Temporal Transfer Learning for Traffic Optimization with Coarse-grained Advisory Autonomy
Pith reviewed 2026-05-24 06:16 UTC · model grok-4.3
The pith
Temporal Transfer Learning selects the most suitable source tasks to solve the full range of traffic advisory tasks without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce Temporal Transfer Learning (TTL) algorithms to select source tasks for zero-shot transfer, systematically leveraging the temporal structure to solve the full range of tasks. TTL selects the most suitable source tasks to maximize the performance of the range of tasks. We validate our algorithms on diverse mixed-traffic scenarios, demonstrating that TTL more reliably solves the tasks than baselines. This paper underscores the potential of coarse-grained advisory autonomy with TTL in traffic flow optimization.
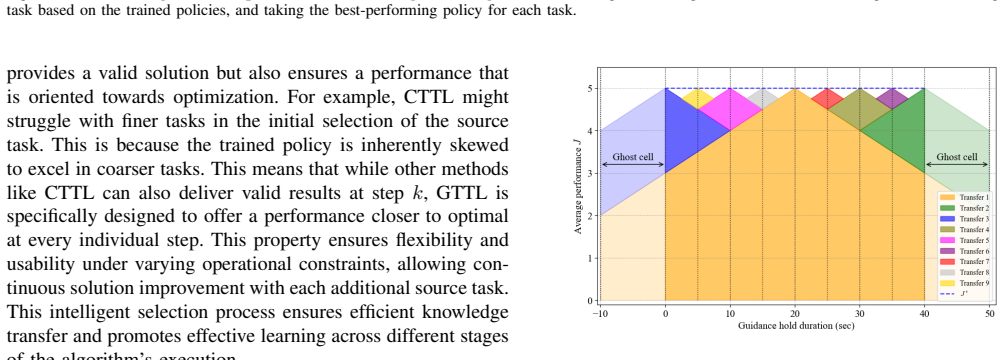
What carries the argument
Temporal Transfer Learning (TTL) algorithms that select source tasks by exploiting the temporal structure of zero-order hold durations for zero-shot transfer to target advisory tasks.
If this is right
- TTL produces policies that handle the entire range of hold durations from 0.1 to 40 seconds after training only on selected sources.
- Advisory autonomy can achieve near-term traffic speed and throughput gains comparable to automated vehicles without full automation.
- Direct deep reinforcement learning does not generalize across different hold durations, but TTL overcomes this limitation.
- Validation shows TTL solves mixed-traffic advisory tasks more reliably than baseline transfer methods.
Where Pith is reading between the lines
- The same selection logic based on temporal similarity could apply to other sequential decision tasks whose update rates vary over orders of magnitude.
- If hold-duration structure proves predictive, designers of real-time advisory systems could pre-compute a small library of source policies rather than retraining continuously.
- Field trials with actual human drivers would test whether the temporal transfer remains stable when driver response noise is added to the simulation.
Load-bearing premise
The temporal structure of hold durations can be systematically leveraged by TTL to enable effective zero-shot transfer across the full range of advisory tasks without retraining.
What would settle it
A comparison experiment in which TTL-selected source policies fail to outperform both direct reinforcement learning and random source selection on target hold durations across the tested mixed-traffic scenarios.
