TwinLiteNet+: An Enhanced Multi-Task Segmentation Model for Autonomous Driving
Pith reviewed 2026-05-24 03:21 UTC · model grok-4.3
The pith
TwinLiteNet+ achieves higher drivable area and lane segmentation accuracy than prior models while using 11 times fewer operations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
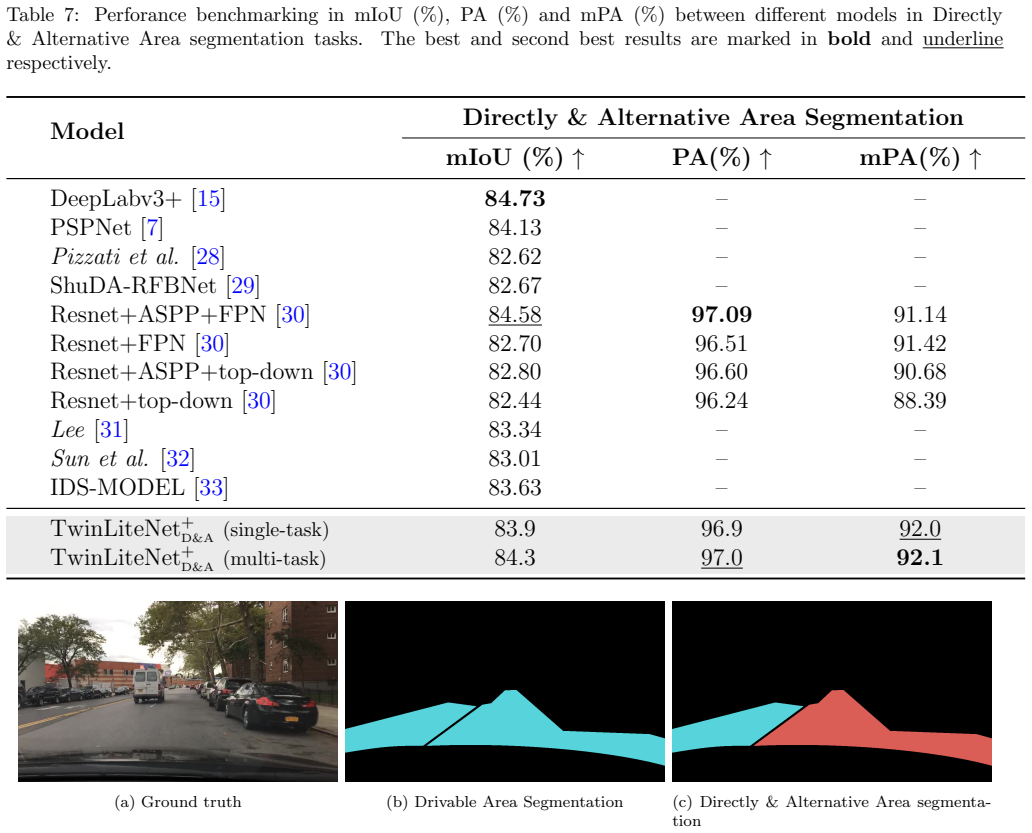
TwinLiteNet+ employs a hybrid encoder architecture that integrates stride-based dilated convolutions and depthwise separable dilated convolutions, balancing representational capacity and computational cost. To improve task-specific decoding, it introduces two lightweight upsampling modules—Upper Convolution Block (UCB) and Upper Simple Block (USB)—alongside a Partial Class Activation Attention (PCAA) mechanism. The model family ranges from 34K parameters in the Nano variant to 1.94M parameters in the Large variant. On the BDD100K dataset, TwinLiteNet+_Large reaches 92.9 percent mIoU for drivable area segmentation and 34.2 percent IoU for lane segmentation while requiring 11 times fewer FLOPs
What carries the argument
Hybrid encoder that combines stride-based dilated convolutions with depthwise separable dilated convolutions to maintain feature quality at low computational cost for simultaneous drivable-area and lane segmentation.
If this is right
- The four size variants allow direct trade-offs between accuracy and parameter count for different hardware budgets.
- Quantization to INT8 and FP16 preserves performance, enabling deployment on typical embedded accelerators.
- Measured inference speed and energy consumption on embedded devices exceed those of heavier models.
- Simultaneous drivable-area and lane outputs support downstream path planning without separate networks.
Where Pith is reading between the lines
- If the same modules transfer to other segmentation backbones, the approach could reduce compute for additional driving perception tasks such as object detection.
