Biased Federated Learning under Wireless Heterogeneity
Pith reviewed 2026-05-23 00:20 UTC · model grok-4.3
The pith
Allowing structured time-invariant bias in wireless FL updates reduces variance and improves convergence under heterogeneous path loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
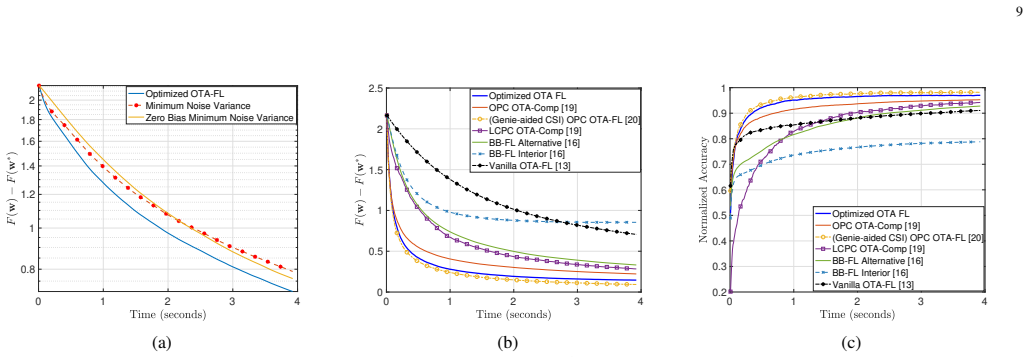
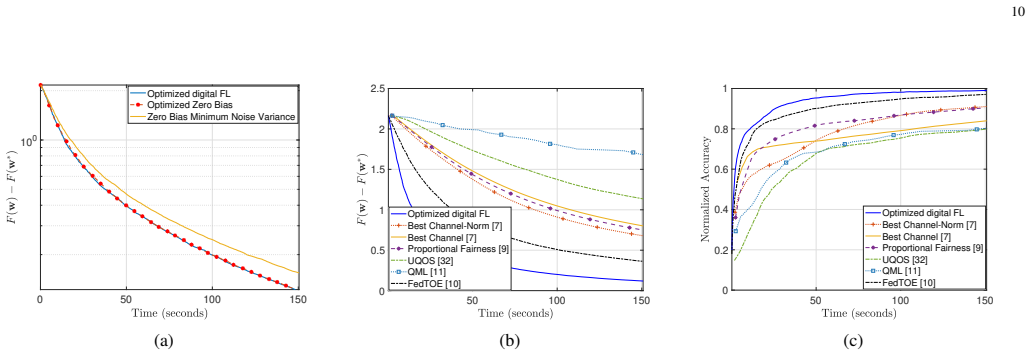
This paper establishes that novel over-the-air and digital federated-learning updates which embed a structured, time-invariant model bias achieve lower variance than zero-bias or uncontrolled-bias baselines when devices experience heterogeneous path loss; a unified convergence analysis supplies an explicit upper bound on optimality error that separates bias and variance contributions, and a successive convex approximation procedure optimizes the design parameters to minimize this bound, yielding faster convergence in heterogeneous wireless settings.
What carries the argument
Structured time-invariant model bias inserted into OTA and digital aggregation steps, which trades a fixed bias term for reduced variance and is jointly optimized inside a unified convergence bound.
If this is right
- The optimality-error bound explicitly separates the effects of bias and variance, allowing designers to tune them independently.
- Both over-the-air computation and orthogonal digital uploads can use the same bias mechanism and optimization framework.
- The SCA procedure yields design parameters that are fixed across time yet still improve convergence under static heterogeneity.
- Performance gains appear in numerical tests against multiple state-of-the-art OTA and digital baselines.
Where Pith is reading between the lines
- The same bias construction could be tested in settings with time-varying channels if the time-invariance assumption is relaxed.
- The bias-variance bound may connect to analogous trade-offs in distributed optimization outside wireless networks.
- If the structured bias can be made device-specific, further variance reduction might be possible without changing the overall framework.
