Efficient Finite Initialization with Partial Norms for Tensorized Neural Networks and Tensor Networks Algorithms
Pith reviewed 2026-05-24 06:26 UTC · model grok-4.3
The pith
Iterative partial norms allow finite initialization of tensorized neural network layers
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The core discovery is that using norms of subnetworks iteratively normalizes tensor networks by finite values, enabling efficient initialization of tensorized layers where direct full-norm calculations fail due to divergence or vanishing.
What carries the argument
Iterative normalization using partial Frobenius norms of subnetworks, with reuse of intermediate calculations.
If this is right
- Initialization becomes efficient for MPS/TT layers as the number of nodes increases.
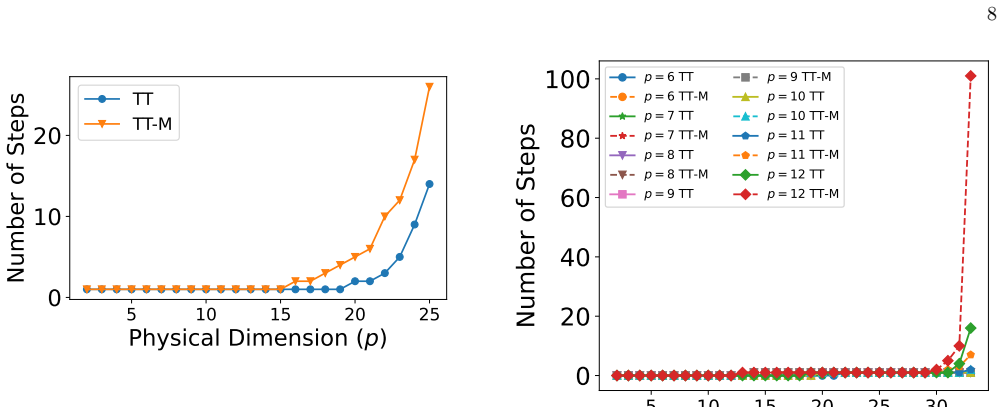
- Same for MPO/TT-M layers.
- Scaling is characterized with respect to bond dimension and physical dimension.
- Intermediate calculations are reused to reduce overall computation time.
Where Pith is reading between the lines
- This method could extend to other tensor network formats not tested in the paper.
- Improved initialization may lead to more stable training in tensorized models.
- Partial norm techniques might address similar numerical issues in other high-dimensional representations.
Load-bearing premise
Partial norm calculations on subnetworks will always produce finite values and can be computed efficiently without the problems of the complete network.
What would settle it
Running the initialization on a network where the full Frobenius norm diverges or is zero, and checking if the partial method yields a usable finite scale factor and valid layer initialization.
Figures












read the original abstract
We present two algorithms to initialize layers of tensorized neural networks and general tensor network algorithms using partial computations of their Frobenius norms and positive lineal entrywise sums, depending on the type of tensor network involved. The core of this method is the use of the norm of subnetworks of the tensor network in an iterative way, so that we normalize by the finite values of the norms that led to the divergence or zero norm. In addition, the method benefits from the reuse of intermediate calculations. We have also applied it to the Matrix Product State/Tensor Train (MPS/TT) and Matrix Product Operator/Tensor Train Matrix (MPO/TT-M) layers and have seen its scaling versus the number of nodes, bond dimension, and physical dimension. All code is publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents two algorithms for initializing layers in tensorized neural networks and general tensor networks. The methods iteratively compute partial Frobenius norms and positive lineal entrywise sums on subnetworks to obtain finite normalizing factors that avoid the divergence or zero-norm problems of full-network calculations, with reuse of intermediate results. The algorithms are applied to MPS/TT and MPO/TT-M layers, with reported scaling behavior versus number of nodes, bond dimension, and physical dimension; all code is made publicly available.
Significance. If the initialization procedure can be shown to reliably produce finite normalizers across a broader range of tensor-network topologies, it would provide a practical tool for stable initialization of tensorized models, with the reuse of subnetwork calculations offering potential efficiency gains. The public release of code is a clear strength that supports reproducibility.
major comments (2)
- [Abstract] Abstract: the claim of applicability to 'general tensor networks' is not supported by any analysis or experiments on topologies containing cycles. Subnetwork norm computations can become intractable in the presence of cycles, directly undermining both the efficiency claim and the guarantee of finite outputs; all reported results are restricted to chain-like MPS/TT and MPO/TT-M structures.
