Learning from Own Solutions: Self-Conditioned Credit Assignment for Reinforcement Learning with Verifiable Rewards
Pith reviewed 2026-06-26 21:50 UTC · model grok-4.3
The pith
Conditioning LLMs on their own verified trajectories creates per-token KL divergences that improve credit assignment in GRPO.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
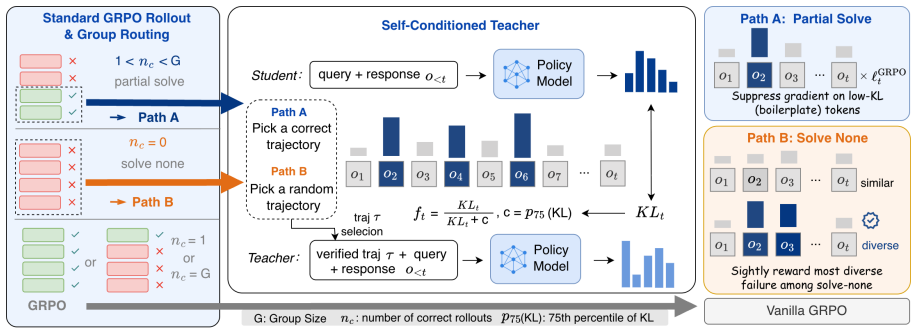
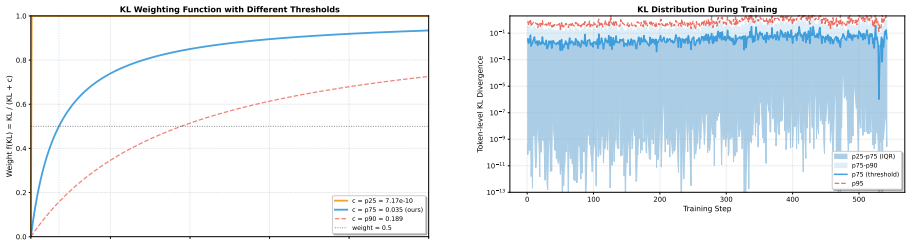
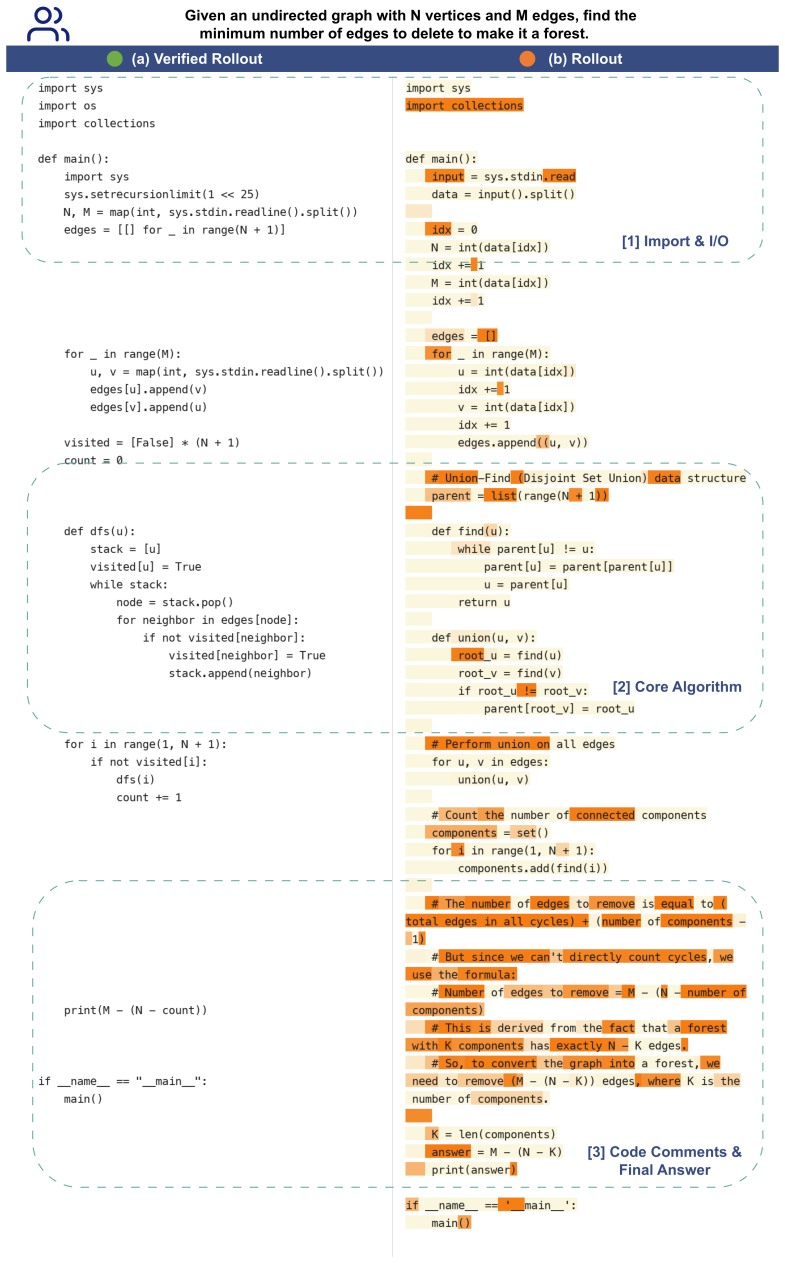
The authors prove that distilling from a self-teacher of verified trajectories leads to infeasible weighted-average solutions when multiple verified trajectories exist, and propose using the induced per-token KL divergence as a multiplicative weight on the GRPO objective to achieve effective token-level credit assignment in the pure RLVR setting.