Load-bearing premise
A structured time-invariant model bias can be introduced so that the resulting convergence bound remains valid and comparable to zero-bias and uncontrolled-bias cases under heterogeneous path loss.
What would settle it
A set of experiments on the same heterogeneous channel realizations in which the optimized biased updates fail to reach a target accuracy faster than the best zero-bias and uncontrolled-bias baselines.
Figures
read the original abstract
Federated learning (FL) has emerged as a promising framework for distributed learning, enabling collaborative model training without sharing private data. Existing wireless FL works primarily adopt two communication strategies: (1) over-the-air (OTA) computation, which exploits wireless signal superposition for simultaneous gradient aggregation, and (2) digital communication, which allocates orthogonal resources for gradient uploads. Prior works on both schemes typically assume \emph{homogeneous} wireless conditions (equal path loss across devices) to enforce zero-bias updates or permit uncontrolled bias, resulting in suboptimal performance and high-variance model updates in \emph{heterogeneous} environments, where devices with poor channel conditions slow down convergence. This paper addresses FL over heterogeneous wireless networks by proposing novel OTA and digital FL updates that allow a structured, time-invariant model bias, thereby reducing variance in FL updates. We analyze their convergence under a unified framework and derive an upper bound on the model ``optimality error", which explicitly quantifies the effect of bias and variance in terms of design parameters. Next, to optimize this trade-off, we study a non-convex optimization problem and develop a successive convex approximation (SCA)-based framework to jointly optimize the design parameters. We perform extensive numerical evaluations with several related design variants and state-of-the-art OTA and digital FL schemes. Our results confirm that minimizing the bias-variance trade-off while allowing a structured bias provides better FL convergence performance than existing schemes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes OTA and digital FL schemes that introduce a structured, time-invariant model bias to reduce update variance under wireless heterogeneity. It derives a unified upper bound on optimality error that quantifies the bias-variance trade-off in terms of design parameters, formulates a non-convex optimization problem solved via SCA to jointly tune those parameters, and reports numerical results showing improved convergence over zero-bias and uncontrolled-bias baselines.
Significance. If the bound derivation and comparisons hold, the work supplies a concrete mechanism for managing wireless heterogeneity in FL by trading controlled bias against variance, together with an explicit optimality-error expression and a joint optimization procedure. The unified treatment of OTA and digital schemes is a constructive contribution.
major comments (2)
- [Convergence analysis (unified bound derivation)] Convergence analysis: the unified upper bound on optimality error is stated to permit direct comparison between the proposed biased updates and the zero-bias baseline. The derivation must explicitly confirm that device-specific path-loss terms do not enter the bias component differently when bias is injected via power scaling or resource allocation, otherwise the zero-bias and uncontrolled-bias comparisons rest on inconsistent normalization.
- [SCA optimization and numerical evaluations] Optimization and evaluation: the SCA procedure optimizes bias and variance design parameters under the derived bound; it is unclear whether the resulting parameter values remain feasible when the same heterogeneous path-loss realization is used for both the biased scheme and the zero-bias reference, which is required for the reported performance gain to be attributable to the bias-variance trade-off rather than to altered aggregation rules.
minor comments (2)
- [Numerical evaluations] Numerical results should report error bars or multiple random seeds to substantiate the claimed improvement over baselines.
- [System model] Notation for the bias injection mechanism (power scaling versus resource allocation) should be introduced once and used consistently across the OTA and digital cases.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the convergence bound and the optimization/evaluation procedure. We address each major comment below and will revise the manuscript to improve clarity on the points raised.
read point-by-point responses
-
Referee: Convergence analysis: the unified upper bound on optimality error is stated to permit direct comparison between the proposed biased updates and the zero-bias baseline. The derivation must explicitly confirm that device-specific path-loss terms do not enter the bias component differently when bias is injected via power scaling or resource allocation, otherwise the zero-bias and uncontrolled-bias comparisons rest on inconsistent normalization.
