Consistency of Lloyd's Algorithm Under Perturbations
Pith reviewed 2026-05-24 06:58 UTC · model grok-4.3
The pith
Lloyd's algorithm achieves exponentially bounded mis-clustering on perturbed sub-Gaussian samples after O(log n) iterations when perturbations stay small relative to noise.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The mis-clustering rate of Lloyd's algorithm on perturbed samples from a sub-Gaussian mixture remains exponentially small after O(log n) iterations, assuming proper initialization and that the perturbation is small relative to the sub-Gaussian noise.
What carries the argument
The perturbation model in which each observed point equals a true mixture sample plus a small additive error, together with the standard assignment-and-centroid-update loop of Lloyd's algorithm.
If this is right
- Clustering pipelines that preprocess data with spectral methods or multidimensional scaling still enjoy exponential consistency guarantees for Lloyd's algorithm.
- Spectral clustering on sparse networks yields provably low mis-clustering rates when followed by Lloyd's iteration.
- Theoretical support is obtained for significance-testing procedures such as SigClust that rely on Lloyd's output.
- The same perturbation tolerance applies to high-dimensional time-series clustering after suitable embedding.
Where Pith is reading between the lines
- Small preprocessing errors introduced by spectral or embedding steps need not destroy the exponential consistency of subsequent Lloyd iterations.
- Analogous perturbation arguments could be checked for other iterative clustering procedures that alternate assignment and centroid updates.
- Empirical verification could fix a mixture, vary perturbation magnitude across the critical threshold, and measure whether the mis-clustering decay rate changes.
Load-bearing premise
The size of the perturbation must remain small compared with the sub-Gaussian noise level of the mixture components.
What would settle it
An experiment in which perturbation size exceeds a fixed fraction of the component noise level and the observed mis-clustering rate fails to decay exponentially with sample size n.
Figures
read the original abstract
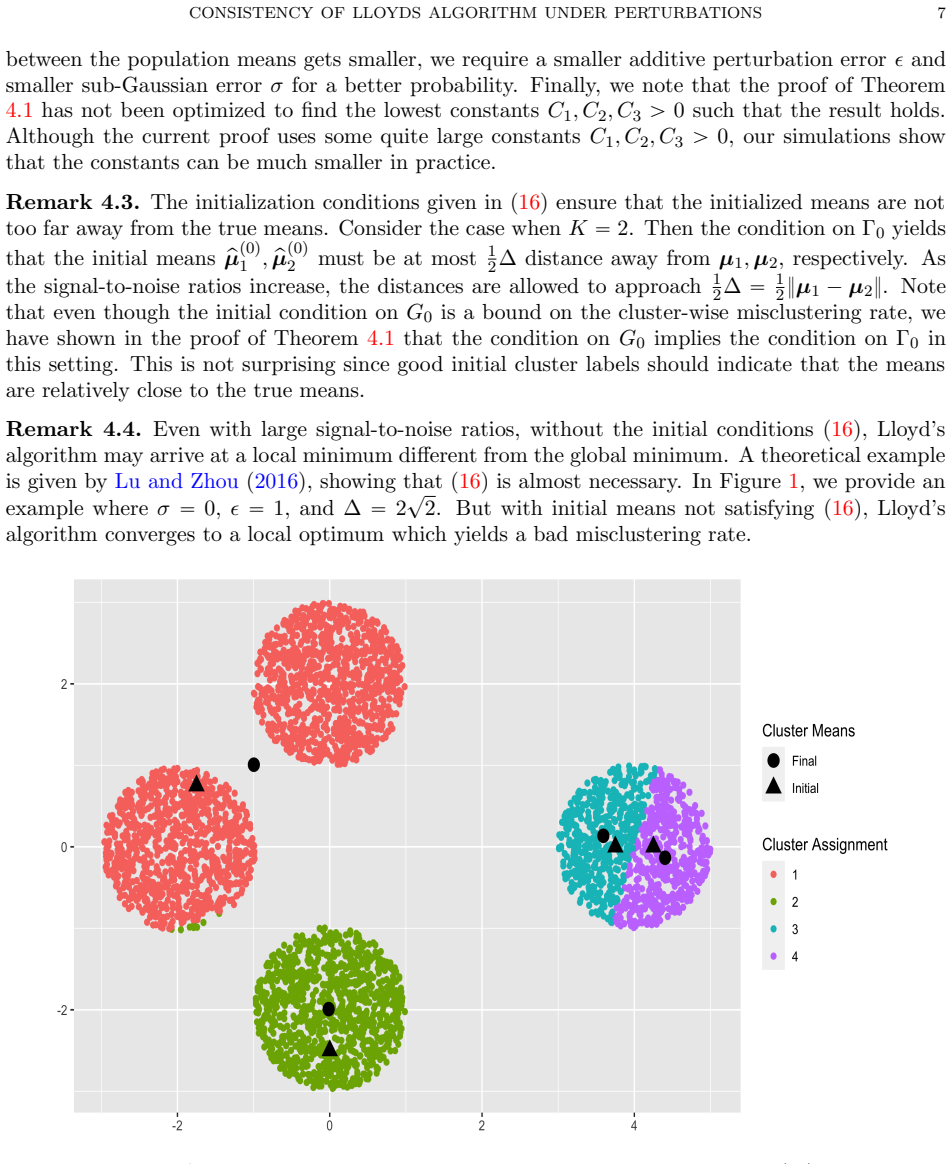