- The partial class activation attention may improve boundary accuracy on narrow structures like lane markings when applied to different datasets.
- Ultra-small variants could enable on-device segmentation for low-power microcontrollers in consumer robotics.
- Combining the encoder with temporal fusion across video frames might further raise lane-segmentation IoU without added parameters.
Load-bearing premise
The accuracy and efficiency gains are produced by the hybrid encoder, UCB, USB, and PCAA modules rather than by differences in training schedule, data augmentation, or hyperparameter choices relative to the baselines.
What would settle it
Retrain the compared state-of-the-art models on the identical BDD100K splits, augmentation pipeline, optimizer schedule, and hyperparameters used for TwinLiteNet+ and check whether the reported accuracy and FLOP gaps remain.
Figures









read the original abstract
Semantic segmentation is a fundamental perception task in autonomous driving, particularly for identifying drivable areas and lane markings to enable safe navigation. However, most state-of-the-art (SOTA) models are computationally intensive and unsuitable for real-time deployment on resource-constrained embedded devices. In this paper, we introduce TwinLiteNet+, an enhanced multi-task segmentation model designed for real-time drivable area and lane segmentation with high efficiency. TwinLiteNet+ employs a hybrid encoder architecture that integrates stride-based dilated convolutions and depthwise separable dilated convolutions, balancing representational capacity and computational cost. To improve task-specific decoding, we propose two lightweight upsampling modules-Upper Convolution Block (UCB) and Upper Simple Block (USB)-alongside a Partial Class Activation Attention (PCAA) mechanism that enhances segmentation precision. The model is available in four configurations, ranging from the ultra-compact TwinLiteNet+_{Nano} (34K parameters) to the high-performance TwinLiteNet+_{Large} (1.94M parameters). On the BDD100K dataset, TwinLiteNet+_{Large} achieves 92.9% mIoU for drivable area segmentation and 34.2% IoU for lane segmentation-surpassing existing state-of-the-art models while requiring 11x fewer floating-point operations (FLOPs) for computation. Extensive evaluations on embedded devices demonstrate superior inference speed, quantization robustness (INT8/FP16), and energy efficiency, validating TwinLiteNet+ as a compelling solution for real-world autonomous driving systems. Code is available at https://github.com/chequanghuy/TwinLiteNetPlus.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TwinLiteNet+, a multi-task segmentation architecture for simultaneous drivable-area and lane-marking segmentation aimed at real-time autonomous driving. It proposes a hybrid encoder that mixes stride-based dilated convolutions with depthwise-separable dilated convolutions, two lightweight up-sampling blocks (UCB and USB), and a Partial Class Activation Attention (PCAA) module. Four model scales are defined (Nano at 34 K parameters to Large at 1.94 M parameters). On BDD100K the Large variant is reported to reach 92.9 % mIoU on drivable area and 34.2 % IoU on lanes while using 11× fewer FLOPs than prior SOTA models; additional embedded-device measurements for latency, INT8/FP16 quantization, and energy are provided. Public code is released.
Significance. If the performance numbers are shown to result from the architectural contributions rather than training-protocol differences, the work would supply a practical, low-FLOP family of models suitable for embedded real-time perception in autonomous driving. The public code release is a clear positive for reproducibility.
major comments (2)
- [Experiments section] Experiments section / results tables: the central claim that the hybrid encoder, UCB, USB and PCAA produce the reported 92.9 % mIoU / 34.2 % IoU and 11× FLOPs reduction is load-bearing, yet the manuscript supplies no statement that the cited SOTA baselines were re-trained under an identical data-augmentation schedule, loss weighting, optimizer, or number of epochs. Without this control the attribution of gains to the proposed modules cannot be verified.
- [Experiments section] Experiments section: no ablation tables isolate the incremental contribution of the hybrid encoder versus the UCB/USB blocks versus PCAA. Because the headline numbers rest on the joint effect of these modules, the absence of controlled ablations leaves the source of the improvement unclear.
minor comments (1)
- The abstract states four model configurations but does not list the exact parameter counts or FLOPs for each; adding a compact table row in the abstract or §3 would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The two major comments correctly identify gaps in experimental controls and analysis. We address each point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Experiments section] Experiments section / results tables: the central claim that the hybrid encoder, UCB, USB and PCAA produce the reported 92.9 % mIoU / 34.2 % IoU and 11× FLOPs reduction is load-bearing, yet the manuscript supplies no statement that the cited SOTA baselines were re-trained under an identical data-augmentation schedule, loss weighting, optimizer, or number of epochs. Without this control the attribution of gains to the proposed modules cannot be verified.
