A Divide-and-Conquer Approach towards Understanding Deep Networks
Pith reviewed 2026-05-24 21:37 UTC · model grok-4.3
The pith
Replacing U-Net parts with trainable guided and Frangi filters matches performance on retinal vessel segmentation while cutting parameters by over 90 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
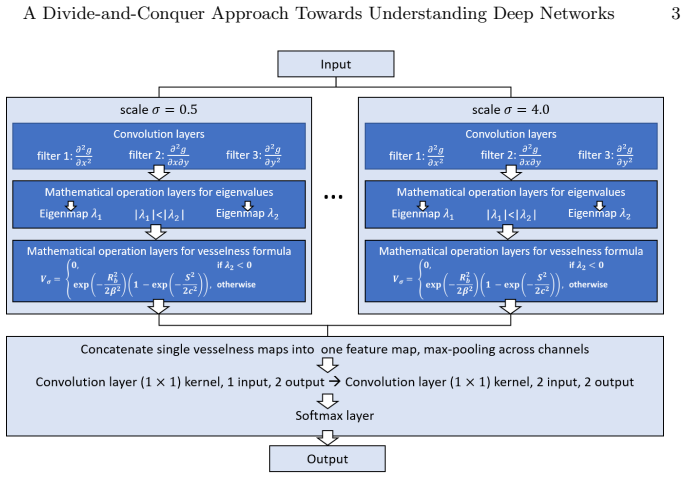
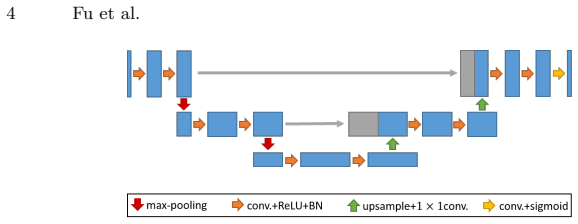
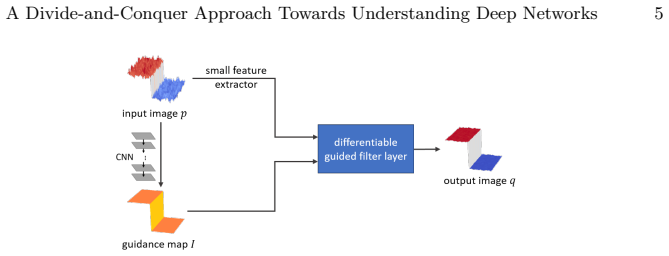
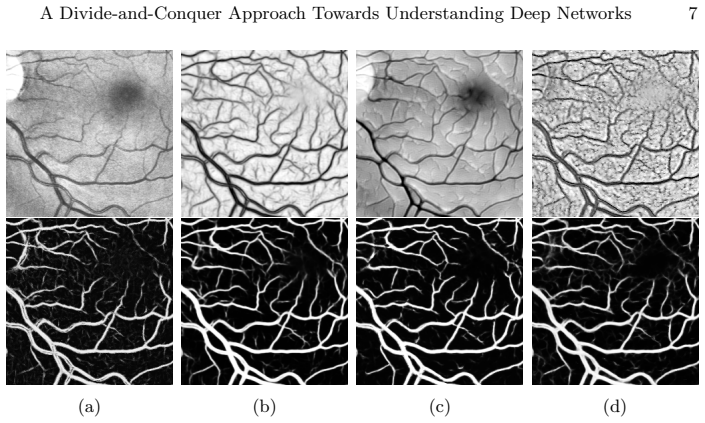
By adopting a divide-and-conquer strategy to replace network components with known operators while retaining performance, the authors demonstrate that a trainable guided filter combined with a trainable Frangi filter achieves an AUC of 0.974 compared to U-Net's 0.972 on retinal vessel segmentation, using only 9,575 parameters instead of 111,536. The trained layers map back to their original algorithmic forms and can be examined with signal processing methods.
What carries the argument
The divide-and-conquer replacement of deep network components with trainable versions of known operators such as the guided filter and Frangi filter.
If this is right
- The resulting model retains performance at the level of the original U-Net.
- Parameter count falls from 111,536 to 9,575.
- Trained layers become directly mappable to classical filter algorithms.
- The layers admit analysis with standard signal-processing tools.
Where Pith is reading between the lines
- The same replacement sequence could be tested on other segmentation tasks to check whether interpretability gains generalize.