Authors: The unified bound in Theorem 1 (Section IV) defines the bias as a structured, time-invariant term whose expectation is taken independently of instantaneous channel realizations. Path-loss enters the variance term via the power-control and resource-allocation coefficients, while the bias component is normalized by the same long-term channel statistics for all schemes. Consequently, the bias term remains identically defined for the proposed biased updates, the zero-bias baseline, and the uncontrolled-bias case. We will add an explicit remark immediately after the statement of Theorem 1 and a short paragraph in the proof appendix confirming that the normalization is identical across the three cases, thereby ensuring consistent comparisons. revision: yes
-
Referee: Optimization and evaluation: the SCA procedure optimizes bias and variance design parameters under the derived bound; it is unclear whether the resulting parameter values remain feasible when the same heterogeneous path-loss realization is used for both the biased scheme and the zero-bias reference, which is required for the reported performance gain to be attributable to the bias-variance trade-off rather than to altered aggregation rules.
Authors: The SCA formulation (Section V) is solved subject to the feasibility constraints that are functions of the fixed heterogeneous path-loss vector; the same path-loss realization is therefore used for every scheme. The zero-bias reference is obtained simply by setting the bias-design variable to zero inside the same feasible set. All numerical results in Section VI are generated from identical channel realizations across schemes. We will insert a clarifying sentence in the optimization problem statement (Problem P1) and in the caption of the numerical-results figure to make this explicit. revision: yes
Circularity Check
No circularity: derivation applies standard analysis to proposed biased updates without reduction to inputs.
full rationale
The abstract and description outline a proposal for structured bias in OTA/digital FL updates under heterogeneous path loss, followed by a unified convergence bound on optimality error that quantifies bias and variance in terms of design parameters, then SCA optimization of the trade-off. No quoted equations or steps show the bound reducing by construction to a fitted quantity, self-definition of bias via the same parameters, or load-bearing self-citation chains. The central claim of better performance via bias-variance minimization rests on the derived bound and numerical comparisons, which are presented as independent of the input assumptions. This matches the default expectation of self-contained analysis.
Axiom & Free-Parameter Ledger
free parameters (1)
- bias and variance design parameters
axioms (1)
- domain assumption Standard assumptions for FL convergence analysis such as bounded gradients or Lipschitz continuity of the loss
Reference graph
Works this paper leans on
-
[1]
Analog-digital scheduling for fed- erated learning: A communication-efficient approach,
M. F. Ul Abrar and N. Michelusi, “Analog-digital scheduling for fed- erated learning: A communication-efficient approach,” in 57th Asilomar Conference on Signals, Systems, and Computers , 2023, pp. 53–58
work page 2023
-
[2]
Biased over-the-air federated learning under wireless heterogeneity,
M. F. U. Abrar and N. Michelusi, “Biased over-the-air federated learning under wireless heterogeneity,” in IEEE International Conference on Communications Workshops (ICC Workshops), 2024, pp. 111–116
work page 2024
-
[3]
Federated learning in mobile edge networks: A comprehensive survey,
W. Y . B. Lim, N. C. Luong, D. T. Hoang, Y . Jiao, Y .-C. Liang, Q. Yang, D. T. Niyato, and C. Miao, “Federated learning in mobile edge networks: A comprehensive survey,” IEEE Comms. Surveys & Tutorials , vol. 22, pp. 2031–2063, 2019
work page 2031
-
[4]
