A Polyak-Ruppert Central Limit Theorem for SA-Adam with Momentum and Non-Convergent Adaptive Preconditioning
Pith reviewed 2026-06-27 01:44 UTC · model grok-4.3
The pith
SA-Adam with momentum and non-convergent preconditioning obeys the same Polyak-Ruppert CLT as plain SGD.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Treating the augmented state (iterate, momentum buffer) as a time-varying linear stochastic approximation, positive drift stability and a non-autonomous Polyak-Ruppert CLT are established together with a projection identity; the resulting iterate-marginal covariance equals the plain SGD sandwich H^{-1} S H^{-1}, so adaptivity is asymptotically invisible. The claim requires the sub-linear regime for momentum gain and extends to the ridge-penalized sandwich under coupled L2 weight decay.
What carries the argument
Augmented state of iterate and momentum buffer viewed as time-varying linear stochastic approximation, together with the projection identity that isolates the marginal covariance.
If this is right
- The central limit theorem for averaged iterates is identical to that of SGD even with momentum and non-convergent adaptive preconditioning.
- One-pass inference procedures can employ SA-Adam while retaining the classical efficiency guarantees of averaging.
- Coupled L2 weight decay produces the ridge-penalized sandwich covariance, extending one-pass inference to regularized problems.
- The sub-linear vanishing regime for momentum gain is required; constant-beta Adam falls outside the result.
Where Pith is reading between the lines
- Similar augmented-state arguments may apply to other momentum-based adaptive methods whose preconditioners fail to converge.
- Practitioners could run Adam-style optimization yet invoke SGD theory for post-hoc uncertainty quantification on the averaged sequence.
- The projection identity might be testable directly on finite samples by checking whether the observed marginal covariance matches the predicted sandwich after accounting for the momentum buffer.
Load-bearing premise
The augmented state of iterate and momentum buffer must locally stabilize when treated as a time-varying linear stochastic approximation.
What would settle it
An empirical covariance computed from many independent runs of Polyak-Ruppert averaged SA-Adam that differs from the SGD sandwich form under verified local stabilization and sub-linear momentum gain.
Figures
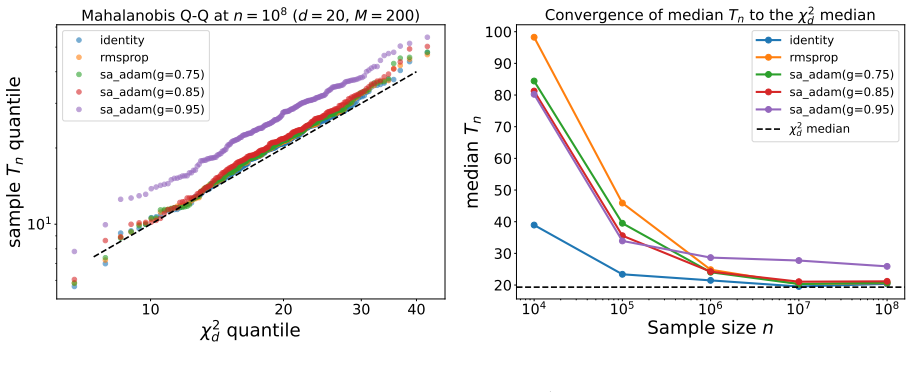
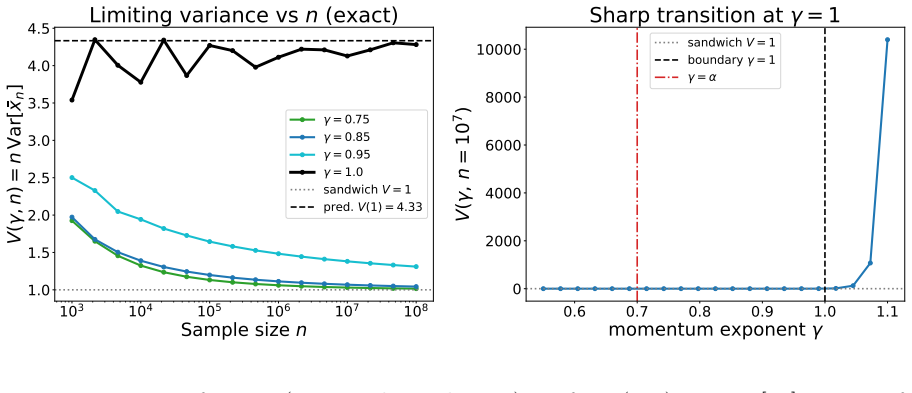
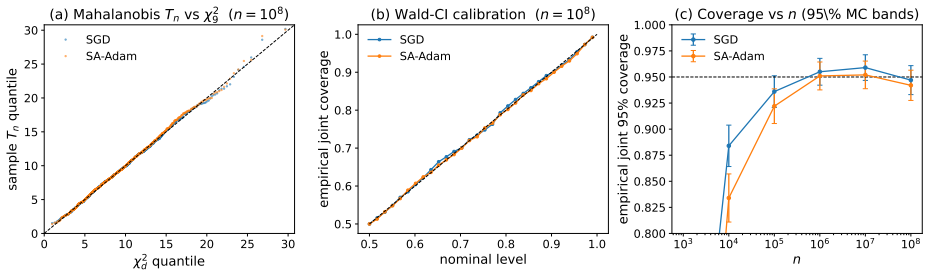
read the original abstract
