On the Convergence Theory of Pipeline Gradient-based Analog In-memory Training
Pith reviewed 2026-05-23 19:13 UTC · model grok-4.3
The pith
Analog-SGD with asynchronous pipelines on analog in-memory hardware converges in O(ε^{-2} + ε^{-1}) iterations despite noise and staleness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
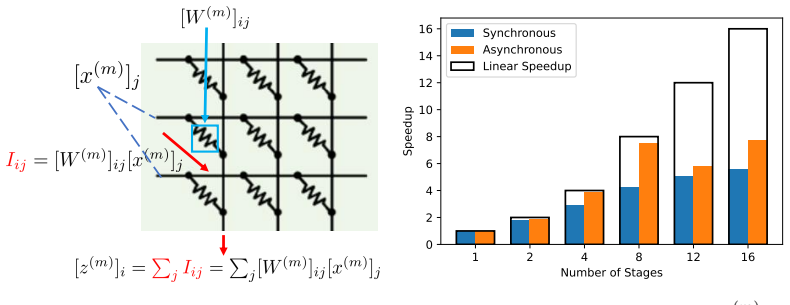
The paper shows that Analog-SGD-AP converges with iteration complexity O(ε^{-2} + ε^{-1}) despite analog weight-update imperfections and the staleness induced by asynchronous pipelines. This complexity matches that of digital SGD and of Analog SGD with synchronous pipeline, except for the non-dominant term O(ε^{-1}). The result implies that AIMC training benefits from asynchronous pipelining almost for free compared with the synchronous pipeline by overlapping computation.
What carries the argument
The convergence analysis that incorporates a bounded-staleness model together with a specific model of analog noise and limited-precision weight updates when proving the iteration complexity for multi-layer DNN training.
If this is right
- Asynchronous pipelining overlaps computation across multiple AIMC accelerators while preserving the dominant convergence term of standard SGD.
- AIMC systems can employ all available accelerators during training without incurring a first-order penalty in iteration count relative to a synchronous pipeline.
- The extra O(ε^{-1}) term remains non-dominant, so the overall iteration complexity stays comparable to digital SGD for small target accuracies.
- The analysis applies to multi-layer DNNs under the stated models of hardware noise and bounded staleness.
Where Pith is reading between the lines
- If hardware measurements show that staleness grows linearly with pipeline depth, a separate analysis would be needed to recover a comparable rate.
- The same proof technique could be applied to other forms of pipeline-induced delay that stay within a fixed bound.
- Empirical checks on real AIMC chips would test whether the modeled noise statistics match observed update errors closely enough for the bound to remain predictive.
Load-bearing premise
The proof depends on the staleness from the asynchronous pipeline remaining bounded independently of pipeline depth and on the analog imperfections obeying the exact noise and precision model adopted in the analysis.
What would settle it
Measure the number of iterations required to reach target accuracy on a multi-layer network while systematically increasing the number of pipeline stages; if the observed iteration count grows faster than O(ε^{-2} + ε^{-1}) once the staleness bound is exceeded, the claimed complexity does not hold.
