Bayesian Reasoning for Physics Informed Neural Networks
Pith reviewed 2026-05-24 08:02 UTC · model grok-4.3
The pith
A Laplace approximation enables automatic optimization of loss weights in Bayesian physics-informed neural networks by computing model evidence analytically without sampling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce an evidence-driven Bayesian formulation of physics-informed neural networks that enables automatic optimization of loss weights between PDE residuals, boundary conditions, and observational data. Unlike existing Bayesian PINN approaches based on sampling or variational inference, the proposed method uses a Laplace approximation to compute model evidence analytically, enabling efficient hyperparameter tuning and model comparison without posterior sampling. We demonstrate the method on the heat, wave, and Burgers' equations, obtaining solutions in agreement with exact or reference results. In the Burgers' equation example, we further show that the framework naturally integrates信息从
What carries the argument
Laplace approximation to the posterior mode, used to obtain an analytic expression for the marginal likelihood (model evidence) that drives loss-weight selection.
If this is right
- Loss weights between physics residuals and data terms are chosen automatically rather than by manual search.
- Different PINN models or physics assumptions can be ranked by their computed evidence values.
- Predictive uncertainty estimates become available within the same training procedure that fits the network.
- Noisy measurements are incorporated directly alongside the governing equations without separate regularization schedules.
Where Pith is reading between the lines
- The analytic evidence may allow rapid iteration over network architectures or PDE formulations that would be expensive to compare with sampling-based methods.
- If the Laplace approximation remains reliable for deeper networks or higher-dimensional PDEs, the method could extend to inverse problems where both parameters and loss weights must be inferred.
- The framework supplies a concrete route to compare a physics-informed model against a purely data-driven one on the same evidence scale.
Load-bearing premise
The Laplace approximation around the posterior mode yields a sufficiently accurate estimate of the marginal likelihood for the purpose of loss-weight selection in PINN training.
What would settle it
A side-by-side run on the same PDE problems in which the loss weights chosen by the Laplace evidence produce solutions whose error or uncertainty calibration differs substantially from weights obtained by full MCMC sampling or by cross-validation.
Figures










read the original abstract
We introduce an evidence-driven Bayesian formulation of physics-informed neural networks that enables automatic optimization of loss weights between PDE residuals, boundary conditions, and observational data. Unlike existing Bayesian PINN approaches based on sampling or variational inference, the proposed method uses a Laplace approximation to compute model evidence analytically, enabling efficient hyperparameter tuning and model comparison without posterior sampling. We demonstrate the method on the heat, wave, and Burgers' equations, obtaining solutions in agreement with exact or reference results. In the Burgers' equation example, we further show that the framework naturally integrates information from governing equations and noisy measurements, providing predictive uncertainties within a unified Bayesian setting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces an evidence-driven Bayesian formulation of physics-informed neural networks (PINNs) that uses a Laplace approximation to compute the model evidence analytically. This enables automatic optimization of loss weights balancing PDE residuals, boundary conditions, and observational data, without requiring posterior sampling or variational inference. The approach is demonstrated on the heat, wave, and Burgers' equations, where solutions agree with exact or reference results, and uncertainties are produced in a unified setting that integrates governing equations with noisy measurements.
Significance. If the Laplace approximation proves sufficiently accurate for the non-convex PINN posteriors, the method would offer an efficient alternative to sampling-based Bayesian PINNs for hyperparameter tuning and model comparison. The analytic evidence computation is a clear strength, as is the unified treatment of physics residuals and data in the Burgers' example. However, the absence of quantitative error metrics, ablation studies on the approximation, and comparisons to existing weight-tuning heuristics limits the immediate impact.
major comments (3)
- [Method section (Laplace approximation derivation)] The central claim that the Laplace approximation yields a reliable analytic marginal likelihood for loss-weight selection rests on the assumption that the posterior over network weights is locally quadratic and unimodal. No verification of this is provided (e.g., no check that the Hessian at the MAP estimate is positive definite or that negative eigenvalues are absent), which is load-bearing for the automatic optimization procedure.