Authors: We agree that the manuscript does not state whether baselines were re-trained under identical conditions; the numbers are taken from the original publications. This is a limitation for direct attribution. In revision we will add an explicit statement in the Experiments section noting that comparisons use reported figures and discussing possible protocol differences. We will also re-train one key baseline under our exact schedule to provide a controlled reference point. revision: yes
-
Referee: [Experiments section] Experiments section: no ablation tables isolate the incremental contribution of the hybrid encoder versus the UCB/USB blocks versus PCAA. Because the headline numbers rest on the joint effect of these modules, the absence of controlled ablations leaves the source of the improvement unclear.
Authors: We acknowledge the lack of component-wise ablations. The revised manuscript will include new ablation tables that evaluate the hybrid encoder, UCB, USB, and PCAA in isolation and in combination, using the same training protocol. These results will be placed in the Experiments section to clarify the contribution of each module. revision: yes
Circularity Check
No circularity: results are direct empirical measurements on public BDD100K dataset
full rationale
The paper proposes an architecture (hybrid encoder, UCB, USB, PCAA) and reports mIoU/IoU/FLOPs numbers obtained by training and evaluating on the public BDD100K benchmark. No equations, fitted parameters, or self-citations are used to derive the headline metrics; they are measured outputs. No self-definitional loops, fitted-input predictions, or load-bearing self-citations appear in the provided text. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- model size configurations
axioms (1)
- domain assumption BDD100K provides reliable ground-truth annotations for drivable area and lane classes.
Reference graph
Works this paper leans on
-
[1]
F. Yu, H. Chen, X. Wang, W. Xian, Y. Chen, F. Liu, V. Madhavan, T. Darrell, Bdd100k: A diverse driving dataset for heterogeneous multitask learning, in: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 2633–2642. doi:10.1109/CVPR42600.2020. 00271
-
[2]
A. A. Mehta, A. A. Padaria, D. J. Bavisi, V. Ukani, P. Thakkar, R. Geddam, K. Kotecha, A. Abra- ham, Securing the future: A comprehensive review of security challenges and solutions in advanced driver assistance systems, IEEE Access 12 (2024) 643–678. doi:10.1109/ACCESS.2023.3347200
-
[3]
H. B. Gade, A. R. Uppala, P. N. Karri, R. Devi Sinduvala Mallesh, V. K. Odugu, J. R. B, Hardware architecture of efficient image dehazing technique for advanced driving assistance system, Computers and Electrical Engineering 126 (2025) 110493. doi:https://doi.org/10.1016/j.compeleceng. 2025.110493
-
[4]
J. Guti´ errez-Zaballa, K. Basterretxea, J. Echanobe, M. V. Mart´ ınez, I. del Campo, Exploring fully convolutional networks for ¬†the¬†segmentation of ¬†hyperspectral imaging applied to ¬†advanced driver assistance systems, in: K. Desnos, S. Pertuz (Eds.), Design and Architecture for Signal and Image Processing, Springer International Publishing, Cham, 2...
