HONEM: Learning Embedding for Higher Order Networks
Pith reviewed 2026-05-24 16:17 UTC · model grok-4.3
The pith
HONEM learns node embeddings from higher-order networks that capture non-Markovian dependencies missed by pairwise methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
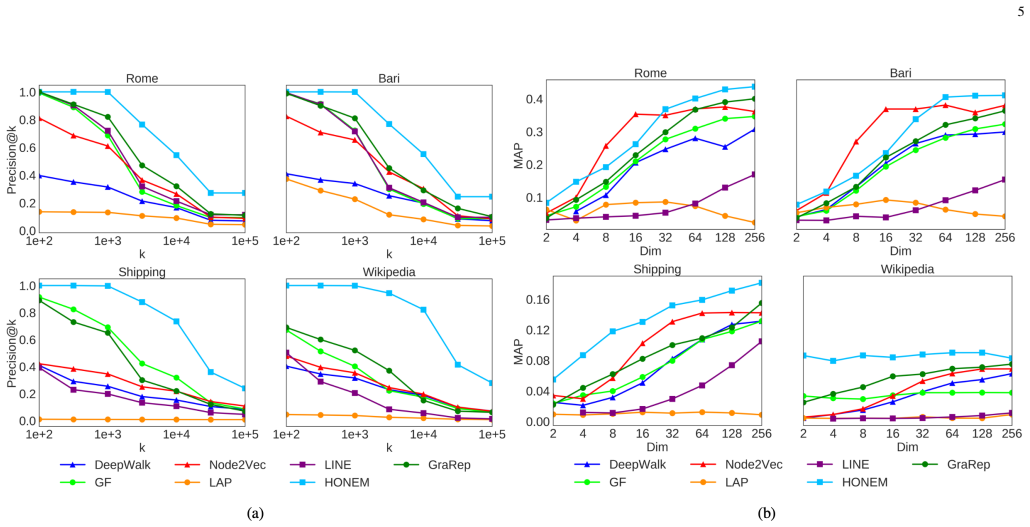
HONEM is a representation learning method built specifically for higher-order network structures; it produces node embeddings that encode non-Markovian higher-order dependencies and thereby outperforms first-order embedding methods on node classification, network reconstruction, link prediction, and visualization when the input network exhibits those dependencies.
What carries the argument
HONEM, an embedding procedure that operates directly on a higher-order network (HON) representation rather than its first-order projection.
If this is right
- Node classification accuracy rises when the embedding respects higher-order paths instead of only immediate neighbors.
- Network reconstruction error drops because the embedding preserves multi-step dependencies.
- Link prediction improves for future interactions that depend on path history.
- Visualizations separate nodes more cleanly when higher-order structure is retained in the embedding space.
Where Pith is reading between the lines
- Methods that first convert data to a first-order graph may systematically lose signal in domains where memory effects matter, suggesting a need to check higher-order structure before choosing an embedding approach.
- The same principle could extend to temporal or sequence data outside static networks, where the order of events carries predictive information.
- If higher-order networks become easier to construct, embedding pipelines may shift from generic graph methods to structure-aware ones as a default.
Load-bearing premise
A higher-order network representation can be obtained from the data and that measured gains arise specifically from modeling the non-Markovian dependencies.
What would settle it
An experiment on a network with verified non-Markovian higher-order dependencies in which HONEM shows no improvement over standard first-order embeddings on the listed tasks.
Figures





read the original abstract
Representation learning on networks offers a powerful alternative to the oft painstaking process of manual feature engineering, and as a result, has enjoyed considerable success in recent years. However, all the existing representation learning methods are based on the first-order network (FON), that is, the network that only captures the pairwise interactions between the nodes. As a result, these methods may fail to incorporate non-Markovian higher-order dependencies in the network. Thus, the embeddings that are generated may not accurately represent of the underlying phenomena in a network, resulting in inferior performance in different inductive or transductive learning tasks. To address this challenge, this paper presents HONEM, a higher-order network embedding method that captures the non-Markovian higher-order dependencies in a network. HONEM is specifically designed for the higher-order network structure (HON) and outperforms other state-of-the-art methods in node classification, network re-construction, link prediction, and visualization for networks that contain non-Markovian higher-order dependencies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HONEM, a network embedding method designed specifically for higher-order networks (HONs) that incorporate non-Markovian dependencies beyond first-order pairwise interactions. It claims that standard embedding methods fail on such networks and that HONEM outperforms state-of-the-art methods on node classification, network reconstruction, link prediction, and visualization tasks when applied to networks containing higher-order dependencies.