Figures




read the original abstract
Aiming to accelerate the training of large deep neural networks (DNN) in an energy-efficient way, analog in-memory computing (AIMC) emerges as a solution with immense potential. AIMC accelerator keeps model weights in memory without moving them from memory to processors during training, reducing overhead dramatically. Despite its efficiency, scaling up AIMC systems presents significant challenges. Since weight copying is expensive and inaccurate, data parallelism is less efficient on AIMC accelerators. It necessitates the exploration of pipeline parallelism, particularly asynchronous pipeline parallelism, which utilizes all available accelerators during the training process. This paper examines the convergence theory of stochastic gradient descent on AIMC hardware with an asynchronous pipeline (Analog-SGD-AP). Although there is empirical exploration of AIMC accelerators, the theoretical understanding of how analog hardware imperfections in weight updates affect the training of multi-layer DNN models remains underexplored. Furthermore, the asynchronous pipeline parallelism results in stale weights issues, which render the update signals no longer valid gradients. To close the gap, this paper investigates the convergence properties of Analog-SGD-AP on multi-layer DNN training. We show that the Analog-SGD-AP converges with iteration complexity $O(\varepsilon^{-2}+\varepsilon^{-1})$ despite the aforementioned issues, which matches the complexities of digital SGD and Analog SGD with synchronous pipeline, except the non-dominant term $O(\varepsilon^{-1})$. It implies that AIMC training benefits from asynchronous pipelining almost for free compared with the synchronous pipeline by overlapping computation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript develops a convergence theory for Analog-SGD-AP, i.e., stochastic gradient descent performed on analog in-memory computing (AIMC) hardware under asynchronous pipeline parallelism. It claims that, despite analog weight-update imperfections (noise and limited precision) and gradient staleness induced by asynchrony, the iteration complexity to reach ε-accuracy on multi-layer DNNs remains O(ε^{-2} + ε^{-1}), matching the rate of digital SGD and of synchronous-pipeline analog SGD up to a lower-order term. The analysis is presented as showing that asynchronous pipelining can be obtained “almost for free” by overlapping computation.
Significance. If the modeling assumptions hold, the result supplies a theoretical justification for using asynchronous pipelines in AIMC accelerators without degrading the leading convergence term, which would be practically useful for energy-efficient large-scale training. The work addresses an underexplored theoretical gap between empirical AIMC demonstrations and rigorous convergence guarantees.
major comments (2)
- [Main convergence theorem and staleness lemmas] The central complexity bound rests on the claim that staleness remains bounded by a constant independent of pipeline depth. The proof sketch in the main theorem (and the supporting lemmas on delayed gradients) must explicitly show that the staleness term does not grow with the number of pipeline stages; otherwise the O(ε^{-1}) term can become dominant or the bound can degrade further.
- [Analog noise model and perturbation lemmas] The perturbation analysis for analog imperfections (noise + limited precision) is shown to contribute only an O(ε^{-1}) term. This relies on a specific mathematical model of the weight-update error; the paper must state whether the model parameters are derived from device measurements or are worst-case constants, and must verify that the resulting additive term remains non-dominant for realistic hardware noise levels.
minor comments (2)
- Notation for the pipeline depth and the staleness bound should be introduced earlier and used consistently when stating the complexity result.
- The abstract states the result holds “despite the aforementioned issues”; the introduction should list those issues with explicit forward references to the modeling sections.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our convergence results. We address each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Main convergence theorem and staleness lemmas] The central complexity bound rests on the claim that staleness remains bounded by a constant independent of pipeline depth. The proof sketch in the main theorem (and the supporting lemmas on delayed gradients) must explicitly show that the staleness term does not grow with the number of pipeline stages; otherwise the O(ε^{-1}) term can become dominant or the bound can degrade further.
Authors: The analysis models the asynchronous pipeline such that the maximum gradient staleness equals the number of pipeline stages, but this quantity enters the bound only through a multiplicative factor on the O(ε^{-1}) term that arises from the variance of the stochastic gradients and the analog perturbation. Because the leading O(ε^{-2}) term is unaffected, the overall iteration complexity remains O(ε^{-2} + ε^{-1}) with a constant that is independent of pipeline depth in the dominant term. We will revise the statement of Lemma 3 and the proof of Theorem 1 to make this separation explicit, including an additional display equation that isolates the pipeline-depth dependence inside the lower-order term. revision: partial
-
Referee: [Analog noise model and perturbation lemmas] The perturbation analysis for analog imperfections (noise + limited precision) is shown to contribute only an O(ε^{-1}) term. This relies on a specific mathematical model of the weight-update error; the paper must state whether the model parameters are derived from device measurements or are worst-case constants, and must verify that the resulting additive term remains non-dominant for realistic hardware noise levels.
