Floralens: a Deep Learning Model for the Portuguese Native Flora
Pith reviewed 2026-05-24 03:32 UTC · model grok-4.3
The pith
Curated public data and standard deep learning tools produce a model for native flora identification that matches leading platforms.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By anchoring a dataset in high-quality data from botanical sources and adding further sampled research-grade observations, then training via standard deep convolutional neural networks on off-the-shelf cloud services, the authors produce a model that performs accurate image-based identification of native plant species at levels comparable to state-of-the-art platforms. The model is integrated into a public website for ongoing use, and the full training dataset is released openly for others to build upon.
What carries the argument
The Floralens model, a deep convolutional neural network trained on a carefully assembled image dataset of native flora species.
If this is right
- The model enables public access to automated identification for citizen science projects focused on plants.
- The openly shared dataset allows direct comparison or extension by other researchers working on similar identification tasks.
- The same combination of curated public data and standard training services can be repeated for other geographic regions or groups of species.
- Integration into websites makes the identification capability available to non-specialists without requiring them to build models from scratch.
Where Pith is reading between the lines
- Such models could support field conservation work by letting volunteers quickly flag unusual or protected species during surveys.
- Pairing the image model with location or seasonal data might further reduce errors in real-world use.
- The method could be tested on images taken under varying lighting or growth stages to measure how robust the accuracy remains outside the original dataset conditions.
Load-bearing premise
Public research-grade data sources supply accurately labeled images that represent the full range of the native flora without substantial label errors or collection biases.
What would settle it
A test showing that the model achieves markedly lower accuracy on an independent collection of images from the same region would indicate the central claim does not hold.
Figures


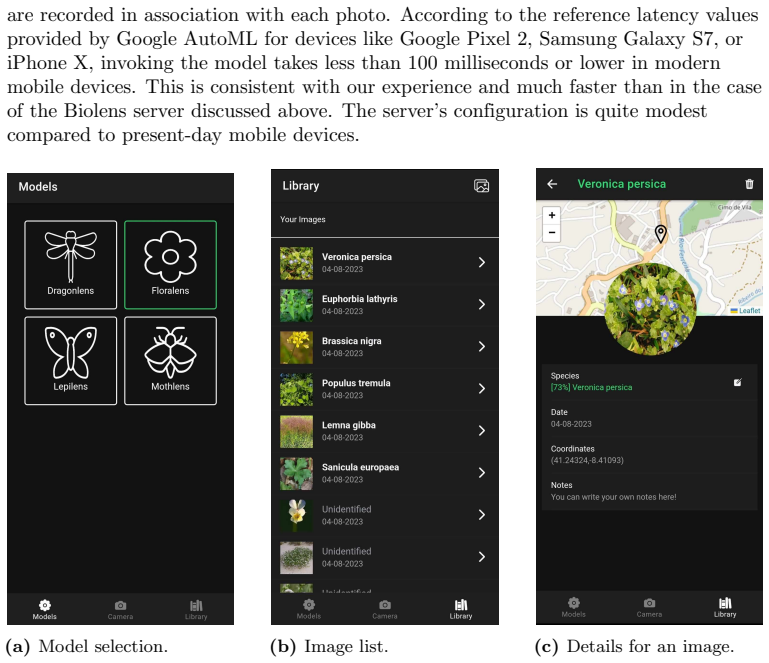
read the original abstract
Machine-learning techniques, especially deep convolutional neural networks, are pivotal for image-based identification of biological species in many Citizen Science platforms. In this paper, we describe the construction of a dataset for the Portuguese native flora based on publicly available research-grade datasets, and the derivation of a high-accuracy model from it using off-the-shelf deep convolutional neural networks. We anchored the dataset in high-quality data provided by Sociedade Portuguesa de Bot\^anica and added further sampled data from research-grade datasets available from GBIF. We find that with a careful dataset design, off-the-shelf machine-learning cloud services such as Google's AutoML Vision produce accurate models, with results comparable to those of Pl@ntNet, a state-of-the-art citizen science platform. The best model we derived, dubbed Floralens, has been integrated into the public website of Project Biolens, where we gather models for other taxa as well. The dataset used to train the model is also publicly available on Zenodo.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript describes the assembly of a dataset for Portuguese native flora by combining high-quality records from the Sociedade Portuguesa de Botânica with research-grade observations from GBIF. It then trains a deep convolutional model using Google's AutoML Vision service, claims that the resulting Floralens model attains accuracy comparable to the Pl@ntNet platform, and reports that the model has been deployed on the Biolens project website with the training data released on Zenodo.