work page 2022
-
[5]
ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation
A. Paszke, A. Chaurasia, S. Kim, E. Culurciello, Enet: A deep neural network architecture for real-time semantic segmentation, ArXiv abs/1606.02147 (2016). 27
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[6]
Y. Hou, Z. Ma, C. Liu, C. C. Loy, Learning lightweight lane detection cnns by self attention distil- lation, 2019 IEEE/CVF International Conference on Computer Vision (ICCV) (2019) 1013–1021
work page 2019
-
[7]
H. Zhao, J. Shi, X. Qi, X. Wang, J. Jia, Pyramid scene parsing network, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017
work page 2017
-
[8]
M. Teichmann, M. Weber, M. Z¨ ollner, R. Cipolla, R. Urtasun, Multinet: Real-time joint semantic reasoning for autonomous driving, in: 2018 IEEE Intelligent Vehicles Symposium (IV), 2018, pp. 1013–1020. doi:10.1109/IVS.2018.8500504
-
[9]
A. Parashar, M. Rhu, A. Mukkara, A. Puglielli, R. Venkatesan, B. Khailany, J. S. Emer, S. W. Keckler, W. J. Dally, Scnn: An accelerator for compressed-sparse convolutional neural networks, 2017 ACM/IEEE 44th Annual International Symposium on Computer Architecture (ISCA) (2017) 27–40
work page 2017
-
[10]
W. Tian, X. Yu, H. Hu, Interactive attention learning on detection of lane and lane marking on the road by monocular camera image, Sensors 23 (14) (2023)
work page 2023
-
[11]
Z. Hu, Y. Shen, Lane detection based on boundary feature enhancement and information interaction, Academic Journal of Computing & Information Science 8 (1) (2025) 57–63. doi:10.25236/AJCIS. 2025.080108. URL https://doi.org/10.25236/AJCIS.2025.080108
-
[12]
Q.-H. Che, D.-P. Nguyen, M.-Q. Pham, D.-K. Lam, Twinlitenet: An efficient and lightweight model for driveable area and lane segmentation in self-driving cars, in: 2023 International Conference on Multimedia Analysis and Pattern Recognition (MAPR), 2023, pp. 1–6. doi:10.1109/MAPR59823. 2023.10288646
-
[13]
J. Sun, Y. Li, Multi-feature fusion network for road scene semantic segmentation, Computers & Electrical Engineering 92 (2021) 107155. doi:https://doi.org/10.1016/j.compeleceng.2021. 107155
-
[14]
M. Zhang, S. Li, D. Wang, Z. Cui, M. Xin, Omnidirectional semantic segmentation fusion network with cross-stage and cross-dimensional remodeling, Computers and Electrical Engineering 122 (2025) 110014. doi:https://doi.org/10.1016/j.compeleceng.2024.110014
-
[15]
L.-C. Chen, Y. Zhu, G. Papandreou, F. Schroff, H. Adam, Encoder-decoder with atrous separable convolution for semantic image segmentation, in: V. Ferrari, M. Hebert, C. Sminchisescu, Y. Weiss (Eds.), Computer Vision – ECCV 2018, Springer International Publishing, Cham, 2018, pp. 833–851
work page 2018
-
[16]
E. Xie, W. Wang, Z. Yu, A. Anandkumar, J. M. Alvarez, P. Luo, Segformer: Simple and efficient design for semantic segmentation with transformers, in: Neural Information Processing Systems (NeurIPS), 2021
work page 2021
-
[17]
S. Mehta, M. Rastegari, A. Caspi, L. Shapiro, H. Hajishirzi, Espnet: Efficient spatial pyramid of dilated convolutions for semantic segmentation, in: V. Ferrari, M. Hebert, C. Sminchisescu, Y. Weiss (Eds.), Computer Vision – ECCV 2018, Springer International Publishing, Cham, 2018, pp. 561–580
work page 2018
-
[18]
S. Mehta, M. Rastegari, L. Shapiro, H. Hajishirzi, Espnetv2: A light-weight, power efficient, and general purpose convolutional neural network, in: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 9182–9192. doi:10.1109/CVPR.2019.00941. 28
-
[19]
M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, U. Franke, S. Roth, B. Schiele, The cityscapes dataset for semantic urban scene understanding, in: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 3213–3223. doi:10.1109/CVPR. 2016.350
- [20]
-
[21]
J. Zhan, Y. Luo, C. Guo, Y. Wu, J. Meng, J. Liu, Yolopx: Anchor-free multi-task learning network for panoptic driving perception, Pattern Recognition 148 (2024) 110152
work page 2024
-
[22]
J. Zhan, J. Liu, Y. Wu, C. Guo, Multi-task visual perception for object detection and semantic segmentation in intelligent driving, Remote Sensing 16 (10) (2024). doi:10.3390/rs16101774. URL https://www.mdpi.com/2072-4292/16/10/1774
