TemporalVLM: Video LLMs for Temporal Reasoning in Long Videos
Pith reviewed 2026-05-23 08:04 UTC · model grok-4.3
The pith
TemporalVLM adds a timestamp-aware visual encoder with BiLSTM to let video LLMs reason about time in long videos.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
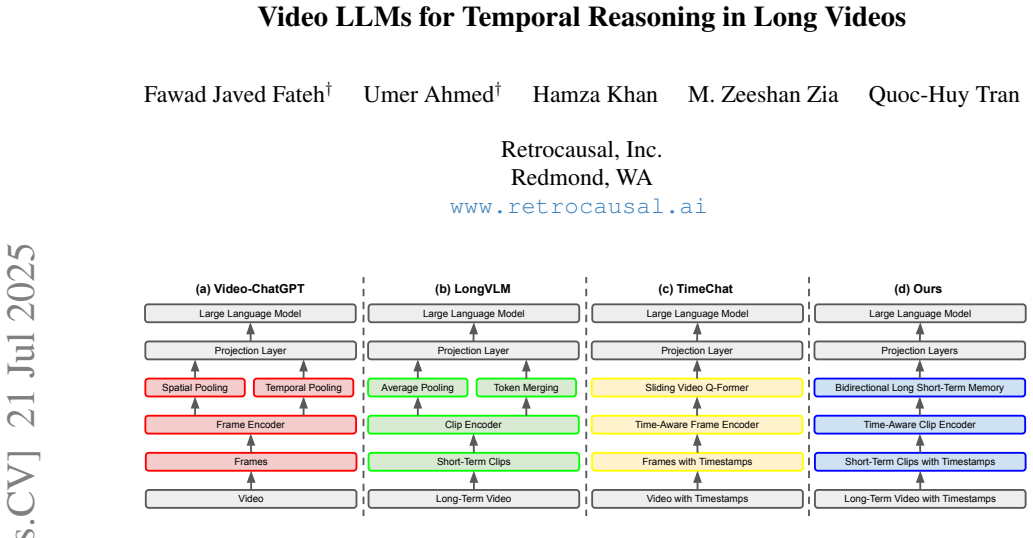
TemporalVLM maps long videos to time-aware features by dividing input into short-term clips jointly encoded with timestamps, fusing across overlapping temporal windows into local features, and passing those through a BiLSTM module for global aggregation, which then supports improved LLM performance on temporal tasks.
What carries the argument
Visual encoder that divides videos into timestamped short-term clips, fuses overlapping windows for local time-sensitive features, and aggregates globally via BiLSTM.
If this is right
- Video LLMs achieve higher accuracy on dense video captioning, temporal video grounding, video highlight detection, and temporal action segmentation.
- The IndustryASM dataset supplies long factory videos with precise action timestamps for training and benchmarking temporal segmentation.
- Combining local timestamp fusion with BiLSTM aggregation supplies both short-range and long-range time cues to the language model.
Where Pith is reading between the lines
- The same clip-plus-timestamp fusion pattern could be tested in other sequential modalities such as audio or sensor streams.
- If the encoder's gains hold on non-assembly videos, it would suggest the method is not limited to industrial domains.
- Replacing BiLSTM with a lighter recurrent unit or attention block while keeping the timestamp fusion could be checked for efficiency trade-offs.
Load-bearing premise
The BiLSTM step on the timestamp-fused local features will create global representations that measurably help the LLM on temporal reasoning tasks.
What would settle it
Ablation experiments on the four listed tasks showing no performance difference when the BiLSTM or the timestamp-overlap fusion is removed.