In the context of unsupervised learning, Lloyd's algorithm is one of the most widely used clustering algorithms. It has inspired a plethora of work investigating the correctness of the algorithm under various settings with ground truth clusters. In particular, in 2016, Lu and Zhou have shown that the mis-clustering rate of Lloyd's algorithm on $n$ independent samples from a sub-Gaussian mixture is exponentially bounded after $O(\log(n))$ iterations, assuming proper initialization of the algorithm. However, in many applications, the true samples are unobserved and need to be learned from the data via pre-processing pipelines such as spectral methods on appropriate data matrices. We show that the mis-clustering rate of Lloyd's algorithm on perturbed samples from a sub-Gaussian mixture is also exponentially bounded after $O(\log(n))$ iterations under the assumptions of proper initialization and that the perturbation is small relative to the sub-Gaussian noise. In canonical settings with ground truth clusters, we derive bounds for algorithms such as $k$-means$++$ to find good initializations and thus leading to the correctness of clustering via the main result. We show the implications of the results for pipelines measuring the statistical significance of derived clusters from data such as SigClust. We use these general results to derive implications in providing theoretical guarantees on the misclustering rate for Lloyd's algorithm in a host of applications, including high-dimensional time series, multi-dimensional scaling, and community detection for sparse networks via spectral clustering.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript extends the Lu-Zhou (2016) exponential mis-clustering bound for Lloyd's algorithm on sub-Gaussian mixtures to the perturbed-sample regime. It claims that after O(log n) iterations the mis-clustering rate remains exponentially small provided the initialization is good and the perturbation norm is sufficiently small relative to the sub-Gaussian parameter; the paper also supplies k-means++ initialization guarantees and derives consequences for SigClust, high-dimensional time series, MDS, and spectral community detection.
Significance. If the central perturbation-propagation argument holds, the result supplies a modular theoretical tool for end-to-end analysis of clustering pipelines that contain an estimation or pre-processing step. The explicit small-perturbation hypothesis and the O(log n) iteration count make the guarantee directly usable for assessing statistical significance procedures such as SigClust and for sparse-network community detection.
major comments (2)
- [§3] §3 (main theorem): the proof sketch must show that the perturbation term enters the concentration inequality only as an additive O(ε) shift that does not destroy the exponential decay; without an explicit error-term calculation it is unclear whether the O(log n) iteration count remains sufficient when ε is comparable to the sub-Gaussian scale.