Significance. If the performance gains are shown to arise specifically from modeling non-Markovian higher-order structure rather than from operating on an expanded node set or different base embedding choices, the work would provide a useful extension of representation learning to path-dependent or temporal networks. The manuscript does not report machine-checked proofs or reproducible code artifacts.
major comments (3)
- [Experiments section] Experiments (likely §4 or §5): no ablation or control experiments isolate whether reported gains on the four tasks are attributable to capturing non-Markovian dependencies versus simply embedding on a larger graph produced by any HON construction; without such controls the central claim reduces to the unsurprising observation that richer input graphs can improve embedding quality.
- [Method section] Method description (likely §3): the manuscript supplies no explicit equations or pseudocode for the HONEM objective or optimization procedure, making it impossible to verify how the higher-order dependencies are encoded into the embedding loss or whether the construction is parameter-free.
- [Experimental setup] Dataset and HON construction (likely §4.1): the paper does not report how the input HONs were built from raw data, the order of dependencies retained, or any validation that the chosen networks genuinely exhibit non-Markovian behavior; this leaves open whether the performance edge is specific to the claimed phenomenon.
minor comments (2)
- [Abstract] Abstract and introduction repeat the same high-level claim without quantitative results or dataset names, reducing clarity for readers.
- [Preliminaries] Notation for first-order vs. higher-order networks is introduced but not consistently used when describing baselines.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below.
read point-by-point responses
-
Referee: [Experiments section] Experiments (likely §4 or §5): no ablation or control experiments isolate whether reported gains on the four tasks are attributable to capturing non-Markovian dependencies versus simply embedding on a larger graph produced by any HON construction; without such controls the central claim reduces to the unsurprising observation that richer input graphs can improve embedding quality.
Authors: We agree that the current experiments do not fully isolate the source of the gains. In the revision we will add control experiments that apply standard embedding methods to expanded graphs constructed without explicit non-Markovian modeling, allowing direct comparison with HONEM on the same node set. revision: yes
-
Referee: [Method section] Method description (likely §3): the manuscript supplies no explicit equations or pseudocode for the HONEM objective or optimization procedure, making it impossible to verify how the higher-order dependencies are encoded into the embedding loss or whether the construction is parameter-free.
Authors: We will insert the explicit objective function, the manner in which higher-order dependencies enter the loss, and pseudocode for the optimization procedure in the revised method section. revision: yes
-
Referee: [Experimental setup] Dataset and HON construction (likely §4.1): the paper does not report how the input HONs were built from raw data, the order of dependencies retained, or any validation that the chosen networks genuinely exhibit non-Markovian behavior; this leaves open whether the performance edge is specific to the claimed phenomenon.
