GuideDog: A Real-World Egocentric Multimodal Dataset for Blind and Low-Vision Accessibility-Aware Guidance
Pith reviewed 2026-05-22 23:48 UTC · model grok-4.3
The pith
A new dataset of real-world scenes shows current multimodal models struggle with depth perception for blind navigation guidance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
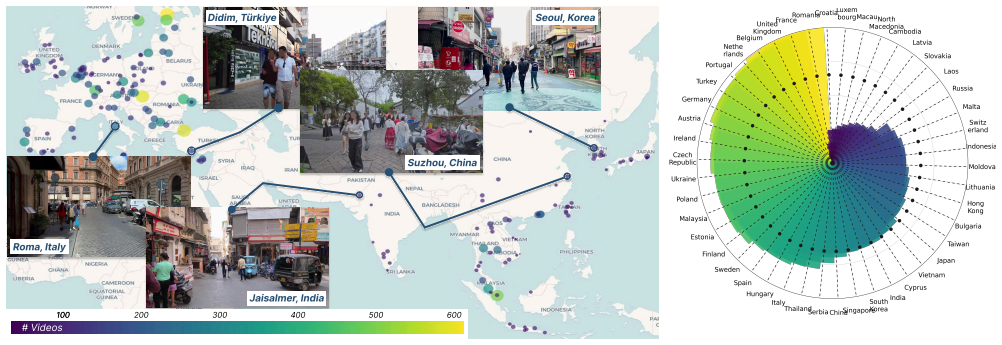
The central claim is that GuideDog supplies a scalable, standards-grounded dataset of 22K image-description pairs plus an 818-sample QA benchmark, and that testing current multimodal large language models on this benchmark reveals persistent difficulties with depth perception and with producing descriptions that adhere to blind and low-vision guidance standards.
What carries the argument
The human-AI annotation pipeline that moves the task from full generation to verification against established blind and low-vision guidance standards.
If this is right
- Models can now be benchmarked on realistic pedestrian scenes for object recognition and depth perception in accessibility contexts.
- The verification-based pipeline reduces the cost of creating further accessibility-aware datasets while preserving standard compliance.
- Persistent model failures on depth perception point to concrete targets for improvement in multimodal systems used for navigation.
- The 2K human-verified subset provides a high-quality seed for training or fine-tuning assistive applications.
Where Pith is reading between the lines
- The same verification approach could extend to other domains where expert standards must be followed at scale, such as medical imaging or legal document review.
- If models improve on this benchmark, real-time mobile apps could translate the descriptions into audio cues that help users avoid obstacles more effectively.
- Dataset creators in related fields might adopt similar hybrid pipelines to incorporate domain standards without full expert labor.
Load-bearing premise
The human-AI pipeline yields descriptions that match the quality and fidelity of full expert annotation when judged against blind and low-vision guidance standards.
What would settle it
Independent expert raters score a random sample of the dataset descriptions for adherence to the guidance standards and find large systematic deviations from expert-level quality.
Figures


















read the original abstract
For people affected by blindness and low vision (BLV), safe and independent navigation remains a major challenge, impacting over 2.2 billion individuals worldwide. Although multimodal large language models (MLLMs) offer new opportunities for assistive navigation, progress has been limited by the scarcity of accessibility-aware datasets, because creating them requires labor-intensive expert annotation. To this end, we introduce GuideDog, a novel dataset containing 22K image-description pairs (2K human-verified) capturing real-world pedestrian scenes across 46 countries. Our human-AI pipeline shifts annotation from generation to verification, grounded in established BLV guidance standards from experts and research, improving scalability while maintaining quality. We also present GuideDogQA, an 818-sample benchmark evaluating object recognition and depth perception. Experiments reveal that depth perception and adherence to these standards remain challenging for current MLLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GuideDog, a dataset of 22K egocentric image-description pairs (2K human-verified) from real-world pedestrian scenes across 46 countries, created via a human-AI annotation pipeline grounded in established BLV guidance standards. It also presents the GuideDogQA benchmark consisting of 818 samples to evaluate MLLMs on object recognition and depth perception, with the central claim that experiments show depth perception and adherence to these standards remain challenging for current MLLMs.