S. Hu, X. Chen, W. Ni, E. Hossain, and X. Wang, “Distributed machine learning for wireless communication networks: Techniques, architec- tures, and applications,” IEEE Comms. Surveys & Tutorials , vol. 23, no. 3, pp. 1458–1493, 2021
work page 2021
-
[5]
Communication-Efficient Learning of Deep Networks from Decentral- ized Data,
B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y. Arcas, “Communication-Efficient Learning of Deep Networks from Decentral- ized Data,” in Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, vol. 54, 20–22 Apr 2017, pp. 1273– 1282
work page 2017
-
[6]
Federated learning over wireless networks: Optimization model design and analysis,
N. H. Tran, W. Bao, A. Zomaya, M. N. H. Nguyen, and C. S. Hong, “Federated learning over wireless networks: Optimization model design and analysis,” in IEEE INFOCOM, 2019, pp. 1387–1395
work page 2019
-
[7]
Convergence of update aware device scheduling for federated learning at the wireless edge,
M. M. Amiri, D. G ¨und¨uz, S. R. Kulkarni, and H. V . Poor, “Convergence of update aware device scheduling for federated learning at the wireless edge,” IEEE Trans. on Wireless Comms., vol. 20, no. 6, pp. 3643–3658, 2021
work page 2021
-
[8]
W. Shi, S. Zhou, Z. Niu, M. Jiang, and L. Geng, “Joint device scheduling and resource allocation for latency constrained wireless federated learn- ing,” IEEE Trans. on Wireless Comms. , vol. 20, no. 1, pp. 453–467, 2021
work page 2021
-
[9]
Scheduling policies for federated learning in wireless networks,
H. H. Yang, Z. Liu, T. Q. S. Quek, and H. V . Poor, “Scheduling policies for federated learning in wireless networks,” IEEE Trans. on Comms. , vol. 68, no. 1, pp. 317–333, 2020
work page 2020
-
[10]
Quantized federated learning under transmission delay and outage constraints,
Y . Wang, Y . Xu, Q. Shi, and T.-H. Chang, “Quantized federated learning under transmission delay and outage constraints,” IEEE Journal on Selected Areas in Communications , vol. 40, no. 1, pp. 323–341, 2022
work page 2022
-
[11]
Wireless quantized federated learning: A joint computation and communication design,
P. S. Bouzinis, P. D. Diamantoulakis, and G. K. Karagiannidis, “Wireless quantized federated learning: A joint computation and communication design,” IEEE Trans. on Comms. , vol. 71, no. 5, pp. 2756–2770, 2023
work page 2023
-
[12]
Federated learning in unreliable and resource-constrained cellular wireless networks,
M. Salehi and E. Hossain, “Federated learning in unreliable and resource-constrained cellular wireless networks,” IEEE Trans. on Comms., vol. 69, no. 8, pp. 5136–5151, 2021
work page 2021
-
[13]
Federated learning via over- the-air computation,
K. Yang, T. Jiang, Y . Shi, and Z. Ding, “Federated learning via over- the-air computation,” IEEE Trans. on Wireless Comms. , vol. 19, no. 3, pp. 2022–2035, 2020
work page 2022
-
[14]
Federated learning over wireless fading channels,
M. M. Amiri and D. G ¨und¨uz, “Federated learning over wireless fading channels,” IEEE Trans. on Wireless Comms. , vol. 19, no. 5, pp. 3546– 3557, 2020
work page 2020
-
[15]
G. Zhu, Y . Du, D. G ¨und¨uz, and K. Huang, “One-bit over-the-air aggregation for communication-efficient federated edge learning: Design and convergence analysis,” IEEE Trans. on Wireless Comms. , vol. 20, no. 3, pp. 2120–2135, 2021
work page 2021
-
[16]
Broadband analog aggregation for low-latency federated edge learning,
G. Zhu, Y . Wang, and K. Huang, “Broadband analog aggregation for low-latency federated edge learning,” IEEE Trans. on Wireless Comms., vol. 19, no. 1, pp. 491–506, 2020
work page 2020
-
[17]
Non-coherent over-the-air decentralized gradient de- scent,
N. Michelusi, “Non-coherent over-the-air decentralized gradient de- scent,” IEEE Trans. on Signal Processing, vol. 72, pp. 4618–4634, 2024
work page 2024
-
[18]
Over-the-air federated learning from heterogeneous data,
T. Sery, N. Shlezinger, K. Cohen, and Y . C. Eldar, “Over-the-air federated learning from heterogeneous data,” IEEE Trans. on Signal Processing, vol. 69, pp. 3796–3811, 2021