- [Numerical experiments (heat, wave, Burgers' sections)] Results on the three PDEs report only qualitative agreement with exact/reference solutions. No quantitative metrics (L2 errors, relative errors, or convergence rates) are supplied, nor is there an ablation on how the evidence-based weights compare to manual or heuristic tuning.
- [Experiments and discussion] No comparison is made to existing Bayesian PINN approaches (sampling or VI) or to standard loss-weight heuristics, leaving open whether the analytic evidence computation improves upon prior methods in practice.
minor comments (2)
- [Method] Notation for the loss weights and evidence terms could be clarified with explicit definitions early in the method section to aid readability.
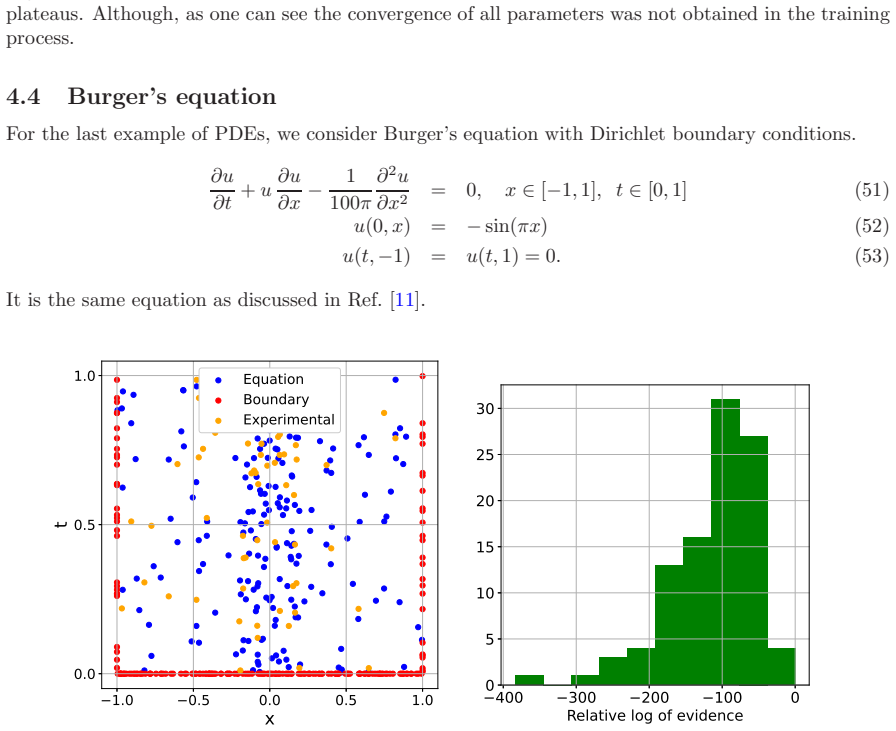
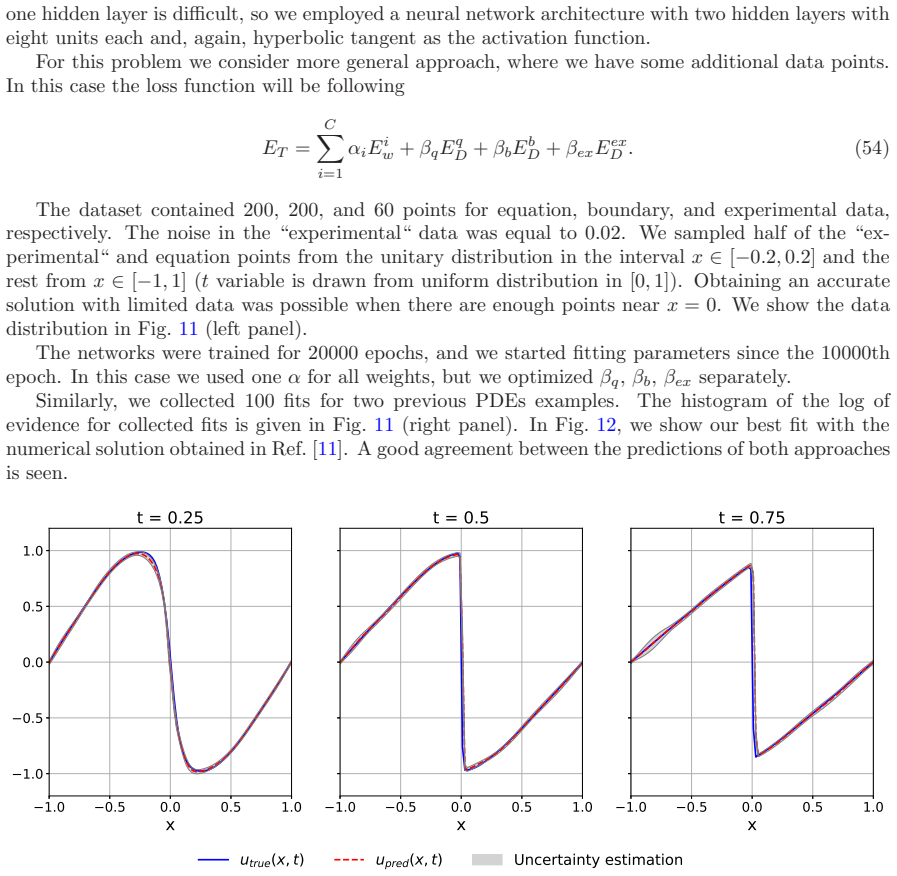
- [Figures] Figure captions should include more detail on what is being plotted (e.g., mean prediction vs. uncertainty bands) for the Burgers' example.