Figures











read the original abstract
The recent development of connected and automated vehicle (CAV) technologies has spurred investigations to optimize dense urban traffic to maximize vehicle speed and throughput. This paper explores advisory autonomy, in which real-time driving advisories are issued to the human drivers, thus achieving near-term performance of automated vehicles. Due to the complexity of traffic systems, recent studies of coordinating CAVs have resorted to leveraging deep reinforcement learning (RL). Coarse-grained advisory is formalized as zero-order holds, and we consider a range of hold duration from 0.1 to 40 seconds. However, despite the similarity of the higher frequency tasks on CAVs, a direct application of deep RL fails to be generalized to advisory autonomy tasks. To overcome this, we utilize zero-shot transfer, training policies on a set of source tasks--specific traffic scenarios with designated hold durations--and then evaluating the efficacy of these policies on different target tasks. We introduce Temporal Transfer Learning (TTL) algorithms to select source tasks for zero-shot transfer, systematically leveraging the temporal structure to solve the full range of tasks. TTL selects the most suitable source tasks to maximize the performance of the range of tasks. We validate our algorithms on diverse mixed-traffic scenarios, demonstrating that TTL more reliably solves the tasks than baselines. This paper underscores the potential of coarse-grained advisory autonomy with TTL in traffic flow optimization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Temporal Transfer Learning (TTL) algorithms, which select source tasks by exploiting the temporal structure of zero-order hold durations (0.1–40 s), enable effective zero-shot transfer of deep RL policies for coarse-grained advisory autonomy in mixed-traffic scenarios, outperforming direct RL application and baselines across the full range of advisory tasks.
Significance. If the empirical validation holds, the result would be significant for practical CAV advisory systems, as it offers a way to cover a wide temporal range of control tasks without per-task retraining. The approach of systematically leveraging hold-duration similarity for policy transfer is a concrete contribution at the intersection of transfer RL and traffic optimization.
major comments (2)
- [Abstract] Abstract: the central claim that TTL 'more reliably solves the tasks than baselines' is load-bearing for the paper's contribution, yet the abstract supplies no quantitative metrics, tables, success rates, or statistical comparisons; without these the magnitude and reliability of the improvement cannot be evaluated.
- [Abstract] Abstract (validation paragraph): the statement that TTL 'systematically leveraging the temporal structure' enables zero-shot transfer across the full range rests on an unstated mechanism for source selection; no definition of the selection criterion, similarity metric, or hold-duration encoding is supplied, which is required to assess whether the transfer actually exploits temporal structure rather than generic task similarity.
minor comments (1)
- [Abstract] Abstract: the phrase 'diverse mixed-traffic scenarios' is used without specifying the traffic densities, CAV penetration rates, or network topologies employed in validation.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on the abstract. We address each major comment below and will revise the abstract accordingly in the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that TTL 'more reliably solves the tasks than baselines' is load-bearing for the paper's contribution, yet the abstract supplies no quantitative metrics, tables, success rates, or statistical comparisons; without these the magnitude and reliability of the improvement cannot be evaluated.
Authors: We agree that the abstract should include quantitative support for the central claim. In the revised manuscript we will add specific metrics (e.g., success rates or normalized performance gains with standard deviations) comparing TTL to the direct-RL and baseline methods across the hold-duration range. revision: yes
-
Referee: [Abstract] Abstract (validation paragraph): the statement that TTL 'systematically leveraging the temporal structure' enables zero-shot transfer across the full range rests on an unstated mechanism for source selection; no definition of the selection criterion, similarity metric, or hold-duration encoding is supplied, which is required to assess whether the transfer actually exploits temporal structure rather than generic task similarity.
Authors: The full manuscript defines the TTL source-selection procedure (temporal proximity of zero-order hold durations together with a similarity metric on the resulting task embeddings) in Section 3. We nevertheless accept that the abstract must briefly state this mechanism rather than only allude to it. The revised abstract will include a concise clause describing the selection criterion and its use of hold-duration structure. revision: yes
Circularity Check
No significant circularity
full rationale
The paper defines TTL as an algorithm that selects source tasks to maximize performance across hold-duration tasks and validates this via empirical results on mixed-traffic scenarios, outperforming baselines. No load-bearing step reduces by construction to its inputs, no fitted parameter is relabeled as a prediction, and no self-citation chain is invoked to justify uniqueness or ansatz. The derivation chain is self-contained through external empirical testing rather than tautological redefinition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Traffic dynamics can be effectively modeled as Markov decision processes suitable for deep RL training
invented entities (1)
-
Temporal Transfer Learning (TTL) algorithms
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Emergent Behaviors in Mixed-Autonomy Traffic,
C. Wu, A. Kreidieh, E. Vinitsky, and A. M. Bayen, “Emergent Behaviors in Mixed-Autonomy Traffic,” in Proceedings of the 1st Annual Conference on Robot Learning . PMLR, Oct. 2017, pp. 398–407, iSSN: 2640-3498. [Online]. Available: https://proceedings. mlr.press/v78/wu17a.html
work page 2017
-
[2]
Dissipation of stop-and-go waves via control of autonomous vehicles: Field experiments,
R. E. Stern, S. Cui, M. L. Delle Monache, R. Bhadani, M. Bunting, M. Churchill, N. Hamilton, R. Haulcy, H. Pohlmann, F. Wu, B. Piccoli, B. Seibold, J. Sprinkle, and D. B. Work, “Dissipation of stop-and-go waves via control of autonomous vehicles: Field experiments,” Transportation Research Part C: Emerging Technologies, vol. 89, pp. 205–221, Apr. 2018. [O...
