Mechanisms of Multimodal Synchronization: Insights from Decoder-Based Video-Text-to-Speech Synthesis
Pith reviewed 2026-05-23 17:19 UTC · model grok-4.3
The pith
Both global sequential indexing and co-temporal ordered indexing enable strong synchronization of video, text, and speech in a unified decoder-only transformer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In the Visatronic decoder-only transformer trained on VoxCeleb2, global sequential indexing (unique position IDs across modalities) and co-temporal ordered indexing (identical IDs for temporally corresponding tokens) both achieve strong synchronization performance. Text ensures intelligibility while video supplies temporal cues and emotional expressiveness. Video-first ordering yields stronger in-domain performance, whereas text-first ordering generalizes more robustly to unseen domains. Diverse large-scale training supports transferable synchronization strategies, and the introduced TimeSync metric exposes per-phoneme timing errors missed by coarser measures.
What carries the argument
Positional encoding strategies of global sequential indexing and co-temporal ordered indexing that align tokens from heterogeneous modalities inside a single decoder-only transformer.
If this is right
- Text and video supply complementary signals that together improve intelligibility, timing, and expressiveness in generated speech.
- Modality ordering produces a consistent trade-off between in-domain accuracy and cross-domain robustness.
- Large-scale diverse training enables synchronization strategies to transfer across domains.
- Phoneme-level metrics such as TimeSync diagnose timing misalignments that frame-level metrics overlook.
Where Pith is reading between the lines
- The same indexing methods could simplify alignment in other multimodal decoder tasks such as video-conditioned captioning.
- Choosing modality order at training time offers a practical lever for controlling generalization without changing the architecture.
- If co-temporal indexing works without explicit timestamps, it reduces the need for additional metadata pipelines in deployed multimodal systems.
Load-bearing premise
The synchronization behaviors and modality-ordering trade-offs observed on the VoxCeleb2-trained VTTS task represent general multimodal synchronization mechanisms in decoder-only transformers.
What would settle it
Repeating the same experiments on a different multimodal generation task or dataset and observing that one indexing method collapses while the other remains effective would falsify the claim of general applicability.
Figures










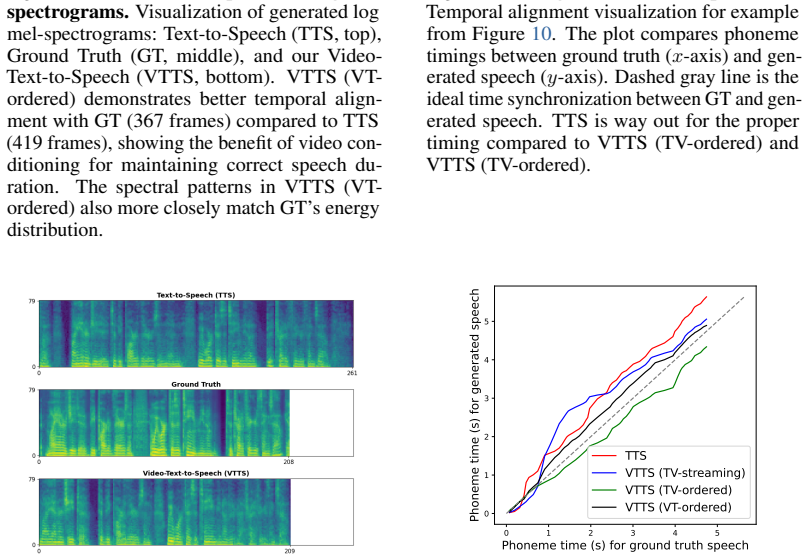


read the original abstract
Unified decoder-only transformers have shown promise for multimodal generation, yet the mechanisms by which they synchronize modalities with heterogeneous sampling rates remain underexplored. We investigate these mechanisms through video-text-to-speech (VTTS) synthesis-a controlled task requiring fine-grained temporal alignment between sparse text, video, and continuous speech. Using a unified decoder-only transformer, dubbed Visatronic, trained on VoxCeleb2, we study: (i) how modalities contribute complementary information, (ii) how positional encoding strategies enable synchronization across heterogeneous rates, (iii) how modality ordering shapes the trade-off between in-domain performance and cross-domain transfer, (iv) how phoneme-level synchronization metrics provide diagnostic insight into per-phoneme timing errors. Our findings reveal that both "global sequential indexing'' (unique position IDs across modalities) and "co-temporal ordered indexing'' (identical IDs for temporally corresponding tokens) achieve strong synchronization performance, with co-temporal ordered indexing providing a simple mechanism without explicit timestamp metadata. Both text and video contribute complementary signals: text ensures intelligibility while video provides temporal cues and emotional expressiveness. Modality ordering reveals a consistent trade-off: video-first ordering achieves stronger in-domain performance while text-first ordering generalizes more robustly to unseen domains. Our findings also reveal, that diverse large-scale training enables transferable synchronization strategies. To enable fine-grained analysis, we also introduce TimeSync, a phoneme-level metric that reveals temporal misalignments overlooked by frame-level metrics. These insights establish VTTS as a valuable testbed for understanding temporal synchronization in unified multimodal decoders.