work page 2021
-
[19]
Optimized power control for over-the-air computation in fading channels,
X. Cao, G. Zhu, J. Xu, and K. Huang, “Optimized power control for over-the-air computation in fading channels,” IEEE Transactions on Wireless Communications, vol. 19, no. 11, pp. 7498–7513, 2020
work page 2020
-
[20]
Optimized power control design for over-the-air federated edge learning,
X. Cao, G. Zhu, J. Xu, Z. Wang, and S. Cui, “Optimized power control design for over-the-air federated edge learning,” IEEE Journal on Selected Areas in Communications, vol. 40, no. 1, pp. 342–358, 2022. 12
work page 2022
-
[21]
A joint learning and communications framework for federated learning over wireless networks,
M. Chen, Z. Yang, W. , C. Yin, H. V . Poor, and S. Cui, “A joint learning and communications framework for federated learning over wireless networks,”IEEE Trans. on Wireless Comms., vol. 20, no. 1, pp. 269–283, 2021
work page 2021
-
[22]
Federated learning over wireless iot networks with optimized communication and resources,
H. Chen, S. Huang, D. Zhang, M. Xiao, M. Skoglund, and H. V . Poor, “Federated learning over wireless iot networks with optimized communication and resources,” IEEE Internet of Things Journal , vol. 9, no. 17, pp. 16 592–16 605, 2022
work page 2022
-
[23]
Federated learning: Strategies for improving communication efficiency,
J. Kone ˇcn´y, H. B. McMahan, F. X. Yu, P. Richtarik, A. T. Suresh, and D. Bacon, “Federated learning: Strategies for improving communication efficiency,” inNIPS Workshop on Private Multi-Party Machine Learning, 2016
work page 2016
-
[24]
Qsgd: Communication-efficient sgd via gradient quantization and encoding,
D. Alistarh, D. Grubic, J. Z. Li, R. Tomioka, and M. V ojnovic, “Qsgd: Communication-efficient sgd via gradient quantization and encoding,” in Proceedings of the 31st International Conference on Neural Information Processing Systems, ser. NIPS’17, 2017
work page 2017
-
[25]
Sparse communication for distributed gradient descent,
A. F. Aji and K. Heafield, “Sparse communication for distributed gradient descent,” in Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing , Copenhagen, Denmark, Sep. 2017, pp. 440–445
work page 2017
-
[26]
The convergence of sparsified gradient methods,
D. Alistarh, T. Hoefler, M. Johansson, N. Konstantinov, S. Khirirat, and C. Renggli, “The convergence of sparsified gradient methods,” in Advances in Neural Information Processing Systems , vol. 31, 2018
work page 2018
-
[27]
Optimal client sampling for federated learning,
W. Chen, S. Horv ´ath, and P. Richt ´arik, “Optimal client sampling for federated learning,” Transactions on Machine Learning Research, 2022
work page 2022
-
[28]
Towards understanding biased client selection in federated learning,
Y . Jee Cho, J. Wang, and G. Joshi, “Towards understanding biased client selection in federated learning,” inProceedings of The 25th International Conference on Artificial Intelligence and Statistics , vol. 151. PMLR, 28–30 Mar 2022, pp. 10 351–10 375
work page 2022
-
[29]
H. Yu, S. Yang, and S. Zhu, “Parallel restarted sgd with faster con- vergence and less communication: demystifying why model averaging works for deep learning,” in Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence . AAAI Press, 2019
work page 2019
-
[30]
Local SGD converges fast and communicates little,
S. U. Stich, “Local SGD converges fast and communicates little,” in International Conference on Learning Representations , 2019
work page 2019
-
[31]
Charles: Channel-quality- adaptive over-the-air federated learning over wireless networks,
J. Mao, H. Yang, P. Qiu, J. Liu, and A. Yener, “Charles: Channel-quality- adaptive over-the-air federated learning over wireless networks,” inIEEE 23rd International Workshop on Signal Processing Advances in Wireless Communication (SPAWC), 2022, pp. 1–5
work page 2022
-
[32]
