An Insight into Security Code Review with LLMs: Capabilities, Obstacles, and Influential Factors
Pith reviewed 2026-05-24 04:44 UTC · model grok-4.3
The pith
Large language models outperform static analysis tools at detecting security defects in code.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
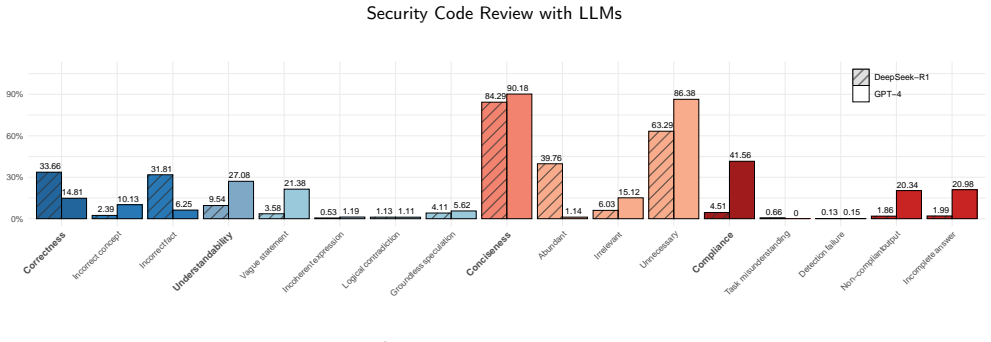
The study finds that LLMs significantly outperform state-of-the-art static analysis tools in security code review, with the reasoning-optimized model DeepSeek-R1 achieving the highest performance. DeepSeek-R1 works best when prompts include both the commit message and chain-of-thought guidance, while GPT-4 via ChatGPT performs best with a Common Weakness Enumeration list in the prompt. GPT-4 often produces vague expressions and struggles to follow instructions exactly, whereas DeepSeek-R1 more frequently generates inaccurate code details. LLMs detect defects more readily in files with fewer tokens and fewer security-relevant annotations, and higher code complexity improves DeepSeek-R1's rate
What carries the argument
Comparative evaluation of seven LLMs under five prompt variants against static analysis baselines on security defect detection, followed by linguistic analysis of outputs and regression on code features.
If this is right
- LLMs achieve higher detection performance than static analysis tools across the evaluated scenarios.
- Prompt design must be tailored to the specific LLM, as optimal strategies differ between reasoning-optimized and general models.
- Detection success rises for code files containing fewer tokens and fewer security annotations.
- For DeepSeek-R1, higher code complexity correlates with better detection on certain defect types.
Where Pith is reading between the lines
- Teams could insert LLMs as an initial filter to reduce the volume of issues passed to human reviewers or static tools.
- Response quality problems such as vagueness or inaccurate details suggest that raw LLM output would still require human verification or additional tooling.
- The observed sensitivity to code length and complexity points to possible value in segmenting large files before LLM review.
Load-bearing premise
The chosen code samples, defect types, and comparison metrics fairly represent real-world security code review tasks without prompt variations introducing bias that favors the LLMs.
What would settle it
Running the top-performing LLMs on an independent set of production code commits containing verified security defects and checking whether the outperformance over static tools still appears.
Figures









read the original abstract
Security code review is a time-consuming and labor-intensive process typically requiring integration with automated security defect detection tools. However, existing security analysis tools struggle with poor generalization, high false positive rates, and coarse detection granularity. Large Language Models (LLMs) have been considered promising candidates for addressing those challenges. In this study, we conducted an empirical study to explore the potential of LLMs in detecting security defects during code review. Specifically, we evaluated the performance of seven LLMs under five different prompts and compared them with state-of-the-art static analysis tools. We also performed linguistic and regression analyses for the two top-performing LLMs to identify quality problems in their responses and factors influencing their performance. Our findings show that: (1) In security code review, LLMs significantly outperform state-of-the-art static analysis tools, and the reasoning-optimized LLM performs better than general-purpose LLMs. (2) DeepSeek-R1 achieves the highest performance, followed by GPT-4 provided in the ChatGPT platform. The optimal prompt for DeepSeek-R1 incorporates both the commit message and chain-of-thought (CoT) guidance, while for GPT-4 via ChatGPT, the prompt with a Common Weakness Enumeration (CWE) list works best. (3) GPT-4 via ChatGPT frequently produces vague expressions and exhibits difficulties in accurately following instructions in the prompts, while DeepSeek-R1 more commonly generates inaccurate code details in its outputs. (4) LLMs are more adept at identifying security defects in code files that have fewer tokens and security-relevant annotations. (5) Higher code complexity correlates with enhanced detection capabilities of DeepSeek-R1 for specific security defect types.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports an empirical study evaluating seven LLMs (including reasoning-optimized models) across five prompt variants for security defect detection during code review. It compares LLM performance against state-of-the-art static analysis tools on the same tasks, then conducts linguistic and regression analyses on the top two LLMs (DeepSeek-R1 and GPT-4 via ChatGPT) to examine response quality issues and factors such as token count, annotations, and code complexity that influence detection rates. The central claims are that LLMs significantly outperform static tools, that prompt design and model type matter, and that specific factors correlate with better LLM performance on certain defect types.
Significance. If the empirical comparisons and factor analyses hold under equivalent conditions, the work supplies concrete evidence that LLMs can address limitations of static analyzers (generalization, false positives, granularity) in security code review and identifies actionable prompt and input characteristics for deployment. The multi-model, multi-prompt design plus regression analysis on influencing factors adds practical value beyond single-model case studies.
major comments (2)
- [Findings (1) and (2); Methods section on static-tool baseline] The headline claim in finding (1) that LLMs significantly outperform SOTA static analysis tools is load-bearing, yet the manuscript provides no explicit description of the input parity or configuration given to the static tools. Finding (2) shows that LLM performance improves when prompts include commit messages or CWE lists; if static tools were run only on default settings without equivalent context, the measured gap cannot be attributed solely to model capability (see skeptic note on input parity).