- [Abstract] Abstract: no proofs, error bounds, or comparative benchmarks against existing initialization schemes are provided, leaving the central algorithmic claim without formal verification or quantitative assessment of numerical stability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the scope of our claims and the need for additional verification. We address the two major comments below and will make targeted revisions to the abstract and experimental section to better align the manuscript with the presented results.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of applicability to 'general tensor networks' is not supported by any analysis or experiments on topologies containing cycles. Subnetwork norm computations can become intractable in the presence of cycles, directly undermining both the efficiency claim and the guarantee of finite outputs; all reported results are restricted to chain-like MPS/TT and MPO/TT-M structures.
Authors: We agree that the abstract overstates the generality. The algorithms rely on efficient subnetwork norm computations that are tractable for acyclic (chain-like) topologies such as MPS/TT and MPO/TT-M, as demonstrated in our scaling experiments. For networks with cycles, the partial-norm approach can indeed become intractable due to the need to handle loops in the contraction order. We will revise the abstract to remove the unqualified reference to 'general tensor networks' and instead state that the methods are developed and tested for Matrix Product State/Tensor Train and Matrix Product Operator structures. A brief discussion of the limitation for cyclic topologies will be added to the introduction. revision: yes
-
Referee: [Abstract] Abstract: no proofs, error bounds, or comparative benchmarks against existing initialization schemes are provided, leaving the central algorithmic claim without formal verification or quantitative assessment of numerical stability.
Authors: The current manuscript focuses on the algorithmic procedure for obtaining finite normalizers via iterative partial norms and reports empirical scaling with respect to number of nodes, bond dimension, and physical dimension. No formal proofs or error bounds are derived, as the primary contribution is the reuse of intermediate subnetwork calculations to avoid divergence or zero-norm issues in practice. We acknowledge the absence of direct comparisons. In revision we will add a new experimental subsection that benchmarks our initialization against standard random initialization (and, where applicable, other layer-wise schemes) on the same MPS/TT and MPO/TT-M layers, measuring numerical stability via the frequency of finite-norm outcomes and downstream training convergence. This will provide the requested quantitative assessment without altering the core algorithmic focus. revision: partial
Circularity Check
No circularity: algorithmic construction is independent of fitted inputs or self-citations
full rationale
The paper presents two explicit algorithms for finite initialization of tensor networks via iterative partial Frobenius norms and entrywise sums on subnetworks. No equations or claims reduce a result to a fitted parameter, self-defined quantity, or load-bearing self-citation chain; the method is described as a direct computational procedure with reuse of intermediates, applied to MPS/TT and MPO/TT-M structures. The central claim rests on the efficiency and finiteness properties of subnetwork computations, which are presented as independent algorithmic facts rather than derived from the target initialization values themselves. This is a standard case of a self-contained algorithmic contribution with no reduction to its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Frobenius norms and positive entrywise sums of subnetworks can be computed independently and used for normalization without requiring the full network norm.
Reference graph
Works this paper leans on
-
[1]
We initialize the node tensors with some initializa- tion method. We recommend random initialization with a Gaussian distribution of a constant stan- dard deviation (not greater than 0 .5) and a con- stant mean neither too high nor too low and posi- tive
-
[2]
If it is finite and non-zero, we divide each element of each node by ||A||F F 1/N and return A
We compute ||A||F . If it is finite and non-zero, we divide each element of each node by ||A||F F 1/N and return A. Otherwise, we continue
-
[3]
We compute pF ||A||1,N. (a) If it is infinite, we divide each element of the nodes of A by (10(1 + ξ))1/2N, being ξ a ran- dom number between 0 and 1, and return to Step 2. (b) If it is zero, we multiply each element of the nodes of A by (10(1 + ξ))1/2N and return to Step 2. (c) Otherwise, we save this value as pF ||A||1,N and continue
-
[4]
For n ∈ [2, N − 1], we compute pF ||A||n,N. (a) If it is infinite or zero, we divide each element of the nodes of A by ( pF ||A||n−1,N) 1 2N , and repeat Steps 2 and 4 (from this value of n). (b) If it is finite, but larger than b or smaller than a, we divide each element of the nodes of A by pF ||A||n,N F 1 2N , and repeat Steps 2 and 4 (from this value ...