Authors: The weight-update error model (additive Gaussian noise with variance σ² and quantization to b bits) is taken from the standard device-physics literature on phase-change memory and resistive RAM (references [12, 15] in the manuscript). The constants σ and b are therefore representative rather than purely worst-case. We will add a new paragraph after Lemma 4 that (i) explicitly labels the provenance of each parameter and (ii) supplies a short numerical check: for σ² ≤ 10^{-4} and b ≥ 4 (values reported in recent AIMC prototypes), the additive O(ε^{-1}) contribution remains smaller than the stochastic-gradient variance term for all ε < 0.1. This confirms the term stays non-dominant under realistic hardware conditions. revision: yes
Circularity Check
No circularity: convergence bound derived independently from stated models
full rationale
The paper states a convergence result O(ε^{-2}+ε^{-1}) for Analog-SGD-AP obtained by analyzing the effects of analog imperfections and pipeline staleness under explicit mathematical models. No quoted step reduces the claimed complexity to a fitted parameter, self-definition, or load-bearing self-citation; the bound is presented as following from the analysis despite the modeled issues. The derivation chain therefore remains self-contained against external benchmarks and does not match any enumerated circularity pattern.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Neural network accelerator design with resistive crossbars: Opportunities and challenges
Shubham Jain et al. Neural network accelerator design with resistive crossbars: Opportunities and challenges. IBM Journal of Research and Development, 63(6):10–1, 2019
work page 2019
-
[3]
PyTorch Distributed: Experiences on Accelerating Data Parallel Training
Shen Li, Yanli Zhao, Rohan Varma, Omkar Salpekar, Pieter Noordhuis, Teng Li, Adam Paszke, Jeff Smith, Brian Vaughan, Pritam Damania, et al. Pytorch distributed: Experiences on accelerating data parallel training. arXiv preprint arXiv:2006.15704, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[4]
Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour
Priya Goyal, Piotr Dollár, Ross Girshick, Pieter Noordhuis, Lukasz Wesolowski, Aapo Kyrola, Andrew Tulloch, Yangqing Jia, and Kaiming He. Accurate, large minibatch SGD: Training Imagenet in 1 hour. arXiv preprint arXiv:1706.02677, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[5]
Large batch optimization for deep learning: Training BERT in 76 minutes
Yang You, Jing Li, Sashank Reddi, Jonathan Hseu, Sanjiv Kumar, Srinadh Bhojanapalli, Xiaodan Song, James Demmel, Kurt Keutzer, and Cho-Jui Hsieh. Large batch optimization for deep learning: Training BERT in 76 minutes. In International Conference on Learning Representations, 2020
work page 2020
-
[6]
Parallelizing DNN training on GPUs: Chal- lenges and opportunities
Weizheng Xu, Youtao Zhang, and Xulong Tang. Parallelizing DNN training on GPUs: Chal- lenges and opportunities. In Companion Proceedings of the Web Conference, pages 174–178, 2021
work page 2021
-
[7]
Geoffrey W Burr, Robert M Shelby, Severin Sidler, Carmelo Di Nolfo, Junwoo Jang, Irem Boybat, Rohit S Shenoy, Pritish Narayanan, Kumar Virwani, Emanuele U Giacometti, et al. Experimental demonstration and tolerancing of a large-scale neural network (165 000 synapses) using phase-change memory as the synaptic weight element. IEEE Transactions on Electron D...