- [Dataset and experimental setup; Finding (4)] The evaluation assumes the chosen code samples and defect types fairly represent real-world security review tasks. No details are supplied on dataset size, selection criteria, language distribution, or whether samples were curated post-hoc; combined with finding (4) that LLMs perform better on shorter files with annotations, this raises the possibility that the dataset favors LLM strengths while under-representing the conditions where static tools are typically applied.
minor comments (2)
- [Abstract; Finding (2)] The abstract and findings refer to 'DeepSeek-R1' without clarifying whether this is a specific model variant, a fine-tune, or a platform name; consistent nomenclature is needed in the methods section.
- [Regression analysis subsection] The regression analysis in the linguistic/regression section would benefit from reporting exact coefficients, p-values, and model fit statistics rather than qualitative statements about correlations.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on clarifying our experimental setup and dataset. We address the major comments point by point below.
read point-by-point responses
-
Referee: [Findings (1) and (2); Methods section on static-tool baseline] The headline claim in finding (1) that LLMs significantly outperform SOTA static analysis tools is load-bearing, yet the manuscript provides no explicit description of the input parity or configuration given to the static tools. Finding (2) shows that LLM performance improves when prompts include commit messages or CWE lists; if static tools were run only on default settings without equivalent context, the measured gap cannot be attributed solely to model capability (see skeptic note on input parity).
Authors: We agree that the Methods section does not explicitly describe the configurations and inputs provided to the static analysis tools. Static analysis tools are designed to operate on source code alone and do not natively accept commit messages or CWE lists in the manner of LLM prompts. We ran each tool on the identical code samples used for the LLM evaluations, using their standard/default configurations as is conventional for such baselines. We will revise the manuscript to add an explicit subsection detailing the exact tool versions, settings, and rule sets applied, along with a note that contextual elements like commit messages are outside the design scope of static analyzers. This will strengthen the attribution of the observed performance differences. revision: yes
-
Referee: [Dataset and experimental setup; Finding (4)] The evaluation assumes the chosen code samples and defect types fairly represent real-world security review tasks. No details are supplied on dataset size, selection criteria, language distribution, or whether samples were curated post-hoc; combined with finding (4) that LLMs perform better on shorter files with annotations, this raises the possibility that the dataset favors LLM strengths while under-representing the conditions where static tools are typically applied.
Authors: We acknowledge that the manuscript lacks a dedicated description of the dataset construction. We will add this information in the revised experimental setup section, including total sample count, selection criteria (e.g., sourcing from public vulnerability repositories and code review benchmarks), language distribution, and any curation steps. While the dataset was assembled to cover common security defect types encountered in code review, we agree that the correlation in finding (4) warrants explicit discussion of potential limitations in representativeness; we will add a limitations paragraph addressing this point. revision: yes
Circularity Check
No circularity: purely empirical evaluation against external baselines
full rationale
The paper reports an empirical study that directly measures LLM detection rates on fixed code samples against SOTA static analysis tools, with performance numbers obtained from experiment rather than any derivation, equation, or fitted parameter. No self-definitional constructs, predictions that reduce to inputs by construction, or load-bearing self-citations appear in the reported claims or findings. The central result (LLM outperformance) is therefore independent of the paper's own inputs and stands as a standard empirical comparison.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Measuring and Exploiting Contextual Bias in LLM-Assisted Security Code Review
LLM-based security code review is vulnerable to framing bias, with a novel iterative refinement attack achieving 100% success in reintroducing vulnerabilities across real projects.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2308.14434
Using chatgpt as a static application security testing tool. arXiv preprint arXiv:2308.14434 . Blackwell, R.E., Barry, J., Cohn, A.G., 2024. Towards reproducible llm evaluation: Quantifying uncertainty in llm benchmark scores. arXiv preprint arXiv:2410.03492 . Borji, A., 2023. A categorical archive of chatgpt failures. arXiv preprint arXiv:2302.03494 . Bo...
-
[2]
Whodoeswhatduringacodereview?datasetsofosspeerreview repositories,in:Proceedingsofthe10thWorkingConferenceonMining Software Repositories (MSR), IEEE. pp. 49–52. Han,X.,Tahir,A.,Liang,P.,Counsell,S.,Blincoe,K.,Li,B.,Luo,Y.,2022. Codesmellsdetectionviamoderncodereview:Astudyoftheopenstack and qt communities. Empirical Software Engineering 27, 127. Harrell, ...
-
[3]
Everything you wanted to know about llm-based vulnerability detection but were afraid to ask. arXiv preprint arXiv:2504.13474 . Liu, F., Liu, Y., Shi, L., Huang, H., Wang, R., Yang, Z., Zhang, L., Li, Z., Ma, Y., 2024. Exploring and evaluating hallucinations in llm-powered code generation. arXiv preprint arXiv:2404.00971 . Liu, P., Yuan, W., Fu, J., Jiang...
-
[4]
A Comprehensive Survey of Hallucination Mitigation Techniques in Large Language Models
A comprehensive survey of hallucination mitigation techniques in large language models. arXiv preprint arXiv:2401.01313 6. Tsai, C.N., Xie, J., Lai, C.M., Lin, C.S., 2025. Leveraging intra-and inter- references in vulnerability detection using multi-agent collaboration based on llms. Cluster Computing 28, 1–12. Turzo, A.K., 2022. Towards improving code re...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.5281/zenodo.15572150 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.