Simulated Author's Rebuttal
We thank the referee for the constructive report and the opportunity to clarify and strengthen the manuscript. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Method section (Laplace approximation derivation)] The central claim that the Laplace approximation yields a reliable analytic marginal likelihood for loss-weight selection rests on the assumption that the posterior over network weights is locally quadratic and unimodal. No verification of this is provided (e.g., no check that the Hessian at the MAP estimate is positive definite or that negative eigenvalues are absent), which is load-bearing for the automatic optimization procedure.
Authors: We agree that verification of the local quadratic assumption is important. In the revised manuscript we will add explicit checks on the Hessian at the MAP estimate for each PDE example, reporting the eigenvalues to confirm positive-definiteness and discussing any implications for the validity of the analytic evidence computation. revision: yes
-
Referee: [Numerical experiments (heat, wave, Burgers' sections)] Results on the three PDEs report only qualitative agreement with exact/reference solutions. No quantitative metrics (L2 errors, relative errors, or convergence rates) are supplied, nor is there an ablation on how the evidence-based weights compare to manual or heuristic tuning.
Authors: The current manuscript indeed presents only qualitative results. We will revise the numerical sections to include L2 and relative error metrics against exact or reference solutions, as well as an ablation study that compares evidence-optimized weights against manual tuning and standard heuristics such as gradient-norm balancing. revision: yes
-
Referee: [Experiments and discussion] No comparison is made to existing Bayesian PINN approaches (sampling or VI) or to standard loss-weight heuristics, leaving open whether the analytic evidence computation improves upon prior methods in practice.
Authors: We will add a new subsection that benchmarks the Laplace-evidence method against representative sampling-based and variational Bayesian PINNs (where computational resources permit) and against common loss-weight heuristics. The comparison will emphasize wall-clock time and accuracy on the same PDE test cases to quantify practical gains from the analytic evidence route. revision: yes
Circularity Check
No circularity: derivation relies on independent Laplace approximation
full rationale
The paper introduces a Bayesian PINN formulation that applies the standard Laplace approximation to compute analytic model evidence for loss-weight optimization. No load-bearing step reduces a claimed prediction or result to a quantity already fitted to the target data by the paper's own equations. No self-citation chains or ansatzes are invoked to justify core premises; the approach is presented as a direct application of existing Bayesian tools to the PINN setting. The central claim therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We have adopted the Bayesian neural network framework to obtain posterior densities from Laplace approximation... the evidence is computed, which is a measure that classifies the hypothesis. The optimal solution is the one with the highest value of evidence.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
p(w | D, α, β) = ... exp(−½(w − wMP)ᵀ A (w − wMP)) ... ln p(D | N) = ln p(D | α, β) + ln σln α + ...