- [23]
-
[24]
J. Fu, J. Liu, H. Tian, Y. Li, Y. Bao, Z. Fang, H. Lu, Dual attention network for scene segmentation, in: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 3141–3149. doi:10.1109/CVPR.2019.00326
-
[25]
J. Hu, L. Shen, G. Sun, Squeeze-and-excitation networks, in: 2018 IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, 2018, pp. 7132–7141. doi:10.1109/CVPR.2018.00745
-
[26]
S.-A. Liu, H. Xie, H. Xu, Y. Zhang, Q. Tian, Partial class activation attention for semantic seg- mentation, in: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 16815–16824. doi:10.1109/CVPR52688.2022.01633
-
[27]
S. Woo, J. Park, J.-Y. Lee, I. S. Kweon, Cbam: Convolutional block attention module, in: V. Ferrari, M. Hebert, C. Sminchisescu, Y. Weiss (Eds.), Computer Vision – ECCV 2018, Springer International Publishing, Cham, 2018, pp. 3–19
work page 2018
-
[28]
F. Pizzati, F. Garcia, Enhanced free space detection in multiple lanes based on single cnn with scene identification, in: 2019 IEEE Intelligent Vehicles Symposium (IV), IEEE, 2019. doi:10.1109/ivs. 2019.8814181
work page doi:10.1109/ivs 2019
-
[29]
Z. Wang, Z. Cheng, H. Huang, J. Zhao, Shuda-rfbnet for real-time multi-task traffic scene perception, in: 2019 Chinese Automation Congress (CAC), 2019, pp. 305–310. doi:10.1109/CAC48633.2019. 8997236
- [30]
-
[31]
D.-G. Lee, Fast drivable areas estimation with multi-task learning for real-time autonomous driving assistant, Applied Sciences 11 (22) (2021). doi:10.3390/app112210713
-
[32]
L. Sun, F. Yan, T. Deng, C. Jiang, J. Li, A lightweight network with lane feature enhancement for multilane drivable area detection, in: 2022 14th International Conference on Wireless Communica- tions and Signal Processing (WCSP), 2022, pp. 66–71
work page 2022
-
[33]
T. Luo, Y. Chen, T. Luan, B. Cai, L. Chen, H. Wang, Ids-model: An efficient multi-task model of road scene instance and drivable area segmentation for autonomous driving, IEEE Transactions on Transportation Electrification (2023) 1–1 doi:10.1109/TTE.2023.3293495. 29
-
[34]
Y. Ko, Y. Lee, S. Azam, F. Munir, M. Jeon, W. Pedrycz, Key points estimation and point instance segmentation approach for lane detection, IEEE Transactions on Intelligent Transportation Systems 23 (7) (2022) 8949–8958. doi:10.1109/TITS.2021.3088488
-
[35]
Z. Qin, H. Wang, X. Li, Ultra fast structure-aware deep lane detection, in: The European Conference on Computer Vision (ECCV), 2020
work page 2020
-
[36]
Z. Qin, P. Zhang, X. Li, Ultra fast deep lane detection with hybrid anchor driven ordinal classification, IEEE Transactions on Pattern Analysis and Machine Intelligence (2022) 1–14 doi:10.1109/TPAMI. 2022.3182097
-
[37]
D. K. Lam, C. V. Du, H. L. Pham, Quantlanenet: A 640-fps and 34-gops/w fpga-based cnn accelerator for lane detection, Sensors 23 (15) (2023). doi:10.3390/s23156661. URL https://www.mdpi.com/1424-8220/23/15/6661
- [38]
-
[39]
N. Silberman, D. Hoiem, P. Kohli, R. Fergus, Indoor segmentation and support inference from rgbd images, in: A. Fitzgibbon, S. Lazebnik, P. Perona, Y. Sato, C. Schmid (Eds.), Computer Vision – ECCV 2012, Springer Berlin Heidelberg, Berlin, Heidelberg, 2012, pp. 746–760
work page 2012
-
[40]
F. Pizzati, F. Garc´ ıa, Enhanced free space detection in multiple lanes based on single cnn with scene identification, in: 2019 IEEE Intelligent Vehicles Symposium (IV), 2019, pp. 2536–2541. doi: 10.1109/IVS.2019.8814181
-
[41]
G. M. Jacob, V. Agarwal, B. Stenger, Online knowledge distillation for multi-task learning, in: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2023, pp. 2359–2368
work page 2023
-
[42]
P. Taghavi, R. Langari, G. Pandey, Swinmtl: A shared architecture for simultaneous depth estima- tion and semantic segmentation from monocular camera images, in: 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), IEEE, 2024, pp. 4957–4964
work page 2024
- [43]
-
[44]
H. Wang, M. Qiu, Y. Cai, L. Chen, Y. Li, Sparse u-pdp: A unified multi-task framework for panoptic driving perception, IEEE Transactions on Intelligent Transportation Systems 24 (10) (2023) 11308– 11320. doi:10.1109/TITS.2023.3273286