- The approach might reveal which operator types are most responsible for accuracy in vessel detection.
- Hybrid models built this way could simplify regulatory review in medical imaging by exposing internal computations.
Load-bearing premise
Network components can be replaced with known operators without altering the essential learned function needed for the segmentation task.
What would settle it
A drop in AUC below 0.97 after full conversion to the guided-plus-Frangi model, or an inability to recover the expected filter behavior under signal-processing analysis, would falsify the claim.
Figures
read the original abstract
Deep neural networks have achieved tremendous success in various fields including medical image segmentation. However, they have long been criticized for being a black-box, in that interpretation, understanding and correcting architectures is difficult as there is no general theory for deep neural network design. Previously, precision learning was proposed to fuse deep architectures and traditional approaches. Deep networks constructed in this way benefit from the original known operator, have fewer parameters, and improved interpretability. However, they do not yield state-of-the-art performance in all applications. In this paper, we propose to analyze deep networks using known operators, by adopting a divide-and-conquer strategy to replace network components, whilst retaining its performance. The task of retinal vessel segmentation is investigated for this purpose. We start with a high-performance U-Net and show by step-by-step conversion that we are able to divide the network into modules of known operators. The results indicate that a combination of a trainable guided filter and a trainable version of the Frangi filter yields a performance at the level of U-Net (AUC 0.974 vs. 0.972) with a tremendous reduction in parameters (111,536 vs. 9,575). In addition, the trained layers can be mapped back into their original algorithmic interpretation and analyzed using standard tools of signal processing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a divide-and-conquer strategy can be used to replace components of a U-Net for retinal vessel segmentation with trainable versions of the guided filter and Frangi filter. This yields comparable performance (AUC 0.974 vs. 0.972) while reducing parameters from 111,536 to 9,575, and permits mapping the trained layers back to classical algorithmic interpretations for analysis with signal-processing tools.
Significance. If the decomposition holds without relying on task-specific alignment, the work would advance interpretability of deep networks by fusing them with known operators, offering both parameter efficiency and the ability to apply standard analysis tools. The reported numbers demonstrate a concrete instance of precision learning achieving near state-of-the-art results.
major comments (2)
- [Abstract / Results] The central claim of a general divide-and-conquer method for understanding arbitrary deep networks rests on the assumption that replacement preserves the learned function without distortion. However, the validation is performed exclusively on retinal vessel segmentation (abstract), a domain where the Frangi vesselness measure and guided filtering are already known to be effective; no experiments on unrelated tasks are reported to rule out that the AUC parity arises from this alignment rather than a broadly applicable decomposition.
- [Abstract] The step-by-step replacement process is described as retaining performance, yet the abstract provides only final AUC and parameter counts without intermediate metrics or ablation showing that each replacement step preserves the original network's function (e.g., no table of per-stage AUC values). This is load-bearing for the claim that the final model is an interpretable equivalent rather than a re-optimized task-specific architecture.
minor comments (1)
- [Abstract] The abstract states the U-Net parameter count as 111,536 and the proposed model as 9,575; clarify whether these figures represent the full architectures or only the replaced modules.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below, clarifying the scope of our claims and the presentation of results.
read point-by-point responses
-
Referee: [Abstract / Results] The central claim of a general divide-and-conquer method for understanding arbitrary deep networks rests on the assumption that replacement preserves the learned function without distortion. However, the validation is performed exclusively on retinal vessel segmentation (abstract), a domain where the Frangi vesselness measure and guided filtering are already known to be effective; no experiments on unrelated tasks are reported to rule out that the AUC parity arises from this alignment rather than a broadly applicable decomposition.
Authors: We agree that the experiments are limited to retinal vessel segmentation, a domain where the Frangi and guided filter operators are known to be effective. The manuscript explicitly frames the work as an investigation of the divide-and-conquer strategy on this task, as stated in the abstract: 'The task of retinal vessel segmentation is investigated for this purpose.' We do not claim that the specific replacement yields an undistorted equivalent for arbitrary networks or unrelated tasks; the approach is to replace components with known operators when they align with the problem. Experiments on unrelated tasks would strengthen generality claims but lie outside the current scope. We will revise the abstract to emphasize that this is a case study on a suitable task. revision: yes
-
Referee: [Abstract] The step-by-step replacement process is described as retaining performance, yet the abstract provides only final AUC and parameter counts without intermediate metrics or ablation showing that each replacement step preserves the original network's function (e.g., no table of per-stage AUC values). This is load-bearing for the claim that the final model is an interpretable equivalent rather than a re-optimized task-specific architecture.