Significance. If the performance claims are substantiated, the work would supply a geographically focused identification tool that lowers the barrier for citizen-science applications in Portugal. The reliance on public datasets and an off-the-shelf cloud service is a practical strength that could be replicated for other regional floras.
major comments (3)
- [Abstract] Abstract: the central claim that Floralens produces 'results comparable to those of Pl@ntNet' is unsupported by any reported accuracy figures, dataset cardinality, train/validation/test split sizes, or error analysis. Without these quantities the comparability assertion cannot be assessed.
- [Dataset construction] Dataset construction (implied in Abstract and methods description): the premise that the SPB+GBIF research-grade subset supplies accurately labeled, representative samples of Portuguese native flora is unverified; no expert re-labeling audit, coverage statistics relative to a complete Portuguese flora checklist, or estimate of residual misidentification rates is supplied.
- [Model derivation] Model derivation: the statement that 'off-the-shelf machine-learning cloud services such as Google's AutoML Vision produce accurate models' is presented without any quantitative validation metrics or ablation against alternative architectures or training regimes, rendering the 'careful dataset design' claim unevaluable.
minor comments (2)
- The manuscript would benefit from a dedicated Results section containing standard computer-vision metrics (top-1/top-5 accuracy, per-class F1, confusion matrix) and a direct numerical comparison table with Pl@ntNet if such data exist.
- Clarify the precise number of taxa and images retained after any filtering steps; these cardinalities are prerequisites for interpreting any future accuracy numbers.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that Floralens produces 'results comparable to those of Pl@ntNet' is unsupported by any reported accuracy figures, dataset cardinality, train/validation/test split sizes, or error analysis. Without these quantities the comparability assertion cannot be assessed.
Authors: We agree that the abstract should contain the supporting quantitative details. In the revised manuscript we will expand the abstract to report the model's top-1 accuracy, total dataset cardinality, train/validation/test split sizes, and a concise error analysis that underpins the comparability statement with Pl@ntNet. revision: yes
-
Referee: [Dataset construction] Dataset construction (implied in Abstract and methods description): the premise that the SPB+GBIF research-grade subset supplies accurately labeled, representative samples of Portuguese native flora is unverified; no expert re-labeling audit, coverage statistics relative to a complete Portuguese flora checklist, or estimate of residual misidentification rates is supplied.
Authors: The dataset is built exclusively from research-grade GBIF records and verified SPB observations. We will add coverage statistics against the Portuguese flora checklist. An expert re-labeling audit and residual misidentification estimate were not performed; these would require resources outside the present study scope. revision: partial
-
Referee: [Model derivation] Model derivation: the statement that 'off-the-shelf machine-learning cloud services such as Google's AutoML Vision produce accurate models' is presented without any quantitative validation metrics or ablation against alternative architectures or training regimes, rendering the 'careful dataset design' claim unevaluable.
Authors: The manuscript already contains the AutoML Vision validation metrics; we will present them more explicitly in the methods and results sections. Ablation experiments against other architectures lie outside the scope of demonstrating feasibility with an off-the-shelf service and are noted as future work. revision: partial
- Expert re-labeling audit of the dataset
- Quantitative estimate of residual misidentification rates
Circularity Check
No circularity; standard ML pipeline on external public datasets with no self-referential definitions or load-bearing self-citations.
full rationale
The paper constructs a dataset from external public sources (Sociedade Portuguesa de Botânica and GBIF research-grade records) and trains off-the-shelf models via Google's AutoML Vision. The central claim of comparability to Pl@ntNet is an empirical performance report on held-out data, not a derivation that reduces to fitted inputs or prior self-citations by construction. No equations, ansatzes, or uniqueness theorems are invoked; the derivation chain consists of standard data collection followed by supervised training and evaluation. This is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- AutoML Vision training configuration
axioms (1)
- domain assumption Research-grade observations from GBIF and Sociedade Portuguesa de Botânica are accurately labeled and representative of Portuguese native flora.
