion and auto-correction. US Patent App. 15/141,645
work page 2017
-
[2]
Edward Chou, Josh Beal, Daniel Levy, Serena Yeung, Albert Haque, and Li Fei-Fei
-
[3]
Faster CryptoNets: Leveraging Sparsity for Real-World Encrypted Inference
Faster CryptoNets: Leveraging sparsity for real-world encrypted inference. arXiv preprint arXiv:1811.09953 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
- [4]
-
[5]
Briland Hitaj, Giuseppe Ateniese, and Fernando Pérez-Cruz. 2017. Deep models under the GAN: information leakage from collaborative deep learning. In Pro- ceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security. ACM, 603–618
work page 2017
-
[6]
Tyler Hunt, Congzheng Song, Reza Shokri, Vitaly Shmatikov, and Emmett Witchel. 2018. Chiron: Privacy-preserving Machine Learning as a Service. arXiv preprint arXiv:1803.05961 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[7]
Alex Krizhevsky and Geoffrey Hinton. 2009. Learning multiple layers of features from tiny images. Technical Report. Citeseer
work page 2009
-
[8]
Yann LeCun, Corinna Cortes, and CJ Burges. 2010. MNIST handwritten digit database. AT&T Labs [Online]. A vailable: http://yann. lecun. com/exdb/mnist 2 (2010), 18
work page 2010
-
[9]
Ian McGraw, Rohit Prabhavalkar, Raziel Alvarez, Montse Gonzalez Arenas, Kan- ishka Rao, David Rybach, Ouais Alsharif, Haşim Sak, Alexander Gruenstein, Françoise Beaufays, et al . 2016. Personalized speech recognition on mobile devices. In 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 5955–5959
work page 2016
-
[10]
Luca Melis, Congzheng Song, Emiliano De Cristofaro, and Vitaly Shmatikov
-
[11]
Exploiting unintended feature leakage in collaborative learning. IEEE
-
[12]
Vinod Nair and Geoffrey E Hinton. 2010. Rectified linear units improve re- stricted boltzmann machines. In Proceedings of the 27th international conference on machine learning (ICML-10) . 807–814
work page 2010
- [13]
-
[14]
Olga Ohrimenko, Felix Schuster, Cédric Fournet, Aastha Mehta, Sebastian Nowozin, Kapil Vaswani, and Manuel Costa. 2016. Oblivious Multi-Party Machine Learning on Trusted Processors.. In USENIX Security Symposium. 619–636
work page 2016
- [15]
-
[16]
Seyed Ali Osia, Ali Shahin Shamsabadi, Ali Taheri, Hamid R Rabiee, and Hamed Haddadi. 2018. Private and Scalable Personal Data Analytics Using Hybrid Edge-to-Cloud Deep Learning. Computer 51, 5 (2018), 42–49
work page 2018
- [17]
-
[18]
Shai Shalev-Shwartz, Ohad Shamir, Nathan Srebro, and Karthik Sridharan. 2010. Learnability, stability and uniform convergence. Journal of Machine Learning Research 11, Oct (2010), 2635–2670
work page 2010
-
[19]
Karen Simonyan and Andrew Zisserman. 2014. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556 (2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[20]
Esteban Vazquez-Fernandez and Daniel Gonzalez-Jimenez. 2016. Face recognition for authentication on mobile devices. Image and Vision Computing 55 (2016), 31–33
work page 2016
-
[21]
Han Xiao, Kashif Rasul, and Roland Vollgraf. 2017. Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms. arXiv preprint arXiv:1708.07747 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[22]
Samuel Yeom, Irene Giacomelli, Matt Fredrikson, and Somesh Jha. 2018. Privacy risk in machine learning: Analyzing the connection to overfitting. In 2018 IEEE 31st Computer Security Foundations Symposium (CSF) . IEEE, 268–282
work page 2018
-
[23]
Matthew D Zeiler and Rob Fergus. 2014. Visualizing and understanding convolu- tional networks. In European conference on computer vision . Springer, 818–833
work page 2014
-
[24]
Chiyuan Zhang, Samy Bengio, Moritz Hardt, Benjamin Recht, and Oriol Vinyals
-
[25]
InProceed- ings of the International Conference on Learning Representations (ICLR)
Understanding deep learning requires rethinking generalization. InProceed- ings of the International Conference on Learning Representations (ICLR) . Toulon, France. 5
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.