Why is prompting hard? Understanding prompts on binary sequence predictors
Pith reviewed 2026-05-23 02:35 UTC · model grok-4.3
The pith
Optimal conditioning sequences for binary sequence predictors are often unintuitive and explained better by the pretraining distribution than by the target task.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
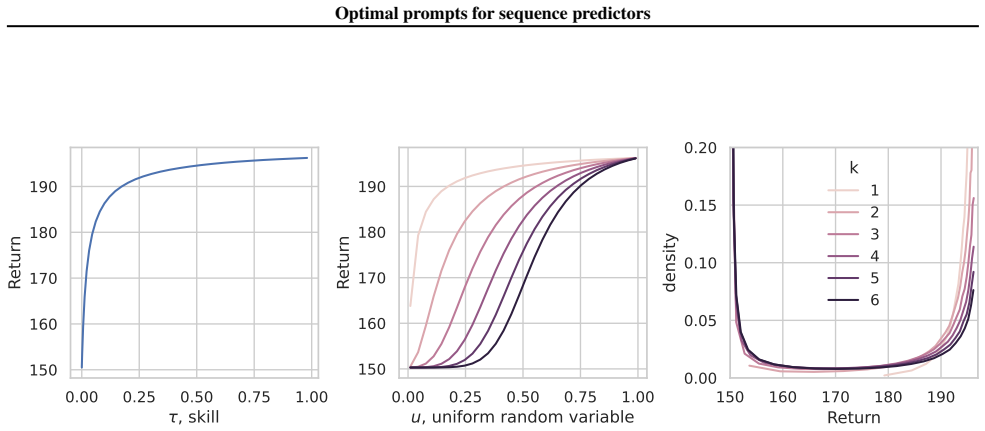
We view prompting as finding the best conditioning sequence on a near-optimal sequence predictor. On numerous well-controlled experiments, we show that unintuitive optimal conditioning sequences can be better understood given the pretraining distribution, which is not usually available. Even using exhaustive search, reliably identifying optimal prompts for practical neural predictors can be surprisingly difficult. Popular prompting methods, such as using demonstrations from the targeted task, can be surprisingly suboptimal. Using the same empirical framework, we analyze optimal prompts on frontier models, revealing patterns similar to the binary examples and previous findings.
What carries the argument
The framing of prompting as search for the best conditioning sequence on a near-optimal sequence predictor, tested via binary sequence predictors with known pretraining distributions.
If this is right
- Popular methods that rely on task demonstrations can remain suboptimal even after exhaustive search over alternatives.
- The pretraining distribution supplies a systematic way to predict which conditioning sequences will perform well.
- Reliable identification of optimal prompts stays difficult for predictors that are only approximately optimal.
- Patterns observed on binary predictors appear again when the same search procedure is run on frontier models.
Where Pith is reading between the lines
- If the pretraining distribution governs optimal conditioning in simple cases, prompt design for large models may benefit from explicit modeling of training-data statistics rather than task-specific heuristics.
- The difficulty of exhaustive search suggests that future prompt-finding algorithms should incorporate distributional priors instead of treating the search as unstructured.
- The binary-predictor setup isolates the effect of conditioning from other model behaviors, offering a test bed for theories of in-context learning that focus on sequence statistics.
Load-bearing premise
Binary sequence predictors trained to near-optimality on fully known distributions behave like the conditioning mechanisms inside practical neural predictors and frontier models.
What would settle it
A binary sequence experiment in which the empirically optimal conditioning sequence is not the one predicted by the pretraining distribution or is consistently beaten by task demonstrations.
Figures


























read the original abstract
Frontier models can be prompted or conditioned to do many tasks, but finding good prompts is not always easy, nor is understanding some performant prompts. We view prompting as finding the best conditioning sequence on a near-optimal sequence predictor. On numerous well-controlled experiments, we show that unintuitive optimal conditioning sequences can be better understood given the pretraining distribution, which is not usually available. Even using exhaustive search, reliably identifying optimal prompts for practical neural predictors can be surprisingly difficult. Popular prompting methods, such as using demonstrations from the targeted task, can be surprisingly suboptimal. Using the same empirical framework, we analyze optimal prompts on frontier models, revealing patterns similar to the binary examples and previous findings. Taken together, this work takes an initial step towards understanding optimal prompts, from a statistical and empirical perspective that complements research on frontier models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that prompting is equivalent to finding the best conditioning sequence on a near-optimal sequence predictor. Through controlled experiments on binary sequence predictors trained to near-optimality on fully known distributions, it shows that optimal conditioning sequences are often unintuitive and explained by the pretraining distribution, that popular methods such as task demonstrations remain suboptimal even under exhaustive search, and that similar patterns hold when the same empirical framework is applied to frontier models.