Reference graph
Works this paper leans on
-
[1]
Citizen Science: A Developing Tool for Expanding Science Knowledge and Scientific Literacy
Bonney R, Cooper CB, Dickinson J, Kelling S, Phillips T, Rosenberg KV, et al. Citizen Science: A Developing Tool for Expanding Science Knowledge and Scientific Literacy. BioScience. 2009;59(11):977–984
work page 2009
-
[2]
Connecting to nature through tech? The case of the iNaturalist app
Altrudi S. Connecting to nature through tech? The case of the iNaturalist app. Convergence. 2021;27(1):124–141
work page 2021
-
[3]
Schermer M, Hogeweg L. Supporting citizen scientists with automatic species identification using deep learning image recognition models. Biodiversity Information Science and Standards. 2018
work page 2018
-
[4]
Machine learning for image based species identification
W¨ aldchen J, M¨ ader P. Machine learning for image based species identification. Methods in Ecology and Evolution. 2018;9(11):2216–2225
work page 2018
-
[5]
The Flora Incognita app–interactive plant species identification
M¨ ader P, Boho D, Rzanny M, Seeland M, Wittich HC, Deggelmann A, et al. The Flora Incognita app–interactive plant species identification. Methods in Ecology and Evolution. 2021;12(7):1335–1342
work page 2021
-
[6]
Pl@ntNet app in the era of deep learning
Affouard A, Go¨ eau H, Bonnet P, Lombardo JC, Joly A. Pl@ntNet app in the era of deep learning. In: International Conference on Learning Representations. Toulon, France; 2017
work page 2017
-
[7]
Perspectives in machine learning for wildlife conservation
Tuia D, Kellenberger B, Beery S, Costelloe BR, Zuffi S, Risse B, et al. Perspectives in machine learning for wildlife conservation. Nature Communications. 2022;13(1):792
work page 2022
-
[8]
Applications for deep learning in ecology
Christin S, Hervet E, Lecomte N. Applications for deep learning in ecology. Methods in Ecology and Evolution. 2019;10(10):1632–1644
work page 2019
-
[9]
https://rubisco.dcc.fc.up.pt/biolens
Biolens; 2020. https://rubisco.dcc.fc.up.pt/biolens
work page 2020
-
[10]
Flora-On: Flora de Portugal Interactiva; 2014. https://www.flora-on.pt
work page 2014
-
[11]
Robertson T, D¨ oring M, Guralnick R, Bloom D, Wieczorek J, Braak K, et al. The GBIF integrated publishing toolkit: facilitating the efficient publishing of biodiversity data on the Internet. PLOS One. 2014;9(8)
work page 2014
-
[12]
Identifica¸ c˜ ao Taxon´ omica em Biologia Usando Inteligˆ encia Artificial; 2022
Lopes LMB, Marques ERB, Mamede T, Filgueiras A, Marques M, Coutinho M. Identifica¸ c˜ ao Taxon´ omica em Biologia Usando Inteligˆ encia Artificial; 2022. Available from: https://rce.casadasciencias.org/rceapp/art/2022/050/
work page 2022
-
[13]
A Portuguese Flora Identification Tool Using Deep Learning
Marques M. A Portuguese Flora Identification Tool Using Deep Learning. Masters thesis, Faculty of Sciences, University of Porto; 2021. https://hdl.handle.net/10216/130189
work page 2021
-
[14]
Floralens: a deep learning model for portuguese flora
Filgueiras A. Floralens: a deep learning model for portuguese flora. Masters thesis, Faculty of Sciences, University of Porto; 2022. https://hdl.handle.net/10216/145701. April 10, 2025 26/29
work page 2022
-
[15]
On using Deep Learning for Automatic Taxonomic Identification of Butterflies
Mamede T. On using Deep Learning for Automatic Taxonomic Identification of Butterflies. BSC project report, Faculty of Sciences, University of Porto; 2020. https: //www.dcc.fc.up.pt/~edrdo/supervision/tmamede_lepidoptera.pdf