Authors: Section 4.1 will be expanded to describe the HON construction pipeline, the dependency orders retained for each dataset, and supporting references or statistics confirming non-Markovian behavior. revision: yes
Circularity Check
No circularity; derivation is self-contained
full rationale
The provided abstract and summary describe HONEM as a distinct embedding construction for higher-order networks (HON) that capture non-Markovian dependencies, with performance claims on standard tasks. No equations, parameter-fitting steps, self-citations, or uniqueness theorems are shown that would reduce any claimed prediction or result to the inputs by construction. The method is presented as a new design choice rather than a renaming or self-referential fit, making the derivation chain independent of the patterns that trigger circularity flags.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
HONEM extracts the actual order of dependency from the non-Markovian interactions... by allowing for variable orders... parameter-free version... does not require setting a pre-defined Max-Order
-
IndisputableMonolith/Foundation/DimensionForcing.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
S = 1/N ∑_{k=0}^L e^{-k} D_{k+1}
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
New perspectives and methods in link prediction,
R. N. Lichtenwalter, J. T. Lussier, and N. V . Chawla, “New perspectives and methods in link prediction,” in Proceedings of the 16th ACM SIGKDD international conference on Knowledge discovery and data mining, 2010, pp. 243–252
work page 2010
-
[2]
Graph embedding techniques, applications, and performance: A survey,
P. Goyal and E. Ferrara, “Graph embedding techniques, applications, and performance: A survey,” Knowledge-Based Systems, vol. 151, pp. 78–94, 2018
work page 2018
-
[3]
A survey on network embedding,
P. Cui, X. Wang, J. Pei, and W. Zhu, “A survey on network embedding,” IEEE Transactions on Knowledge and Data Engineering , vol. 31, no. 5, pp. 833–852, 2018
work page 2018
-
[4]
From community to role-based graph embeddings,
R. A. Rossi, D. Jin, S. Kim, N. K. Ahmed, D. Koutra, and J. B. Lee, “From community to role-based graph embeddings,” arXiv preprint arXiv:1908.08572, 2019
-
[5]
node2vec: Scalable feature learning for networks,
A. Grover and J. Leskovec, “node2vec: Scalable feature learning for networks,” in Proceedings of the 22nd ACM SIGKDD international conference on Knowledge discovery and data mining . ACM, 2016, pp. 855–864
work page 2016
-
[6]
Line: Large-scale information network embedding,
J. Tang, M. Qu, M. Wang, M. Zhang, J. Yan, and Q. Mei, “Line: Large-scale information network embedding,” in Proceedings of the 24th International Conference on World Wide Web. International World Wide Web Conferences Steering Committee, 2015, pp. 1067–1077
work page 2015
-
[7]
Arbitrary-order proximity preserved network embedding,
Z. Zhang, P. Cui, X. Wang, J. Pei, X. Yao, and W. Zhu, “Arbitrary-order proximity preserved network embedding,” in Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. ACM, 2018, pp. 2778–2786
work page 2018
-
[8]
Asymmetric transitivity preserving graph embedding,
M. Ou, P. Cui, J. Pei, Z. Zhang, and W. Zhu, “Asymmetric transitivity preserving graph embedding,” in Proceedings of the 22nd ACM SIGKDD international conference on Knowledge discovery and data mining . ACM, 2016, pp. 1105–1114
work page 2016
-
[9]
Higher-order network representation learning,
R. A. Rossi, N. K. Ahmed, and E. Koh, “Higher-order network representation learning,” in Companion of the The Web Conference 2018 on The Web Conference 2018 . International World Wide Web Conferences Steering Committee, 2018, pp. 3–4
work page 2018
-
[10]
Representing higher-order dependencies in networks,
J. Xu, T. L. Wickramarathne, and N. V . Chawla, “Representing higher-order dependencies in networks,” Science advances, vol. 2, no. 5, p. e1600028, 2016. [Online]. Available: https://github.com/xyjprc/hon
work page 2016
-
[11]