- [Theorem 4.1] Theorem 4.1 (k-means++ initialization): the claimed probability of obtaining a good initialization is stated only for the clean case; the argument needs to be re-checked to confirm that the same O(1) success probability carries over when each point is replaced by a perturbed version whose norm is bounded by ε.
minor comments (3)
- The abstract refers to 'canonical settings with ground truth clusters' without defining the term; a short parenthetical list of the concrete mixture models considered would improve readability.
- Notation for the perturbation matrix (or vector) is introduced only in the main theorem statement; an earlier global notation paragraph would prevent readers from having to back-track.
- The reference list entry for Lu & Zhou (2016) should include the conference or journal name and page numbers.
Simulated Author's Rebuttal
We thank the referee for the constructive report and the recommendation of minor revision. The comments highlight places where additional explicit calculations and verifications will improve clarity. We address each point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§3] §3 (main theorem): the proof sketch must show that the perturbation term enters the concentration inequality only as an additive O(ε) shift that does not destroy the exponential decay; without an explicit error-term calculation it is unclear whether the O(log n) iteration count remains sufficient when ε is comparable to the sub-Gaussian scale.
Authors: We agree that an explicit error-term calculation strengthens the presentation. In the proof, each concentration inequality for the Lloyd iteration receives an additive perturbation of size O(ε) inside the deviation bounds. Because the theorem assumes ε is sufficiently small relative to the sub-Gaussian parameter (specifically ε = o(σ) where σ is the sub-Gaussian scale), this additive term only shifts the effective threshold by a lower-order amount and does not alter the exponential decay rate. Consequently the same O(log n) iteration count continues to suffice. We will expand the proof sketch in §3 to display this calculation explicitly. revision: yes
-
Referee: [Theorem 4.1] Theorem 4.1 (k-means++ initialization): the claimed probability of obtaining a good initialization is stated only for the clean case; the argument needs to be re-checked to confirm that the same O(1) success probability carries over when each point is replaced by a perturbed version whose norm is bounded by ε.
Authors: We will re-examine the k-means++ argument. Because each perturbed point differs from its clean counterpart by at most ε in norm, the distance-based probabilities that appear in the k-means++ analysis change by at most an additive O(ε) term. Under the standing small-perturbation hypothesis of the main theorem this additive error is absorbed into the existing constants, preserving an O(1) success probability. We will add a short remark or lemma confirming the carry-over and, if the constants require adjustment, state the modified bound. revision: yes
Circularity Check
No significant circularity
full rationale
The derivation extends the external Lu-Zhou (2016) exponential mis-clustering bound to the perturbed case under an explicitly stated assumption that perturbation size is small relative to sub-Gaussian noise. No load-bearing step reduces to a self-citation by the same authors, a fitted parameter renamed as prediction, or a self-definitional loop. The paper invokes standard concentration inequalities and initialization results (including k-means++) whose validity is independent of the target bound. The central claim therefore retains independent content and is not forced by construction from its inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption data are i.i.d. samples from a sub-Gaussian mixture model
- domain assumption initialization is proper (sufficiently close to true centers)
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We show that the mis-clustering rate of Lloyd’s algorithm on perturbed samples from a sub-Gaussian mixture is also exponentially bounded after O(log n) iterations under the assumptions of proper initialization and that the perturbation is small relative to the sub-Gaussian noise (Theorem 4.1).