Figures









read the original abstract
We introduce TemporalVLM, a video large language model (video LLM) for temporal reasoning and fine-grained understanding in long videos. Our approach includes a visual encoder for mapping a long-term video into features which are time-aware and contain both local and global cues. It first divides an input video into short-term clips, which are jointly encoded with timestamps and fused across overlapping temporal windows into time-sensitive local features. Next, the local features are passed through a bidirectional long short-term memory (BiLSTM) module for global feature aggregation. Moreover, to facilitate the evaluation of TemporalVLM, we present a large-scale long video dataset of industry assembly processes, namely IndustryASM, consisting of videos recorded on factory floors with actions and timestamps annotated by industrial engineers for time and motion studies and temporal action segmentation evaluation. Finally, extensive experiments show that TemporalVLM outperforms previous methods across temporal reasoning and fine-grained understanding tasks, i.e., dense video captioning, temporal video grounding, video highlight detection, and temporal action segmentation. To our best knowledge, our work is the first to incorporate LSTMs into video LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TemporalVLM, a video LLM for temporal reasoning and fine-grained understanding in long videos. Its visual encoder divides input videos into short-term clips that are jointly encoded with timestamps, fused across overlapping temporal windows to produce time-sensitive local features, and then aggregated via a BiLSTM for global cues. The work also presents the IndustryASM dataset of factory-floor assembly videos with engineer-annotated actions and timestamps. The central claim is that TemporalVLM outperforms prior methods on dense video captioning, temporal video grounding, video highlight detection, and temporal action segmentation, and that the work is the first to incorporate LSTMs into video LLMs.
Significance. If the reported outperformance is substantiated with proper baselines, ablations, and statistical tests, the architecture could offer a practical route to injecting explicit temporal modeling into video LLMs via recurrent aggregation of local time-aware features. The IndustryASM dataset would additionally supply a new, domain-specific benchmark for long-video temporal action segmentation in industrial settings.
major comments (1)
- Abstract: the claim that TemporalVLM 'outperforms previous methods across' the four listed tasks is asserted without any quantitative results, baselines, error bars, dataset statistics, or even a reference to the experimental section, so the central empirical claim cannot be evaluated from the supplied text.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for better support of the central empirical claim in the abstract. We agree this is a substantive issue and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: Abstract: the claim that TemporalVLM 'outperforms previous methods across' the four listed tasks is asserted without any quantitative results, baselines, error bars, dataset statistics, or even a reference to the experimental section, so the central empirical claim cannot be evaluated from the supplied text.
Authors: We agree that the abstract's assertion of outperformance lacks supporting quantitative details or a pointer to the experiments, making the claim difficult to assess from the abstract alone. This is a fair observation. In the revised version, we will update the abstract to include key quantitative highlights (e.g., specific improvements on representative benchmarks) and add an explicit reference to Section 4 (Experiments), where full baselines, ablations, error bars, and dataset statistics are reported. This change will strengthen the abstract without exceeding typical length constraints. revision: yes
Circularity Check
No significant circularity; claims rest on architecture and experiments
full rationale
The paper describes a visual encoder (clip division + timestamp joint encoding + overlapping-window fusion + BiLSTM aggregation) as a compositional design choice that produces time-sensitive features, then reports empirical outperformance on downstream tasks. No equations define any quantity in terms of the target result, no fitted parameter is relabeled as a prediction, and no load-bearing premise reduces to a self-citation chain. The 'first to incorporate LSTMs' statement is an external literature claim, not a definitional step. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ah- mad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774 ,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Nadine Behrmann, S Alireza Golestaneh, Zico Kolter, J¨urgen Gall, and Mehdi Noroozi. Unified fully and times- tamp supervised temporal action segmentation via sequence to sequence translation. In European Conference on Com- puter Vision, pages 52–68. Springer, 2022. 1, 3
work page 2022
-
[3]
Revisiting the” video” in video-language understanding
Shyamal Buch, Crist ´obal Eyzaguirre, Adrien Gaidon, Jiajun Wu, Li Fei-Fei, and Juan Carlos Niebles. Revisiting the” video” in video-language understanding. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2917–2927, 2022. 3
work page 2022
-
[4]
Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhang- hao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yong- 13 1s 9s 12s 15s 19s 23s User: Locate and describe the visual content mentioned in the text query “a person runs up some stairs.” within the video, including timestamps. TemporalVLM (Ours): The given query happens in 0.0 - 10.0 seconds. User: Loca...
