Ister: Linear Transformer for Efficient Multivariate Time Series Forecasting
Pith reviewed 2026-05-23 07:25 UTC · model grok-4.3
The pith
Ister replaces quadratic self-attention with linear element-wise dot products and inverted seasonal-trend decomposition for multivariate time series forecasting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
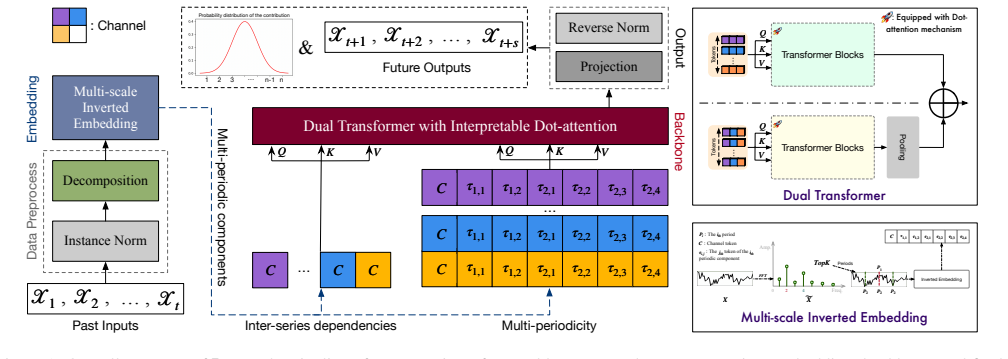
Ister achieves state-of-the-art performance on real-world multivariate time series forecasting benchmarks by using Dot-attention, a linear-complexity mechanism that replaces multi-head self-attention with element-wise dot-product operations to model inter-series dependencies, together with an inverted seasonal-trend decomposition strategy that isolates periodic components to improve channel alignment and predictive accuracy.
What carries the argument
Dot-attention, a linear-complexity attention mechanism that replaces conventional multi-head self-attention with element-wise dot-product operations to model inter-series dependencies.
If this is right
- Forecasting models can handle higher-dimensional series without quadratic compute growth.
- Isolating periodic components allows the model to focus capacity on repeating patterns rather than mixing trend and seasonal signals.
- The architecture supports longer input sequences in practical MTSF tasks while keeping memory and runtime linear in sequence length.
- Channel alignment improves because decomposition precedes the attention step.
Where Pith is reading between the lines
- The same dot-product replacement might apply to other sequence tasks where full pairwise attention is the main bottleneck rather than the core modeling need.
- If the mechanism works, it raises the question of whether explicit inter-series modeling requires matrix multiplications at all or whether simpler operations can be tuned further.
- Synthetic datasets with controlled cross-series correlations could isolate whether Dot-attention truly recovers the necessary dependencies or merely approximates them.
- The inverted decomposition might interact with other preprocessing choices such as normalization or patching, suggesting follow-up ablations on those combinations.
Load-bearing premise
Element-wise dot-product operations suffice to capture the inter-series dependencies needed for accurate forecasting.
What would settle it
A head-to-head evaluation on the same real-world benchmarks where Ister produces higher MSE or MAE than a standard quadratic transformer or existing linear baselines would falsify the central performance claim.
Figures







read the original abstract
Transformer-based models have achieved remarkable success in multivariate time series forecasting (MTSF) by capturing long-range dependencies. However, their widespread adoption is hindered by the quadratic computational complexity of self-attention, which limits scalability on high-dimensional sequences. To address this challenge, we propose the Inverted Seasonal-Trend Decomposition Transformer (Ister), a novel architecture that enhances both predictive accuracy and computational efficiency. Central to Ister is Dot-attention, a linear-complexity attention mechanism that replaces conventional multi-head self-attention with element-wise dot-product operations to model inter-series dependencies. Furthermore, we introduce an inverted seasonal-trend decomposition strategy that isolates periodic components, enabling the model to focus learning on periodic patterns, thereby improving the performance of channel alignment. Extensive experiments across several real-world benchmarks demonstrate that Ister consistently achieves state-of-the-art performance. Code is available at https://github.com/macovaseas/Ister.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Inverted Seasonal-Trend Decomposition Transformer (Ister) for multivariate time series forecasting. It introduces Dot-attention, which replaces multi-head self-attention with element-wise dot-product operations to achieve linear complexity while modeling inter-series dependencies, along with an inverted seasonal-trend decomposition to isolate periodic components. The paper claims that these innovations lead to state-of-the-art performance on several real-world benchmarks, with code made available.
Significance. If the central claims hold, Ister would represent a significant advance in efficient transformer architectures for MTSF by providing a linear-complexity attention mechanism that maintains or improves accuracy. The public code release supports reproducibility and further research.
major comments (2)
- [Dot-attention mechanism (as described)] The assertion that element-wise dot-product operations can model inter-series dependencies is load-bearing for the efficiency and performance claims, but lacks a supporting derivation or analysis showing how this fixed operation provides the necessary non-linear mixing across series that standard attention achieves via learned projections and softmax (see abstract).