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates mechanisms of multimodal synchronization in unified decoder-only transformers via a video-text-to-speech (VTTS) task using the Visatronic model trained on VoxCeleb2. It examines how modalities contribute complementary information (text for intelligibility, video for temporal/emotional cues), compares positional encoding strategies (global sequential indexing vs. co-temporal ordered indexing), analyzes modality ordering trade-offs (video-first for in-domain performance vs. text-first for cross-domain generalization), and introduces the TimeSync phoneme-level metric to diagnose temporal misalignments. The central claims are that both indexing approaches enable strong synchronization without explicit timestamps and that diverse training yields transferable strategies.
Significance. If the empirical findings on indexing and ordering hold under broader validation, the work offers concrete design insights for handling heterogeneous sampling rates in decoder-only multimodal models and introduces a useful fine-grained diagnostic (TimeSync) that improves on frame-level metrics. The paper's strength lies in its controlled VTTS testbed and direct measurement of synchronization behaviors rather than derived claims.
major comments (2)
- [Abstract] Abstract: The assertion that the reported synchronization behaviors and modality-ordering trade-offs reveal 'general mechanisms' for decoder-only multimodal transformers is load-bearing for the paper's contribution but rests on experiments limited to VTTS on VoxCeleb2 (with speech-centric held-out domains); no ablations on alternative tasks, architectures, or non-speech modalities are described, leaving open whether results are specific to this setup's sampling rates and causal attention.
- [Abstract] Abstract: The abstract states clear experimental findings on indexing performance and modality contributions, yet provides no quantitative results, statistical tests, ablation controls, or details on architecture/training procedure, making it impossible to assess whether reported differences are robust or influenced by post-hoc metric/data choices.
minor comments (2)
- The description of 'global sequential indexing' and 'co-temporal ordered indexing' would benefit from explicit pseudocode or a small diagram to clarify token-to-ID mapping across modalities.
- Clarify whether TimeSync is evaluated with statistical significance testing across phonemes or speakers, as this would strengthen the diagnostic claims.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the scope of our claims and the abstract's level of detail. We address each point below with proposed revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that the reported synchronization behaviors and modality-ordering trade-offs reveal 'general mechanisms' for decoder-only multimodal transformers is load-bearing for the paper's contribution but rests on experiments limited to VTTS on VoxCeleb2 (with speech-centric held-out domains); no ablations on alternative tasks, architectures, or non-speech modalities are described, leaving open whether results are specific to this setup's sampling rates and causal attention.
Authors: We agree that the experiments are limited to the VTTS task on VoxCeleb2 and that broader validation would be required to claim fully general mechanisms across decoder-only multimodal models. The manuscript uses VTTS as a controlled testbed precisely because of its heterogeneous sampling rates and fine-grained alignment demands, but we will revise the abstract to qualify the language. We will change the final sentence from 'These insights establish VTTS as a valuable testbed for understanding temporal synchronization in unified multimodal decoders' to 'These insights, demonstrated in the VTTS setting, provide concrete design considerations for handling heterogeneous sampling rates in decoder-only multimodal models.' This removes the load-bearing generality claim while preserving the contribution. revision: yes
-
Referee: [Abstract] Abstract: The abstract states clear experimental findings on indexing performance and modality contributions, yet provides no quantitative results, statistical tests, ablation controls, or details on architecture/training procedure, making it impossible to assess whether reported differences are robust or influenced by post-hoc metric/data choices.