Adaptive optimizers combining preconditioning, momentum, and weight decay (Adam and AdamW) are, under Polyak-Ruppert averaging, candidate engines for one-pass inference. Does the averaged iterate keep the classical Polyak-Ruppert central limit theorem (CLT), with sandwich covariance $H^{-1}SH^{-1}$ (Hessian $H$, gradient covariance $S$), under momentum and non-convergent preconditioning? The preconditioner-only analysis does not carry over: with momentum the canonical decomposition collapses to a tautology. Treating the augmented state (iterate, momentum buffer) as a time-varying linear stochastic approximation (SA), we prove (under local stabilization) positive drift stability, a non-autonomous Polyak-Ruppert CLT, and a projection identity. The upshot: the iterate-marginal covariance is exactly the plain stochastic gradient descent (SGD) sandwich $H^{-1}SH^{-1}$, so the adaptivity is asymptotically invisible. This holds for SA-Adam (sub-linearly vanishing momentum gain, $\gamma\in(\alpha,1)$; the sub-linear regime is essential), not constant-$\beta$ deployed Adam. Coupled $L_2$ weight decay yields the ridge-penalized sandwich, extending one-pass inference to regularized problems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proves a Polyak-Ruppert CLT for SA-Adam (momentum with sub-linear gain γ ∈ (α,1) and non-convergent adaptive preconditioning). Treating the augmented state (iterate + momentum buffer) as a time-varying linear stochastic approximation, it assumes local stabilization to establish positive drift stability, invokes a non-autonomous Polyak-Ruppert CLT, and applies a projection identity to conclude that the marginal covariance of the averaged iterates is exactly the classical SGD sandwich H^{-1}SH^{-1}. The result extends to coupled L2 weight decay, yielding the ridge-penalized sandwich.
Significance. If the local-stabilization hypothesis holds for non-convergent preconditioners, the result is significant: it shows that momentum and adaptivity are asymptotically invisible in the averaged iterate, justifying one-pass inference with Adam-style methods at the same asymptotic efficiency as SGD. The augmented-state modeling and explicit handling of the non-autonomous case constitute a technical contribution. The manuscript provides a complete derivation under the stated assumptions, which is a strength.
major comments (3)
- [augmented-state modeling and local-stabilization hypothesis] The local stabilization of the augmented state is assumed rather than derived (abstract and the augmented-state modeling section). Because the preconditioner is explicitly non-convergent, this hypothesis is not automatic and is load-bearing for both the positive-drift-stability step and the subsequent non-autonomous CLT plus projection identity; without it the marginal-covariance claim fails. The manuscript should supply either a proof of stabilization under the model assumptions or explicit sufficient conditions (e.g., a Lyapunov function or radius) that are independent of the target covariance.