work page 2020
-
[16]
The Floralens Dataset for Portuguese Flora; 2024
Filgueiras A, Marques ERB, Lopes LMB, Marques M. The Floralens Dataset for Portuguese Flora; 2024. https://doi.org/10.5281/zenodo.10639701
-
[17]
Deep-plant: Plant identification with convolutional neural networks
Lee SH, Chan CS, Wilkin P, Remagnino P. Deep-plant: Plant identification with convolutional neural networks. In: IEEE International Conference on Image Processing; 2015. p. 452–456
work page 2015
-
[18]
Large-scale plant classification with deep neural networks
Heredia I. Large-scale plant classification with deep neural networks. In: Computing Frontiers Conference; 2017. p. 259–262
work page 2017
-
[19]
Deep learning for plant identification in natural environment
Sun Y, Liu Y, Wang G, Zhang H. Deep learning for plant identification in natural environment. Computational Intelligence and Neuroscience. 2017
work page 2017
-
[20]
Plant identification: Experts vs
Bonnet P, Go¨ eau H, Hang ST, Lasseck M,ˇSulc M, Mal´ ecot V, et al. Plant identification: Experts vs. machines in the era of deep learning: deep learning techniques challenge flora experts. Multimedia Tools and Applications for Environmental & Biodiversity Informatics. 2018; p. 131–149
work page 2018
-
[21]
https://observation.org/pages/nia-explain/
Observation.org - Explanation NIA; 2022. https://observation.org/pages/nia-explain/
work page 2022
-
[22]
Visual Feature Extraction by a Multilayered Network of Analog Threshold Elements
Fukushima K. Visual Feature Extraction by a Multilayered Network of Analog Threshold Elements. IEEE Transactions on Systems Science and Cybernetics. 1969;5(4):322–333
work page 1969
-
[23]
Fukushima K. Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biological Cybernetics. 1980;36(4):193–202
work page 1980
-
[24]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Kolesnikov A, Dosovitskiy A, Weissenborn D, Heigold G, Uszkoreit J, Beyer L, et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In: International Conference on Learning Representations. Virtual Conference; 2021
work page 2021
-
[25]
Are Transformers more robust than CNNs? In: Advances in Neural Information Processing Systems; 2021
Bai Y, Mei J, Yuille AL, Xie C. Are Transformers more robust than CNNs? In: Advances in Neural Information Processing Systems; 2021. p. 26831–26843
work page 2021
-
[26]
Pl@ntNet news – Covering all countries floras and new identification AI; 2023
Pl@ntNet. Pl@ntNet news – Covering all countries floras and new identification AI; 2023. https://plantnet.org/en/2023/07/05/ covering-all-countries-floras-new-identification-ai/
work page 2023
-
[27]
https://www.inaturalist.org/pages/computer_vision_demo
iNaturalist - Computer Vision Explorations; 2024. https://www.inaturalist.org/pages/computer_vision_demo
work page 2024
-
[28]
Joly A, Bonnet P, Affouard A, Lombardo JC, Go¨ eau H. Pl@ntnet-my business. In: International Conference on Multimedia. ACM; 2017. p. 551–555
work page 2017
-
[29]
https://observation.org/apps/obsidentify/
Observation.org - ObsIdentify; 2022. https://observation.org/apps/obsidentify/
work page 2022
-
[30]
https://multi-source.docs.biodiversityanalysis.eu/index.html
Naturalis Biodiversity Center - Nature Identification API v2; 2022. https://multi-source.docs.biodiversityanalysis.eu/index.html. April 10, 2025 27/29
work page 2022
-
[31]
https://aws.amazon.com/rekognition/
Amazon Rekognition; 2024. https://aws.amazon.com/rekognition/
work page 2024
-
[32]
https://developer.apple.com/documentation/createml