Memory in network flows and its effects on spreading dynamics and community detection,
M. Rosvall, A. V . Esquivel, A. Lancichinetti, J. D. West, and R. Lam- biotte, “Memory in network flows and its effects on spreading dynamics and community detection,” Nature communications, vol. 5, 2014
work page 2014
-
[12]
Higher-order organization of complex networks,
A. R. Benson, D. F. Gleich, and J. Leskovec, “Higher-order organization of complex networks,” Science, vol. 353, no. 6295, pp. 163–166, 2016
work page 2016
-
[13]
Tensor spectral clustering for partitioning higher-order network structures,
——, “Tensor spectral clustering for partitioning higher-order network structures,” in Proceedings of the 2015 SIAM International Conference on Data Mining . SIAM, 2015, pp. 118–126
work page 2015
-
[14]
A local algorithm for structure-preserving graph cut,
D. Zhou, S. Zhang, M. Y . Yildirim, S. Alcorn, H. Tong, H. Davulcu, and J. He, “A local algorithm for structure-preserving graph cut,” in Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , 2017, pp. 655–664
work page 2017
-
[15]
Motif-preserving dynamic local graph cut,
D. Zhou, J. He, H. Davulcu, and R. Maciejewski, “Motif-preserving dynamic local graph cut,” in 2018 IEEE International Conference on Big Data (Big Data) . IEEE, 2018, pp. 1156–1161. 10
work page 2018
-
[16]
I. Scholtes, N. Wider, and A. Garas, “Higher-order aggregate networks in the analysis of temporal networks: path structures and centralities,” The European Physical Journal B , vol. 89, no. 3, p. 61, 2016
work page 2016
-
[17]
Causality-driven slow-down and speed-up of diffusion in non-markovian temporal networks,
I. Scholtes, N. Wider, R. Pfitzner, A. Garas, C. J. Tessone, and F. Schweitzer, “Causality-driven slow-down and speed-up of diffusion in non-markovian temporal networks,” Nature communications, vol. 5, p. 5024, 2014
work page 2014
-
[18]
Higher-order patterns of aquatic species spread through the global shipping network,
M. Saebi, J. Xu, E. K. Grey, D. M. Lodge, and N. Chawla, “Higher-order patterns of aquatic species spread through the global shipping network,” BioRxiv, p. 704684, 2019
work page 2019
-
[19]
Detecting anomalies in sequential data with higher-order networks,
J. Xu, M. Saebi, B. Ribeiro, L. M. Kaplan, and N. V . Chawla, “Detecting anomalies in sequential data with higher-order networks,” arXiv preprint arXiv:1712.09658, 2017
-
[20]
I. Scholtes, “When is a network a network?: Multi-order graphical model selection in pathways and temporal networks,” in Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining . ACM, 2017, pp. 1037–1046
work page 2017
-
[21]
Understanding Complex Systems: From Networks to Optimal Higher-Order Models
R. Lambiotte, M. Rosvall, and I. Scholtes, “Understanding complex systems: From networks to optimal higher-order models,” arXiv preprint arXiv:1806.05977, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[22]
Grarep: Learning graph representations with global structural information,
S. Cao, W. Lu, and Q. Xu, “Grarep: Learning graph representations with global structural information,” in Proceedings of the 24th ACM International on Conference on Information and Knowledge Management. ACM, 2015, pp. 891–900
work page 2015
-
[23]
On information and sufficiency,
S. Kullback and R. A. Leibler, “On information and sufficiency,” The annals of mathematical statistics , vol. 22, no. 1, pp. 79–86, 1951
work page 1951
-
[24]
Deepwalk: Online learning of social representations,
B. Perozzi, R. Al-Rfou, and S. Skiena, “Deepwalk: Online learning of social representations,” in Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining . ACM, 2014, pp. 701–710
work page 2014
-
[25]
The approximation of one matrix by another of lower rank,
C. Eckart and G. Young, “The approximation of one matrix by another of lower rank,” Psychometrika, vol. 1, no. 3, pp. 211–218, 1936
work page 1936
-
[26]
Human wayfinding in information networks,