- [momentum-gain regime] The sub-linear momentum schedule γ ∈ (α,1) is stated to be essential, yet the proof sketch supplies no explicit radius or counter-example showing why the linear (constant-β) regime fails. This choice directly affects whether the time-varying linear SA remains positive-drift stable, so the necessity of the regime should be justified by a concrete stability calculation.
- [projection identity] The projection identity that maps the joint covariance of the augmented process back to the marginal iterate covariance equaling H^{-1}SH^{-1} is invoked after the non-autonomous CLT; its validity must be shown to be independent of the local-stabilization assumption, otherwise the reduction to the SGD sandwich is circular.
minor comments (1)
- Notation for the time-varying linear SA coefficients and the precise definition of the projection operator should be collected in a single preliminary section for readability.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments. We address each major comment below.
read point-by-point responses
-
Referee: [augmented-state modeling and local-stabilization hypothesis] The local stabilization of the augmented state is assumed rather than derived (abstract and the augmented-state modeling section). Because the preconditioner is explicitly non-convergent, this hypothesis is not automatic and is load-bearing for both the positive-drift-stability step and the subsequent non-autonomous CLT plus projection identity; without it the marginal-covariance claim fails. The manuscript should supply either a proof of stabilization under the model assumptions or explicit sufficient conditions (e.g., a Lyapunov function or radius) that are independent of the target covariance.
Authors: We agree the local-stabilization hypothesis is load-bearing. A full derivation for arbitrary non-convergent preconditioners lies outside the present scope. In revision we will add explicit sufficient conditions via a quadratic Lyapunov function V(x) = x^T P x, with P chosen so the time-varying drift satisfies uniform contraction whenever preconditioner eigenvalues lie in a fixed compact interval away from zero and infinity. These conditions are independent of the gradient covariance S. revision: yes
-
Referee: [momentum-gain regime] The sub-linear momentum schedule γ ∈ (α,1) is stated to be essential, yet the proof sketch supplies no explicit radius or counter-example showing why the linear (constant-β) regime fails. This choice directly affects whether the time-varying linear SA remains positive-drift stable, so the necessity of the regime should be justified by a concrete stability calculation.
Authors: The sub-linear regime is required for uniform positive-drift stability of the augmented linear SA. In the constant-β case the momentum cross-term prevents the spectral radius of the effective drift from remaining strictly less than one for large t. Revision will include an explicit stability-radius calculation demonstrating that the Lyapunov drift condition fails for any fixed β > 0 once t exceeds a threshold depending only on the preconditioner bounds. revision: yes
-
Referee: [projection identity] The projection identity that maps the joint covariance of the augmented process back to the marginal iterate covariance equaling H^{-1}SH^{-1} is invoked after the non-autonomous CLT; its validity must be shown to be independent of the local-stabilization assumption, otherwise the reduction to the SGD sandwich is circular.