work page 2018
-
[3]
Piecewise Constant Policies for Human- Compatible Congestion Mitigation,
M. Sridhar and C. Wu, “Piecewise Constant Policies for Human- Compatible Congestion Mitigation,” in 2021 IEEE International Intelligent Transportation Systems Conference (ITSC) . Indianapolis, IN, USA: IEEE, Sep. 2021, pp. 2499–2505. [Online]. Available: https://ieeexplore.ieee.org/document/9564789/
-
[4]
Reinforcement Learning for Mixed Autonomy Intersections,
Z. Yan and C. Wu, “Reinforcement Learning for Mixed Autonomy Intersections,” in 2021 IEEE International Intelligent Transportation Systems Conference (ITSC) , Sep. 2021, pp. 2089–2094, arXiv:2111.04686 [cs, eess]. [Online]. Available: http://arxiv.org/abs/2111.04686
-
[5]
Flow: A Modular Learning Framework for Mixed Autonomy Traffic,
C. Wu, A. R. Kreidieh, K. Parvate, E. Vinitsky, and A. M. Bayen, “Flow: A Modular Learning Framework for Mixed Autonomy Traffic,” IEEE Transactions on Robotics , vol. 38, no. 2, pp. 1270–1286, Apr. 2022. [Online]. Available: https://ieeexplore.ieee.org/document/9489303/
-
[6]
Unified Automatic Control of Vehicular Systems With Reinforcement Learning,
Z. Yan, A. R. Kreidieh, E. Vinitsky, A. M. Bayen, and C. Wu, “Unified Automatic Control of Vehicular Systems With Reinforcement Learning,” IEEE Transactions on Automation Science and Engineering , pp. 1– 16, 2022. [Online]. Available: https://ieeexplore.ieee.org/document/ 9765650/
work page 2022
-
[7]
Transfer Learning for Reinforcement Learn- ing Domains: A Survey,
M. E. Taylor and P. Stone, “Transfer Learning for Reinforcement Learn- ing Domains: A Survey,” The Journal of Machine Learning Research , vol. 10, pp. 1633–1685, Dec. 2009
work page 2009
-
[8]
A Survey on Transfer Learning,
S. J. Pan and Q. Yang, “A Survey on Transfer Learning,” IEEE Transactions on Knowledge and Data Engineering , vol. 22, no. 10, pp. 1345–1359, Oct. 2010, conference Name: IEEE Transactions on Knowledge and Data Engineering
work page 2010
-
[9]
Dissipating stop-and-go waves in closed and open networks via deep reinforcement learning,
A. R. Kreidieh, C. Wu, and A. M. Bayen, “Dissipating stop-and-go waves in closed and open networks via deep reinforcement learning,” in 2018 21st International Conference on Intelligent Transportation Systems (ITSC). Maui, HI: IEEE, Nov. 2018, pp. 1475–1480. [Online]. Available: https://ieeexplore.ieee.org/document/8569485/
-
[10]
Simulation to Scaled City: Zero-Shot Policy Transfer for Traffic Control via Autonomous Vehicles
K. Jang, E. Vinitsky, B. Chalaki, B. Remer, L. Beaver, A. Malikopoulos, and A. Bayen, “Simulation to Scaled City: Zero-Shot Policy Transfer for Traffic Control via Autonomous Vehicles,” Feb. 2019, arXiv:1812.06120 [cs]. [Online]. Available: http://arxiv.org/abs/1812.06120 19 TABLE III EXPERIMENTAL PARAMETERS FOR REINFORCEMENT LEARNING , T EMPORAL TRANSFER...