Authors: Abstracts are conventionally high-level, but we accept that including key quantitative anchors would improve evaluability. In revision we will add concise references to core results (e.g., 'co-temporal ordered indexing matches global sequential indexing on TimeSync while improving cross-domain generalization under text-first ordering') and note that full architecture, training, and statistical details appear in Sections 3–5. Because space constraints prevent exhaustive ablation descriptions in the abstract itself, we treat this as a partial revision focused on the most salient metrics. revision: partial
Circularity Check
No circularity; all claims are direct empirical measurements from trained models on VoxCeleb2 VTTS task
full rationale
The paper reports experimental results from training a unified decoder-only transformer (Visatronic) on VoxCeleb2 for video-text-to-speech synthesis. It compares positional encoding strategies (global sequential vs. co-temporal ordered indexing), modality orderings (video-first vs. text-first), and measures contributions via metrics including a new phoneme-level TimeSync. All stated findings (synchronization performance, complementarity of text/video, in-domain vs. generalization trade-offs) are presented as outcomes of these trained-model evaluations rather than any derivation, fitted-parameter prediction, or self-citation chain. No equations, uniqueness theorems, or ansatzes are invoked that reduce to the inputs by construction. The work is self-contained against external benchmarks as a set of controlled ablation experiments.
Axiom & Free-Parameter Ledger
free parameters (2)
- neural network weights
- training hyperparameters
axioms (1)
- domain assumption A decoder-only transformer can learn to align heterogeneous modalities when trained on paired video-text-speech data.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
both 'global sequential indexing' (unique position IDs across modalities) and 'co-temporal ordered indexing' (identical IDs for temporally corresponding tokens) achieve strong synchronization performance
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
TimeSync phoneme-level metric... VTTS as a valuable testbed for understanding temporal synchronization in unified multimodal decoders
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
LRS3-TED: a large-scale dataset for visual speech recognition
Triantafyllos Afouras, Joon Son Chung, and Andrew Zisserman. Lrs3-ted: a large-scale dataset for visual speech recognition. arXiv preprint arXiv:1809.00496, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[2]
Lip2audspec: Speech reconstruction from silent lip movements video
Hassan Akbari, Himani Arora, Liangliang Cao, and Nima Mesgarani. Lip2audspec: Speech reconstruction from silent lip movements video. In 2018 IEEE international conference on acoustics, speech and signal processing (ICASSP), pages 2516–2520. IEEE, 2018
work page 2018
-
[3]
A 3T: Alignment-aware acoustic and text pretraining for speech synthesis and editing
He Bai, Renjie Zheng, Junkun Chen, Mingbo Ma, Xintong Li, and Liang Huang. A 3T: Alignment-aware acoustic and text pretraining for speech synthesis and editing. In Proceedings of the 39th International Conference on Machine Learning, pages 1399–1411. PMLR, 2022
work page 2022
-
[4]
dmel: Speech tokenization made simple
He Bai, Tatiana Likhomanenko, Ruixiang Zhang, Zijin Gu, Zakaria Aldeneh, and Navdeep Jaitly. dmel: Speech tokenization made simple. arXiv preprint arXiv:2407.15835, 2024
-
[5]
Audiolm: a language modeling approach to audio generation
Zalán Borsos, Raphaël Marinier, Damien Vincent, Eugene Kharitonov, Olivier Pietquin, Matt Sharifi, Dominik Roblek, Olivier Teboul, David Grangier, Marco Tagliasacchi, et al. Audiolm: a language modeling approach to audio generation. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2023
work page 2023
-
[6]
A Short Note about Kinetics-600