-
[5]
If no partial square norm is outside the range, infi- nite or zero, we divide each element of the nodes of A by pF ||A||N −1,N F 1 2N , and repeat steps 2 and 5. We repeat the cycle until we obtain a valid A or we reach a stop condition, which entails repeating a certain maximum number of iterations. If we reach this last point, the protocol will have fai...
-
[6]
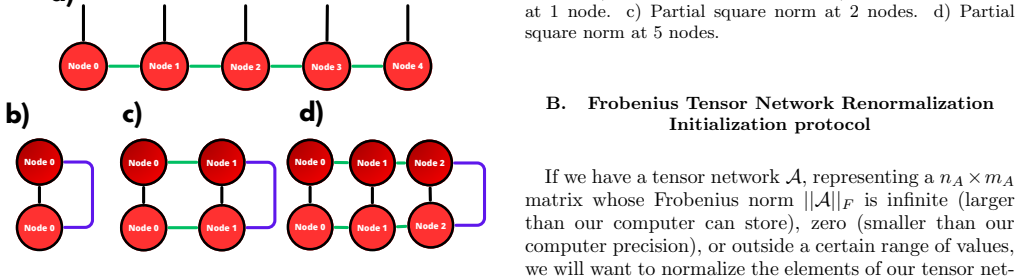
We initialize the node tensors with some initializa- 7 Node 2 Node 5Node 1 Node 9 Node 4 Node 8 Node 7 Node 3 Node 6 a) b) Node 1 c) Node 2 Node 1 d) Node 2 Node 5Node 1 Node 4 Node 3 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 FIG. 10. a) PEPS layer with 9 nodes. b) Partial lineal norm at 1 node. c) Partial lineal norm at 2 nodes. d) Partial lineal norm at 5 nodes...
-
[7]
If it is finite and non-zero, we divide each element of each node by ||A||L F 1/N and return A
We compute ||A||L. If it is finite and non-zero, we divide each element of each node by ||A||L F 1/N and return A. Otherwise, we continue
-
[8]
We compute pL||A||1,N. (a) If it is infinite, we divide each element of the nodes of A by (10(1+ξ))1/N, being ξ a random number between 0 and 1, and return to Step 2. (b) If it is zero, we multiply each element of the nodes of A by (10(1 + ξ))1/N and return to Step 2. (c) Otherwise, we save this value aspL||A||1,N and continue
-
[9]
For n ∈ [2, N − 1], we compute pL||A||n,N. (a) If it is infinite or zero, we divide each element of the nodes of A by (pL||A||n−1,N) 1 N , and re- peat Steps 2 and 4 (from this value of n). (b) If it is finite, but larger than b or smaller than a, we divide each element of the nodes of A by pL||A||n,N F 1 N , and repeat Steps 2 and 4 (from this value of n...
-
[10]
If no partial lineal norm is outside the range, infi- nite or zero, we divide each element of the nodes of A by pL||A||N −1,N F 1 N , and repeat steps 2 and 5. As in the general case, we repeat the cycle until we reach a stop condition, which will be to have repeated a certain maximum number of iterations. If we reach that point, the protocol will have fa...
-
[11]
Then, we check the number of steps against p for the same value of N = 25 and b = 10 in Fig. 12. Finally, we check the number of steps against b with the same value of N = 25 and p = 15 in Fig. 13. 5 10 15 20 25 30 Number of Nodes (N) 0 10 20 30 40 50Number of Steps p = 6 TT p = 6 TT-M p = 7 TT p = 7 TT-M p = 8 TT p = 8 TT-M p = 9 TT p = 9 TT-M p = 10 TT ...