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[11]
Lagrangian Control through Deep-RL: Applications to Bottleneck Decongestion,
E. Vinitsky, K. Parvate, A. Kreidieh, C. Wu, and A. Bayen, “Lagrangian Control through Deep-RL: Applications to Bottleneck Decongestion,” in 2018 21st International Conference on Intelligent Transportation Systems (ITSC) . Maui, HI: IEEE, Nov. 2018, pp. 759–765. [Online]. Available: https://ieeexplore.ieee.org/document/8569615/
-
[12]
Intelligent vehicle applications worldwide,
R. Bishop, “Intelligent vehicle applications worldwide,” IEEE Intelligent Systems and their Applications , vol. 15, no. 1, pp. 78–81, Jan. 2000, conference Name: IEEE Intelligent Systems and their Applications
work page 2000
-
[13]
K. Katsaros, R. Kernchen, M. Dianati, and D. Rieck, “Performance study of a Green Light Optimized Speed Advisory (GLOSA) application using an integrated cooperative ITS simulation platform,” in 2011 7th Inter- national Wireless Communications and Mobile Computing Conference , Jul. 2011, pp. 918–923, iSSN: 2376-6506
work page 2011
-
[14]
A Closed- Loop Speed Advisory Model With Driver’s Behavior Adaptability for Eco-Driving,
X. Xiang, K. Zhou, W.-B. Zhang, W. Qin, and Q. Mao, “A Closed- Loop Speed Advisory Model With Driver’s Behavior Adaptability for Eco-Driving,” IEEE Transactions on Intelligent Transportation Systems, vol. 16, no. 6, pp. 3313–3324, Dec. 2015, conference Name: IEEE Transactions on Intelligent Transportation Systems
work page 2015
-
[15]
A. Hasan, N. Chakraborty, H. Chen, J.-H. Cho, C. Wu, and K. Driggs- Campbell, “PeRP: Personalized residual policies for congestion miti- gation through co-operative advisory systems,” in IEEE International Conference on Intelligent Transportation Systems (ITSC) , 2023
work page 2023
-
[16]
B. Mok, M. Johns, K. J. Lee, D. Miller, D. Sirkin, P. Ive, and W. Ju, “Emergency, Automation Off: Unstructured Transition Timing for Distracted Drivers of Automated Vehicles,” in 2015 IEEE 18th International Conference on Intelligent Transportation Systems . Gran Canaria, Spain: IEEE, Sep. 2015, pp. 2458–2464. [Online]. Available: http://ieeexplore.ieee.o...
-
[17]
Stabilization Guarantees of Human- Compatible Control via Lyapunov Analysis,
S. Li, R. Dong, and C. Wu, “Stabilization Guarantees of Human- Compatible Control via Lyapunov Analysis,” in 2023 European Control Conference (ECC), Jun. 2023, pp. 1–8
work page 2023
-
[18]
Between MDPs and semi-MDPs: A framework for temporal abstraction in reinforcement learning,
R. S. Sutton, D. Precup, and S. Singh, “Between MDPs and semi-MDPs: A framework for temporal abstraction in reinforcement learning,” Artificial Intelligence , vol. 112, no. 1, pp. 181–211, Aug. 1999. [Online]. Available: https://www.sciencedirect.com/science/ article/pii/S0004370299000521
work page 1999
-
[19]
Dynamic Action Repetition for Deep Reinforcement Learning,
A. Lakshminarayanan, S. Sharma, and B. Ravindran, “Dynamic Action Repetition for Deep Reinforcement Learning,” Proceedings of the AAAI Conference on Artificial Intelligence, vol. 31, no. 1, Feb. 2017. [Online]. Available: https://ojs.aaai.org/index.php/AAAI/article/view/10918
work page 2017
-
[20]
Learning to Repeat: Fine Grained Action Repetition for Deep Reinforcement Learning,
S. Sharma, A. Srinivas, and B. Ravindran, “Learning to Repeat: Fine Grained Action Repetition for Deep Reinforcement Learning,” Sep. 2020, arXiv:1702.06054 [cs]. [Online]. Available: http://arxiv.org/abs/ 1702.06054
-
[21]