Joao Carreira, Eric Noland, Andras Banki-Horvath, Chloe Hillier, and Andrew Zisserman. A short note about kinetics-600. arXiv preprint arXiv:1808.01340, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[7]
Adaspeech: Adaptive text to speech for custom voice
Mingjian Chen, Xu Tan, Bohan Li, Yanqing Liu, Tao Qin, Sheng Zhao, and Tie-Yan Liu. Adaspeech: Adaptive text to speech for custom voice. arXiv preprint arXiv:2103.00993, 2021
-
[8]
Qi Chen, Mingkui Tan, Yuankai Qi, Jiaqiu Zhou, Yuanqing Li, and Qi Wu. V2c: Visual voice cloning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21242–21251, 2022
work page 2022
-
[9]
Diffv2s: Diffusion-based video-to-speech synthesis with vision-guided speaker embedding
Jeongsoo Choi, Joanna Hong, and Yong Man Ro. Diffv2s: Diffusion-based video-to-speech synthesis with vision-guided speaker embedding. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 7812–7821, 2023
work page 2023
-
[10]
V oxCeleb2: Deep Speaker Recogni- tion
Joon Son Chung, Arsha Nagrani, and Andrew Zisserman. V oxCeleb2: Deep Speaker Recogni- tion. In Proc. Interspeech 2018, pages 1086–1090, 2018
work page 2018
-
[11]
Learning to dub movies via hierarchical prosody models
Gaoxiang Cong, Liang Li, Yuankai Qi, Zheng-Jun Zha, Qi Wu, Wenyu Wang, Bin Jiang, Ming- Hsuan Yang, and Qingming Huang. Learning to dub movies via hierarchical prosody models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 14687–14697, 2023
work page 2023
-
[12]
Styledubber: towards multi-scale style learning for movie dubbing
Gaoxiang Cong, Yuankai Qi, Liang Li, Amin Beheshti, Zhedong Zhang, Anton van den Hengel, Ming-Hsuan Yang, Chenggang Yan, and Qingming Huang. Styledubber: towards multi-scale style learning for movie dubbing. arXiv preprint arXiv:2402.12636, 2024
-
[13]
Real time speech enhancement in the waveform domain
Alexandre Defossez, Gabriel Synnaeve, and Yossi Adi. Real time speech enhancement in the waveform domain. In Interspeech, 2020
work page 2020
-
[14]
High Fidelity Neural Audio Compression
Alexandre Défossez, Jade Copet, Gabriel Synnaeve, and Yossi Adi. High fidelity neural audio compression. arXiv preprint arXiv:2210.13438, 2022. 10
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[15]
Vid2speech: speech reconstruction from silent video
Ariel Ephrat and Shmuel Peleg. Vid2speech: speech reconstruction from silent video. In 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 5095–5099. IEEE, 2017
work page 2017
-
[16]
Shunsuke Goto, Kotaro Onishi, Yuki Saito, Kentaro Tachibana, and Koichiro Mori. Face2speech: Towards multi-speaker text-to-speech synthesis using an embedding vector predicted from a face image. In INTERSPEECH, pages 1321–1325, 2020
work page 2020
-
[17]
Wei-Ning Hsu, Tal Remez, Bowen Shi, Jacob Donley, and Yossi Adi. Revise: Self-supervised speech resynthesis with visual input for universal and generalized speech regeneration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18795–18805, 2023
work page 2023
-
[18]
Neural dubber: Dubbing for videos according to scripts
Chenxu Hu, Qiao Tian, Tingle Li, Wang Yuping, Yuxuan Wang, and Hang Zhao. Neural dubber: Dubbing for videos according to scripts. Advances in neural information processing systems, 34:16582–16595, 2021
work page 2021
-
[19]
Generspeech: Towards style transfer for generalizable out-of-domain text-to-speech
Rongjie Huang, Yi Ren, Jinglin Liu, Chenye Cui, and Zhou Zhao. Generspeech: Towards style transfer for generalizable out-of-domain text-to-speech. Advances in Neural Information Processing Systems, 35:10970–10983, 2022
work page 2022
-
[20]
Transfer learning from speaker verification to multispeaker text-to-speech synthesis
Ye Jia, Yu Zhang, Ron Weiss, Quan Wang, Jonathan Shen, Fei Ren, Patrick Nguyen, Ruoming Pang, Ignacio Lopez Moreno, Yonghui Wu, et al. Transfer learning from speaker verification to multispeaker text-to-speech synthesis. Advances in neural information processing systems, 31, 2018