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ρσ = Δ/σ √(α/(1+Kr/n)), ρε = √α Δ/ε; As ≤ max{exp(−Δ²/16σ²), exp(−Δ²/8εσ)}
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Abbe, E. (2017). Community detection and stochastic block models: recent developments. The Journal of Machine Learning Research , 18(1):6446--6531
work page 2017
-
[2]
Abbe, E., Fan, J., and Wang, K. (2022). An _p theory of pca and spectral clustering. The Annals of Statistics , 50(4):2359--2385
work page 2022
-
[3]
Abbe, E., Fan, J., Wang, K., and Zhong, Y. (2020). Entrywise eigenvector analysis of random matrices with low expected rank. Annals of statistics , 48(3):1452
work page 2020
-
[4]
Amini, A. A., Chen, A., Bickel, P. J., and Levina, E. (2013). Pseudo-likelihood methods for community detection in large sparse networks
work page 2013
-
[5]
Arora, S., Raghavan, P., and Rao, S. (1998). Approximation schemes for euclidean k-medians and related problems. In Proceedings of the thirtieth annual ACM symposium on Theory of computing , pages 106--113
work page 1998
-
[6]
Arthur, D. and Vassilvitskii, S. (2007). k-means++: The advantages of careful seeding: Conference. In Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms.--New Orleans
work page 2007
-
[7]
Awasthi, P., Blum, A., and Sheffet, O. (2012). Center-based clustering under perturbation stability. Information Processing Letters , 112(1):49--54
work page 2012
- [8]
-
[9]
Balakrishnan, S., Wainwright, M. J., and Yu, B. (2017). Statistical guarantees for the EM algorithm: From population to sample-based analysis . The Annals of Statistics , 45(1):77 -- 120
work page 2017
- [10]
-
[11]
Bickel, P. J. and Chen, A. (2009). A nonparametric view of network models and newman--girvan and other modularities. Proceedings of the National Academy of Sciences , 106(50):21068--21073
work page 2009
-
[12]
Bock, H.-H. (1985). On some significance tests in cluster analysis. Journal of classification , 2:77--108
work page 1985
-
[13]
Bordenave, C., Lelarge, M., and Massouli \'e , L. (2015). Non-backtracking spectrum of random graphs: community detection and non-regular ramanujan graphs. In 2015 IEEE 56th Annual Symposium on Foundations of Computer Science , pages 1347--1357. IEEE
work page 2015
-
[14]
Borg, I. and Groenen, P. J. (2005). Modern multidimensional scaling: Theory and applications . Springer Science & Business Media
work page 2005
-
[15]
Boucheron, S., Lugosi, G., and Massart, P. (2013). Concentration inequalities: A nonasymptotic theory of independence . Oxford university press
work page 2013
- [16]
-
[17]
Chang, J., Kolaczyk, E. D., and Yao, Q. (2022). Estimation of subgraph densities in noisy networks. Journal of the American Statistical Association , 117(537):361--374
work page 2022
-
[18]
Chen, G., Ning, B., and Shi, T. (2019). Single-cell rna-seq technologies and related computational data analysis. Frontiers in genetics , page 317
work page 2019
-
[19]
Chen, L. and Buja, A. (2009). Local multidimensional scaling for nonlinear dimension reduction, graph drawing, and proximity analysis. Journal of the American Statistical Association , 104(485):209--219
work page 2009
-
[20]
Cox, T. F. and Cox, M. A. (2000). Multidimensional scaling . CRC press
work page 2000
- [21]
-
[22]
Doz, C., Giannone, D., and Reichlin, L. (2012). A quasi maximum likelihood approach for large, approximate dynamic factor models. Review of Economics and Statistics , 94(4):1014--1024
work page 2012
-
[23]
Dunn, J. C. (1973). A fuzzy relative of the ISODATA process and its use in detecting compact well-separated clusters. Journal of Cybernetics , 3(3):32--57
work page 1973
-
[24]
Dutta, A., Vijayaraghavan, A., and Wang, A. (2017). Clustering stable instances of E uclidean k-means. Advances in Neural Information Processing Systems , pages 6501--6510. 31st Annual Conference on Neural Information Processing Systems, NIPS 2017
