3D Densification for Multi-Map Monocular VSLAM in Endoscopy
Pith reviewed 2026-05-22 23:42 UTC · model grok-4.3
The pith
Aligning neural up-to-scale depth predictions to sparse CudaSIFT submaps via LMedS removes outliers and resolves scale ambiguity to produce dense 3D maps at 4.15 mm RMS accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Robust LMedS alignment of LightDepth up-to-scale dense depth predictions with the sparse points of CudaSIFT multi-map submaps simultaneously resolves monocular scale ambiguity and rejects outliers, yielding reliable dense 3D maps whose accuracy is demonstrated at 4.15 mm RMS on phantom colon data.
What carries the argument
LMedS robust estimator that finds the scale factor aligning LightDepth depth images to each CudaSIFT submap while discarding inconsistent points, thereby densifying the map and filtering noise.
If this is right
- The multi-map SLAM system retains its ability to recover from tracking losses while now supplying maps dense enough for clinical visualization.
- Outlier rejection occurs as a byproduct of the scale-alignment step, removing the need for separate post-processing filters.
- The method runs at acceptable compute cost on standard hardware, supporting potential intraoperative deployment.
- Qualitative success on real Endomapper sequences indicates the alignment works beyond the controlled phantom environment.
Where Pith is reading between the lines
- The same alignment technique could be tested on other monocular SLAM pipelines that already produce submaps, without requiring changes to the underlying tracker.
- If the LMedS step proves the dominant cost, replacing it with a faster robust estimator might preserve accuracy at higher frame rates.
- Combining the densified output with surface reconstruction algorithms could produce watertight meshes suitable for surgical planning.
- Failure cases on real data would likely appear first in sequences with large scale changes or heavy specular reflections.
Load-bearing premise
The neural depth predictions and the sparse SLAM points share enough consistent geometry that a single robust scale estimate can be found and that the remaining points after outlier rejection are accurate enough for clinical use.
What would settle it
Quantitative evaluation of the densified maps against independent ground-truth 3D surface measurements on a set of real human colonoscopy sequences, checking whether RMS error remains near 4 mm or rises sharply when lighting, fluid, or tool motion differs from the phantom.
Figures



read the original abstract
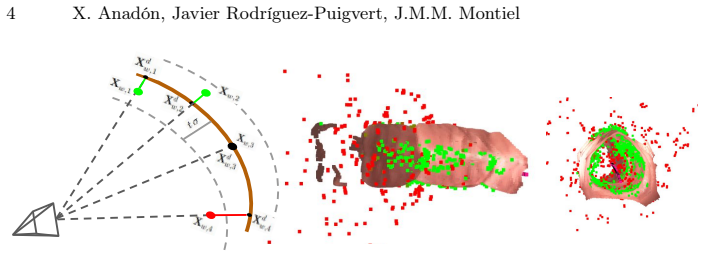
Multi-map Sparse Monocular visual Simultaneous Localization and Mapping applied to monocular endoscopic sequences has proven efficient to robustly recover tracking after the frequent losses in endoscopy due to motion blur, temporal occlusion, tools interaction or water jets. The sparse multi-maps are adequate for robust camera localization, however they are very poor for environment representation, they are noisy, with a high percentage of inaccurately reconstructed 3D points, including significant outliers, and more importantly with an unacceptable low density for clinical applications. We propose a method to remove outliers and densify the maps of the state of the art for sparse endoscopy multi-map CudaSIFT-SLAM. The NN LightDepth for up-to-scale depth dense predictions are aligned with the sparse CudaSIFT submaps by means of the robust to spurious LMedS. Our system mitigates the inherent scale ambiguity in monocular depth estimation while filtering outliers, leading to reliable densified 3D maps. We provide experimental evidence of accurate densified maps 4.15 mm RMS accuracy at affordable computing time in the C3VD phantom colon dataset. We report qualitative results on the real colonoscopy from the Endomapper dataset.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a densification pipeline for multi-map sparse monocular VSLAM in endoscopy. Up-to-scale dense depth maps from the LightDepth network are aligned to the noisy, outlier-heavy CudaSIFT submaps via LMedS robust estimation; the resulting scale factor is used both to resolve monocular scale ambiguity and to filter outliers, producing denser 3D maps. Quantitative evaluation on the C3VD phantom colon dataset reports 4.15 mm RMS accuracy; qualitative results are shown on real Endomapper colonoscopy sequences.