work page 2023
-
[5]
Instructblip: Towards general- purpose vision-language models with instruction tuning,
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, and Steven Hoi. Instructblip: Towards general- purpose vision-language models with instruction tuning,
-
[6]
Long-term recurrent convolutional net- works for visual recognition and description
Jeffrey Donahue, Lisa Anne Hendricks, Sergio Guadarrama, Marcus Rohrbach, Subhashini Venugopalan, Kate Saenko, and Trevor Darrell. Long-term recurrent convolutional net- works for visual recognition and description. In Proceed- ings of the IEEE conference on computer vision and pattern recognition, pages 2625–2634, 2015. 3
work page 2015
-
[7]
Soda: Story oriented dense video captioning evaluation framework
Soichiro Fujita, Tsutomu Hirao, Hidetaka Kamigaito, Man- abu Okumura, and Masaaki Nagata. Soda: Story oriented dense video captioning evaluation framework. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part VI 16 , pages 517–531. Springer, 2020. 6
work page 2020
-
[8]
multiple people are riding bikes across the field
Jiyang Gao, Chen Sun, Zhenheng Yang, and Ram Nevatia. Tall: Temporal activity localization via language query. In 14 3s 20s 48s 60s 77s 81s User: You are given an egocentric video where a person performs a series of actions. Please watch the video and extract a minimum of 6 and a maximum of 10 significant steps. For each step, determine the starting and e...
work page 2017
-
[9]
Frameexit: Conditional early exiting for effi- cient video recognition
Amir Ghodrati, Babak Ehteshami Bejnordi, and Amirhos- sein Habibian. Frameexit: Conditional early exiting for effi- cient video recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 15608–15618, 2021. 3
work page 2021
-
[10]
Smart frame selection for action recognition
Shreyank N Gowda, Marcus Rohrbach, and Laura Sevilla- Lara. Smart frame selection for action recognition. In Pro- ceedings of the AAAI Conference on Artificial Intelligence , pages 1451–1459, 2021. 3
work page 2021
-
[11]
Temporal alignment networks for long-term video
Tengda Han, Weidi Xie, and Andrew Zisserman. Temporal alignment networks for long-term video. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2906–2916, 2022. 3
work page 2022
-
[12]
Jing Hu, Yiming Yang, Huan Wang, and Eric P. Xing. Lora: Low-rank adaptation of large language models. In Proceed- ings of the 2023 Conference on Neural Information Process- ing Systems (NeurIPS 2023), 2023. 5
work page 2023
-
[13]
Vtimellm: Empower llm to grasp video moments
Bin Huang, Xin Wang, Hong Chen, Zihan Song, and Wenwu Zhu. Vtimellm: Empower llm to grasp video moments. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 14271–14280, 2024. 2, 3
work page 2024
-
[14]
Lita: Language instructed temporal-localization assistant
De-An Huang, Shijia Liao, Subhashree Radhakrishnan, Hongxu Yin, Pavlo Molchanov, Zhiding Yu, and Jan Kautz. Lita: Language instructed temporal-localization assistant. In European Conference on Computer Vision, pages 202–218. Springer, 2024. 2, 3
work page 2024
-
[15]
Sagar Imambi, Kolla Bhanu Prakash, and GR Kanagachi- dambaresan. Pytorch. Programming with TensorFlow: solu- tion for edge computing applications , pages 87–104, 2021. 5
work page 2021
-
[16]
Peng Jin, Ryuichi Takanobu, Wancai Zhang, Xiaochun Cao, and Li Yuan. Chat-univi: Unified visual representation em- powers large language models with image and video un- derstanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13700– 13710, 2024. 2
work page 2024
-
[17]
Bert: Pre-training of deep bidirectional trans- formers for language understanding
Jacob Devlin Ming-Wei Chang Kenton and Lee Kristina Toutanova. Bert: Pre-training of deep bidirectional trans- formers for language understanding. In Proceedings of naacL-HLT, page 2. Minneapolis, Minnesota, 2019. 2
work page 2019
-
[18]
Movinets: Mobile video networks for efficient video recog- nition