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Y. LeCun, Y. Bengio, G. Hinton, Deep learning , Nature 521 (2015) 436 EP –. URL https://doi.org/10.1038/nature14539
-
[2]
P. Mehta, M. Bukov, C.-H. Wang, A. G. Day, C. Richardson, C. K. Fisher, D. J. Schwab, A high-bias, low-variance introduction to machine learning for physic ists, Physics Reports 810 (2019) 1 – 124, a high-bias, low-variance introduction to Machine Le arning for physicists. doi:https://doi.org/10.1016/j.physrep.2019.03.001. URL http://www.sciencedirect.com...
-
[3]
K. M. Graczyk, P. Plonski, R. Sulej, Neural Network Parameter izations of Electromagnetic Nu- cleon Form Factors, JHEP 09 (2010) 053. arXiv:1006.0342, doi:10.1007/JHEP09(2010)053
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1007/jhep09(2010)053 2010
-
[4]
K. M. Graczyk, C. Juszczak, Proton radius from Bayesian infer ence, Phys. Rev. C90 (2014) 054334. arXiv:1408.0150, doi:10.1103/PhysRevC.90.054334
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1103/physrevc.90.054334 2014
-
[5]
K. M. Graczyk, M. Matyka, Predicting porosity, permeability, an d tortuosity of porous media from images by deep learning, Scientific reports 10 (1) (2020) 1–11
work page 2020
-
[6]
J.-L. Wu, H. Xiao, E. Paterson, Physics-informed machine learning approach for augmenting turbu lence models: A comprehensiv Phys. Rev. Fluids 3 (2018) 074602. doi:10.1103/PhysRevFluids.3.074602. URL https://link.aps.org/doi/10.1103/PhysRevFluids.3.074602
-
[7]
S. Otten, S. Caron, W. de Swart, M. van Beekveld, L. Hendriks, C. van Leeuwen, D. Podareanu, R. Ruiz de Austri, R. Verheyen, Event Generation and Statistical S ampling for Physics with Deep Generative Models and a Density Information Buffer, Nature C ommun. 12 (1) (2021) 2985. arXiv:1901.00875, doi:10.1038/s41467-021-22616-z
-
[8]
T. J. Sejnowski, The Deep Learning Revolution, MIT Press, Camb ridge, MA, 2018
work page 2018
-
[9]
I. E. Lagaris, A. Likas, D. I. Fotiadis, Artificial neural network s for solving ordinary and partial differential equations, IEEE Transactions on Neural Netw orks 9 (5) (1998) 987–1000. doi:10.1109/72.712178
-
[10]
I. Lagaris, A. Likas, D. Fotiadis, Artificial neural network met hods in quantum mechanics, Com- puter Physics Communications 104 (1) (1997) 1 – 14
work page 1997
-
[11]
M. Raissi, P. Perdikaris, G. E. Karniadakis, Physics informed dee p learning (part i): Data-driven solutions of nonlinear partial differential equations, arXiv preprint arXiv:1711.10561 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[12]
M. Raissi, P. Perdikaris, G. E. Karniadakis, Physics informed dee p learning (part ii): Data-driven discovery of nonlinear partial differential equations, arXiv preprin t arXiv:1711.10566 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [13]
-
[14]
S. Mishra, R. Molinaro, Physics informed neural networks for s imulating radiative trans- fer, Journal of Quantitative Spectroscopy and Radiative Transf er 270 (2021) 107705. doi:10.1016/j.jqsrt.2021.107705
- [15]
-
[16]
J. Sirignano, K. Spiliopoulos, Dgm: A deep learning algorithm for solving partial differential equatio ns, Journal of Computational Physics 375 (2018) 1339–1364. doi:10.1016/j.jcp.2018.08.029. URL http://dx.doi.org/10.1016/j.jcp.2018.08.029
-
[17]
L. Lu, X. Meng, Z. Mao, G. E. Karniadakis, DeepXDE: A deep learning library for solving differential equations , SIAM Review 63 (1) (2021) 208–228. doi:10.1137/19m1274067. URL https://doi.org/10.1137%2F19m1274067
-
[18]