work page 2018
-
[21]
Neural voice cloning with a few low-quality samples
Sunghee Jung and Hoirin Kim. Neural voice cloning with a few low-quality samples. arXiv preprint arXiv:2006.06940, 2020
-
[22]
Glow-tts: A generative flow for text-to-speech via monotonic alignment search
Jaehyeon Kim, Sungwon Kim, Jungil Kong, and Sungroh Yoon. Glow-tts: A generative flow for text-to-speech via monotonic alignment search. Advances in Neural Information Processing Systems, 33:8067–8077, 2020
work page 2020
-
[23]
Lip to speech synthesis with visual context attentional gan
Minsu Kim, Joanna Hong, and Yong Man Ro. Lip to speech synthesis with visual context attentional gan. Advances in Neural Information Processing Systems, 34:2758–2770, 2021
work page 2021
-
[24]
Lip-to-speech synthesis in the wild with multi- task learning
Minsu Kim, Joanna Hong, and Yong Man Ro. Lip-to-speech synthesis in the wild with multi- task learning. In ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2023
work page 2023
-
[25]
Dan Kondratyuk, Lijun Yu, Xiuye Gu, Jose Lezama, Jonathan Huang, Grant Schindler, Rachel Hornung, Vighnesh Birodkar, Jimmy Yan, Ming-Chang Chiu, Krishna Somandepalli, Hassan Akbari, Yair Alon, Yong Cheng, Joshua V . Dillon, Agrim Gupta, Meera Hahn, Anja Hauth, David Hendon, Alonso Martinez, David Minnen, Mikhail Sirotenko, Kihyuk Sohn, Xuan Yang, Hartwig ...
work page 2024
-
[26]
DiffWave: A Versatile Diffusion Model for Audio Synthesis
Zhifeng Kong, Wei Ping, Jiaji Huang, Kexin Zhao, and Bryan Catanzaro. Diffwave: A versatile diffusion model for audio synthesis. arXiv preprint arXiv:2009.09761, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[27]
Imaginary voice: Face-styled diffusion model for text-to-speech
Jiyoung Lee, Joon Son Chung, and Soo-Whan Chung. Imaginary voice: Face-styled diffusion model for text-to-speech. In ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2023
work page 2023
-
[28]
Pvae-tts: Adaptive text-to- speech via progressive style adaptation
Ji-Hyun Lee, Sang-Hoon Lee, Ji-Hoon Kim, and Seong-Whan Lee. Pvae-tts: Adaptive text-to- speech via progressive style adaptation. In ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 6312–6316. IEEE, 2022
work page 2022
-
[29]
Priorgrad: Improving conditional denoising diffusion models with data-dependent adaptive prior
Sang-gil Lee, Heeseung Kim, Chaehun Shin, Xu Tan, Chang Liu, Qi Meng, Tao Qin, Wei Chen, Sungroh Yoon, and Tie-Yan Liu. Priorgrad: Improving conditional denoising diffusion models with data-dependent adaptive prior. arXiv preprint arXiv:2106.06406, 2021. 11
-
[30]
Sang-Hoon Lee, Hyun-Wook Yoon, Hyeong-Rae Noh, Ji-Hoon Kim, and Seong-Whan Lee. Multi-spectrogan: High-diversity and high-fidelity spectrogram generation with adversarial style combination for speech synthesis. In Proceedings of the AAAI Conference on Artificial Intelligence, 2021
work page 2021
-
[31]
M3tts: Multi-modal text-to-speech of multi-scale style control for dubbing
Yan Liu, Li-Fang Wei, Xinyuan Qian, Tian-Hao Zhang, Song-Lu Chen, and Xu-Cheng Yin. M3tts: Multi-modal text-to-speech of multi-scale style control for dubbing. Pattern Recognition Letters, 179:158–164, 2024
work page 2024
-
[32]
Soumi Maiti, Yifan Peng, Shukjae Choi, Jee-weon Jung, Xuankai Chang, and Shinji Watanabe. V oxtlm: Unified decoder-only models for consolidating speech recognition, synthesis and speech, text continuation tasks. In ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 13326–13330. IEEE, 2024
work page 2024
-
[33]
Mm1: Methods, analysis & insights from multimodal llm pre-training, 2024
Brandon McKinzie, Zhe Gan, Jean-Philippe Fauconnier Biard, Sam Dodge, Philipp Dufter, Bowen Zhang, Dhruti Shah, Xianzhi Du, Futang Peng, Haotian Zhang, Floris Weers, Anton Belyi, Karanjeet Singh, Doug Kang, Ankur Jain, Hongyu He, Max Schwarzer, Tom Gunter, Xiang Kong, Aonan Zhang, Jianyu Wang, Chong Wang, Nan Du, Tao Lei, Sam Wiseman, Mark Lee, Zirui Wang...