- [Experimental validation] The claim of consistent SOTA performance is central, but the provided abstract does not include details on the experimental setup, baselines, or ablations demonstrating the contribution of Dot-attention, making it difficult to assess if the performance gains are due to the proposed mechanism.
minor comments (1)
- The abstract could benefit from a brief mention of the specific benchmarks used to support the SOTA claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point-by-point below. Both concerns can be resolved by expanding the manuscript with additional analysis and minor abstract revisions.
read point-by-point responses
-
Referee: [Dot-attention mechanism (as described)] The assertion that element-wise dot-product operations can model inter-series dependencies is load-bearing for the efficiency and performance claims, but lacks a supporting derivation or analysis showing how this fixed operation provides the necessary non-linear mixing across series that standard attention achieves via learned projections and softmax (see abstract).
Authors: We agree the abstract description is concise and would benefit from elaboration. The full manuscript (Section 3.2) defines Dot-attention as an element-wise dot-product applied to linearly projected series representations, achieving linear complexity while capturing pairwise inter-series interactions. Non-linearity is introduced via subsequent position-wise feed-forward networks. To strengthen the paper, we will add a dedicated paragraph with a brief derivation showing that the operation, when combined with learned projections and MLPs, provides sufficient mixing for inter-series dependencies without requiring quadratic softmax attention. This addition will directly address the request for supporting analysis. revision: yes
-
Referee: [Experimental validation] The claim of consistent SOTA performance is central, but the provided abstract does not include details on the experimental setup, baselines, or ablations demonstrating the contribution of Dot-attention, making it difficult to assess if the performance gains are due to the proposed mechanism.
Authors: The full manuscript provides the requested details in Sections 4 and 5, including experimental setup on standard MTSF benchmarks (ETTh1/2, ETTm1/2, Electricity, Traffic, Weather), comparisons against baselines such as iTransformer, PatchTST, and Autoformer, and ablations isolating Dot-attention and inverted decomposition. However, we acknowledge the abstract is too high-level. We will revise the abstract to briefly reference the experimental validation and the role of ablations in confirming the contribution of each component. revision: yes
Circularity Check
No significant circularity; architectural claims rest on empirical validation
full rationale
The paper proposes Ister with Dot-attention (element-wise dot-product) and inverted seasonal-trend decomposition as design choices, then reports SOTA results on benchmarks. No equations or steps reduce predictions to fitted inputs by construction, no self-citation chains justify uniqueness, and no ansatz is smuggled via prior work. The derivation is self-contained as a standard empirical architecture paper.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Dot-attention
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
Dot-attention ... replaces the matrix multiplication in self-attention with element-wise multiplication ... Dot.(Q, K, V) = (∑ Softmax(Qi) ⊙ Ki )^T 1^T_L ⊙ V
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Lemma 1 ... continuous multivariate function f that ... is permutation-invariant ... approximated using Dot-attention
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
E. O. Brigham and R. E. Morrow. The fast fourier transform. IEEE Spectrum , 4(12):63--70, 1967
work page 1967
-
[2]
Long-term forecasting with ti DE : Time-series dense encoder
Abhimanyu Das, Weihao Kong, Andrew Leach, Shaan K Mathur, Rajat Sen, and Rose Yu. Long-term forecasting with ti DE : Time-series dense encoder. Transactions on Machine Learning Research , 2023
work page 2023
-
[3]
Stephen Grossberg. Recurrent neural networks. Scholarpedia , 8(2):1888, 2013
work page 2013
-
[4]
Pradeep Hewage, Ardhendu Behera, Marcello Trovati, Ella Pereira, Morteza Ghahremani, Francesco Palmieri, and Yonghuai Liu. Temporal convolutional neural (tcn) network for an effective weather forecasting using time-series data from the local weather station. Soft Computing , 24:16453--16482, 2020
work page 2020
-
[5]
Sepp Hochreiter and J \"u rgen Schmidhuber. Long short-term memory. Neural computation , 9(8):1735--1780, 1997
work page 1997
-
[6]
Reversible instance normalization for accurate time-series forecasting against distribution shift
Taesung Kim, Jinhee Kim, Yunwon Tae, Cheonbok Park, Jang-Ho Choi, and Jaegul Choo. Reversible instance normalization for accurate time-series forecasting against distribution shift. In International Conference on Learning Representations , 2021
work page 2021
-
[7]
Adam: A method for stochastic optimization