Significance. If the results hold, the work supplies a useful statistical perspective on prompting that complements frontier-model studies by leveraging fully known distributions and exhaustive enumeration to identify suboptimality. The controlled binary-predictor setting and the reported replication of patterns on frontier models are explicit strengths that allow precise, falsifiable observations about pretraining-distribution effects.
major comments (1)
- [Abstract and introduction framing; § on frontier-model experiments] The central extension from binary predictors to frontier models rests on the assumption that the conditioning dynamics are governed by the same statistical factors. The manuscript invokes this framing in the abstract and introduction but provides no ablation or quantitative comparison (e.g., of context-length scaling or token-dependency effects) between the attention-free binary models and transformer in-context behavior, leaving the representativeness claim load-bearing yet under-supported.
minor comments (1)
- [Methods] Notation for conditioning sequences and pretraining distributions would benefit from an explicit running example early in the methods to improve readability for readers outside the binary-sequence setting.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for recognizing the strengths of the controlled binary-predictor experiments. We respond to the major comment below.
read point-by-point responses
-
Referee: [Abstract and introduction framing; § on frontier-model experiments] The central extension from binary predictors to frontier models rests on the assumption that the conditioning dynamics are governed by the same statistical factors. The manuscript invokes this framing in the abstract and introduction but provides no ablation or quantitative comparison (e.g., of context-length scaling or token-dependency effects) between the attention-free binary models and transformer in-context behavior, leaving the representativeness claim load-bearing yet under-supported.
Authors: We agree that the current framing in the abstract and introduction could more precisely delineate the scope of the frontier-model analysis. The manuscript applies the same empirical procedure (exhaustive or targeted search over conditioning sequences) and reports qualitatively similar patterns, but does not assert that the underlying statistical factors or scaling behaviors are identical across architectures. The binary setting supplies known distributions and exhaustive enumeration; the frontier-model results are presented as an existence check that the observed phenomena are not artifacts of the simplified model class. To address the concern, we will revise the abstract, introduction, and discussion to (i) state explicitly that we observe analogous patterns without claiming mechanistic equivalence, (ii) note the architectural differences (attention-free vs. transformer attention), and (iii) acknowledge the absence of direct ablations on context-length scaling or token dependencies. These changes will clarify that the representativeness claim is limited to the recurrence of the reported qualitative phenomena. revision: yes
Circularity Check
No circularity: results from direct experiments on known distributions
full rationale
The paper frames prompting as conditioning a near-optimal sequence predictor and reports empirical results from training binary predictors on fully specified distributions, identifying optimal sequences via search, and comparing to task demonstrations. These are direct measurements, not derivations. No equations, fitted parameters renamed as predictions, or self-citation chains are invoked to force the central claims. The extension to frontier models is presented as an empirical check showing similar patterns. The work is self-contained against external benchmarks via controlled experiments; the modeling choice of binary predictors does not create a definitional loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Prompting can be viewed as finding the best conditioning sequence on a near-optimal sequence predictor.
Reference graph
Works this paper leans on
-
[1]
Map the binary tokens xt ∈ {0, 1} to embeddings et ∈ Rh through et = Wembxt where Wemb ∈ Rh×2, and h ∈ N+ is the hidden size
-
[2]
Sequentially map h1:T through some neural architecture, called the torso, such as LSTM, multi-head attention, etc, to obtain some hidden activations ut ∈ Rh
-
[3]
For each t, map ut through the fully connected MLP to vt ∈ Rh that is usually found after the attention layer in a transformer block (Vaswani, 2017)
2017
-
[4]
There is also a residual connection from step 2 to 3 and from 3 to 4
For each t, map vt to output logits through a linear map. There is also a residual connection from step 2 to 3 and from 3 to 4. The different neural architectures differ only by the torso. This maintains a flexible enough architecture for different tasks while controlling for the model complexity between different architectures. For the torso, we use the ...
-
[5]
Vanilla recurrent neural networks (Elman, 1990)
1990
-
[6]
Long-short term memory (LSTM) (Hochreiter & Schmidhuber, 1997), reported in main text
1997
-
[7]
sLSTM (Beck et al., 2024)
2024
-
[8]
Softmax-attention transformer (Transformer) (Vaswani, 2017), reported in main text
2017
-
[9]
Linear transformer (Katharopoulos et al., 2020)
2020
-
[10]
landscape
Another variant of Linear transformer we refer to as Inner-product transformer (IP transformer) (Li et al., 2020; Shen et al., 2021) We found that step 3 above is crucial for transformer architectures to perform some of the tasks, although this is not essential for LSTMs to perform well, so we leave this stage in for all model architectures. We did use no...
2020
-
[11]
mismatch
The first bias y1 associated with s1 may not be the first ε appearing in Definition 5.1. In other words, the “phase” of the y is unknown and y1:L. Taking λ = 3 for example, y can start with any of the following: [ε, ε, ε, 1−ε, 1−ε, 1−ε, . . . ] [ε, ε, 1−ε, 1−ε, 1−ε, ε, . . . ] [ε, 1−ε, 1−ε, 1−ε, ε, ε, . . . ] [1−ε, 1−ε, 1−ε, ε, ε, ε, . . . ] [1−ε, 1−ε, ε,...
2021
-
[12]
retrieval
Together with the constantly reward streak from the other arm, creating a posterior of Beta (1 + 7τ, 1), choosing the rewarding arm is more likely if τ is large. Essentially, a large reward gap between the two Beta distributions helps the predictor identify τ. 30 Optimal prompts for sequence predictors Another large reward gap can be induced by other rewa...
1957
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.