What carries the argument
Self-conditioned per-token KL divergence used as multiplicative weight on GRPO gradients.
If this is right
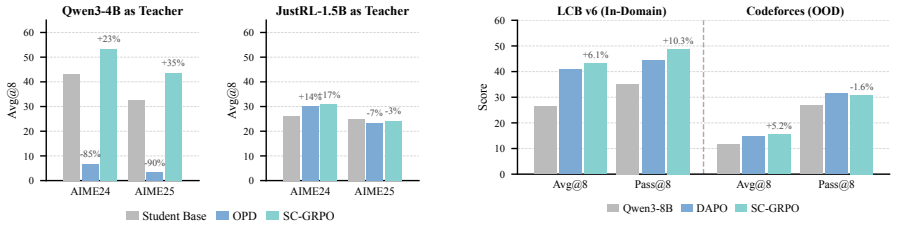
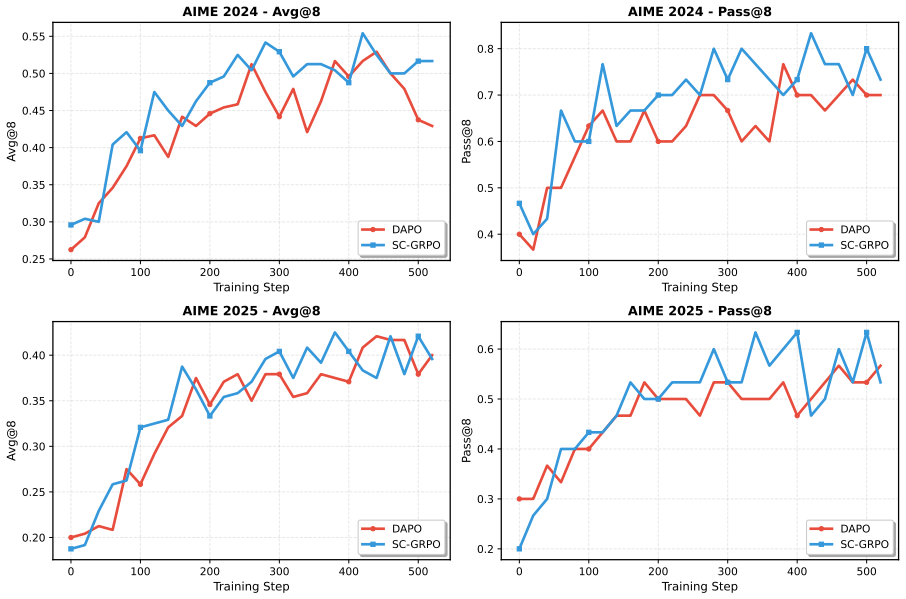
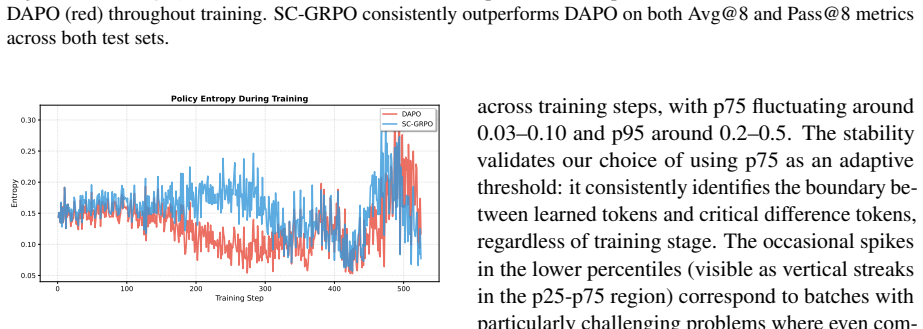
- SC-GRPO outperforms GRPO by 8.1% and DAPO by 5.9% across five benchmarks.