-
[45]
Quantizing deep convolutional networks for efficient inference: A whitepaper
R. Krishnamoorthi, Quantizing deep convolutional networks for efficient inference: A whitepaper, CoRR abs/1806.08342 (2018). arXiv:1806.08342. URL http://arxiv.org/abs/1806.08342
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[46]
S. Han, J. Pool, J. Tran, W. J. Dally, Learning both weights and connections for efficient neural networks, in: Proceedings of the 29th International Conference on Neural Information Processing Systems - Volume 1, NIPS’15, MIT Press, Cambridge, MA, USA, 2015, p. 1135–1143
work page 2015
-
[47]
Distilling the Knowledge in a Neural Network
G. Hinton, O. Vinyals, J. Dean, Distilling the knowledge in a neural network (2015). arXiv:1503. 02531. URL https://arxiv.org/abs/1503.02531 30
work page internal anchor Pith review Pith/arXiv arXiv 2015
- [48]
- [49]
-
[50]
K. Han, Y. Wang, Q. Tian, J. Guo, C. Xu, C. Xu, Ghostnet: More features from cheap operations, in: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 1577–1586. doi:10.1109/CVPR42600.2020.00165
- [51]
-
[52]
T.-Y. Lin, P. Goyal, R. Girshick, K. He, P. Dollar, Focal loss for dense object detection, in: Proceed- ings of the IEEE International Conference on Computer Vision (ICCV), 2017
work page 2017
-
[53]
S. S. M. Salehi, D. Erdogmus, A. Gholipour, Tversky loss function for image segmentation using 3d fully convolutional deep networks, in: Q. Wang, Y. Shi, H.-I. Suk, K. Suzuki (Eds.), Machine Learning in Medical Imaging, Springer International Publishing, Cham, 2017, pp. 379–387
work page 2017
- [54]
-
[55]
K. He, X. Zhang, S. Ren, J. Sun, Delving deep into rectifiers: Surpassing human-level performance on imagenet classification, in: 2015 IEEE International Conference on Computer Vision (ICCV), 2015, pp. 1026–1034. doi:10.1109/ICCV.2015.123
-
[56]
C. H. Sudre, W. Li, T. Vercauteren, S. Ourselin, M. Jorge Cardoso, Generalised dice overlap as a deep learning loss function for highly unbalanced segmentations, in: Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support, Springer International Publishing, Cham, 2017, pp. 240–248
work page 2017
- [57]
-
[58]
K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, in: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 770–778. doi:10. 1109/CVPR.2016.90
work page 2016
-
[59]
I. Loshchilov, F. Hutter, Decoupled weight decay regularization, in: International Conference on Learning Representations, 2017
work page 2017
-
[60]
A. Tarvainen, H. Valpola, Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results, in: I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, R. Garnett (Eds.), Advances in Neural Information Processing Systems, Vol. 30, Curran Associates, Inc., 2017
work page 2017
- [61]
-
[62]
H. Wang, J. Wang, B. Xiao, Y. Jiao, J. Guo, Drivable area and lane line detection model based on semantic segmentation, in: 2024 IEEE 3rd International Conference on Computing and Machine Intelligence (ICMI), 2024, pp. 1–7. doi:10.1109/ICMI60790.2024.10585878. 31
-
[63]
J. Zhao, D. Wu, Z. Yu, Z. Gao, Drmnet: A multi-task detection model based on image processing for autonomous driving scenarios, IEEE Transactions on Vehicular Technology (2023) 1–16 doi: 10.1109/TVT.2023.3296735
- [64]
-
[65]
G. Chen, T. Wu, J. Duan, Q. Hu, D. Huang, H. Li, Centerpnets: A multi-task shared network for traffic perception, Sensors 23 (5) (2023). doi:10.3390/s23052467
-
[66]
Y. Zhang, Y. Zheng, Z. Tu, C. Wu, T. Zhang, Cffm: Multi-task lane object detection method based on cross-layer feature fusion, Expert Systems with Applications 257 (2024) 125051. doi:https: //doi.org/10.1016/j.eswa.2024.125051
-
[67]
Q.-H. Che, D.-K. Lam, Trilitenet: Lightweight model for multi-task visual perception, IEEE Access 13 (2025) 50152–50166. doi:10.1109/ACCESS.2025.3552088
-
[68]
Z. Wang, W. Ren, Q. Qiu, Lanenet: Real-time lane detection networks for autonomous driving, CoRR abs/1807.01726 (2018). arXiv:1807.01726. 32
work page internal anchor Pith review Pith/arXiv arXiv 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.