TempoRL: Learning When to Act,
A. Biedenkapp, R. Rajan, F. Hutter, and M. Lindauer, “TempoRL: Learning When to Act,” in Proceedings of the 38th International Conference on Machine Learning . PMLR, Jul. 2021, pp. 914–924, iSSN: 2640-3498. [Online]. Available: https://proceedings.mlr.press/ v139/biedenkapp21a.html
work page 2021
-
[22]
Control Frequency Adaptation via Action Persistence in Batch Reinforcement Learning,
A. M. Metelli, F. Mazzolini, L. Bisi, L. Sabbioni, and M. Restelli, “Control Frequency Adaptation via Action Persistence in Batch Reinforcement Learning,” in Proceedings of the 37th International Conference on Machine Learning . PMLR, Nov. 2020, pp. 6862–6873, iSSN: 2640-3498. [Online]. Available: https://proceedings.mlr.press/ v119/metelli20a.html
work page 2020
-
[23]
Reinforcement Learning for Control with Multiple Frequencies,
J. Lee, B.-J. Lee, and K.-E. Kim, “Reinforcement Learning for Control with Multiple Frequencies,” in Advances in Neural Information Processing Systems, vol. 33. Curran Associates, Inc., 2020, pp. 3254–
work page 2020
-
[24]
[Online]. Available: https://proceedings.neurips.cc/paper files/ paper/2020/hash/216f44e2d28d4e175a194492bde9148f-Abstract.html
work page 2020
-
[25]
A theory of transfer learning with applications to active learning,
L. Yang, S. Hanneke, and J. Carbonell, “A theory of transfer learning with applications to active learning,” Machine Learning , vol. 90, no. 2, pp. 161–189, Feb. 2013. [Online]. Available: http://link.springer.com/10.1007/s10994-012-5310-y
-
[26]
Multi-robot transfer learning: A dynamical system perspective,
M. K. Helwa and A. P. Schoellig, “Multi-robot transfer learning: A dynamical system perspective,” in 2017 IEEE/RSJ International Con- ference on Intelligent Robots and Systems (IROS) , Sep. 2017, pp. 4702– 4708, iSSN: 2153-0866
work page 2017
-
[27]
An introduction to domain adaptation and transfer learning
W. M. Kouw and M. Loog, “An introduction to domain adaptation and transfer learning,” Jan. 2019, arXiv:1812.11806 [cs, stat]. [Online]. Available: http://arxiv.org/abs/1812.11806
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[28]
On the Theory of Transfer Learning: The Importance of Task Diversity,
N. Tripuraneni, M. Jordan, and C. Jin, “On the Theory of Transfer Learning: The Importance of Task Diversity,” in Advances in Neural Information Processing Systems , vol. 33. Curran Associates, Inc., 2020, pp. 7852–7862. [Online]. Available: https://proceedings.neurips. cc/paper/2020/hash/59587bffec1c7846f3e34230141556ae-Abstract.html 20
work page 2020
-
[29]
Task Relatedness-Based Generalization Bounds for Meta Learning,
J. Guan and Z. Lu, “Task Relatedness-Based Generalization Bounds for Meta Learning,” in International Conference on Learning Representations, Jan. 2022. [Online]. Available: https://openreview.net/ forum?id=A3HHaEdqAJL
work page 2022
-
[30]
DARLA: Improving Zero-Shot Transfer in Reinforcement Learning
I. Higgins, A. Pal, A. A. Rusu, L. Matthey, C. P. Burgess, A. Pritzel, M. Botvinick, C. Blundell, and A. Lerchner, “DARLA: Improving Zero- Shot Transfer in Reinforcement Learning,” Jun. 2018, arXiv:1707.08475 [cs, stat]. [Online]. Available: http://arxiv.org/abs/1707.08475
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[31]
Sim-to-Real Robot Learning from Pixels with Progressive Nets
A. A. Rusu, M. Vecerik, T. Roth ¨orl, N. Heess, R. Pascanu, and R. Hadsell, “Sim-to-Real Robot Learning from Pixels with Progressive Nets,” May 2018, arXiv:1610.04286 [cs]. [Online]. Available: http://arxiv.org/abs/1610.04286