Dan Kondratyuk, Liangzhe Yuan, Yandong Li, Li Zhang, Mingxing Tan, Matthew Brown, and Boqing Gong. Movinets: Mobile video networks for efficient video recog- nition. In Proceedings of the IEEE/CVF conference on com- puter vision and pattern recognition , pages 16020–16030,
-
[19]
Deep Learning. Ian goodfellow. Yoshua Bengio, and Aaron Courville, 2016. 4
work page 2016
-
[20]
Detecting mo- ments and highlights in videos via natural language queries
Jie Lei, Tamara L Berg, and Mohit Bansal. Detecting mo- ments and highlights in videos via natural language queries. Advances in Neural Information Processing Systems , 34: 11846–11858, 2021. 3, 5, 7
work page 2021
-
[21]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In In- ternational conference on machine learning , pages 19730– 19742. PMLR, 2023. 2
work page 2023
-
[22]
VideoChat: Chat-Centric Video Understanding
KunChang Li, Yinan He, Yi Wang, Yizhuo Li, Wenhai Wang, Ping Luo, Yali Wang, Limin Wang, and Yu Qiao. Videochat: Chat-centric video understanding. arXiv preprint arXiv:2305.06355, 2023. 2, 3, 5, 7
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Ms-tcn++: Multi-stage temporal convolu- tional network for action segmentation
Shijie Li, Yazan Abu Farha, Yun Liu, Ming-Ming Cheng, and Juergen Gall. Ms-tcn++: Multi-stage temporal convolu- tional network for action segmentation. IEEE transactions on pattern analysis and machine intelligence , 45(6):6647– 6658, 2020. 1, 3
work page 2020
-
[24]
Video- teller: Enhancing cross-modal generation with fusion and decoupling
Haogeng Liu, Qihang Fan, Tingkai Liu, Linjie Yang, Yunzhe Tao, Huaibo Huang, Ran He, and Hongxia Yang. Video- teller: Enhancing cross-modal generation with fusion and decoupling. arXiv preprint arXiv:2310.04991, 2023. 2 15
-
[25]
Bt-adapter: Video conversation is fea- sible without video instruction tuning
Ruyang Liu, Chen Li, Yixiao Ge, Thomas H Li, Ying Shan, and Ge Li. Bt-adapter: Video conversation is fea- sible without video instruction tuning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13658–13667, 2024. 12
work page 2024
-
[26]
Fact: Frame-action cross- attention temporal modeling for efficient action segmenta- tion
Zijia Lu and Ehsan Elhamifar. Fact: Frame-action cross- attention temporal modeling for efficient action segmenta- tion. In Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition , pages 18175–18185,
-
[27]
Towards generalisable video moment retrieval: Visual-dynamic injection to image-text pre-training
Dezhao Luo, Jiabo Huang, Shaogang Gong, Hailin Jin, and Yang Liu. Towards generalisable video moment retrieval: Visual-dynamic injection to image-text pre-training. In Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 23045–23055, 2023. 2, 3
work page 2023
-
[28]
Valley: Video assistant with large language model enhanced ability.arXiv preprint arXiv:2306.07207,
Ruipu Luo, Ziwang Zhao, Min Yang, Junwei Dong, Da Li, Pengcheng Lu, Tao Wang, Linmei Hu, Minghui Qiu, and Zhongyu Wei. Valley: Video assistant with large language model enhanced ability. arXiv preprint arXiv:2306.07207 ,
-
[29]
Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models
Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fa- had Shahbaz Khan. Video-chatgpt: Towards detailed video understanding via large vision and language models. arXiv preprint arXiv:2306.05424, 2023. 2, 3, 8, 11, 12
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Query-dependent video representa- tion for moment retrieval and highlight detection
WonJun Moon, Sangeek Hyun, SangUk Park, Dongchan Park, and Jae-Pil Heo. Query-dependent video representa- tion for moment retrieval and highlight detection. In Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 23023–23033, 2023. 2, 3, 6, 9, 10
work page 2023
-
[31]
Chatgpt: Generative pre-trained transformer, 2024
OpenAI. Chatgpt: Generative pre-trained transformer, 2024. 2
work page 2024
-
[32]
Training language models to follow instructions with human feedback
