Deep Learning for Pneumothorax Detection and Localization in Chest Radiographs
Pith reviewed 2026-05-24 20:44 UTC · model grok-4.3
The pith
Three deep learning methods detect pneumothorax in chest X-rays with AUCs of 0.96, 0.93 and 0.92.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
On a dataset of 1003 chest X-ray images, convolutional neural networks achieve an AUC of 0.96, multiple-instance learning 0.93, and fully convolutional networks 0.92 for pneumothorax detection, with the approaches also demonstrating localization capabilities, and their ensemble reviewed for combined performance.
What carries the argument
The three deep learning techniques—convolutional neural networks, multiple-instance learning, and fully convolutional networks—applied to chest radiograph classification and localization.
If this is right
- Early detection of pneumothorax becomes feasible through automated analysis of chest X-rays.
- Localization of the condition can guide clinical attention to specific areas in the image.
- An ensemble approach may improve overall reliability by combining the strengths of different methods.
- Five-fold cross-validation provides a robust estimate of performance on the given dataset.
Where Pith is reading between the lines
- These methods could be integrated into radiology workflows to flag urgent cases for immediate review.
- Performance on this dataset suggests potential for reducing missed diagnoses in emergency settings.
- Further validation on diverse patient populations would be needed to confirm generalizability.
Load-bearing premise
The 1003 chest X-ray images with labels are representative of real clinical cases without significant biases in selection or annotation.
What would settle it
A test on an independent dataset of chest X-rays from different hospitals or populations yielding substantially lower AUC values would disprove the claim of reliable detection.
Figures


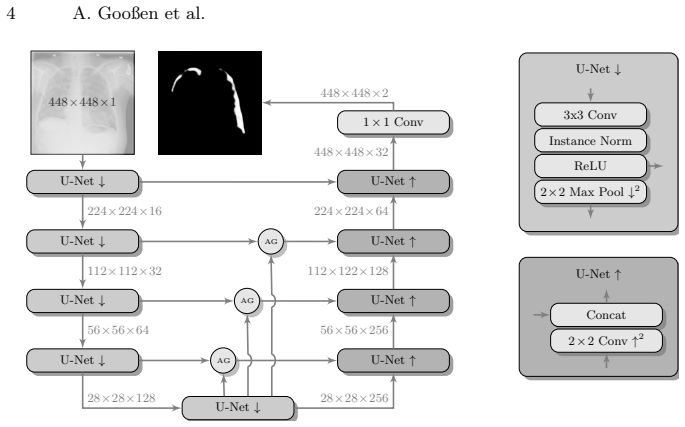


read the original abstract
Pneumothorax is a critical condition that requires timely communication and immediate action. In order to prevent significant morbidity or patient death, early detection is crucial. For the task of pneumothorax detection, we study the characteristics of three different deep learning techniques: (i) convolutional neural networks, (ii) multiple-instance learning, and (iii) fully convolutional networks. We perform a five-fold cross-validation on a dataset consisting of 1003 chest X-ray images. ROC analysis yields AUCs of 0.96, 0.93, and 0.92 for the three methods, respectively. We review the classification and localization performance of these approaches as well as an ensemble of the three aforementioned techniques.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript compares three deep learning approaches—convolutional neural networks, multiple-instance learning, and fully convolutional networks—for pneumothorax detection and localization in chest radiographs. On a dataset of 1003 images, five-fold cross-validation yields reported AUCs of 0.96, 0.93, and 0.92 respectively; the work also evaluates an ensemble and reviews both classification and localization performance.
Significance. If the performance metrics prove robust under proper independent validation, the comparative evaluation of the three architectures plus ensemble could offer practical guidance for method selection in an urgent clinical task. The explicit attention to localization performance is a strength of the empirical design.
major comments (3)
- [Dataset description (abstract and §3)] Dataset description (abstract and §3): the 1003-image collection is introduced without any information on institutional source, patient demographics, label acquisition protocol, class balance, or prevalence. This information is required to assess whether the reported AUCs can be interpreted as representative of clinical distributions.
- [Experimental protocol (§4, cross-validation paragraph)] Experimental protocol (§4, cross-validation paragraph): no statement is made on whether the five-fold splits were performed at the patient level. If multiple images per patient exist and splits are image-level, patient-specific features can leak across folds, directly undermining the independence assumption that supports the headline AUC claims of 0.96/0.93/0.92.
- [Results (§5)] Results (§5): the manuscript reports point AUC values without confidence intervals, statistical comparison between methods, or an external held-out test set. These omissions leave the relative ranking of the three methods and the ensemble unverified.
minor comments (2)
- [Abstract] The abstract would be strengthened by a single sentence summarizing dataset size, source type, and any noted limitations.
- [Methods] Notation for the three methods is introduced inconsistently between the abstract and the methods section; a single consistent abbreviation table would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and indicate the revisions we will make to improve clarity and rigor.
read point-by-point responses
-
Referee: [Dataset description (abstract and §3)] Dataset description (abstract and §3): the 1003-image collection is introduced without any information on institutional source, patient demographics, label acquisition protocol, class balance, or prevalence. This information is required to assess whether the reported AUCs can be interpreted as representative of clinical distributions.