work page 2017
-
[25]
Fortunato, S. (2010). Community detection in graphs. Physics reports , 486(3-5):75--174
work page 2010
-
[26]
Gao, C., Ma, Z., Zhang, A. Y., and Zhou, H. H. (2017). Achieving optimal misclassification proportion in stochastic block models. The Journal of Machine Learning Research , 18(1):1980--2024
work page 2017
-
[27]
Gao, C. and Zhang, A. Y. (2022). Iterative algorithm for discrete structure recovery. The Annals of Statistics , 50(2):1066--1094
work page 2022
-
[28]
Gower, J. C. (1966). Some distance properties of latent root and vector methods used in multivariate analysis. Biometrika , 53(3-4):325--338
work page 1966
-
[29]
Hajek, B., Wu, Y., and Xu, J. (2016). Achieving exact cluster recovery threshold via semidefinite programming. IEEE Transactions on Information Theory , 62(5):2788--2797
work page 2016
-
[30]
Hoff, P. D., Raftery, A. E., and Handcock, M. S. (2002). Latent space approaches to social network analysis. Journal of the American Statistical Association , 97(460):1090--1098
work page 2002
- [31]
-
[32]
Kaufman, L. and Rousseeuw, P. J. (2009). Finding groups in data: an introduction to cluster analysis . John Wiley & Sons
work page 2009
-
[33]
Klochkov, Y., Kroshnin, A., and Zhivotovskiy, N. (2021). Robust k-means clustering for distributions with two moments. The Annals of Statistics , 49(4):2206--2230
work page 2021
-
[34]
Krzakala, F., Moore, C., Mossel, E., Neeman, J., Sly, A., Zdeborov \'a , L., and Zhang, P. (2013). Spectral redemption in clustering sparse networks. Proceedings of the National Academy of Sciences , 110(52):20935--20940
work page 2013
-
[35]
Lei, J. and Rinaldo, A. (2015). Consistency of spectral clustering in stochastic block models . The Annals of Statistics , 43(1):215 -- 237
work page 2015
- [36]
-
[37]
Little, A., Xie, Y., and Sun, Q. (2022). An analysis of classical multidimensional scaling with applications to clustering. Information and Inference: A Journal of the IMA
work page 2022
-
[38]
Liu, Y., Hayes, D. N., Nobel, A., and Marron, J. S. (2008). Statistical significance of clustering for high-dimension, low--sample size data. Journal of the American Statistical Association , 103(483):1281--1293
work page 2008
-
[39]
Lloyd, S. (1982). Least squares quantization in PCM . IEEE Transactions on Information Theory , 28(2):129--137
work page 1982
-
[40]
L \"o ffler, M., Zhang, A. Y., and Zhou, H. H. (2021). Optimality of spectral clustering in the gaussian mixture model. The Annals of Statistics , 49(5):2506--2530
work page 2021
-
[41]
Statistical and Computational Guarantees of Lloyd's Algorithm and its Variants
Lu, Y. and Zhou, H. H. (2016). Statistical and computational guarantees of lloyd's algorithm and its variants. arXiv preprint arXiv:1612.02099
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[42]
L., Tang, M., Athreya, A., and Priebe, C
Lyzinski, V., Sussman, D. L., Tang, M., Athreya, A., and Priebe, C. E. (2014). Perfect clustering for stochastic blockmodel graphs via adjacency spectral embedding. Electronic Journal of Statistics , 8(2):2905--2922
work page 2014
-
[43]
Mahajan, M., Nimbhorkar, P., and Varadarajan, K. (2009). The planar k-means problem is NP -hard. In WALCOM : Algorithms and Computation , pages 274--285. Springer Berlin Heidelberg
work page 2009
-
[44]
Mossel, E., Neeman, J., and Sly, A. (2015). Reconstruction and estimation in the planted partition model. Probability Theory and Related Fields , 162:431--461
work page 2015
-
[45]
Mossel, E., Neeman, J., and Sly, A. (2018). A proof of the block model threshold conjecture. Combinatorica , 38(3):665--708
work page 2018
-
[46]
Ndaoud, M. (2022). Sharp optimal recovery in the two component gaussian mixture model. The Annals of Statistics , 50(4):2096--2126
work page 2022
