Smart Bilingual Focused Crawling of Parallel Documents
Pith reviewed 2026-05-24 00:51 UTC · model grok-4.3
The pith
Neural models that read language and parallelism from URLs alone let crawlers locate more parallel documents while skipping many useless pages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
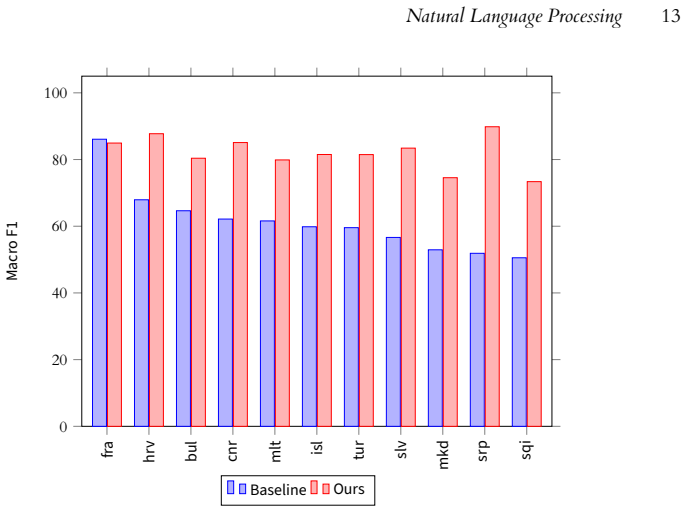
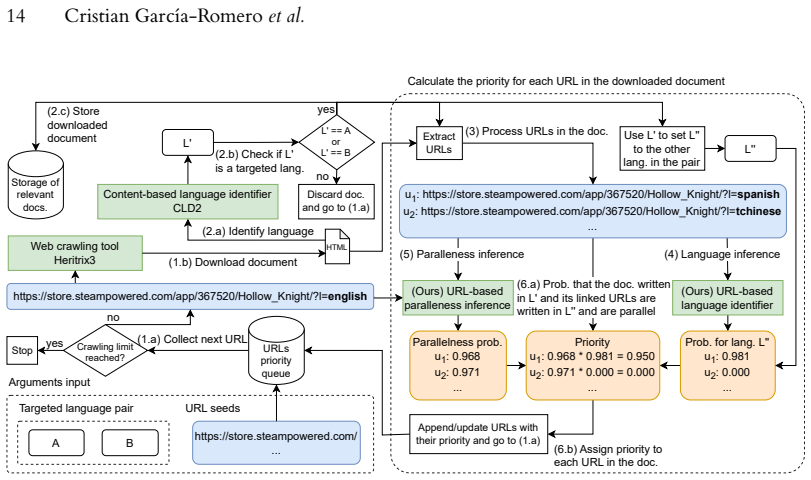
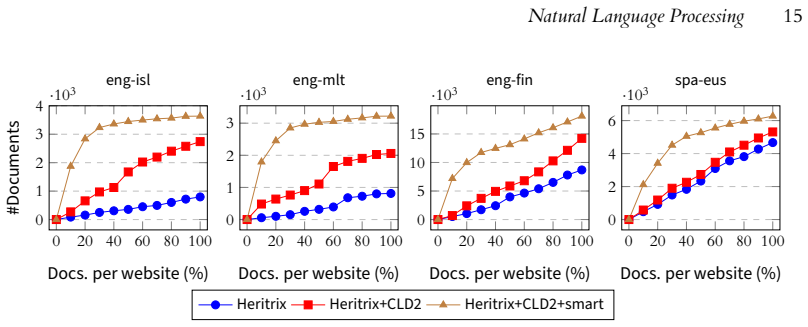
By fine-tuning a pre-trained multilingual Transformer encoder for the tasks of inferring document language from a single URL and inferring parallelism from a pair of URLs, the method enables early identification of parallel content during crawling; the resulting system downloads fewer non-parallel documents and returns a larger set of parallel pairs than conventional unguided crawling for the same language pair.