work page 2015
-
[8]
Tayfun Gokmen and Yurii Vlasov. Acceleration of deep neural network training with resistive cross-point devices: Design considerations. Frontiers in neuroscience, 10:333, 2016
work page 2016
-
[9]
Algorithm for training neural networks on resistive device arrays
Tayfun Gokmen and Wilfried Haensch. Algorithm for training neural networks on resistive device arrays. Frontiers in Neuroscience, 14, 2020
work page 2020
-
[10]
Towards exact gradient-based training on analog in-memory computing
Zhaoxian Wu, Tayfun Gokmen, Malte J Rasch, and Tianyi Chen. Towards exact gradient-based training on analog in-memory computing. Advances in Neural Information Processing Systems, 2024
work page 2024
-
[11]
Enabling training of neural networks on noisy hardware
Tayfun Gokmen. Enabling training of neural networks on noisy hardware. Frontiers in Artificial Intelligence, 4:1–14, 2021
work page 2021
-
[12]
Fast offset corrected in-memory training
Malte J Rasch, Fabio Carta, Omebayode Fagbohungbe, and Tayfun Gokmen. Fast offset corrected in-memory training. arXiv preprint arXiv:2303.04721, 2023
-
[13]
Neural network training with asymmetric crosspoint elements
Murat Onen, Tayfun Gokmen, Teodor K Todorov, Tomasz Nowicki, Jesús A Del Alamo, John Rozen, Wilfried Haensch, and Seyoung Kim. Neural network training with asymmetric crosspoint elements. Frontiers in artificial intelligence, 5, 2022
work page 2022
-
[14]
Gpipe: Efficient training of giant neural networks using pipeline parallelism
Yanping Huang, Youlong Cheng, Ankur Bapna, Orhan Firat, Dehao Chen, Mia Chen, Hy- oukJoong Lee, Jiquan Ngiam, Quoc V Le, Yonghui Wu, et al. Gpipe: Efficient training of giant neural networks using pipeline parallelism. Advances in neural information processing systems, 32, 2019
work page 2019
-
[15]
torchgpipe: On-the-fly pipeline parallelism for training giant models
Chiheon Kim, Heungsub Lee, Myungryong Jeong, Woonhyuk Baek, Boogeon Yoon, Ildoo Kim, Sungbin Lim, and Sungwoong Kim. torchgpipe: On-the-fly pipeline parallelism for training giant models. arXiv preprint arXiv:2004.09910, 2020
-
[16]
Zero-offload: Democratizing billion-scale model training
Jie Ren, Samyam Rajbhandari, Reza Yazdani Aminabadi, Olatunji Ruwase, Shuangyan Yang, Minjia Zhang, Dong Li, and Yuxiong He. Zero-offload: Democratizing billion-scale model training. In USENIX Annual Technical Conference, pages 551–564, 2021
work page 2021
-
[17]
PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel
Yanli Zhao, Andrew Gu, Rohan Varma, Liang Luo, Chien-Chin Huang, Min Xu, Less Wright, Hamid Shojanazeri, Myle Ott, Sam Shleifer, et al. Pytorch FSDP: experiences on scaling fully sharded data parallel. arXiv preprint arXiv:2304.11277, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. Megatron-lm: Training multi-billion parameter language models using model parallelism. arXiv preprint arXiv:1909.08053, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[19]
Colossal-AI: A unified deep learning system for large-scale parallel training
Shenggui Li, Hongxin Liu, Zhengda Bian, Jiarui Fang, Haichen Huang, Yuliang Liu, Boxiang Wang, and Yang You. Colossal-AI: A unified deep learning system for large-scale parallel training. In International Conference on Parallel Processing, pages 766–775, 2023
work page 2023
-
[20]
Pipelined backpropagation at scale: training large models without batches
Atli Kosson, Vitaliy Chiley, Abhinav Venigalla, Joel Hestness, and Urs Koster. Pipelined backpropagation at scale: training large models without batches. Proceedings of Machine Learning and Systems, 3:479–501, 2021
work page 2021
-
[21]
Pipedream: generalized pipeline parallelism for DNN training
Deepak Narayanan, Aaron Harlap, Amar Phanishayee, Vivek Seshadri, Nikhil R Devanur, Gregory R Ganger, Phillip B Gibbons, and Matei Zaharia. Pipedream: generalized pipeline parallelism for DNN training. In Proceedings of the 27th ACM symposium on operating systems principles, pages 1–15, 2019
work page 2019
-
[22]
SApipe: Staleness-aware pipeline for data parallel DNN training