work page 2024
-
[34]
Matcha-tts: A fast tts architecture with conditional flow matching
Shivam Mehta, Ruibo Tu, Jonas Beskow, Éva Székely, and Gustav Eje Henter. Matcha-tts: A fast tts architecture with conditional flow matching. In ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 11341–11345. IEEE, 2024
work page 2024
-
[35]
Meta-stylespeech: Multi- speaker adaptive text-to-speech generation
Dongchan Min, Dong Bok Lee, Eunho Yang, and Sung Ju Hwang. Meta-stylespeech: Multi- speaker adaptive text-to-speech generation. In International Conference on Machine Learning, pages 7748–7759. PMLR, 2021
work page 2021
-
[36]
Svts: scalable video-to-speech synthesis
Rodrigo Mira, Alexandros Haliassos, Stavros Petridis, Björn W Schuller, and Maja Pantic. Svts: scalable video-to-speech synthesis. arXiv preprint arXiv:2205.02058, 2022
-
[37]
End-to-end video-to-speech synthesis using generative adversarial networks
Rodrigo Mira, Konstantinos V ougioukas, Pingchuan Ma, Stavros Petridis, Björn W Schuller, and Maja Pantic. End-to-end video-to-speech synthesis using generative adversarial networks. IEEE transactions on cybernetics, 53(6):3454–3466, 2022
work page 2022
-
[38]
Grad- tts: A diffusion probabilistic model for text-to-speech
Vadim Popov, Ivan V ovk, Vladimir Gogoryan, Tasnima Sadekova, and Mikhail Kudinov. Grad- tts: A diffusion probabilistic model for text-to-speech. In International Conference on Machine Learning, pages 8599–8608. PMLR, 2021
work page 2021
-
[39]
Learning individual speaking styles for accurate lip to speech synthesis
KR Prajwal, Rudrabha Mukhopadhyay, Vinay P Namboodiri, and CV Jawahar. Learning individual speaking styles for accurate lip to speech synthesis. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 13796–13805, 2020
work page 2020
-
[40]
Robust speech recognition via large-scale weak supervision
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision. In International conference on machine learning, pages 28492–28518. PMLR, 2023
work page 2023
-
[41]
Fastspeech: Fast, robust and controllable text to speech
Yi Ren, Yangjun Ruan, Xu Tan, Tao Qin, Sheng Zhao, Zhou Zhao, and Tie-Yan Liu. Fastspeech: Fast, robust and controllable text to speech. Advances in neural information processing systems, 32, 2019
work page 2019
-
[42]
MMAU: A Massive Multi-Task Audio Understanding and Reasoning Benchmark
S Sakshi, Utkarsh Tyagi, Sonal Kumar, Ashish Seth, Ramaneswaran Selvakumar, Oriol Nieto, Ramani Duraiswami, Sreyan Ghosh, and Dinesh Manocha. Mmau: A massive multi-task audio understanding and reasoning benchmark. arXiv preprint arXiv:2410.19168, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
Natural tts synthesis by conditioning wavenet on mel spectrogram predictions
Jonathan Shen, Ruoming Pang, Ron J Weiss, Mike Schuster, Navdeep Jaitly, Zongheng Yang, Zhifeng Chen, Yu Zhang, Yuxuan Wang, Rj Skerrv-Ryan, et al. Natural tts synthesis by conditioning wavenet on mel spectrogram predictions. In 2018 IEEE international conference on acoustics, speech and signal processing (ICASSP), pages 4779–4783. IEEE, 2018
work page 2018
-
[44]
Learning lip-based audio-visual speaker embeddings with av-hubert
Bowen Shi, Abdelrahman Mohamed, and Wei-Ning Hsu. Learning lip-based audio-visual speaker embeddings with av-hubert. arXiv preprint arXiv:2205.07180, 2022. 12
-
[45]
Roformer: Enhanced transformer with rotary position embedding
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding. Neurocomputing, 568:127063, 2024
work page 2024
-
[46]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv preprint arXiv:2403.05530, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timo- thée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[48]
Towards Accurate Generative Models of Video: A New Metric & Challenges