What carries the argument
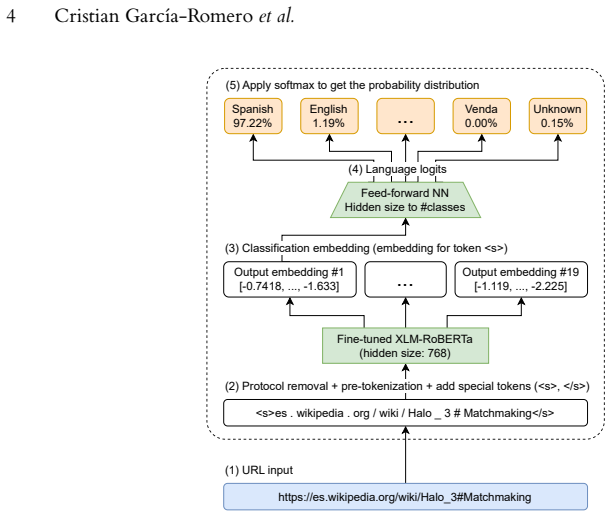
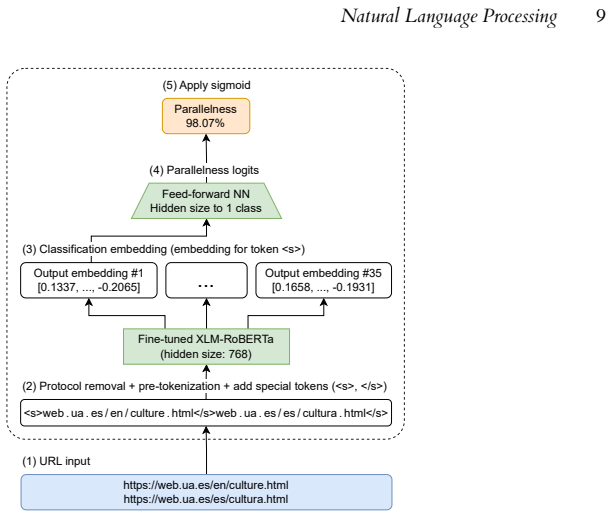
A single fine-tuned Transformer encoder performing two URL-based tasks: language identification from one URL and parallelism judgment from a URL pair.
If this is right
- The crawler can abandon or deprioritize branches of the web graph once language or parallelism predictions indicate low yield.
- For a fixed download budget, the number of extracted parallel documents increases.
- The same two models can be retrained for any new language pair provided suitable labeled URL data exist.
- Bandwidth and storage are saved because non-parallel pages are often identified before their full content is fetched.
Where Pith is reading between the lines
- The URL-only approach could be combined with lightweight content sampling after the first few bytes to handle sites whose URLs are uninformative.
- Extending the same training procedure to additional language pairs would test whether the reported gains generalize beyond the pairs evaluated in the paper.
- The method's efficiency gain depends on how often real web URLs carry language or parallelism cues; sites that hide such cues would limit the advantage.
Load-bearing premise
The models trained on the chosen data will keep their accuracy when applied to the URLs that appear during live crawling for the target language pair.
What would settle it
Run the smart crawler and a standard crawler from identical seed URLs for the same language pair and measure parallel pairs found per document downloaded; if the smart crawler does not collect more parallel pairs or does not reduce useless downloads, the central claim does not hold.
Figures
read the original abstract
Crawling parallel texts -- texts that are mutual translations -- from the Internet is usually done following a brute-force approach: documents are massively downloaded in an unguided process, and only a fraction of them end up leading to actual parallel content. In this work we propose a smart crawling method that guides the crawl towards finding parallel content more rapidly. We follow a neural approach that consists in adapting a pre-trained multilingual language model based on the encoder of the Transformer architecture by fine-tuning it for two new tasks: inferring the language of a document from its Uniform Resource Locator (URL), and inferring whether a pair of URLs link to parallel documents. We evaluate both models in isolation and their integration into a crawling tool. The results demonstrate the individual effectiveness of both models, and highlight that their combination enables us to address a practical engineering challenge: the early discovery of parallel content during web crawling in a given language pair. This leads to a reduction in the amount of downloaded documents deemed useless, and yields a greater quantity of parallel documents compared to conventional crawling approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a neural smart crawling method for parallel documents that fine-tunes a pre-trained multilingual Transformer encoder on two URL-based tasks: language identification from a single URL and parallelism detection from URL pairs. It claims that integrating these models enables earlier discovery of parallel content during crawling for a given language pair, thereby reducing the volume of useless documents downloaded and increasing the quantity of parallel documents obtained relative to conventional unguided crawling.