Authors: The full manuscript describes the step-by-step replacement process and demonstrates retention of performance through the conversions. The abstract, due to length constraints, reports only the final AUC and parameter counts as a summary. The claim that the final model is an interpretable equivalent is supported by the body of the paper, where trained layers are mapped back to classical interpretations and analyzed with signal-processing tools. We do not intend to modify the abstract to include intermediate metrics. revision: no
Circularity Check
No significant circularity; performance claims rest on external AUC validation.
full rationale
The paper's central result is an empirical demonstration that successive replacement of U-Net blocks by trainable guided and Frangi operators yields AUC 0.974 vs. 0.972 on retinal vessel segmentation while reducing parameter count. This comparison is performed on held-out test data and is not obtained by fitting a parameter to the target metric and then relabeling it as a prediction. No equation equates the final performance to the input architecture by construction, no uniqueness theorem is imported from prior self-work to forbid alternatives, and the cited precision-learning framework is used only as background motivation rather than as the sole justification for the reported numbers. The derivation chain therefore remains self-contained against the external benchmark.
Axiom & Free-Parameter Ledger
free parameters (1)
- trainable parameters in guided filter and Frangi filter
axioms (1)
- domain assumption Known operators can be made trainable and substituted into deep networks without loss of performance
Reference graph
Works this paper leans on
-
[1]
In: Proc IEEE Int Conf Comput Vis
Chen, Q., Xu, J., Koltun, V.: Fast Image Processing With Fully-Convolutional Networks. In: Proc IEEE Int Conf Comput Vis. pp. 2497–2506 (2017)
work page 2017
-
[2]
Frangi, A.F., Niessen, W.J., Vincken, K.L., Viergever, M.A.: Multiscale Vessel Enhancement Filtering. In: MICCAI. pp. 130–137 (1998)
work page 1998
-
[3]
Fu, W., Breininger, K., Schaffert, R., Ravikumar, N., W¨ urfl, T., Fujimoto, J., Moult, E., Maier, A.: Frangi-Net. In: BVM, pp. 341–346 (2018)
work page 2018
-
[4]
IEEE Trans Pattern Anal Mach Intell 35(6), 1397–1409 (2013)
He, K., Sun, J., Tang, X.: Guided Image Filtering. IEEE Trans Pattern Anal Mach Intell 35(6), 1397–1409 (2013)
work page 2013
-
[5]
Adam: A Method for Stochastic Optimization
Kingma, D.P., Ba, J.: Adam: A Method for Stochastic Optimization. arXiv preprint arXiv:1412.6980 (2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[6]
LeCun, Y., Bengio, Y., Hinton, G.: Deep Learning. Nature 521(7553), 436 (2015)
work page 2015
-
[7]
In: Proc IEEE Int Conf Comput Vis
Lin, T.Y., Goyal, P., Girshick, R., He, K., Doll´ ar, P.: Focal Loss for Dense Object Detection. In: Proc IEEE Int Conf Comput Vis. pp. 2980–2988 (2017)
work page 2017
- [8]
-
[9]
arXiv preprint arXiv:1907.01992 (2019)
Maier, A.K., Syben, C., Stimpel, B., W¨ urfl, T., Hoffmann, M., Schebesch, F., Fu, W., Mill, L., Kling, L., Christiansen, S.: Learning with Known Operators Reduces Maximum Training Error Bounds. arXiv preprint arXiv:1907.01992 (2019)
-
[10]
Ronneberger, O., Fischer, P., Brox, T.: U-Net: Convolutional Networks for Biomed- ical Image Segmentation. In: MICCAI. pp. 234–241 (2015)
work page 2015
-
[11]
IEEE Trans Med Imaging 23(4), 501–509 (2004)
Staal, J., Abr` amoff, M.D., Niemeijer, M., Viergever, M.A., Van Ginneken, B.: Ridge-Based Vessel Segmentation in Color Images of the Retina. IEEE Trans Med Imaging 23(4), 501–509 (2004)
work page 2004
- [12]
-
[13]
W¨ urfl, T., Ghesu, F.C., Christlein, V., Maier, A.: Deep Learning Computed To- mography. In: MICCAI. pp. 432–440 (2016)
work page 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.