Apple Create ML; 2024. https://developer.apple.com/documentation/createml
work page 2024
-
[33]
https: //azure.microsoft.com/en-us/solutions/automated-machine-learning/
Automated Machine Learning (AutoML) - Microsoft Azure; 2024. https: //azure.microsoft.com/en-us/solutions/automated-machine-learning/
work page 2024
-
[34]
Choudhary M, Sentil S, Jones JB, Paret ML. Non-coding deep learning models for tomato biotic and abiotic stress classification using microscopic images. Frontiers in Plant Science. 2023;14:1292643
work page 2023
-
[35]
Code-free deep learning for multi-modality medical image classification
Korot E, Guan Z, Ferraz D, Wagner SK, Zhang G, Liu X, et al. Code-free deep learning for multi-modality medical image classification. Nature Machine Intelligence. 2021;3(4):288–298
work page 2021
-
[36]
Borkowski AA, Wilson CP, Borkowski SA, Thomas LB, Deland LA, Grewe SJ, et al. Google Auto ML versus Apple Create ML for histopathologic cancer diagnosis; which algorithms are better? arXiv preprint arXiv:190308057. 2019
work page 2019
-
[37]
Malounas I, Lentzou D, Xanthopoulos G, Fountas S. Testing the suitability of automated machine learning, hyperspectral imaging and CIELAB color space for proximal in situ fertilization level classification. Smart Agricultural Technology. 2024;8:100437
work page 2024
-
[38]
Liang D, Xue F. Integrating automated machine learning and interpretability analysis in architecture, engineering and construction industry: A case of identifying failure modes of reinforced concrete shear walls. Computers in Industry. 2023;147:103883
work page 2023
-
[39]
AI-GeoSpecies: integrate artificial intelligence into your citizen science app; 2023
Justamante A, Joly A, Lombardo JC, Robert F, Chouet M, Li˜ n´ an S, et al.. AI-GeoSpecies: integrate artificial intelligence into your citizen science app; 2023. https://doi.org/10.5281/zenodo.7657594
-
[40]
http://sftp.kew.org/pub/data-repositories/WCVP/
WCVP: World Checklist of Vascular Plants; 2023. http://sftp.kew.org/pub/data-repositories/WCVP/
work page 2023
-
[41]
Flowers, leaves or both? How to obtain suitable images for automated plant identification
Rzanny M, M¨ ader P, Deggelmann A, Chen M, W¨ aldchen J. Flowers, leaves or both? How to obtain suitable images for automated plant identification. Plant Methods. 2019;15(1):1–11
work page 2019
-
[42]
Florid – a Nationwide Identification Service for Plants from Photos and Habitat Information; 2024
Brun P, de Witte L, Popp MR, Zurell D, Karger DN, Descombes P, et al.. Florid – a Nationwide Identification Service for Plants from Photos and Habitat Information; 2024. Available from: https://ssrn.com/abstract=4830448
work page 2024
-
[43]
Mind your app: Could plant ID applications lead to an increase in extinction risk? Phytotaxa
Berjano, R and Lopez-Tirado, J and Martin-Escobar, I and Martinez-Sagarra, G and Nieto-Lugilde, D and Sanchez-Romero, J and De La Estrella, M . Mind your app: Could plant ID applications lead to an increase in extinction risk? Phytotaxa. 2023;609(1):65–68
work page 2023
-
[44]
The iNaturalist species classification and detection dataset
Van Horn G, Mac Aodha O, Song Y, Cui Y, Sun C, Shepard A, et al. The iNaturalist species classification and detection dataset. In: IEEE Conference on Computer Vision and Pattern Recognition; 2018. p. 8769–8778
work page 2018
-
[45]
Go¨ eau H, Bonnet P, Joly A. Plant identification based on noisy web data: the amazing performance of deep learning (LifeCLEF 2017). In: Conference and Labs of the Evaluation Forum; 2017. April 10, 2025 28/29