Authors: We agree that these details are essential for contextualizing the results. In the revised manuscript we will expand the dataset description in the abstract and Section 3 to include institutional source, patient demographics, label acquisition protocol, class balance, and prevalence. revision: yes
-
Referee: [Experimental protocol (§4, cross-validation paragraph)] Experimental protocol (§4, cross-validation paragraph): no statement is made on whether the five-fold splits were performed at the patient level. If multiple images per patient exist and splits are image-level, patient-specific features can leak across folds, directly undermining the independence assumption that supports the headline AUC claims of 0.96/0.93/0.92.
Authors: We thank the referee for highlighting this critical aspect of the experimental design. The five-fold cross-validation splits were performed at the patient level to prevent leakage of patient-specific features. We will add an explicit statement to this effect in the revised Section 4. revision: yes
-
Referee: [Results (§5)] Results (§5): the manuscript reports point AUC values without confidence intervals, statistical comparison between methods, or an external held-out test set. These omissions leave the relative ranking of the three methods and the ensemble unverified.
Authors: We agree that confidence intervals and statistical comparisons would strengthen the presentation. In the revised Section 5 we will report bootstrap confidence intervals for all AUC values and include pairwise statistical comparisons. An external held-out test set was not available within the scope of this study; we will add a limitations paragraph discussing the value of future external validation. revision: partial
Circularity Check
No circularity: purely empirical performance reporting with no derivations or fitted predictions
full rationale
The paper trains three deep learning models (CNN, MIL, FCN) on a fixed dataset of 1003 images and reports AUCs from 5-fold cross-validation. No equations, first-principles derivations, parameter fitting followed by prediction, or self-citation chains are present. The central claims are direct empirical measurements of model performance on held-out folds; they do not reduce to the inputs by construction. Dataset splitting concerns affect experimental validity but are unrelated to circularity in any derivation chain.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We study the characteristics of three different deep learning techniques: (i) convolutional neural networks, (ii) multiple-instance learning, and (iii) fully convolutional networks. We perform a five-fold cross-validation on a dataset consisting of 1003 chest X-ray images. ROC analysis yields AUCs of 0.96, 0.93, and 0.92
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Comparison of Deep Learning Approaches for Multi-Label Chest X-Ray Classification
Baltruschat, I.M., Nickisch, H., Grass, M., Knopp, T., Saalbach, A.: Com- parison of deep learning approaches for multi-label chest X-ray classification. arXiv:1803.02315 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[2]
Artif Intell 89(1-2), 31–71 (1997)
Dietterich, T.G., Lathrop, R.H., Lozano-P´ erez, T.: Solving the multiple instance problem with axis-parallel rectangles. Artif Intell 89(1-2), 31–71 (1997)
work page 1997
-
[3]
Esteva, A., Kuprel, B., Novoa, R.A., Ko, J., Swetter, S.M., Blau, H.M., Thrun, S.: Dermatologist-level classification of skin cancer with deep neural networks. Nature 542(7639), 115 (2017)
work page 2017
-
[4]
JAMA 316(22), 2402–2410 (2016) Pneumothorax Detection and Localization in Chest Radiographs 9
Gulshan, V., Peng, L., Coram, M., et al.: Development and validation of a deep learning algorithm for detection of diabetic retinopathy in retinal fundus pho- tographs. JAMA 316(22), 2402–2410 (2016) Pneumothorax Detection and Localization in Chest Radiographs 9
work page 2016
-
[5]
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proc CVPR. pp. 770–778. IEEE (2016)
work page 2016
-
[6]
J Am Coll Radiol 11(6), 552–558 (2014)
Larson, P.A., Berland, L.L., Griffith, B., Kahn Jr., C.E., Liebscher, L.A.: Action- able findings and the role of IT support: report of the ACR actionable reporting work group. J Am Coll Radiol 11(6), 552–558 (2014)
work page 2014
-
[7]
Comput Biol Med 89, 135–143 (2017)
Lopes, U., Valiati, J.F.: Pre-trained convolutional neural networks as feature ex- tractors for tuberculosis detection. Comput Biol Med 89, 135–143 (2017)
work page 2017
-
[8]
Attention U-Net: Learning Where to Look for the Pancreas
Oktay, O., Schlemper, J., Folgoc, L.L., et al.: Attention U-Net: Learning where to look for the pancreas. arXiv preprint arXiv:1804.03999 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[9]
In: International Conference on Medical image computing and computer-assisted intervention
Ronneberger, O., Fischer, P., Brox, T.: U-Net: Convolutional networks for biomed- ical image segmentation. In: International Conference on Medical image computing and computer-assisted intervention. pp. 234–241. Springer (2015)
work page 2015
-
[10]
Wang, X., Peng, Y., Lu, L., et al.: ChestX-ray8: Hospital-scale chest X-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases. In: Proc CVPR. pp. 3462–3471. IEEE (2017)
work page 2017
-
[11]
IEEE T Med Imaging 35(5), 1332–1343 (2016)
Yan, Z., Zhan, Y., Peng, Z., et al.: Multi-instance deep learning: Discover discrim- inative local anatomies for bodypart recognition. IEEE T Med Imaging 35(5), 1332–1343 (2016)
work page 2016
-
[12]
Chest 141(4), 1098–1105 (2012)
Yarmus, L., Feller-Kopman, D.: Pneumothorax in the critically ill patient. Chest 141(4), 1098–1105 (2012)
work page 2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.