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[32]
Inter-Level Cooperation in Hierarchical Reinforcement Learning,
A. R. Kreidieh, G. Berseth, B. Trabucco, S. Parajuli, S. Levine, and A. M. Bayen, “Inter-Level Cooperation in Hierarchical Reinforcement Learning,” Nov. 2021, arXiv:1912.02368 [cs, stat]. [Online]. Available: http://arxiv.org/abs/1912.02368
-
[33]
Transfer learning for spatio-temporal transferability of real-time crash prediction models,
C. K. Man, M. Quddus, and A. Theofilatos, “Transfer learning for spatio-temporal transferability of real-time crash prediction models,” Accident Analysis & Prevention , vol. 165, p. 106511, Feb
-
[34]
Available: https://linkinghub.elsevier.com/retrieve/pii/ S000145752100542X
[Online]. Available: https://linkinghub.elsevier.com/retrieve/pii/ S000145752100542X
-
[35]
Transfer learning to improve streamflow forecasts in data sparse regions,
R. Oruche, L. Egede, T. Baker, and F. O’Donncha, “Transfer learning to improve streamflow forecasts in data sparse regions,” Dec. 2021, arXiv:2112.03088 [cs]. [Online]. Available: http://arxiv.org/abs/2112. 03088
-
[36]
Learning What and Where to Transfer
Y . Jang, H. Lee, S. J. Hwang, and J. Shin, “Learning What and Where to Transfer,” May 2019, arXiv:1905.05901 [cs, stat]. [Online]. Available: http://arxiv.org/abs/1905.05901
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[37]
Learning Inter-Task Transferability in the Absence of Target Task Samples,
J. Sinapov, S. Narvekar, M. Leonetti, and P. Stone, “Learning Inter-Task Transferability in the Absence of Target Task Samples,” in Proceedings of the 14th International Conference on Autonomous Agents and Multi- agent Systems (AAMAS 2015) , May 2015
work page 2015
-
[38]
S. Li, F. Gu, G. Zhu, and C. Zhang, “Context-Aware Policy Reuse,” Mar. 2019, arXiv:1806.03793 [cs] version: 4. [Online]. Available: http://arxiv.org/abs/1806.03793
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[39]
Transferability Metrics for Selecting Source Model Ensembles,
A. Agostinelli, J. Uijlings, T. Mensink, and V . Ferrari, “Transferability Metrics for Selecting Source Model Ensembles,” in 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) . New Orleans, LA, USA: IEEE, Jun. 2022, pp. 7926–7936. [Online]. Available: https://ieeexplore.ieee.org/document/9878724/
-
[40]
Expert Level Control of Ramp Metering Based on Multi-Task Deep Reinforcement Learning,
F. Belletti, D. Haziza, G. Gomes, and A. M. Bayen, “Expert Level Control of Ramp Metering Based on Multi-Task Deep Reinforcement Learning,” IEEE Transactions on Intelligent Transportation Systems , vol. 19, no. 4, pp. 1198–1207, Apr. 2018. [Online]. Available: http://ieeexplore.ieee.org/document/8011495/
-
[41]
Coarse-to-fine: A RNN-based hierarchical attention model for vehicle re-identification
X.-S. Wei, C.-L. Zhang, L. Liu, C. Shen, and J. Wu, “Coarse- to-fine: A RNN-based hierarchical attention model for vehicle re- identification,” Dec. 2018, arXiv:1812.04239 [cs]. [Online]. Available: http://arxiv.org/abs/1812.04239
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[42]
Y . Wang, R. Liu, D. Lin, D. Chen, P. Li, Q. Hu, and C. L. P. Chen, “Coarse-to-Fine: Progressive Knowledge Transfer-Based Multitask Con- volutional Neural Network for Intelligent Large-Scale Fault Diagnosis,” IEEE Transactions on Neural Networks and Learning Systems , vol. 34, no. 2, pp. 761–774, Feb. 2023, conference Name: IEEE Transactions on Neural Net...