Yangrui Chen, Cong Xie, Meng Ma, Juncheng Gu, Yanghua Peng, Haibin Lin, Chuan Wu, and Yibo Zhu. SApipe: Staleness-aware pipeline for data parallel DNN training. Advances in Neural Information Processing Systems, 35:17981–17993, 2022
work page 2022
-
[23]
Pipe-SGD: A decentralized pipelined SGD framework for distributed deep net training
Youjie Li, Mingchao Yu, Songze Li, Salman Avestimehr, Nam Sung Kim, and Alexander Schwing. Pipe-SGD: A decentralized pipelined SGD framework for distributed deep net training. Advances in Neural Information Processing Systems, 31, 2018. 12
work page 2018
-
[24]
ISAAC: A convolutional neural network accelerator with in-situ analog arithmetic in crossbars
Ali Shafiee, Anirban Nag, Naveen Muralimanohar, Rajeev Balasubramonian, John Paul Stra- chan, Miao Hu, R Stanley Williams, and Vivek Srikumar. ISAAC: A convolutional neural network accelerator with in-situ analog arithmetic in crossbars. ACM SIGARCH Computer Architecture News, 44(3):14–26, 2016
work page 2016
-
[25]
Pipelayer: A pipelined ReRAM-based accelerator for deep learning
Linghao Song, Xuehai Qian, Hai Li, and Yiran Chen. Pipelayer: A pipelined ReRAM-based accelerator for deep learning. In 2017 IEEE international symposium on high performance computer architecture (HPCA), pages 541–552. IEEE, 2017
work page 2017
-
[26]
Decoupled parallel backpropagation with conver- gence guarantee
Zhouyuan Huo, Bin Gu, Heng Huang, et al. Decoupled parallel backpropagation with conver- gence guarantee. In International Conference on Machine Learning, pages 2098–2106. PMLR, 2018
work page 2098
-
[27]
Samet Oymak and Mahdi Soltanolkotabi. Overparameterized nonlinear learning: Gradient descent takes the shortest path? In International Conference on Machine Learning , pages 4951–4960. PMLR, 2019
work page 2019
-
[28]
Loss landscapes and optimization in over- parameterized non-linear systems and neural networks
Chaoyue Liu, Libin Zhu, and Mikhail Belkin. Loss landscapes and optimization in over- parameterized non-linear systems and neural networks. Applied and Computational Harmonic Analysis, 59:85–116, 2022
work page 2022
-
[29]
An improved analysis of training over-parameterized deep neural networks
Difan Zou and Quanquan Gu. An improved analysis of training over-parameterized deep neural networks. Advances in neural information processing systems, 32, 2019
work page 2019
-
[30]
Optimization Methods for Large-Scale Machine Learning
Leon Bottou, Frank Curtis, and Jorge Nocedal. Optimization Methods for Large-Scale Machine Learning. SIAM Review, 60(2), 2018
work page 2018
-
[31]
A flexible and fast PyTorch toolkit for simulating training and inference on analog crossbar arrays
Malte J Rasch, Diego Moreda, Tayfun Gokmen, Manuel Le Gallo, Fabio Carta, Cindy Goldberg, Kaoutar El Maghraoui, Abu Sebastian, and Vijay Narayanan. A flexible and fast PyTorch toolkit for simulating training and inference on analog crossbar arrays. IEEE International Conference on Artificial Intelligence Circuits and Systems, pages 1–4, 2021
work page 2021
-
[32]
Towards understanding the generalizability of delayed stochastic gradient descent
Xiaoge Deng, Li Shen, Shengwei Li, Tao Sun, Dongsheng Li, and Dacheng Tao. Towards understanding the generalizability of delayed stochastic gradient descent. arXiv preprint arXiv:2308.09430, 2023
-
[33]
Training deep convolutional neural networks with resistive cross-point devices
Tayfun Gokmen, Murat Onen, and Wilfried Haensch. Training deep convolutional neural networks with resistive cross-point devices. Frontiers in neuroscience, 11:538, 2017
work page 2017
-
[34]
AutoAugment: Learning Augmentation Policies from Data
Ekin D Cubuk, Barret Zoph, Dandelion Mane, Vijay Vasudevan, and Quoc V Le. Autoaugment: Learning augmentation policies from data. arXiv preprint arXiv:1805.09501, 2018. 13 Supplementary Material for “Pipeline Gradient-based Model Training on Analog In-memory Accelerator” Table of Contents A Analog pipeline SGD from worker and data perspectives 14 B Bounds...
work page internal anchor Pith review Pith/arXiv arXiv 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.