- SC-GRPO exhibits stronger out-of-distribution performance than baselines.
- SC-GRPO achieves higher performance than On-Policy Distillation.
- It operates without requiring external resources beyond the model's own rollouts.
Where Pith is reading between the lines
- The weighting mechanism might extend to other policy gradient methods in RLVR.
- Self-generated conditioning signals could reduce reliance on human-annotated or model-trained reward models in reasoning tasks.
- Testing on larger models or different verifiable reward structures would reveal if the KL weighting scales.
Load-bearing premise
The per-token KL divergence from conditioning on verified trajectories provides an unbiased and effective multiplicative weight without introducing new optimization problems.
What would settle it
If experiments show that SC-GRPO performs no better than or worse than standard GRPO, or if the weighting leads to unstable training, the central claim would be falsified.
Figures

read the original abstract
Reinforcement learning with verifiable rewards (RLVR) has driven substantial progress in training LLMs for reasoning tasks, but representative methods such as GRPO assign uniform credit across all tokens, wasting gradient on routine tokens while under-crediting pivotal reasoning steps. Existing token-level credit assignment methods require resources beyond the model's own rollouts. GRPO variants rely on process reward models or ground-truth answers. Knowledge distillation assigns credit through per-token divergence but requires external teachers (On-Policy Distillation) or privileged information (On-Policy Self Distillation). However, these dependencies limit applicability in the pure RLVR setting. We observe that conditioning the model on its own verified trajectories induces a measurable per-token KL divergence between the original and conditioned distributions, and prove that distilling from a self-teacher constructed by verified trajectories leads to infeasible weighted-average solutions when multiple verified trajectories exist. We propose SC-GRPO (Self-Conditioned GRPO), which uses KL divergence mentioned before as a multiplicative weight on GRPO gradients. Across five benchmarks spanning math, code, and agentic tasks, SC-GRPO consistently outperforms 8.1% over GRPO and 5.9% over DAPO with stronger OOD performance. Moreover, SC-GRPO achieves higher performance than OPD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that conditioning an LLM on its own verified trajectories induces a per-token KL divergence that can be used as a multiplicative weight in the GRPO objective to achieve token-level credit assignment in RLVR without external teachers. It proves that self-distillation from verified trajectories yields infeasible weighted-average solutions when multiple trajectories exist, proposes SC-GRPO using this KL weight, and reports consistent gains of 8.1% over GRPO and 5.9% over DAPO across five benchmarks with stronger OOD performance.
Significance. If the KL weighting is shown to be theoretically justified and free of the averaging pathology identified in the self-distillation proof, the result would be significant: it would supply a purely internal mechanism for non-uniform credit assignment in verifiable-reward RL that outperforms uniform baselines and external-distillation methods while remaining applicable in the pure RLVR setting. The explicit infeasibility proof for self-distillation is a positive contribution that clarifies limitations of related approaches.
major comments (2)
- [Abstract and SC-GRPO description] Abstract / method proposal: the manuscript proves that distilling from a self-teacher on verified trajectories produces infeasible weighted-average solutions when multiple verified trajectories exist, yet introduces the induced per-token KL as a multiplicative weight on GRPO gradients without a derivation showing why this weighting avoids the same infeasibility or constitutes an unbiased estimator of token importance. This assumption is load-bearing for the central claim that SC-GRPO supplies effective credit assignment.
- [Results and benchmarks] Empirical section: the reported 8.1% and 5.9% gains are presented without accompanying details on the number of independent runs, statistical significance tests, or controls for trajectory-length variation that could systematically affect the magnitude of the per-token KL weights.
minor comments (1)
- The abstract states that SC-GRPO 'achieves higher performance than OPD' but does not specify whether OPD results are re-implemented under identical conditions or taken from prior work; clarify the comparison protocol.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the value of the infeasibility proof. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and SC-GRPO description] Abstract / method proposal: the manuscript proves that distilling from a self-teacher on verified trajectories produces infeasible weighted-average solutions when multiple verified trajectories exist, yet introduces the induced per-token KL as a multiplicative weight on GRPO gradients without a derivation showing why this weighting avoids the same infeasibility or constitutes an unbiased estimator of token importance. This assumption is load-bearing for the central claim that SC-GRPO supplies effective credit assignment.