-
[47]
Newman, M. E. (2004). Detecting community structure in networks. The European physical journal B , 38:321--330
work page 2004
-
[48]
Newman, M. E. (2013). Spectral methods for community detection and graph partitioning. Physical Review E , 88(4):042822
work page 2013
-
[49]
Pollard, D. (1981). Strong consistency of k-means clustering. The Annals of Statistics , 9(1):135--140
work page 1981
-
[50]
Pollard, D. (1982). A central limit theorem for k-means clustering. The Annals of Probability , 10(4):919 -- 926
work page 1982
-
[51]
Pollard, D. (1990). Empirical processes: theory and applications. Ims
work page 1990
-
[52]
Priebe, C. E., Sussman, D. L., Tang, M., and Vogelstein, J. T. (2015). Statistical inference on errorfully observed graphs. Journal of Computational and Graphical Statistics , 24(4):930--953
work page 2015
-
[53]
Rakhlin, A. and Caponnetto, A. (2007). Stability of k-means clustering. In Sch\" o lkopf, B., Platt, J., and Hoffman, T., editors, Advances in Neural Information Processing Systems , volume 19. MIT Press
work page 2007
-
[54]
Rohe, K., Chatterjee, S., and Yu, B. (2011). Spectral clustering and the high-dimensional stochastic blockmodel. Annals of statistics , 39(4):1878--1915
work page 2011
-
[55]
H., Viswanath, P., and Reddy, B
Sarma, T. H., Viswanath, P., and Reddy, B. E. (2012). A hybrid approach to speed-up the k-means clustering method. International Journal of Machine Learning and Cybernetics , 4(2):107--117
work page 2012
-
[56]
Shen, H., Bhamidi, S., and Liu, Y. (2023). Statistical significance of clustering with multidimensional scaling. Journal of Computational and Graphical Statistics , (just-accepted):1--27
work page 2023
-
[57]
Tabouy, T., Barbillon, P., and Chiquet, J. (2020). Variational inference for stochastic block models from sampled data. Journal of the American Statistical Association , 115(529):455--466
work page 2020
-
[58]
Tang, M., Sussman, D. L., and Priebe, C. E. (2013). Universally consistent vertex classification for latent positions graphs. The Annals of Statistics , 41(3):1406--1430
work page 2013
-
[59]
Telgarsky, M. J. and Dasgupta, S. (2013). Moment-based uniform deviation bounds for k -means and friends. Advances in Neural Information Processing Systems , 26
work page 2013
-
[60]
Tenenbaum, J. B., Silva, V. d., and Langford, J. C. (2000). A global geometric framework for nonlinear dimensionality reduction. science , 290(5500):2319--2323
work page 2000
-
[61]
Torgerson, W. S. (1952). Multidimensional scaling: I. theory and method. Psychometrika , 17(4):401--419
work page 1952
-
[62]
Uematsu, Y. and Yamagata, T. (2020). Estimation of weak factor models. ISER discussion paper, Institute of Social and Economic Research, Osaka University
work page 2020
- [63]
-
[64]
Wei, L., Zeng, W., and Wang, H. (2010). K-means clustering with manifold. In 2010 Seventh International Conference on Fuzzy Systems and Knowledge Discovery , volume 5, pages 2095--2099
work page 2010
-
[65]
Wierzcho \'n , S. T. and K opotek, M. A. (2018). Modern A lgorithms of C luster A nalysis . Springer
work page 2018
-
[66]
Young, G. and Householder, A. S. (1938). Discussion of a set of points in terms of their mutual distances. Psychometrika , 3(1):19--22
work page 1938
-
[67]
Young, S. J. and Scheinerman, E. R. (2007). Random dot product graph models for social networks. In International Workshop on Algorithms and Models for the Web-Graph , pages 138--149. Springer
work page 2007
-
[68]
Accurate Community Detection in the Stochastic Block Model via Spectral Algorithms
Yun, S.-Y. and Proutiere, A. (2014). Accurate community detection in the stochastic block model via spectral algorithms. arXiv preprint arXiv:1412.7335
work page internal anchor Pith review Pith/arXiv arXiv 2014
- [69]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.