R. West and J. Leskovec, “Human wayfinding in information networks,” in Proceedings of the 21st international conference on World Wide Web . ACM, 2012, pp. 619–628
work page 2012
-
[27]
Distributed large-scale natural graph factorization,
A. Ahmed, N. Shervashidze, S. Narayanamurthy, V . Josifovski, and A. J. Smola, “Distributed large-scale natural graph factorization,” in Proceedings of the 22nd international conference on World Wide Web . ACM, 2013, pp. 37–48
work page 2013
-
[28]
Laplacian eigenmaps for dimensionality reduction and data representation,
M. Belkin and P. Niyogi, “Laplacian eigenmaps for dimensionality reduction and data representation,” Neural computation, vol. 15, no. 6, pp. 1373–1396, 2003
work page 2003
-
[29]
L. v. d. Maaten and G. Hinton, “Visualizing data using t-sne,” Journal of machine learning research , vol. 9, no. Nov, pp. 2579–2605, 2008
work page 2008
-
[30]
Motif-based communities in complex networks,
A. Arenas, A. Fernandez, S. Fortunato, and S. Gomez, “Motif-based communities in complex networks,” Journal of Physics A: Mathematical and Theoretical, vol. 41, no. 22, p. 224001, 2008
work page 2008
-
[31]
Topological strata of weighted complex networks,
G. Petri, M. Scolamiero, I. Donato, and F. Vaccarino, “Topological strata of weighted complex networks,” PloS one , vol. 8, no. 6, p. e66506, 2013
work page 2013
-
[32]
M. Kivel¨a, A. Arenas, M. Barthelemy, J. P. Gleeson, Y . Moreno, and M. A. Porter, “Multilayer networks,” Journal of complex networks, vol. 2, no. 3, pp. 203–271, 2014
work page 2014
-
[33]
The physics of spreading processes in multilayer networks,
M. De Domenico, C. Granell, M. A. Porter, and A. Arenas, “The physics of spreading processes in multilayer networks,” Nature Physics, vol. 12, no. 10, p. 901, 2016
work page 2016
-
[34]
Nonlinear dimensionality reduction by locally linear embedding,
S. T. Roweis and L. K. Saul, “Nonlinear dimensionality reduction by locally linear embedding,” science, vol. 290, no. 5500, pp. 2323–2326, 2000
work page 2000
-
[35]
S. Wold, K. Esbensen, and P. Geladi, “Principal component analysis,” Chemometrics and intelligent laboratory systems , vol. 2, no. 1-3, pp. 37–52, 1987
work page 1987
-
[36]
J. B. Kruskal and M. Wish, “Multidimensional scaling. number 07–011 in sage university paper series on quantitative applications in the social sciences,” 1978
work page 1978
-
[37]
Dis- tributed representations of words and phrases and their compositionality,
T. Mikolov, I. Sutskever, K. Chen, G. S. Corrado, and J. Dean, “Dis- tributed representations of words and phrases and their compositionality,” in Advances in neural information processing systems , 2013, pp. 3111– 3119
work page 2013
-
[38]
MOHONE: Modeling Higher Order Network Effects in KnowledgeGraphs via Network Infused Embeddings
H. Yu, V . Kulkarni, and W. Wang, “Mohone: Modeling higher order network effects in knowledgegraphs via network infused embeddings,” arXiv preprint arXiv:1811.00198 , 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[39]
role2vec: Role-based network embeddings,
N. K. Ahmed, R. A. Rossi, J. B. Lee, T. L. Willke, R. Zhou, X. Kong, and H. Eldardiry, “role2vec: Role-based network embeddings,” in Proc. DLG KDD, 2019
work page 2019
-
[40]
Don't Walk, Skip! Online Learning of Multi-scale Network Embeddings
B. Perozzi, V . Kulkarni, and S. Skiena, “Walklets: Multiscale graph embeddings for interpretable network classification,” arXiv preprint arXiv:1605.02115, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[41]
Network embedding as matrix factorization: Unifying deepwalk, line, pte, and node2vec,
J. Qiu, Y . Dong, H. Ma, J. Li, K. Wang, and J. Tang, “Network embedding as matrix factorization: Unifying deepwalk, line, pte, and node2vec,” in Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining . ACM, 2018, pp. 459–467
work page 2018
-
[42]
Pte: Predictive text embedding through large-scale heterogeneous text networks,
J. Tang, M. Qu, and Q. Mei, “Pte: Predictive text embedding through large-scale heterogeneous text networks,” in Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 2015, pp. 1165–1174