Significance. If the human-AI pipeline produces annotations of quality comparable to full expert annotation and the 818-sample benchmark is constructed rigorously, the dataset would provide a valuable, scalable resource for developing accessibility-aware navigation systems for BLV users, addressing the scarcity of real-world egocentric data in this domain.
major comments (1)
- [Abstract] Abstract: The statement that 'experiments reveal that depth perception and adherence to these standards remain challenging for current MLLMs' is not accompanied by any quantitative results, performance metrics, error analysis, or details on the construction, sampling method, or composition of the 818-sample GuideDogQA benchmark, leaving the central empirical claim only moderately supported.
minor comments (1)
- [Abstract] Abstract: Clarify whether the 2K human-verified pairs are a subset of the 22K or represent an additional verification step applied to the full set.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the abstract. We address the concern point-by-point below and will incorporate changes in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The statement that 'experiments reveal that depth perception and adherence to these standards remain challenging for current MLLMs' is not accompanied by any quantitative results, performance metrics, error analysis, or details on the construction, sampling method, or composition of the 818-sample GuideDogQA benchmark, leaving the central empirical claim only moderately supported.
Authors: We agree that the abstract would be strengthened by including brief quantitative support for the central claim. The full details on GuideDogQA construction (including sampling method and composition), performance metrics, and error analysis appear in Sections 3.3 and 4 of the manuscript. In revision we will add concise quantitative highlights to the abstract (e.g., key accuracy figures on depth-perception and standard-adherence tasks across evaluated MLLMs) while preserving length constraints. This directly addresses the concern without altering the underlying experimental results. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is an empirical dataset release introducing GuideDog (22K image-description pairs via human-AI pipeline grounded in external BLV expert standards) and GuideDogQA benchmark (818 samples). No mathematical derivations, equations, parameter fitting, or predictions exist. Claims about MLLM performance on depth perception and standards adherence are direct empirical observations on the benchmark, not reductions to fitted inputs or self-citations. The annotation process is presented as shifting to verification with 2K human-verified pairs, without self-definitional loops or ansatzes smuggled via citation. The work is self-contained against external benchmarks and standards.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Established BLV guidance standards from experts and research provide a valid and complete basis for annotation.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ah- mad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774 ,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923, 2025. 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
METEOR: An auto- matic metric for MT evaluation with improved correlation with human judgments
Satanjeev Banerjee and Alon Lavie. METEOR: An auto- matic metric for MT evaluation with improved correlation with human judgments. InProceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, pages 65–72, Ann Arbor, Michigan, 2005. Association for Computational Linguistics. 6
work page 2005
-
[4]
Depth Pro: Sharp Monocular Metric Depth in Less Than a Second
Aleksei Bochkovskii, Ama ¨el Delaunoy, Hugo Germain, Marcel Santos, Yichao Zhou, Stephan R Richter, and Vladlen Koltun. Depth pro: Sharp monocular metric depth in less than a second. arXiv preprint arXiv:2410.02073, 2024. 4
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Rupert RA Bourne, Seth R Flaxman, Tasanee Braithwaite, Maria V Cicinelli, Aditi Das, Jost B Jonas, Jill Keeffe, John H Kempen, Janet Leasher, Hans Limburg, et al. Mag- nitude, temporal trends, and projections of the global preva- lence of blindness and distance and near vision impairment: a systematic review and meta-analysis. The Lancet Global Health, 5(...