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Car- roll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Ad- vances in neural information processing systems, 35:27730– 27744, 2022. 2
work page 2022
-
[33]
Momen- tor: Advancing video large language model with fine-grained temporal reasoning
Long Qian, Juncheng Li, Yu Wu, Yaobo Ye, Hao Fei, Tat- Seng Chua, Yueting Zhuang, and Siliang Tang. Momen- tor: Advancing video large language model with fine-grained temporal reasoning. arXiv preprint arXiv:2402.11435, 2024. 2, 3
-
[34]
Improving language understanding by gener- ative pre-training
Alec Radford. Improving language understanding by gener- ative pre-training. 2018. 2
work page 2018
-
[35]
Exploring the limits of transfer learning with a unified text-to-text transformer
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research, 21(140):1–67, 2020. 2
work page 2020
-
[36]
Timechat: A time-sensitive multimodal large lan- guage model for long video understanding
Shuhuai Ren, Linli Yao, Shicheng Li, Xu Sun, and Lu Hou. Timechat: A time-sensitive multimodal large lan- guage model for long video understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 14313–14323, 2024. 2, 3, 5, 6, 7, 8, 9, 11
work page 2024
-
[37]
Temporal aggregate representations for long-range video understand- ing
Fadime Sener, Dipika Singhania, and Angela Yao. Temporal aggregate representations for long-range video understand- ing. In Computer Vision–ECCV 2020: 16th European Con- ference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XVI 16, pages 154–171. Springer, 2020. 3
work page 2020
-
[38]
An image is worth 16x16 words, what is a video worth? arXiv preprint arXiv:2103.13915, 2021
Gilad Sharir, Asaf Noy, and Lihi Zelnik-Manor. An image is worth 16x16 words, what is a video worth? arXiv preprint arXiv:2103.13915, 2021. 2
-
[39]
Moviechat: From dense token to sparse memory for long video understanding
Enxin Song, Wenhao Chai, Guanhong Wang, Yucheng Zhang, Haoyang Zhou, Feiyang Wu, Haozhe Chi, Xun Guo, Tian Ye, Yanting Zhang, et al. Moviechat: From dense token to sparse memory for long video understanding. In Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18221–18232, 2024. 2
work page 2024
-
[40]
EVA-CLIP: Improved Training Techniques for CLIP at Scale
Quan Sun, Yuxin Fang, Ledell Wu, Xinlong Wang, and Yue Cao. Eva-clip: Improved training techniques for clip at scale. arXiv preprint arXiv:2303.15389, 2023. 3, 5
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
Alpaca: A strong, replicable instruction-following model
Aakarsh Taori, Evan Chen, Sainbayar Sukhbaatar, et al. Alpaca: A strong, replicable instruction-following model. arXiv preprint arXiv:2303.11347, 2023. 2
-
[42]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timoth´ee Lacroix, Baptiste Rozi`ere, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[43]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023. 2, 5
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[44]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017. 4, 8
work page 2017
-
[45]
Cider: Consensus-based image description evalua- tion
Ramakrishna Vedantam, C Lawrence Zitnick, and Devi Parikh. Cider: Consensus-based image description evalua- tion. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4566–4575, 2015. 6
work page 2015
-
[46]
End-to-end dense video captioning with parallel decoding
Teng Wang, Ruimao Zhang, Zhichao Lu, Feng Zheng, Ran Cheng, and Ping Luo. End-to-end dense video captioning with parallel decoding. In Proceedings of the IEEE/CVF international conference on computer vision , pages 6847– 6857, 2021. 1, 3
work page 2021
-
[47]
Self-Instruct: Aligning Language Models with Self-Generated Instructions
Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A Smith, Daniel Khashabi, and Hannaneh Hajishirzi. Self-instruct: Aligning language models with self-generated instructions. arXiv preprint arXiv:2212.10560, 2022. 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[48]