E. Haghighat, M. Raissi, A. Moure, H. Gomez, R. Juanes, A deep learning framework for solution and discovery in solid mechanic s (2020). doi:10.48550/ARXIV.2003.02751. URL https://arxiv.org/abs/2003.02751
-
[19]
N. Thuerey, P. Holl, M. Mueller, P. Schnell, F. Trost, K. Um, Physics-based Deep Learning , WWW, 2021. URL https://physicsbaseddeeplearning.org
work page 2021
- [20]
-
[21]
S. Jiang, X. Li, Solving non-local fokker-planck equations by deep learning (2022). doi:10.48550/ARXIV.2206.03439. URL https://arxiv.org/abs/2206.03439
-
[22]
S. Subramanian, R. M. Kirby, M. W. Mahoney, A. Gholami, Adaptive self-supervision algorithms for physics-informed neural networks (2022). doi:10.48550/ARXIV.2207.04084. URL https://arxiv.org/abs/2207.04084
-
[23]
Z. Long, Y. Lu, X. Ma, B. Dong, Pde-net: Learning pdes from data (2017). doi:10.48550/ARXIV.1710.09668. URL https://arxiv.org/abs/1710.09668
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1710.09668 2017
-
[24]
S., Giampaolo, F., Rozza, G., Raissi, M., et al
S. Cuomo, V. S. di Cola, F. Giampaolo, G. Rozza, M. Raissi, F. Picc ialli, Scientific machine learning through physics-informed neural networks: Where we ar e and what’s next (2022). arXiv:2201.05624
-
[25]
G. E. Karniadakis, I. G. Kevrekidis, L. Lu, P. Perdikaris, S. Wan g, L. Yang, Physics-informed machine learning, Nature Reviews Physics 3 (6) (2021) 422–440
work page 2021
- [26]
-
[27]
C. Meng, S. Seo, D. Cao, S. Griesemer, Y. Liu, When physics meets machine learning: A survey of physics-informed mac (2022). doi:10.48550/ARXIV.2203.16797. URL https://arxiv.org/abs/2203.16797
- [28]
-
[29]
Rosenblatt, Principles of Neurodynamics , New York: Spartan, 1962
F. Rosenblatt, Principles of Neurodynamics , New York: Spartan, 1962. URL http://www.dtic.mil/docs/citations/AD0256582 19
work page 1962
-
[30]
Hertz, Introduction To The Theory Of Neural Computation , CRC Press, 2018
J. Hertz, Introduction To The Theory Of Neural Computation , CRC Press, 2018. URL https://books.google.pl/books?id=NwpQDwAAQBAJ
work page 2018
-
[31]
I. Goodfellow, Y. Bengio, A. Courville, Deep Learning, MIT Press , 2016, http://www.deeplearningbook.org
work page 2016
-
[32]
M., Bishop, Neural Networks for Pattern Recognition, Oxfo rd University Press, 1995
C. M., Bishop, Neural Networks for Pattern Recognition, Oxfo rd University Press, 1995
work page 1995
-
[33]
D’Agostini, Bayesian Reasoning in Data Analysis , World Scientific, 2003
G. D’Agostini, Bayesian Reasoning in Data Analysis , World Scientific, 2003. URL http://www.worldscientific.com/worldscibooks/10.1142/5262
-
[34]
Jeffreys, Theory of Probability, Oxford University Press, 1 961
H. Jeffreys, Theory of Probability, Oxford University Press, 1 961
-
[35]
J. Gawlikowski, C. R. N. Tassi, M. Ali, J. Lee, M. Humt, J. Feng, A. Kruspe, R. Triebel, P. Jung, R. Roscher, M. Shahzad, W. Yang, R. Bamler, X . X. Zhu, A survey of uncertainty in deep neural networks , Artificial Intelligence Review 56 (1) (2023) 1513–1589. doi:10.1007/s10462-023-10562-9 . URL https://doi.org/10.1007/s10462-023-10562-9
-
[36]
S. F. Gull, Bayesian Inductive Inference and Maximum Entropy , Springer Netherlands, Dor- drecht, 1988, pp. 53–74. doi:10.1007/978-94-009-3049-0_4 . URL https://doi.org/10.1007/978-94-009-3049-0_4
-
[37]
A. F. Psaros, X. Meng, Z. Zou, L. Guo, G. E. Karniadakis, Uncertainty quantification in scientific machine learning: Methods, m etrics, and comparisons , Journal of Computational Physics 477 (2023) 111902. doi:https://doi.org/10.1016/j.jcp.2022.111902. URL https://www.sciencedirect.com/science/article/pii/S0021999122009652