work page 2017
-
[6]
Emerg- ing properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv ´e J´egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerg- ing properties in self-supervised vision transformers. In Pro- ceedings of the IEEE/CVF international conference on com- puter vision, pages 9650–9660, 2021. 4
work page 2021
-
[7]
Yolo-world: Real-time open-vocabulary object detection
Tianheng Cheng, Lin Song, Yixiao Ge, Wenyu Liu, Xing- gang Wang, and Ying Shan. Yolo-world: Real-time open-vocabulary object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16901–16911, 2024. 4
work page 2024
-
[8]
Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Vision-Language Models
Matt Deitke, Christopher Clark, Sangho Lee, Rohun Tri- pathi, Yue Yang, Jae Sung Park, Mohammadreza Salehi, Niklas Muennighoff, Kyle Lo, Luca Soldaini, et al. Molmo and pixmo: Open weights and open data for state-of-the-art multimodal models. arXiv preprint arXiv:2409.17146, 2024. 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
V-eye: A vision-based navigation system for the visually impaired
Ping-Jung Duh, Yu-Cheng Sung, Liang-Yu Fan Chiang, Yung-Ju Chang, and Kuan-Wen Chen. V-eye: A vision-based navigation system for the visually impaired. IEEE Transac- tions on Multimedia, 23:1567–1580, 2020. 3
work page 2020
-
[10]
How to guide someone who is blind or partially sighted
Emma Turner, Sense. How to guide someone who is blind or partially sighted. https://www.sense.org.uk/ blog/how-to-guide-someone-who-is-blind- or-partially-sighted, 2023. 3
work page 2023
-
[11]
A review of assistive spatial orientation and navigation technologies for the visually impaired
Hugo Fernandes, Paulo Costa, Vitor Filipe, Hugo Paredes, and Jo ˜ao Barroso. A review of assistive spatial orientation and navigation technologies for the visually impaired. Uni- versal Access in the Information Society, 18:155–168, 2019. 3
work page 2019
-
[12]
Introducing gemini 2.0: our new ai model for the agentic era
Google DeepMind. Introducing gemini 2.0: our new ai model for the agentic era. https://blog.google/ technology / google - deepmind / google - gemini - ai - update - december - 2024/ , 2024. 6, 8
work page 2024
-
[13]
Vizwiz grand challenge: Answering visual questions from blind people
Danna Gurari, Qing Li, Abigale J Stangl, Anhong Guo, Chi Lin, Kristen Grauman, Jiebo Luo, and Jeffrey P Bigham. Vizwiz grand challenge: Answering visual questions from blind people. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3608–3617,
-
[14]
Danna Gurari, Qing Li, Chi Lin, Yinan Zhao, Anhong Guo, Abigale Stangl, and Jeffrey P Bigham. Vizwiz-priv: A dataset for recognizing the presence and purpose of private visual information in images taken by blind people. In Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 939–948, 2019. 8
work page 2019
-
[15]
ByungOk Han, Woo-han Yun, Beom-Su Seo, and Jaehong Kim. Space-aware instruction tuning: Dataset and bench- mark for guide dog robots assisting the visually impaired. arXiv preprint arXiv:2502.07183, 2025. 2
-
[16]
Lora: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models. ICLR, 1(2):3, 2022. 6
work page 2022
-
[17]
Long-form answers to visual questions from blind and low vision people
Mina Huh, Fangyuan Xu, Yi-Hao Peng, Chongyan Chen, Hansika Murugu, Danna Gurari, Eunsol Choi, and Amy Pavel. Long-form answers to visual questions from blind and low vision people. arXiv preprint arXiv:2408.06303, 2024. 8
-
[18]
System configuration and navigation of a guide dog robot: Toward animal guide dog-level guiding work
Hochul Hwang, Tim Xia, Ibrahima Keita, Ken Suzuki, Joy- deep Biswas, Sunghoon I Lee, and Donghyun Kim. System configuration and navigation of a guide dog robot: Toward animal guide dog-level guiding work. In 2023 IEEE Inter- national Conference on Robotics and Automation (ICRA) , pages 9778–9784. IEEE, 2023. 2