work page 2023
-
[43]
Towards Co-operative Congestion Mitigation,
A. Hasan, N. Chakraborty, C. Wu, and K. Driggs-Campbell, “Towards Co-operative Congestion Mitigation,” Feb. 2023, arXiv:2302.09140 [cs]. [Online]. Available: http://arxiv.org/abs/2302.09140
-
[44]
Understanding and Modeling the Human Driver,
C. C. Macadam, “Understanding and Modeling the Human Driver,” Vehicle System Dynamics , vol. 40, no. 1-3, pp. 101–134, Jan. 2003. [Online]. Available: http://www.tandfonline.com/doi/abs/10.1076/vesd. 40.1.101.15875
-
[45]
Dynamical model of traffic congestion and numerical simulation,
M. Bando, K. Hasebe, A. Nakayama, A. Shibata, and Y . Sugiyama, “Dynamical model of traffic congestion and numerical simulation,” Physical Review E , vol. 51, no. 2, pp. 1035–1042, Feb. 1995. [Online]. Available: https://link.aps.org/doi/10.1103/PhysRevE.51.1035
-
[46]
Optimal velocity model for traffic flow,
Y . Sugiyama, “Optimal velocity model for traffic flow,” Computer Physics Communications , vol. 121-122, pp. 399–401, Sep
-
[47]
Available: https://linkinghub.elsevier.com/retrieve/pii/ S0010465599003665
[Online]. Available: https://linkinghub.elsevier.com/retrieve/pii/ S0010465599003665
-
[48]
X. J. Liang, S. I. Guler, and V . V . Gayah, “Joint Optimization of Signal Phasing and Timing and Vehicle Speed Guidance in a Connected and Autonomous Vehicle Environment,” Transportation Research Record: Journal of the Transportation Research Board , vol. 2673, no. 4, pp. 70–83, Apr. 2019. [Online]. Available: http://journals.sagepub.com/doi/10.1177/0361...
-
[49]
S. Liu, W. Zhang, X. Wu, S. Feng, X. Pei, and D. Yao, “A simulation system and speed guidance algorithms for intersection traffic control using connected vehicle technology,” Tsinghua Science and Technology, vol. 24, no. 2, pp. 160–170, Apr. 2019. [Online]. Available: https://ieeexplore.ieee.org/document/8595295/
-
[50]
X. Ma, X. Hu, S. Schweig, J. Pragalathan, and D. Schramm, “A Vehicle Guidance Model with a Close-to-Reality Driver Model and Different Levels of Vehicle Automation,” Applied Sciences , vol. 11, no. 1, p. 380, Jan. 2021. [Online]. Available: https: //www.mdpi.com/2076-3417/11/1/380
work page 2021
-
[51]
Z. Wang, M. Abdel-Aty, L. Yue, J. Zhu, O. Zheng, and M. H. Zaki, “Investigating the Effects of Human-Machine Interface on Cooperative Driving Using a Multi-Driver Co-Simulation Platform,” IEEE Transac- tions on Intelligent Vehicles , pp. 1–14, 2023, conference Name: IEEE Transactions on Intelligent Vehicles
work page 2023
-
[52]
An empirical analysis of driver perceptions of the relationship between speed limits and safety,
F. Mannering, “An empirical analysis of driver perceptions of the relationship between speed limits and safety,” Transportation Research Part F: Traffic Psychology and Behaviour , vol. 12, no. 2, pp. 99–106, Mar. 2009. [Online]. Available: https://www.sciencedirect.com/science/ article/pii/S1369847808000752
work page 2009
-
[53]
The Impact of Task Underspecification in Evaluating Deep Reinforcement Learning,
V . Jayawardana, C. Tang, S. Li, D. Suo, and C. Wu, “The Impact of Task Underspecification in Evaluating Deep Reinforcement Learning,” in Advances in Neural Information Processing Systems , S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, Eds., vol. 35. Curran Associates, Inc., 2022, pp. 23 881–23 893. [Online]. Available: https://procee...