work page 2015
-
[43]
Motif-based Convolutional Neural Network on Graphs
A. Sankar, X. Zhang, and K. C.-C. Chang, “Motif-based convolutional neural network on graphs,” arXiv preprint arXiv:1711.05697 , 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[44]
struc2vec: Learning node representations from structural identity,
L. F. Ribeiro, P. H. Saverese, and D. R. Figueiredo, “struc2vec: Learning node representations from structural identity,” in Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , 2017, pp. 385–394
work page 2017
-
[45]
Inductive representation learning on large graphs,
W. Hamilton, Z. Ying, and J. Leskovec, “Inductive representation learning on large graphs,” in Advances in neural information processing systems , 2017, pp. 1024–1034
work page 2017
-
[46]
Structural deep network embedding,
D. Wang, P. Cui, and W. Zhu, “Structural deep network embedding,” in Proceedings of the 22nd ACM SIGKDD international conference on Knowledge discovery and data mining . ACM, 2016, pp. 1225–1234
work page 2016
-
[47]
Deep neural networks for learning graph representations
S. Cao, W. Lu, and Q. Xu, “Deep neural networks for learning graph representations.” in AAAI, 2016, pp. 1145–1152
work page 2016
-
[48]
Semi-Supervised Classification with Graph Convolutional Networks
T. N. Kipf and M. Welling, “Semi-supervised classification with graph convolutional networks,” arXiv preprint arXiv:1609.02907 , 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[49]
Deep Convolutional Networks on Graph-Structured Data
M. Henaff, J. Bruna, and Y . LeCun, “Deep convolutional networks on graph-structured data,” arXiv preprint arXiv:1506.05163 , 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[50]
Gated Graph Sequence Neural Networks
Y . Li, D. Tarlow, M. Brockschmidt, and R. Zemel, “Gated graph sequence neural networks,” arXiv preprint arXiv:1511.05493 , 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[51]
Depthlgp: Learning embeddings of out-of- sample nodes in dynamic networks
J. Ma, P. Cui, and W. Zhu, “Depthlgp: Learning embeddings of out-of- sample nodes in dynamic networks.” AAAI, 2018
work page 2018
-
[52]
Local higher- order graph clustering,
H. Yin, A. R. Benson, J. Leskovec, and D. F. Gleich, “Local higher- order graph clustering,” in Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining . ACM, 2017, pp. 555–564
work page 2017
-
[53]
Embedding temporal network via neighborhood formation,
Y . Zuo, G. Liu, H. Lin, J. Guo, X. Hu, and J. Wu, “Embedding temporal network via neighborhood formation,” in Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. ACM, 2018, pp. 2857–2866
work page 2018
-
[54]
Dynamic network embedding by modeling triadic closure process
L.-k. Zhou, Y . Yang, X. Ren, F. Wu, and Y . Zhuang, “Dynamic network embedding by modeling triadic closure process.” in AAAI, 2018
work page 2018
-
[55]
Dysat: Deep neural representation learning on dynamic graphs via self-attention networks,
A. Sankar, Y . Wu, L. Gou, W. Zhang, and H. Yang, “Dysat: Deep neural representation learning on dynamic graphs via self-attention networks,” in Proceedings of the 13th International Conference on Web Search and Data Mining, 2020, pp. 519–527
work page 2020
-
[56]
Learning dynamic embeddings from temporal interaction networks,
S. Kumar, X. Zhang, and J. Leskovec, “Learning dynamic embeddings from temporal interaction networks,” Learning, vol. 17, p. 29, 2018
work page 2018
-
[57]
Dynamic network embeddings: From random walks to temporal random walks,
G. H. Nguyen, J. B. Lee, R. A. Rossi, N. K. Ahmed, E. Koh, and S. Kim, “Dynamic network embeddings: From random walks to temporal random walks,” in 2018 IEEE International Conference on Big Data (Big Data) . IEEE, 2018, pp. 1085–1092. 11 1st-order 2nd-order 3rd-order (1) Observations A− →C :2 A|E− →C :1 A|E.D− →C :1 B− →C :1 B|D− →C :1 B|D.C− →C :1 C− →D ...
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.