work page 2023
-
[19]
Identifying crucial ob- jects in blind and low-vision individuals’ navigation
Md Touhidul Islam, Imran Kabir, Elena Ariel Pearce, Md Al- imoor Reza, and Syed Masum Billah. Identifying crucial ob- jects in blind and low-vision individuals’ navigation. InPro- ceedings of the 26th International ACM SIGACCESS Con- ference on Computers and Accessibility, pages 1–8, 2024. 2, 3, 4
work page 2024
-
[20]
Enhancing multimodal large language models with vision detection models: An empirical study
Qirui Jiao, Daoyuan Chen, Yilun Huang, Yaliang Li, and Ying Shen. Enhancing multimodal large language models with vision detection models: An empirical study. arXiv preprint arXiv:2401.17981, 2024. 4
-
[21]
Techniques for constructing indoor navigation systems for the visually impaired: A review
Roya Norouzi Kandalan and Kamesh Namuduri. Techniques for constructing indoor navigation systems for the visually impaired: A review. IEEE Transactions on Human-Machine Systems, 50(6):492–506, 2020. 1
work page 2020
-
[22]
Meganno+: A human-llm collabora- tive annotation system
Hannah Kim, Kushan Mitra, Rafael Li Chen, Sajjadur Rah- man, and Dan Zhang. Meganno+: A human-llm collabora- tive annotation system. arXiv preprint arXiv:2402.18050 ,
-
[23]
Understanding expec- tations for a robotic guide dog for visually impaired people
J Taery Kim, Morgan Byrd, Jack L Crandell, Bruce N Walker, Greg Turk, and Sehoon Ha. Understanding expec- tations for a robotic guide dog for visually impaired people. arXiv preprint arXiv:2501.04594, 2025. 2 9
-
[24]
Deepnavi: A deep learning based smartphone navigation as- sistant for people with visual impairments
Bineeth Kuriakose, Raju Shrestha, and Frode Eika Sandnes. Deepnavi: A deep learning based smartphone navigation as- sistant for people with visual impairments. Expert Systems with Applications, 212:118720, 2023. 3
work page 2023
-
[25]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Zi- wei Liu, et al. Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326, 2024. 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
A survey of multimodel large language models
Zijing Liang, Yanjie Xu, Yifan Hong, Penghui Shang, Qi Wang, Qiang Fu, and Ke Liu. A survey of multimodel large language models. In Proceedings of the 3rd International Conference on Computer, Artificial Intelligence and Control Engineering, pages 405–409, 2024. 4
work page 2024
-
[27]
A technique for the measurement of attitudes
Rensis Likert. A technique for the measurement of attitudes. Archives of psychology, 1932. 7
work page 1932
-
[28]
ROUGE: A package for automatic evalua- tion of summaries
Chin-Yew Lin. ROUGE: A package for automatic evalua- tion of summaries. In Text Summarization Branches Out , pages 74–81, Barcelona, Spain, 2004. Association for Com- putational Linguistics. 6
work page 2004
-
[29]
Deep learning based wearable assistive system for visually im- paired people
Yimin Lin, Kai Wang, Wanxin Yi, and Shiguo Lian. Deep learning based wearable assistive system for visually im- paired people. In Proceedings of the IEEE/CVF interna- tional conference on computer vision workshops, pages 0–0,
-
[30]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. Advances in neural information processing systems, 36:34892–34916, 2023. 1, 8
work page 2023
-
[31]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. In Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26296–26306, 2024. 6
work page 2024
-
[32]
Ruiping Liu, Jiaming Zhang, Kunyu Peng, Junwei Zheng, Ke Cao, Yufan Chen, Kailun Yang, and Rainer Stiefelhagen. Open scene understanding: Grounded situation recognition meets segment anything for helping people with visual im- pairments. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 1857–1867, 2023. 1