-
[12]
to determine the appropriate decay factor and adapt it to quantum machine learning layers. ACKNOWLEDGMENTS The research leading to this paper has received funding from the Q4Real project (Quantum Computing for Real Industries), HAZITEK 2022, no. ZE-2022/00033
work page 2022
- [13]
-
[14]
LLaMA: Open and Efficient Foundation Language Models
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozi` ere, N. Goyal, E. Ham- bro, F. Azhar, A. Rodriguez, A. Joulin, E. Grave, and G. Lample, Llama: Open and efficient foundation lan- guage models (2023), arXiv:2302.13971 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [15]
-
[16]
J. Biamonte and V. Bergholm, Tensor networks in a nut- shell (2017), arXiv:1708.00006
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[17]
R. Or´ us, A practical introduction to tensor networks: Matrix product states and projected entangled pair states, Annals of Physics 349, 117–158 (2014)
work page 2014
-
[18]
Matrix Product State Representations
D. Perez-Garcia, F. Verstraete, M. M. Wolf, and J. I. Cirac, Matrix product state representations (2007), arXiv:quant-ph/0608197 [quant-ph]
work page internal anchor Pith review Pith/arXiv arXiv 2007
-
[19]
V. M. F. Verstraete and J. Cirac, Matrix prod- uct states, projected entangled pair states, and vari- ational renormalization group methods for quantum spin systems, Advances in Physics 57, 143 (2008), https://doi.org/10.1080/14789940801912366
-
[20]
A. Novikov, D. Podoprikhin, A. Osokin, and D. Vetrov, Tensorizing neural networks (2015), arXiv:1509.06569
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[21]
Z.-F. Gao, S. Cheng, R.-Q. He, Z. Y. Xie, H.-H. Zhao, Z.- Y. Lu, and T. Xiang, Compressing deep neural networks by matrix product operators, Phys. Rev. Res. 2, 023300 (2020)
work page 2020
-
[22]
Y. Qing, K. Li, P.-F. Zhou, and S.-J. Ran, Compressing neural networks using tensor networks with exponentially fewer variational parameters, Intelligent Computing 4, 10.34133/icomputing.0123 (2025)
- [23]
-
[24]
H. Li, J. Zhao, H. Huo, S. Fang, J. Chen, L. Yao, and Y. Hua, T3srs: Tensor train transformer for compressing sequential recommender systems, Expert Systems with Applications 238, 122260 (2024)
work page 2024
- [25]
-
[26]
B. Aizpurua, S. S. Jahromi, S. Singh, and R. Orus, Quan- tum large language models via tensor network disentan- glers (2024), arXiv:2410.17397 [quant-ph]
-
[27]
A. Tomut, S. S. Jahromi, A. Sarkar, U. Kurt, S. Singh, F. Ishtiaq, C. Mu˜ noz, P. S. Bajaj, A. Elborady, G. del 10 Bimbo, M. Alizadeh, D. Montero, P. Martin-Ramiro, M. Ibrahim, O. T. Alaoui, J. Malcolm, S. Mugel, and R. Orus, Compactifai: Extreme compression of large lan- guage models using quantum-inspired tensor networks (2024), arXiv:2401.14109 [cs.CL]
- [28]
-
[29]
P. Blagoveschensky and A. H. Phan, Deep convolutional tensor network (2020), arXiv:2005.14506
- [30]
-
[31]
R. Patel, C.-W. Hsing, S. Sahin, S. S. Jahromi, S. Palmer, S. Sharma, C. Michel, V. Porte, M. Abid, S. Aubert, P. Castellani, C.-G. Lee, S. Mugel, and R. Orus, Quantum-inspired tensor neural networks for partial dif- ferential equations (2022), arXiv:2208.02235
-
[32]
F. Barratt, J. Dborin, and L. Wright, Improvements to gradient descent methods for quantum tensor network machine learning (2022), arXiv:2203.03366
-
[33]
X. Glorot and Y. Bengio, Understanding the difficulty of training deep feedforward neural networks, in Pro- ceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics , Proceedings of Ma- chine Learning Research, Vol. 9, edited by Y. W. Teh and M. Titterington (PMLR, Chia Laguna Resort, Sardinia, Italy, 2010) pp. 249–256
work page 2010
- [34]
-
[35]
I. Oseledets and E. Tyrtyshnikov, Tt-cross approxima- tion for multidimensional arrays, Linear Algebra and its Applications 432, 70 (2010)
work page 2010
-
[36]
How to generate random matrices from the classical compact groups
F. Mezzadri, How to generate random matrices from the classical compact groups (2007), arXiv:math-ph/0609050 [math-ph]
work page internal anchor Pith review Pith/arXiv arXiv 2007
- [37]
- [38]
-
[39]
T. Hao, X. Huang, C. Jia, and C. Peng, A quantum- inspired tensor network algorithm for constrained combi- natorial optimization problems, Frontiers in Physics 10, 10.3389/fphy.2022.906590 (2022)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.