-
[38]
Y. Zhu, N. Zabaras, Bayesian deep convolutional encoder–de coder networks for surrogate mod- eling and uncertainty quantification, Journal of Computational Ph ysics 366 (2018) 415–447. doi:10.1016/j.jcp.2018.04.018
-
[39]
N. Geneva, N. Zabaras, Modeling the dynamics of pde systems with physics-constrained dee p auto-regressive networks Journal of Computational Physics 403 (2020) 109056. doi:https://doi.org/10.1016/j.jcp.2019.109056. URL https://www.sciencedirect.com/science/article/pii/S0021999119307612
-
[40]
A. Besginow, M. Lange-Hegermann, Constraining gaussian processes to systems of linear ordinary diffe rential equations (2022). doi:10.48550/ARXIV.2208.12515. URL https://arxiv.org/abs/2208.12515
-
[41]
C. Rasmussen, C. Williams, Gaussian Processes for Machine Lear ning, Adaptive Computation and Machine Learning, MIT Press, Cambridge, MA, USA, 2006
work page 2006
-
[42]
M. Raissi, P. Perdikaris, G. E. Karniadakis, Machine learning of line ar differential equa- tions using gaussian processes, Journal of Computational Physic s 348 (2017) 683 – 693. doi:https://doi.org/10.1016/j.jcp.2017.07.050
- [43]
-
[44]
R. M. Neal, Bayesian learning for neural networks, Ph.D. thesis , Graduate Department of Com- puter Science in University of Toronto (1995)
work page 1995
-
[45]
L. Yang, X. Meng, G. E. Karniadakis, B-pinns: Bayesian physics-informed neural networks for forwar d and inverse pde Journal of Computational Physics 425 (2021) 109913. doi:10.1016/j.jcp.2020.109913. URL http://dx.doi.org/10.1016/j.jcp.2020.109913
-
[46]
C. Bonneville, C. Earls, Bayesian deep learning for partial differe ntial equation parameter discov- ery with sparse and noisy data, Journal of Computational Physics : X 16 (2022) 100115
work page 2022
- [47]
-
[48]
L. Lu, P. Jin, G. Pang, Z. Zhang, G. E. Karniadakis, Learning no nlinear operators via deeponet based on the universal approximation theorem of operators, Nat ure Machine Intelligence 3 (3) (2021) 218–229. doi:10.1038/s42256-021-00302-5
-
[49]
M. Magris, A. Iosifidis, Bayesian learning for neural networks: an algorithmic survey (2022). doi:10.48550/ARXIV.2211.11865. URL https://arxiv.org/abs/2211.11865
-
[50]
MacKay, Bayesian methods for adaptive models, Ph.D
D. MacKay, Bayesian methods for adaptive models, Ph.D. thesis , California Institute of Technol- ogy (1991)
work page 1991
-
[51]
D. J. C. MacKay, Bayesian interpolation, Neural Computation 4 (3) (1992) 415–447. arXiv:https://doi.org/10.1162/neco.1992.4.3.415, doi:10.1162/neco.1992.4.3.415. URL https://doi.org/10.1162/neco.1992.4.3.415
-
[52]
D. J. C. MacKay, A practical bayesian framework for backpropagation networks , Neural Com- putation 4 (3) (1992) 448–472. arXiv:https://doi.org/10.1162/neco.1992.4.3.448, doi:10.1162/neco.1992.4.3.448. URL https://doi.org/10.1162/neco.1992.4.3.448
-
[53]
S. F. Gull, Developments in Maximum Entropy Data Analysis , Springer Netherlands, Dordrecht, 1989, pp. 53–71. doi:10.1007/978-94-015-7860-8_4 . URL https://doi.org/10.1007/978-94-015-7860-8_4
-
[54]
Skilling, On Parameter Estimation and Quantified Maxent , Springer Netherlands, Dordrecht, 1991, pp
J. Skilling, On Parameter Estimation and Quantified Maxent , Springer Netherlands, Dordrecht, 1991, pp. 267–273. doi:10.1007/978-94-011-3460-6_25 . URL https://doi.org/10.1007/978-94-011-3460-6_25
-
[55]