Benchmarking generalization via in-context instructions on 1,600+ language tasks
Yizhong Wang, Swaroop Mishra, Pegah Alipoormolabashi, Yeganeh Kordi, Amirreza Mirzaei, Anjana Arunkumar, Ar- jun Ashok, Arut Selvan Dhanasekaran, Atharva Naik, David Stap, et al. Benchmarking generalization via in-context instructions on 1,600+ language tasks. arXiv preprint arXiv:2204.07705, 2, 2022. 2
-
[49]
Negative sample matters: A renaissance of met- ric learning for temporal grounding
Zhenzhi Wang, Limin Wang, Tao Wu, Tianhao Li, and Gang- shan Wu. Negative sample matters: A renaissance of met- ric learning for temporal grounding. In Proceedings of the AAAI Conference on Artificial Intelligence, pages 2613– 2623, 2022. 3, 6 16
work page 2022
-
[50]
Longvlm: Efficient long video un- derstanding via large language models
Yuetian Weng, Mingfei Han, Haoyu He, Xiaojun Chang, and Bohan Zhuang. Longvlm: Efficient long video un- derstanding via large language models. arXiv preprint arXiv:2404.03384, 2024. 3, 4, 5, 6, 7, 8, 9, 11, 12
-
[51]
Towards long-form video understanding
Chao-Yuan Wu and Philipp Krahenbuhl. Towards long-form video understanding. In Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 1884–1894, 2021. 3
work page 2021
-
[52]
Memvit: Memory-augmented multiscale vision transformer for efficient long-term video recognition
Chao-Yuan Wu, Yanghao Li, Karttikeya Mangalam, Haoqi Fan, Bo Xiong, Jitendra Malik, and Christoph Feichtenhofer. Memvit: Memory-augmented multiscale vision transformer for efficient long-term video recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13587–13597, 2022. 3
work page 2022
-
[53]
Vid2seq: Large-scale pretraining of a vi- sual language model for dense video captioning
Antoine Yang, Arsha Nagrani, Paul Hongsuck Seo, An- toine Miech, Jordi Pont-Tuset, Ivan Laptev, Josef Sivic, and Cordelia Schmid. Vid2seq: Large-scale pretraining of a vi- sual language model for dense video captioning. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10714–10726, 2023. 1, 2, 3, 9, 10
work page 2023
-
[54]
Asformer: Transformer for action segmentation
Fangqiu Yi, Hongyu Wen, and Tingting Jiang. Asformer: Transformer for action segmentation. arXiv preprint, 2021. 1, 3
work page 2021
-
[55]
Merlot reserve: Neural script knowledge through vision and language and sound
Rowan Zellers, Jiasen Lu, Ximing Lu, Youngjae Yu, Yan- peng Zhao, Mohammadreza Salehi, Aditya Kusupati, Jack Hessel, Ali Farhadi, and Yejin Choi. Merlot reserve: Neural script knowledge through vision and language and sound. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 16375–16387, 2022. 5, 11
work page 2022
-
[56]
Ailing Zeng, Muxi Chen, Lei Zhang, and Qiang Xu. Are transformers effective for time series forecasting? In Pro- ceedings of the AAAI conference on artificial intelligence , pages 11121–11128, 2023. 8
work page 2023
-
[57]
Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding
Hang Zhang, Xin Li, and Lidong Bing. Video-llama: An instruction-tuned audio-visual language model for video un- derstanding. arXiv preprint arXiv:2306.02858, 2023. 2, 3, 5, 7, 8, 12
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[58]
Yucheng Zhao, Chong Luo, Chuanxin Tang, Dongdong Chen, Noel Codella, and Zheng-Jun Zha. Streaming video model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages 14602–14612, 2023. 3
work page 2023
-
[59]
Towards automatic learning of procedures from web instructional videos
Luowei Zhou, Chenliang Xu, and Jason Corso. Towards automatic learning of procedures from web instructional videos. In Proceedings of the AAAI Conference on Artificial Intelligence, 2018. 5, 7, 8
work page 2018
-
[60]
End-to-end dense video captioning as sequence generation
Wanrong Zhu, Bo Pang, Ashish V Thapliyal, William Yang Wang, and Radu Soricut. End-to-end dense video captioning as sequence generation. arXiv preprint arXiv:2204.08121 ,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.