Wireless federated learning over resource-constrained networks: Digital versus analog transmissions,
J. Yao, W. Xu, Z. Yang, X. You, M. Bennis, and H. V . Poor, “Wireless federated learning over resource-constrained networks: Digital versus analog transmissions,” IEEE Trans. on Wireless Comms., vol. 23, no. 10, pp. 14 020–14 036, 2024
work page 2024
-
[33]
Understanding clipping for federated learning: Convergence and client-level differential privacy,
X. Zhang, X. Chen, M. Hong, S. Wu, and J. Yi, “Understanding clipping for federated learning: Convergence and client-level differential privacy,” in Proceedings of the 39th International Conference on Machine Learn- ing, vol. 162. PMLR, 17–23 Jul 2022, pp. 26 048–26 067
work page 2022
-
[34]
On the convergence of fedavg on non-iid data,
X. Li, K. Huang, W. Yang, S. Wang, and Z. Zhang, “On the convergence of fedavg on non-iid data,” in 8th International Conference on Learning Representations, ICLR, Addis Ababa, Ethiopia, April 26-30 , 2020
work page 2020
-
[35]
SGD and hogwild! Convergence without the bounded gradients assumption,
L. Nguyen, P. H. NGUYEN, M. van Dijk, P. Richtarik, K. Scheinberg, and M. Takac, “SGD and hogwild! Convergence without the bounded gradients assumption,” in Proceedings of the 35th International Confer- ence on Machine Learning , vol. 80, 10–15 Jul 2018, pp. 3750–3758
work page 2018
-
[36]
Harnessing interference for analog function computation in wireless sensor networks,
M. Goldenbaum, H. Boche, and S. Sta ´nczak, “Harnessing interference for analog function computation in wireless sensor networks,” IEEE Transactions on Signal Processing, vol. 61, no. 20, pp. 4893–4906, 2013
work page 2013
-
[37]
Federated learning over wireless device-to-device networks: Algorithms and convergence analysis,
H. Xing, O. Simeone, and S. Bi, “Federated learning over wireless device-to-device networks: Algorithms and convergence analysis,” IEEE Journal on Selected Areas in Comms. , vol. 39, no. 12, pp. 3723–3741, 2021
work page 2021
-
[38]
Over- the-air federated learning and optimization,
J. Zhu, Y . Shi, Y . Zhou, C. Jiang, W. Chen, and K. B. Letaief, “Over- the-air federated learning and optimization,” IEEE Internet of Things Journal, vol. 11, no. 10, pp. 16 996–17 020, 2024
work page 2024
-
[39]
Nesterov, Lectures on Convex Optimization , 2nd ed
Y . Nesterov, Lectures on Convex Optimization , 2nd ed. Springer Publishing Company, Incorporated, 2018
work page 2018
-
[40]
Technical note - a general inner approximation algorithm for nonconvex mathematical programs,
B. R. Marks and G. P. Wright, “Technical note - a general inner approximation algorithm for nonconvex mathematical programs,” Oper. Res., vol. 26, pp. 681–683, 1978
work page 1978
-
[41]
Majorization-minimization algo- rithms in signal processing, communications, and machine learning,
Y . Sun, P. Babu, and D. P. Palomar, “Majorization-minimization algo- rithms in signal processing, communications, and machine learning,” IEEE Trans. on Signal Processing , vol. 65, no. 3, pp. 794–816, 2017
work page 2017
-
[42]
G. Scutari and Y . Sun, Parallel and Distributed Successive Convex Approximation Methods for Big-Data Optimization . Cham: Springer International Publishing, 2018, pp. 141–308
work page 2018
-
[43]
CVX: Matlab software for disciplined convex programming, version 2.1,
M. Grant and S. Boyd, “CVX: Matlab software for disciplined convex programming, version 2.1,” https://cvxr.com/cvx, Mar. 2014
work page 2014
-
[44]
MNIST handwritten digit database,
Y . LeCun and C. Cortes, “MNIST handwritten digit database,” 2010. [Online]. Available: http://yann.lecun.com/exdb/mnist/ APPENDIX A: P ROOF OF THEOREM 1 Here, we provide the detailed proof of Theorem 1, which characterizes the model optimality error for the proposed OTA- FL and digital FL schemes. This proof uses auxiliary results presented in Appendix B...
work page 2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.