Significance. If the empirical claims are substantiated, the work could improve the efficiency of harvesting parallel corpora for machine translation, especially for lower-resource language pairs where brute-force crawling is particularly wasteful. The approach builds on standard fine-tuning of encoder-only models for auxiliary prediction tasks, which is a technically straightforward but potentially useful engineering contribution when the generalization holds.
major comments (2)
- [Abstract] Abstract: the central claims that the method 'leads to a reduction in the amount of downloaded documents deemed useless, and yields a greater quantity of parallel documents compared to conventional crawling approaches' are asserted without any quantitative metrics, baseline comparisons, dataset descriptions, or error analysis. This absence prevents assessment of whether the claimed benefits are realized.
- [Evaluation section] Evaluation (or equivalent results section): no experiments are reported that test model performance or crawling yield on URLs drawn from live web crawls rather than the training distribution. The central engineering claim depends on the models maintaining high precision on the long-tail, noisy URLs encountered in practice; without such evidence the early-pruning benefit is unverified.
minor comments (1)
- The manuscript should include explicit descriptions of the training corpora, fine-tuning hyperparameters, and evaluation metrics used for the two auxiliary tasks.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and constructive feedback. We address each major comment below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims that the method 'leads to a reduction in the amount of downloaded documents deemed useless, and yields a greater quantity of parallel documents compared to conventional crawling approaches' are asserted without any quantitative metrics, baseline comparisons, dataset descriptions, or error analysis. This absence prevents assessment of whether the claimed benefits are realized.
Authors: We agree that the abstract would be strengthened by including concrete quantitative support for the central claims. In the revised manuscript we will add specific metrics (e.g., percentage reduction in useless downloads and increase in parallel documents found) drawn from the evaluation section, along with brief references to the datasets and baselines used. revision: yes
-
Referee: [Evaluation section] Evaluation (or equivalent results section): no experiments are reported that test model performance or crawling yield on URLs drawn from live web crawls rather than the training distribution. The central engineering claim depends on the models maintaining high precision on the long-tail, noisy URLs encountered in practice; without such evidence the early-pruning benefit is unverified.
Authors: The evaluation section reports results on a large held-out test set of real-world URLs collected independently from the training data; these URLs exhibit the noise and diversity typical of web content. We will revise the text to explicitly describe the construction and characteristics of this test set and to discuss its relation to live-crawl distributions. While a full online crawling experiment would provide additional validation, the current offline evaluation already demonstrates the early-pruning benefit under realistic URL conditions. revision: partial
Circularity Check
No circularity; empirical ML application with external evaluation
full rationale
The paper trains two fine-tuned Transformer models on URL language ID and parallelism detection tasks, then measures their effect on crawling yield versus baseline crawlers. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central claim rests on measured reductions in useless downloads during live crawling, which is evaluated separately from the training objectives and does not reduce to a definitional identity or input fit.
Axiom & Free-Parameter Ledger
free parameters (1)
- fine-tuning hyperparameters
axioms (1)
- domain assumption A pre-trained multilingual Transformer encoder can be successfully adapted to URL-based language identification and parallelism detection via fine-tuning.
Reference graph
Works this paper leans on
-
[1]
InProceedings of the 58th annual meeting of the association for computational linguistics,4555–4567
ParaCrawl: web-scale acquisition of parallel corpora. InProceedings of the 58th annual meeting of the association for computational linguistics,4555–4567. Online: Association for Computational Linguistics, July. https://doi.org/10.18653/ v1/2020.acl-main.417. https://aclanthology.org/2020.acl-main.417. Bañón, Marta, Miquel Esplà-Gomis, Mikel L. Forcada, C...
-
[2]
No Language Left Behind: Scaling Human-Centered Machine Translation
https://aclanthology.org/W16-2367. Esplà-Gomis, Miquel, and Mikel L. Forcada. 2010. Combining content-based and URL-based heuristics to harvest aligned bitexts from multilingual sites with bitextor.The Prague Bulletin of Mathematical Linguistics,no. 93, 77–86. Facebook AI Research. 2017.Language identification with fasttext.https://f asttext.cc/docs/en/la...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/w19-5207 2010
-
[3]
MT5: a massively multilingual pre-trained text-to-text transformer. InProceedings of the 2021 conference of the north american chapter of the association for computational linguistics: human language technologies,edited by Kristina Toutanova, Anna Rumshisky, Luke Zettlemoyer, Dilek Hakkani-Tur, Iz Beltagy, Steven Bethard, Ryan Cotterell, Tanmoy Chakrabort...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.