Diederik Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In International Conference on Learning Representations (ICLR) , San Diega, CA, USA, 2015
work page 2015
-
[8]
Reformer: The efficient transformer
Nikita Kitaev, Lukasz Kaiser, and Anselm Levskaya. Reformer: The efficient transformer. In International Conference on Learning Representations , 2020
work page 2020
-
[9]
Scinet: Time series modeling and forecasting with sample convolution and interaction
Minhao Liu, Ailing Zeng, Muxi Chen, Zhijian Xu, Qiuxia Lai, Lingna Ma, and Qiang Xu. Scinet: Time series modeling and forecasting with sample convolution and interaction. Advances in Neural Information Processing Systems , 35:5816--5828, 2022
work page 2022
-
[10]
Non-stationary transformers: Exploring the stationarity in time series forecasting
Yong Liu, Haixu Wu, Jianmin Wang, and Mingsheng Long. Non-stationary transformers: Exploring the stationarity in time series forecasting. Advances in Neural Information Processing Systems , 35:9881--9893, 2022
work page 2022
-
[11]
itransformer: Inverted transformers are effective for time series forecasting
Yong Liu, Tengge Hu, Haoran Zhang, Haixu Wu, Shiyu Wang, Lintao Ma, and Mingsheng Long. itransformer: Inverted transformers are effective for time series forecasting. In The Twelfth International Conference on Learning Representations , 2024
work page 2024
-
[12]
A time series is worth 64 words: Long-term forecasting with transformers
Yuqi Nie, Nam H Nguyen, Phanwadee Sinthong, and Jayant Kalagnanam. A time series is worth 64 words: Long-term forecasting with transformers. In The Eleventh International Conference on Learning Representations , 2023
work page 2023
-
[13]
Pytorch: An imperative style, high-performance deep learning library
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library. Advances in neural information processing systems , 32, 2019
work page 2019
-
[14]
Robert H Shumway, David S Stoffer, Robert H Shumway, and David S Stoffer. Arima models. Time series analysis and its applications: with R examples , pages 75--163, 2017
work page 2017
-
[15]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, ukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems , 30, 2017
work page 2017
-
[16]
Timexer: Empowering transformers for time series fore- casting with exogenous variables,
Yuxuan Wang, Haixu Wu, Jiaxiang Dong, Guo Qin, Haoran Zhang, Yong Liu, Yunzhong Qiu, Jianmin Wang, and Mingsheng Long. Timexer: Empowering transformers for time series forecasting with exogenous variables. arXiv preprint arXiv:2402.19072 , 2024
-
[17]
Transformers in time series: A survey
Qingsong Wen, Tian Zhou, Chaoli Zhang, Weiqi Chen, Ziqing Ma, Junchi Yan, and Liang Sun. Transformers in time series: A survey. In Edith Elkind, editor, Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence, IJCAI-23 , pages 6778--6786, 8 2023. Survey Track
work page 2023
-
[18]
Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting
Haixu Wu, Jiehui Xu, Jianmin Wang, and Mingsheng Long. Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting. Advances in neural information processing systems , 34:22419--22430, 2021
work page 2021
-
[19]
Timesnet: Temporal 2d-variation modeling for general time series analysis
Haixu Wu, Tengge Hu, Yong Liu, Hang Zhou, Jianmin Wang, and Mingsheng Long. Timesnet: Temporal 2d-variation modeling for general time series analysis. In The eleventh international conference on learning representations , 2022
work page 2022
- [20]
-
[21]
Ailing Zeng, Muxi Chen, Lei Zhang, and Qiang Xu. Are transformers effective for time series forecasting? In Proceedings of the AAAI conference on artificial intelligence , volume 37, pages 11121--11128, 2023
work page 2023
-
[22]
Yunhao Zhang and Junchi Yan. Crossformer: Transformer utilizing cross-dimension dependency for multivariate time series forecasting. In The eleventh international conference on learning representations , 2022
work page 2022
-
[23]
Informer: Beyond efficient transformer for long sequence time-series forecasting
Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang. Informer: Beyond efficient transformer for long sequence time-series forecasting. In Proceedings of the AAAI conference on artificial intelligence , volume 35, pages 11106--11115, 2021
work page 2021
-
[24]
Fedformer: Frequency enhanced decomposed transformer for long-term series forecasting
Tian Zhou, Ziqing Ma, Qingsong Wen, Xue Wang, Liang Sun, and Rong Jin. Fedformer: Frequency enhanced decomposed transformer for long-term series forecasting. In International conference on machine learning , pages 27268--27286. PMLR, 2022
work page 2022
-
[25]
" write newline "" before.all 'output.state := FUNCTION fin.entry add.period write newline FUNCTION new.block output.state before.all = 'skip after.block 'output.state := if FUNCTION new.sentence output.state after.block = 'skip output.state before.all = 'skip after.sentence 'output.state := if if FUNCTION not #0 #1 if FUNCTION and 'skip pop #0 if FUNCTIO...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.