Authors: The infeasibility result applies specifically to self-distillation methods that construct a target distribution via weighted averaging across multiple verified trajectories, which can fall outside the support of the base model. SC-GRPO does not perform distillation or construct such an averaged target; the per-token KL is instead used solely as a multiplicative scalar on the existing GRPO policy gradient. This modulates credit without altering the optimization target. We agree that the current manuscript would benefit from an explicit derivation or expanded motivation section clarifying this distinction and the rationale for the weighting. We will add this material in revision. revision: partial
-
Referee: [Results and benchmarks] Empirical section: the reported 8.1% and 5.9% gains are presented without accompanying details on the number of independent runs, statistical significance tests, or controls for trajectory-length variation that could systematically affect the magnitude of the per-token KL weights.
Authors: We will expand the experimental section to report all results as means and standard deviations over three independent random seeds, include paired statistical significance tests against the baselines, and add a dedicated analysis of trajectory-length effects. This analysis will either normalize the KL weights by sequence length or evaluate performance on length-matched trajectory subsets to confirm that reported gains are not driven by length variation. revision: yes
Circularity Check
No significant circularity detected; derivation remains self-contained.
full rationale
The paper generates the per-token KL divergence directly from conditioning on its own verified rollouts inside each training iteration and applies it as a multiplier inside the existing GRPO objective. No equation is presented in which this multiplier is defined in terms of the target performance metric or fitted to the same data it is later claimed to predict. The separate mathematical observation that self-distillation yields infeasible averages when multiple verified trajectories exist is not used to justify the weighting scheme via self-citation; the weighting is introduced as an independent design choice whose effectiveness is evaluated empirically on external benchmarks. No self-citation chain, ansatz smuggling, or renaming of a known result is required for the central claim. The reported gains over GRPO and DAPO therefore rest on independent experimental outcomes rather than reducing to the inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Conditioning the model on its own verified trajectories induces a per-token KL divergence that can be used as a credit weight.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:1503.02531 , year=
Distilling the knowledge in a neural network , author=. arXiv preprint arXiv:1503.02531 , year=
-
[2]
The twelfth international conference on learning representations , year=
On-policy distillation of language models: Learning from self-generated mistakes , author=. The twelfth international conference on learning representations , year=
-
[3]
The Thirteenth International Conference on Learning Representations , year=
MiniPLM: Knowledge Distillation for Pre-training Language Models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[4]
Forty-first International Conference on Machine Learning , year=
DistiLLM: Towards Streamlined Distillation for Large Language Models , author=. Forty-first International Conference on Machine Learning , year=
-
[5]
arXiv preprint arXiv:2601.20802 , year=
Reinforcement Learning via Self-Distillation , author=. arXiv preprint arXiv:2601.20802 , year=
-
[6]
arXiv preprint arXiv:2601.18734 , year=
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models , author=. arXiv preprint arXiv:2601.18734 , year=
-
[7]
2026 , eprint=
Demystifying OPD: Length Inflation and Stabilization Strategies for Large Language Models , author=. 2026 , eprint=
2026
-
[8]
2026 , eprint=
Self-Distillation Enables Continual Learning , author=. 2026 , eprint=
2026
-
[9]
arXiv preprint arXiv:2603.23871 , year=
HDPO: Hybrid Distillation Policy Optimization via Privileged Self-Distillation , author=. arXiv preprint arXiv:2603.23871 , year=
-
[10]
arXiv preprint arXiv:2603.25562 , year=
Revisiting On-Policy Distillation: Empirical Failure Modes and Simple Fixes , author=. arXiv preprint arXiv:2603.25562 , year=
-
[11]
arXiv preprint arXiv:2603.24472 , year=
Why Does Self-Distillation (Sometimes) Degrade the Reasoning Capability of LLMs? , author=. arXiv preprint arXiv:2603.24472 , year=
-
[12]
Advances in Neural Information Processing Systems , volume=
Dapo: An open-source llm reinforcement learning system at scale , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
International Conference on Learning Representations , volume=
Livecodebench: Holistic and contamination free evaluation of large language models for code , author=. International Conference on Learning Representations , volume=
-
[14]
Advances in Neural Information Processing Systems , volume=
Webshop: Towards scalable real-world web interaction with grounded language agents , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Appworld: A controllable world of apps and people for benchmarking interactive coding agents , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[16]
Guo, Daya and Yang, Dejian and Zhang, Haowei and Song, Junxiao and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Zhang, Ruoyu and Ma, Shirong and Bi, Xiao and Zhang, Xiaokang and Yu, Xingkai and Wu, Yu and Wu, Z. F. and Gou, Zhibin and Shao, Zhihong and Li, Zhuoshu and Gao, Ziyi and Liu, Aixin and Xue, Bing and Wang, Bingxuan and Wu, Bochao and Feng, Bei ...