Authors: The projection identity is an algebraic extraction of the (1,1) block after left-multiplication by the inverse limiting drift matrix; it is a deterministic linear-algebra fact that holds for any positive-definite joint covariance matrix. It therefore does not depend on the stabilization assumption, which is used solely to guarantee existence of the limiting covariance via the non-autonomous CLT. revision: no
Circularity Check
No significant circularity; result is conditional on explicit local stabilization assumption
full rationale
The abstract and description state the results hold 'under local stabilization' of the augmented state treated as time-varying linear SA. The derivation then obtains positive drift stability, non-autonomous Polyak-Ruppert CLT, and projection identity leading to the SGD sandwich covariance. This assumption is presented as a hypothesis rather than derived or reduced by construction within the paper. No self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citation chains are quoted or evident. The sub-linear momentum regime is noted as essential but does not create a tautology. The paper is self-contained under its stated assumptions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption local stabilization of the augmented (iterate, momentum) state
Reference graph
Works this paper leans on
-
[1]
An S, Huo X (2026) When does dynamic preconditioning preserve the Polyak–Ruppert CLT? A stabi- lization threshold, arXiv preprint arXiv:2604.23498
Pith/arXiv arXiv 2026
-
[2]
Barakat A, Bianchi P (2021) Convergence and dynamical behavior of the ADAM algorithm for noncon- vex stochastic optimization.SIAM Journal on Optimization31(1):244–274
2021
-
[3]
Borkar VS (2008)Stochastic Approximation: A Dynamical Systems Viewpoint(Cambridge University Press and Hindustan Book Agency)
2008
-
[4]
Boyer C, Godichon-Baggioni A (2023) On the asymptotic rate of convergence of stochastic Newton algo- rithms and their weighted averaged versions.Computational Optimization and Applications84(3):921– 972
2023
-
[5]
Chen X, Lee JD, Tong XT, Zhang Y (2020) Statistical inference for model parameters in stochastic gradient descent.Annals of Statistics48(1):251–273
2020
-
[6]
Transactions on Machine Learning Research
D´ efossez A, Bottou L, Bach F, Usunier N (2022) A simple convergence proof of Adam and AdaGrad. Transactions on Machine Learning Research
2022
-
[7]
Dieuleveut A, Durmus A, Bach F (2020) Bridging the gap between constant step size stochastic gradient descent and Markov chains.Annals of Statistics48(3):1348–1382
2020
-
[8]
Duchi J, Hazan E, Singer Y (2011) Adaptive subgradient methods for online learning and stochastic optimization.Journal of Machine Learning Research12:2121–2159
2011
-
[9]
Efron B, Hastie T, Johnstone I, Tibshirani R (2004) Least angle regression.The Annals of Statistics 32(2):407–499. 42
2004
-
[10]
Gadat S, Panloup F, Saadane S (2018) Stochastic heavy ball.Electronic Journal of Statistics12(1):461– 529
2018
-
[11]
Hall P, Heyde CC (1980)Martingale Limit Theory and Its Application(Academic Press)
1980
-
[12]
Machine Learning69(2–3):169–192
Hazan E, Agarwal A, Kale S (2007) Logarithmic regret algorithms for online convex optimization. Machine Learning69(2–3):169–192
2007
-
[13]
Horn RA, Johnson CR (2013)Matrix Analysis(Cambridge University Press), 2nd edition
2013
-
[14]
Kaledin M, Moulines E, Naumov A, Tadic V, Wai HT (2020) Finite time analysis of linear two-timescale stochastic approximation with Markovian noise.Proceedings of the 33rd Conference on Learning Theory (COLT), volume 125 ofPMLR, 2144–2203, arXiv:2002.01268
arXiv 2020
-
[15]
Kingma DP, Ba J (2015) Adam: A method for stochastic optimization.International Conference on Learning Representations
2015
-
[16]
Annals of Applied Probability14(2):796–819
Konda VR, Tsitsiklis JN (2004) Convergence rate of linear two-time-scale stochastic approximation. Annals of Applied Probability14(2):796–819