work page 2023
-
[33]
Objectfinder: Open-vocabulary assistive sys- tem for interactive object search by blind people
Ruiping Liu, Jiaming Zhang, Angela Sch ¨on, Karin M ¨uller, Junwei Zheng, Kailun Yang, Kathrin Gerling, and Rainer Stiefelhagen. Objectfinder: Open-vocabulary assistive sys- tem for interactive object search by blind people. arXiv preprint arXiv:2412.03118, 2024. 8
-
[34]
G-eval: NLG evaluation using gpt- 4 with better human alignment
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. G-eval: NLG evaluation using gpt- 4 with better human alignment. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Pro- cessing, pages 2511–2522, Singapore, 2023. Association for Computational Linguistics. 7
work page 2023
-
[35]
Jyoti Madake, Shripad Bhatlawande, Anjali Solanke, and Swati Shilaskar. A qualitative and quantitative analysis of research in mobility technologies for visually impaired peo- ple. IEEE Access, 11:82496–82520, 2023. 3
work page 2023
-
[36]
Mobility-related ac- cidents experienced by people with visual impairment
Roberto Manduchi and Sri Kurniawan. Mobility-related ac- cidents experienced by people with visual impairment. AER Journal: Research and Practice in Visual Impairment and Blindness, 4(2):44–54, 2011. 1, 3
work page 2011
-
[37]
Generating contextually- relevant navigation instructions for blind and low vision peo- ple
Zain Merchant, Abrar Anwar, Emily Wang, Souti Chat- topadhyay, and Jesse Thomason. Generating contextually- relevant navigation instructions for blind and low vision peo- ple. arXiv preprint arXiv:2407.08219, 2024. 2, 3, 8
-
[38]
Meredith Ringel Morris. Ai and accessibility. Communica- tions of the ACM, 63(6):35–37, 2020. 2
work page 2020
-
[39]
We don’t need no bounding-boxes: Train- ing object class detectors using only human verification
Dim P Papadopoulos, Jasper RR Uijlings, Frank Keller, and Vittorio Ferrari. We don’t need no bounding-boxes: Train- ing object class detectors using only human verification. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 854–863, 2016. 2
work page 2016
-
[40]
Bleu: a method for automatic evaluation of machine translation
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics , pages 311– 318, Philadelphia, Pennsylvania, USA, 2002. Association for Computational Linguistics. 6
work page 2002
-
[41]
Egoblur: Responsible innovation in aria, 2023
Nikhil Raina, Guruprasad Somasundaram, Kang Zheng, Sagar Miglani, Steve Saarinen, Jeff Meissner, Mark Schwesinger, Luis Pesqueira, Ishita Prasad, Edward Miller, Prince Gupta, Mingfei Yan, Richard Newcombe, Carl Ren, and Omkar M Parkhi. Egoblur: Responsible innovation in aria, 2023. 4, 8, 12
work page 2023
-
[42]
Optimal walking in terms of variability in step length
Noboru Sekiya, Hiroshi Nagasaki, Hajime Ito, and Taketo Furuna. Optimal walking in terms of variability in step length. Journal of Orthopaedic & Sports Physical Therapy, 26(5):266–272, 1997. 4
work page 1997
-
[43]
Touch your way: hap- tic sight for visually impaired people to walk with indepen- dence
Ji-Won Song and Sung-Ho Yang. Touch your way: hap- tic sight for visually impaired people to walk with indepen- dence. In CHI’10 Extended Abstracts on Human Factors in Computing Systems, pages 3343–3348. 2010. 3
work page 2010
-
[44]
Assisting the blind and visually impaired: guidelines for eye health workers and other helpers
Sue Stevens. Assisting the blind and visually impaired: guidelines for eye health workers and other helpers. Com- munity Eye Health, 16(45):7, 2003. 3
work page 2003
-
[45]
Garreth W Tigwell. Nuanced perspectives toward disabil- ity simulations from digital designers, blind, low vision, and color blind people. In Proceedings of the 2021 CHI confer- ence on human factors in computing systems , pages 1–15,