work page 2022
-
[54]
On the Generalization Gap in Reparameterizable Reinforcement Learning,
H. Wang, S. Zheng, C. Xiong, and R. Socher, “On the Generalization Gap in Reparameterizable Reinforcement Learning,” in Proceedings of the 36th International Conference on Machine Learning . PMLR, May 2019, pp. 6648–6658, iSSN: 2640-3498. [Online]. Available: https://proceedings.mlr.press/v97/wang19o.html
work page 2019
-
[55]
Contextualize Me – The Case for Context in Reinforcement Learning,
C. Benjamins, T. Eimer, F. Schubert, A. Mohan, S. D ¨ohler, A. Biedenkapp, B. Rosenhahn, F. Hutter, and M. Lindauer, “Contextualize Me – The Case for Context in Reinforcement Learning,” Transactions on Machine Learning Research , Jun. 2023, arXiv:2202.04500 [cs] version: 2. [Online]. Available: http://arxiv.org/abs/2202.04500
-
[56]
Multi-objective Evolution for Generalizable Policy Gradient Algorithms,
J. J. Garau-Luis, Y . Miao, J. D. Co-Reyes, A. Parisi, J. Tan, E. Real, and A. Faust, “Multi-objective Evolution for Generalizable Policy Gradient Algorithms,” in Generalizable Policy Learning in the Physical World Workshop (ICLR 2022), 2022
work page 2022
-
[57]
Congested traffic states in empirical observations and microscopic simulations
M. Treiber, A. Hennecke, and D. Helbing, “Congested Traffic States in Empirical Observations and Microscopic Simulations,” Physical Review E, vol. 62, no. 2, pp. 1805–1824, Aug. 2000, arXiv:cond-mat/0002177. [Online]. Available: http://arxiv.org/abs/cond-mat/0002177
work page internal anchor Pith review Pith/arXiv arXiv 2000
-
[58]
Microscopic traffic simulation using sumo,
P. A. Lopez, M. Behrisch, L. Bieker-Walz, J. Erdmann, Y .-P. Fl ¨otter¨od, R. Hilbrich, L. L ¨ucken, J. Rummel, P. Wagner, and E. Wießner, “Microscopic traffic simulation using sumo,” in The 21st IEEE International Conference on Intelligent Transportation Systems . IEEE,
- [59]
-
[60]
Interactive Supercomputing on 40,000 Cores for Machine Learning and Data Analysis,
A. Reuther, J. Kepner, C. Byun, S. Samsi, W. Arcand, D. Bestor, B. Bergeron, V . Gadepally, M. Houle, M. Hubbell, M. Jones, A. Klein, L. Milechin, J. Mullen, A. Prout, A. Rosa, C. Yee, and P. Michaleas, “Interactive Supercomputing on 40,000 Cores for Machine Learning and Data Analysis,” in 2018 IEEE High Performance extreme Computing Conference (HPEC) , S...
-
[61]
Trust Region Policy Optimization
J. Schulman, S. Levine, P. Moritz, M. I. Jordan, and P. Abbeel, “Trust Region Policy Optimization,” Apr. 2017, arXiv:1502.05477 [cs]. [Online]. Available: http://arxiv.org/abs/1502.05477
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[62]
Y . Sugiyama, M. Fukui, M. Kikuchi, K. Hasebe, A. Nakayama, K. Nishinari, S.-i. Tadaki, and S. Yukawa, “Traffic jams without bottlenecks—experimental evidence for the physical mechanism of the formation of a jam,” New Journal of Physics , vol. 10, no. 3, p. 033001, Mar. 2008. [Online]. Available: https://iopscience.iop.org/ article/10.1088/1367-2630/10/3/033001
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.