-
[17]
DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence , author=
-
[18]
arXiv preprint arXiv:2510.14967 , year=
Information Gain-based Policy Optimization: A Simple and Effective Approach for Multi-Turn LLM Agents , author=. arXiv preprint arXiv:2510.14967 , year=
-
[19]
arXiv preprint arXiv:2502.01456 , year=
Process reinforcement through implicit rewards , author=. arXiv preprint arXiv:2502.01456 , year=
-
[20]
arXiv preprint arXiv:2604.11056 , year=
Rethinking Token-Level Credit Assignment in RLVR: A Polarity-Entropy Analysis , author=. arXiv preprint arXiv:2604.11056 , year=
-
[21]
arXiv preprint arXiv:2510.10649 , year=
Unlocking exploration in rlvr: Uncertainty-aware advantage shaping for deeper reasoning , author=. arXiv preprint arXiv:2510.10649 , year=
-
[22]
arXiv preprint arXiv:2507.19849 , year=
Agentic reinforced policy optimization , author=. arXiv preprint arXiv:2507.19849 , year=
-
[23]
arXiv preprint arXiv:2410.15115 , year=
On designing effective rl reward at training time for llm reasoning , author=. arXiv preprint arXiv:2410.15115 , year=
-
[24]
arXiv preprint arXiv:2511.22888 , year=
Adversarial Training for Process Reward Models , author=. arXiv preprint arXiv:2511.22888 , year=
-
[25]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Math-shepherd: Verify and reinforce llms step-by-step without human annotations , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[26]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Incorporating Self-Rewriting into Large Language Model Reasoning Reinforcement , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[27]
2025 , eprint=
REINFORCE++: Stabilizing Critic-Free Policy Optimization with Global Advantage Normalization , author=. 2025 , eprint=
2025
-
[28]
2026 , eprint=
Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe , author=. 2026 , eprint=
2026
-
[29]
arXiv preprint arXiv:2512.16649 , year=
Justrl: Scaling a 1.5 b llm with a simple rl recipe , author=. arXiv preprint arXiv:2512.16649 , year=
-
[30]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[31]
2026 , eprint=
Self-Distilled RLVR , author=. 2026 , eprint=
2026
-
[32]
2023 , eprint=
Let's Verify Step by Step , author=. 2023 , eprint=
2023
-
[33]
rStar-Math: Small LLMs Can Master Math Reasoning with Self-Evolved Deep Thinking , author=
-
[34]
Advances in Neural Information Processing Systems , volume=
Segment policy optimization: Effective segment-level credit assignment in rl for large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[35]
International Conference on Machine Learning , pages=
ABKD: Pursuing a Proper Allocation of the Probability Mass in Knowledge Distillation via - -Divergence , author=. International Conference on Machine Learning , pages=. 2025 , organization=
2025
-
[36]
TAID: Temporally Adaptive Interpolated Distillation for Efficient Knowledge Transfer in Language Models , author=
-
[37]
EMNLP , year=
Interpretable Preferences via Multi-Objective Reward Modeling and Mixture-of-Experts , author=. EMNLP , year=
-
[38]
Understanding R1-Zero-Like Training: A Critical Perspective , author=
-
[39]
arXiv preprint arXiv:2507.18071 , year=
Group sequence policy optimization , author=. arXiv preprint arXiv:2507.18071 , year=
-
[40]
2026 , eprint=
Search-R2: Enhancing Search-Integrated Reasoning via Actor-Refiner Collaboration , author=. 2026 , eprint=
2026
-
[41]
2025 , eprint=
Acting Less is Reasoning More! Teaching Model to Act Efficiently , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.