work page 2021
-
[46]
Label Studio: Data labeling soft- ware, 2020-2025
Maxim Tkachenko, Mikhail Malyuk, Andrey Holmanyuk, and Nikolai Liubimov. Label Studio: Data labeling soft- ware, 2020-2025. Open source software available from https://github.com/HumanSignal/label-studio. 12
work page 2020
-
[47]
Cambrian-1: A fully open, vision-centric explo- ration of multimodal llms
Peter Tong, Ellis Brown, Penghao Wu, Sanghyun Woo, Adithya Jairam Vedagiri IYER, Sai Charitha Akula, Shusheng Yang, Jihan Yang, Manoj Middepogu, Ziteng Wang, et al. Cambrian-1: A fully open, vision-centric explo- ration of multimodal llms. Advances in Neural Information Processing Systems, 37:87310–87356, 2025. 6
work page 2025
-
[48]
Helpful resources for business con- sulting
Vision Australia. Helpful resources for business con- sulting. https://www.visionaustralia.org/ business - consulting / helpful - resources ,
-
[49]
Vision Loss Resources. How to be a sighted guide. https: //visionlossresources.org/resources/how- to-be-a-guide/
-
[50]
Etiquette for interacting with people who are blind or have low vision
Washington State University. Etiquette for interacting with people who are blind or have low vision. https:// 10 studentaffairs.vancouver.wsu.edu/access- center / etiquette - interacting - people - who-are-blind-who-have-low-vision . 3
-
[51]
Dos and don’ts for people with vision loss
Wisconsin Department of Health Services. Dos and don’ts for people with vision loss. https : / / www . dhs . wisconsin.gov/obvi/adjustment/dos-donts. htm, 2023. 3
work page 2023
-
[52]
Wisconsin Department of Health Services. Sighted guide techniques. https://www.dhs.wisconsin.gov/ obvi / adjustment / sightedguidetech . htm ,
-
[53]
Jingyi Xie, Rui Yu, He Zhang, Sooyeon Lee, Syed Ma- sum Billah, and John M Carroll. Emerging practices for large multimodal model (lmm) assistance for people with vi- sual impairments: Implications for design. arXiv preprint arXiv:2407.08882, 2024. 1, 2, 8
-
[54]
MM-Vet: Evaluating Large Multimodal Models for Integrated Capabilities
Weihao Yu, Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Zicheng Liu, Xinchao Wang, and Lijuan Wang. Mm-vet: Evaluating large multimodal models for integrated capabilities. arXiv preprint arXiv:2308.02490, 2023. 13
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[55]
Socratic models: Composing zero-shot multimodal rea- soning with language
Andy Zeng, Maria Attarian, Krzysztof Marcin Choroman- ski, Adrian Wong, Stefan Welker, Federico Tombari, Aveek Purohit, Michael S Ryoo, Vikas Sindhwani, Johnny Lee, et al. Socratic models: Composing zero-shot multimodal rea- soning with language. In The Eleventh International Confer- ence on Learning Representations. 6
-
[56]
Zhe-Xin Zhang and Yoichi Ochiai. A design of interface for visual-impaired people to access visual information from images featuring large language models and visual language models. In Extended Abstracts of the CHI Conference on Human Factors in Computing Systems, pages 1–4, 2024. 8
work page 2024
-
[57]
Vialm: A survey and benchmark of visually impaired assis- tance with large models
Yi Zhao, Yilin Zhang, Rong Xiang, Jing Li, and Hillming Li. Vialm: A survey and benchmark of visually impaired assis- tance with large models. arXiv preprint arXiv:2402.01735,
-
[58]
2, 8 11 A. Automatic Pipeline Details A.1. Gathering Videos To construct a high-quality dataset of outdoor walking scenes, we implemented a systematic approach to video selection. We manually identified YouTube channels spe- cializing in walking tours across urban and natural envi- ronments. All selected channels (listed in Table 6) sat- isfy three criter...