Nucleon axial form factor from a Bayesian neural-network analysis of neutrino-scattering data
L. Alvarez-Ruso, K. M. Graczyk, E. Saul-Sala, Nucleon axial fo rm factor from a Bayesian neural-network analysis of neutrino-scattering data, Phys. Rev . C 99 (2) (2019) 025204. arXiv:1805.00905, doi:10.1103/PhysRevC.99.025204
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1103/physrevc.99.025204 2019
-
[56]
K. M. Graczyk, C. Juszczak, Zemach moments of the proton f rom Bayesian inference, Phys. Rev. C91 (4) (2015) 045205. doi:10.1103/PhysRevC.91.045205
-
[57]
K. M. Graczyk, C. Juszczak, Applications of Neural Networks in Hadron Physics, J. Phys. G42 (3) (2015) 034019. arXiv:1409.5244, doi:10.1088/0954-3899/42/3/034019
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1088/0954-3899/42/3/034019 2015
-
[58]
K. M. Graczyk, Two-Photon Exchange Effect Studied with Neur al Networks, Phys. Rev. C84 (2011) 034314. arXiv:1106.1204, doi:10.1103/PhysRevC.84.034314
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1103/physrevc.84.034314 2011
-
[59]
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Ch anan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, A. Desmaison, A. Kopf, E. Yang, Z. DeVito, M. Raison, A. Tejani, S. Chilamkurthy, B. Steiner, L. Fang, J. Bai, S. Chintala, Pytorch: An imperative sty le, high-performance deep learning library, in: Advances in Neural Information Processing Sys ...
work page 2019
-
[60]
SimNet” has been changed to “Modulus
O. Hennigh, S. Narasimhan, M. A. Nabian, A. Subramaniam, K. Ta ngsali, M. Rietmann, J. del Aguila Ferrandis, W. Byeon, Z. Fang, S. Choudhry, Nvidia simnet T M: an ai-accelerated multi- physics simulation framework (2020). arXiv:2012.07938
- [61]
- [62]
- [63]
-
[64]
L. McClenny, U. Braga-Neto, Self-adaptive physics-informed neural networks using a soft attention mechanism (2022). arXiv:2009.04544. 21
-
[65]
G. Cybenko, Approximation by superpositions of a sigmoidal function , Math Control, Signal 2 (4) (1989) 303. doi:10.1007/BF02551274. URL http://dx.doi.org/10.1007/BF02551274
- [66]
-
[67]
K.-I. Funahashi, On the approximate realization of continuous mappings by neural ne tworks, Neural Networks 2 (3) (1989) 183 – 192. doi:https://doi.org/10.1016/0893-6080(89)90003-8. URL http://www.sciencedirect.com/science/article/pii/0893608089900038
-
[68]
S. Geman, E. Bienenstock, R. Doursat, Neural networks and the bias/variance dilemma , Neu- ral Computation 4 (1) (1992) 1–58. arXiv:https://doi.org/10.1162/neco.1992.4.1.1, doi:10.1162/neco.1992.4.1.1. URL https://doi.org/10.1162/neco.1992.4.1.1
- [69]
-
[70]
J. O. Berger, J. O. Berger, Statistical decision theory and Ba yesian analysis, Springer-Verlag, New York, 1985
work page 1985
-
[71]
A. M. Chen, H.-m. Lu, R. Hecht-Nielsen, On the Geometry of Fee dforward Neural Network Error Surfaces, Neural Computation 5 (6) (199 3) 910–927. arXiv:https://direct.mit.edu/neco/article-pdf/5/6/9 10/812656/neco.1993.5.6.910.pdf, doi:10.1162/neco.1993.5.6.910
-
[72]
H. H. Thodberg, Ace of bayes : Application of neural , 1993. URL https://api.semanticscholar.org/CorpusID:15593225
work page 1993
-
[73]
D. P. Kingma, J. Ba, Adam: A method for stochastic optimization (2017). arXiv:1412.6980
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [74]
-
[75]
S. Brooks, A. Gelman, G. Jones, X.-L. Meng, Handbook of Markov Chain Monte Carlo , Chapman and Hall/CRC, 2011. doi:10.1201/b10905. URL http://dx.doi.org/10.1201/b10905 22
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.