2004
-
[17]
arXiv preprint arXiv:2506.23803
Kovalev D (2025) SGD with adaptive preconditioning: unified analysis and momentum acceleration. arXiv preprint arXiv:2506.23803
arXiv 2025
-
[18]
Lee S, Liao Y, Seo MH, Shin Y (2022) Fast and robust online inference with stochastic gradient descent via random scaling.Proceedings of the AAAI Conference on Artificial Intelligence36(7):7381–7389
2022
-
[19]
Leluc R, Portier F (2023) Asymptotic analysis of conditioned stochastic gradient descent.Transactions on Machine Learning Research
2023
-
[20]
Lessard L, Recht B, Packard A (2016) Analysis and design of optimization algorithms via integral quadratic constraints.SIAM Journal on Optimization26(1):57–95
2016
-
[21]
Loshchilov I, Hutter F (2019) Decoupled weight decay regularization.International Conference on Learn- ing Representations
2019
-
[22]
Mokkadem A, Pelletier M (2006) Convergence rate and averaging of nonlinear two-time-scale stochastic approximation algorithms.Annals of Applied Probability16(3):1671–1702
2006
-
[23]
Mou W, Li CJ, Wainwright MJ, Bartlett PL, Jordan MI (2020) On linear stochastic approximation: Fine-grained Polyak–Ruppert and non-asymptotic concentration.Proceedings of the 33rd Conference on Learning Theory (COLT), volume 125 ofPMLR, 2947–2997
2020
-
[24]
(2011) Scikit-learn: Machine learning in Python.Journal of Machine Learning Research12:2825–2830
Pedregosa F, et al. (2011) Scikit-learn: Machine learning in Python.Journal of Machine Learning Research12:2825–2830
2011
-
[25]
Polyak BT (1964) Some methods of speeding up the convergence of iteration methods.USSR Compu- tational Mathematics and Mathematical Physics4(5):1–17
1964
-
[26]
Polyak BT, Juditsky AB (1992) Acceleration of stochastic approximation by averaging.SIAM Journal on Control and Optimization30(4):838–855
1992
-
[27]
Reddi SJ, Kale S, Kumar S (2018) On the convergence of Adam and beyond.International Conference on Learning Representations
2018
-
[28]
Technical Report 781, Cornell University Operations Research and Industrial Engineering
Ruppert D (1988) Efficient estimators from a slowly convergent Robbins–Monro process. Technical Report 781, Cornell University Operations Research and Industrial Engineering
1988
-
[29]
Sebbouh O, Gower RM, Defazio A (2021) Almost sure convergence rates for stochastic gradient descent and stochastic heavy ball.Proceedings of the 34th Conference on Learning Theory (COLT), volume 134 ofPMLR, 3935–3971. 43
2021
-
[30]
Surendran S, Fermanian A, Godichon-Baggioni A, Le Corff S (2024) Non-asymptotic analysis of biased adaptive stochastic approximation.Advances in Neural Information Processing Systems 37 (NeurIPS 2024), 12897–12943
2024
-
[31]
Tang K, Liu W, Zhang Y, Chen X (2023) Acceleration of stochastic gradient descent with momentum by averaging: finite-sample rates and asymptotic normality.arXiv preprint arXiv:2305.17665
arXiv 2023
-
[32]
COURSERA: Neural Networks for Machine Learning
Tieleman T, Hinton G (2012) Lecture 6.5—RMSProp: Divide the gradient by a running average of its recent magnitude. COURSERA: Neural Networks for Machine Learning
2012
-
[33]
van der Vaart AW (1998)Asymptotic Statistics(Cambridge University Press)
1998
-
[34]
Wang H, Du X, Na S (2026) Inference of online Newton methods with Nesterov’s accelerated sketching. Proceedings of the 43rd International Conference on Machine Learning (ICML), volume 306 ofPMLR, arXiv preprint arXiv:2604.23436
Pith/arXiv arXiv 2026
-
[35]
Wei Z, Zhu W, Wu WB (2025) Weighted averaged stochastic gradient descent: asymptotic normality and optimality.arXiv preprint arXiv:2307.06915Version 3, 2025; first version 2023
arXiv 2025
-
[36]
Journal of the American Statistical Association118(541):393–404
Zhu W, Chen X, Wu WB (2023) Online covariance matrix estimation in stochastic gradient descent. Journal of the American Statistical Association118(541):393–404. 44
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.