-
[59]
Review the image and decide if it represents a street scene (”Yes”) or not (”No”). Filter out the following non-street cases from the label {is street}: • Certain objects block most of the screen, making it difficult to recognize the street. • The viewer is looking at something other than the street (e.g., looking at the display glass of a store on the st...
-
[60]
If "Yes": • scene description: Provide an overview of the street, including pedestrians, buildings, vehicles, or any key elements that make it a street. • scene location: Describe the location and surroundings using only 10, 11, 12, 1, and 2 o’clock positions. The leftmost part of the image is 10 o’clock, the center is 12 o’clock, and the rightmost is 2 o’clock
-
[61]
No": • scene description: Briefly explain why this is not a street scene. • scene location: Must be
If "No": • scene description: Briefly explain why this is not a street scene. • scene location: Must be "None"
-
[62]
Use only the JSON format below. 5. Do not include any text outside of this JSON format. Output JSON example: { "is_street": "Yes", "scene_description": "A detailed description of the street, including key elements such as pedestrians, shops, and vehicles.", "scene_location": "A positional overview using 10, 11, 12, 1, and 2 o’clock references." } Or: { "i...
-
[63]
Complete Danger Zone (within 5 meters): • Evaluate whether each object is directly in the user’s walking path and could lead to a collision. • Mark an object as dangerous (”Yes”) only if it poses a collision risk (e.g., curbs, potholes, poles, stairs, con- struction barriers, parked vehicles, etc.). • Otherwise, mark it as not dangerous (”No”) and briefly...
-
[64]
object": the object’s identifier or name. •
Ordinary Zone (beyond 5 meters) • Focus on moving objects in this zone (e.g., approaching motorcycles, cars, bicycles, pedestrians). • Mark an object as dangerous (”Yes”) if it is moving toward the user and could pose a threat. • Otherwise, mark it as not dangerous (”No”) and provide a brief explanation. For each object, provide a JSON entry with the foll...
-
[66]
Navigation: After describing all hazards, provide a single, concise sentence on how to safely navigate or avoid them overall. Potential Hazards: {object info} Scene Information: {scene info} Remember to provide a single, flowing explanation without labeled sections, as if talking directly to the visually impaired individual. Figure 9. The silver label gen...
-
[68]
Navigation: After describing all hazards, provide a single, concise sentence on how to safely navigate or avoid them overall. Remember to provide a single, flowing explanation without labeled sections, as if talking directly to the visually impaired individual. Figure 11. The zero-shot prompt designed for MLLM to generate accessibility-aware guidance gene...
-
[70]
Navigation: After describing all hazards, provide a single, concise sentence on how to safely navigate or avoid them overall. Examples: • You’re on a bustling city street with buildings on your left, and the sidewalk and storefronts on your right. At 10 o’clock, about five steps away, there’s a moving car which is potentially dangerous if you stray off th...
-
[72]
Navigation: After describing all hazards, provide a single, concise sentence on how to safely navigate or avoid them overall. Remember to provide a single, flowing explanation without labeled sections, as if talking directly to the visually impaired individual. Scene Description: {llava output} Object Info: {object info} Guidance: Figure 13. The zero-shot...
-
[73]
Surroundings and Position: Summarize where the person is, the general environment, their current position, and any nearby landmarks in 1-2 sentences
-
[74]
• Follow the order of 10, 11, 12, 1, and 2 o’clock
Hazards: • For each direction (10, 11, 12, 1, and 2 o’clock), combine all hazards in that direction into exactly one sentence, mentioning approximate distance(s) and reason(s) they are dangerous. • Follow the order of 10, 11, 12, 1, and 2 o’clock
-
[75]
Navigation: After describing all hazards, provide a single, concise sentence on how to safely navigate or avoid them overall. Remember to provide a single, flowing explanation without labeled sections, as if talking directly to the visually impaired individual. Scene Description: Object Info: Guidance: You’re on a bustling city street with buildings on yo...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.