Thomas Unterthiner, Sjoerd Van Steenkiste, Karol Kurach, Raphael Marinier, Marcin Michalski, and Sylvain Gelly. Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:1812.01717, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[49]
Deep neural networks for small footprint text-dependent speaker verification
Ehsan Variani, Xin Lei, Erik McDermott, Ignacio Lopez Moreno, and Javier Gonzalez- Dominguez. Deep neural networks for small footprint text-dependent speaker verification. In 2014 IEEE international conference on acoustics, speech and signal processing (ICASSP), pages 4052–4056. IEEE, 2014
work page 2014
-
[50]
Residual- guided personalized speech synthesis based on face image
Jianrong Wang, Zixuan Wang, Xiaosheng Hu, Xuewei Li, Qiang Fang, and Li Liu. Residual- guided personalized speech synthesis based on face image. In ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 4743–
work page 2022
-
[51]
VioLA: Unified codec language models for speech recognition, synthesis, and translation
Tianrui Wang, Long Zhou, Ziqiang Zhang, Yu Wu, Shujie Liu, Yashesh Gaur, Zhuo Chen, Jinyu Li, and Furu Wei. Viola: Unified codec language models for speech recognition, synthesis, and translation. arXiv preprint arXiv:2305.16107, 2023
-
[52]
Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, et al. Qwen2. 5-omni technical report. arXiv preprint arXiv:2503.20215, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
Ryuichi Yamamoto, Eunwoo Song, and Jae-Min Kim. Parallel wavegan: A fast waveform gen- eration model based on generative adversarial networks with multi-resolution spectrogram. In ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 6199–6203. IEEE, 2020
work page 2020
-
[54]
VideoGPT: Video Generation using VQ-VAE and Transformers
Wilson Yan, Yunzhi Zhang, Pieter Abbeel, and Aravind Srinivas. Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:2104.10157, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[55]
Lipvoicer: Generating speech from silent videos guided by lip reading
Yochai Yemini, Aviv Shamsian, Lior Bracha, Sharon Gannot, and Ethan Fetaya. Lipvoicer: Generating speech from silent videos guided by lip reading. In The Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[56]
Steve Young, Gunnar Evermann, Mark Gales, Thomas Hain, Dan Kershaw, Xunying Liu, Gareth Moore, Julian Odell, Dave Ollason, Dan Povey, et al. The htk book. Cambridge university engineering department, 3(175):12, 2002
work page 2002
-
[57]
Scaling autoregressive models for content-rich text-to-image generation, 2022
Jiahui Yu, Yuanzhong Xu, Jing Yu Koh, Thang Luong, Gunjan Baid, Zirui Wang, Vijay Vasudevan, Alexander Ku, Yinfei Yang, Burcu Karagol Ayan, Ben Hutchinson, Wei Han, Zarana Parekh, Xin Li, Han Zhang, Jason Baldridge, and Yonghui Wu. Scaling autoregressive models for content-rich text-to-image generation, 2022
work page 2022
-
[58]
Statistical parametric speech synthesis
Heiga Zen, Keiichi Tokuda, and Alan W Black. Statistical parametric speech synthesis. speech communication, 51(11):1039–1064, 2009
work page 2009
-
[59]
From speaker to dubber: movie dubbing with prosody and duration consistency learning
Zhedong Zhang, Liang Li, Gaoxiang Cong, Haibing Yin, Yuhan Gao, Chenggang Yan, Anton van den Hengel, and Yuankai Qi. From speaker to dubber: movie dubbing with prosody and duration consistency learning. In Proceedings of the 32nd ACM International Conference on Multimedia, pages 7523–7532, 2024. 13 A Ethics Discussion The advancement of speech technologie...
work page 2024
-
[60]
VoxCeleb2 [10] is a large-scale audio-visual dataset primarily designed for speaker recognition task but applicable to various audio-visual processing domains. It consists of over 1M face-cropped YouTube videos from more than 6k distinct identities, resulting in 1.6k hours of speechw/o paired transcription. The dataset is characterized by high variability...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.