work page 2017
-
[46]
Overview of PlantCLEF 2022: Image-based plant identification at global scale
Go¨ eau H, Bonnet P, Joly A. Overview of PlantCLEF 2022: Image-based plant identification at global scale. In: Conference and Labs of the Evaluation Forum. vol. 3180; 2022. p. 1916–1928
work page 2022
-
[47]
iNaturalist Research-grade Observations
iNaturalist contributors, iNaturalist (2022). iNaturalist Research-grade Observations. iNaturalist.org.; 2023. https://doi.org/10.15468/ab3s5x
-
[48]
Observation.org - Nature data from around the World
de Vries H, Lemmens M. Observation.org - Nature data from around the World
-
[49]
https://doi.org/10.15468/5nilie
-
[50]
Affouard A, Joly A, Lombardo JC, Champ J, Goeau H, Bonnet P. Pl@ntNet observations. Version 1.2. Pl@ntNet; 2023. https://doi.org/10.15468/gtebaa
-
[51]
Robertson T, D¨ oring M, Guralnick R, Bloom D, Wieczorek J, Braak K, et al. The GBIF integrated publishing toolkit: facilitating the efficient publishing of biodiversity data on the internet. PLOS One. 2014;9(8)
work page 2014
-
[52]
https://observation.org/pages/validation/
Observation.org - Validation; 2023. https://observation.org/pages/validation/
work page 2023
-
[53]
What is the data quality assessment and how do observations qualify to become “Research Grade”?; 2023. https://www.inaturalist.org/pages/help#quality
work page 2023
-
[54]
In: Google AutoML: Cloud Vision
Bisong E. In: Google AutoML: Cloud Vision. Apress; 2019. p. 581–598
work page 2019
-
[55]
https://cloud.google.com/vision/automl/docs/
AutoML Vision Documentation; 2023. https://cloud.google.com/vision/automl/docs/
work page 2023
-
[56]
https://www.tensorflow.org/lite/
TensorFlow Lite, ML for Mobile and Edge Devices; 2023. https://www.tensorflow.org/lite/
work page 2023
-
[57]
https://www.tensorflow.org/js/
TensorFlow.js, Machine Learning for Javascript developers; 2023. https://www.tensorflow.org/js/
work page 2023
- [58]
-
[59]
MnasNet: Platform-Aware Neural Architecture Search for Mobile
Tan M, Chen B, Pang R, Vasudevan V, Sandler M, Howard A, et al. MnasNet: Platform-Aware Neural Architecture Search for Mobile. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2019. p. 2815–2823
work page 2019
-
[60]
https://www.imageclef.org/PlantCLEF2022
PlantCLEF2022, Image-based plant identification at global scale; 2023. https://www.imageclef.org/PlantCLEF2022
work page 2023
-
[61]
https://lab.plantnet.org/LifeCLEF/PlantCLEF2022/train
PlantCLEF’22 trusted training set; 2022. https://lab.plantnet.org/LifeCLEF/PlantCLEF2022/train
work page 2022
-
[62]
https://www.mediawiki.org/wiki/Wikimedia_REST_API
Wikimedia REST API; 2023. https://www.mediawiki.org/wiki/Wikimedia_REST_API
work page 2023
-
[63]
Assessing the accuracy of free automated plant identification applications
Hart, Adam G and Bosley, Hayley and Hooper, Chloe and Perry, Jessica and Sellors-Moore, Joel and Moore, Oliver and Goodenough, Anne E . Assessing the accuracy of free automated plant identification applications. People and Nature. 2023;5(3):929–937
work page 2023
-
[64]
Pl@ntNet API for developers; 2023
Pl@ntNet. Pl@ntNet API for developers; 2023. https://my.plantnet.org
work page 2023
-
[65]
https://powo.science.kew.org/taxon/urn:lsid:ipni.org: names:192416-1
Royal Botanical Gardens, Kew: Plants of the World Online: Chamaeleon gummifer; 2023. https://powo.science.kew.org/taxon/urn:lsid:ipni.org: names:192416-1. April 10, 2025 29/29
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.