Significance. If the LMedS alignment step is shown to be robust, the method would address a practical limitation of existing sparse endoscopic SLAM systems by delivering denser, metrically scaled maps at modest computational cost, which is relevant for clinical visualization and navigation tasks.
major comments (2)
- [Abstract] Abstract and method description: the claim that LMedS alignment 'mitigates the inherent scale ambiguity' while reliably filtering outliers rests on the assumption that a single scale factor recovered from the sparse CudaSIFT points is unique and accurate. No per-submap inlier ratios, scale-factor variance across maps, or sensitivity analysis to inlier distribution (e.g., clustering on specular highlights) is provided, leaving the central robustness claim unverified.
- [Experimental results] Experimental evaluation: the reported 4.15 mm RMS is given without accompanying details on the exact alignment procedure, number of inliers retained, error distribution per submap, or comparison against alternative scale-recovery baselines, so it is impossible to assess whether the improvement is attributable to the proposed densification or to dataset-specific properties.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract and method description: the claim that LMedS alignment 'mitigates the inherent scale ambiguity' while reliably filtering outliers rests on the assumption that a single scale factor recovered from the sparse CudaSIFT points is unique and accurate. No per-submap inlier ratios, scale-factor variance across maps, or sensitivity analysis to inlier distribution (e.g., clustering on specular highlights) is provided, leaving the central robustness claim unverified.
Authors: We agree that additional quantitative support for the robustness of the single-scale LMedS recovery would strengthen the central claim. LMedS was selected for its established resistance to outliers in scale-estimation settings, and the reported 4.15 mm RMS on C3VD provides indirect evidence of overall map accuracy. In the revised manuscript we will add per-submap inlier ratios, scale-factor variance statistics, and a brief sensitivity check against specular-highlight clustering to directly verify the assumption. revision: yes
-
Referee: [Experimental results] Experimental evaluation: the reported 4.15 mm RMS is given without accompanying details on the exact alignment procedure, number of inliers retained, error distribution per submap, or comparison against alternative scale-recovery baselines, so it is impossible to assess whether the improvement is attributable to the proposed densification or to dataset-specific properties.
Authors: We acknowledge that the current experimental section lacks the requested procedural and comparative details. The 4.15 mm RMS figure is obtained after LMedS alignment on the C3VD phantom; the revision will expand the evaluation to report the precise alignment steps, retained inlier counts, per-submap error distributions, and direct comparisons against alternative scale-recovery baselines (e.g., RANSAC). revision: yes
Circularity Check
No circularity; densification uses independent NN predictions and standard LMedS on external SLAM output
full rationale
The paper's core step aligns up-to-scale dense depth from the external LightDepth network to sparse CudaSIFT submaps via LMedS robust estimation. This determines a scale factor from the data rather than by definition or self-fit. No equations reduce a claimed prediction to its own inputs, no self-citation chains justify uniqueness, and no ansatz is smuggled. Validation reports an independent RMS metric on the C3VD dataset, confirming the derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Monocular depth estimation networks provide up-to-scale but structurally accurate depth maps.
- domain assumption LMedS can robustly estimate the scale and inlier set between dense predictions and sparse points.
Reference graph
Works this paper leans on
-
[1]
Scientific Data10(1), 671 (2023)
Azagra, P., et al.: EndoMapper dataset of complete calibrated endoscopy proce- dures. Scientific Data10(1), 671 (2023)
work page 2023
-
[2]
Batlle, V.M., Montiel, J.M.M., Fua, P., Tardós, J.D.: LightNeuS: Neural surface reconstruction in endoscopy using illumination decline. In: MICCAI. pp. 503–513. Springer (2023)
work page 2023
-
[3]
Bonilla, S., Zhang, S., Psychogyios, D., Stoyanov, D., Vasconcelos, F., Bano, S.: Gaussian Pancakes: Geometrically-Regularized 3D Gaussian Splatting for Realistic Endoscopic Reconstruction. arXiv (2024)
work page 2024
-
[4]
IEEE Transactions on Robotics37(6), 1874–1890 (2021)
Campos, C., Elvira, R., Gomez, J.J., Montiel, J.M.M., Tardós, J.D.: ORB-SLAM3: An accurate open-source library for visual, visual-inertial and multi-map SLAM. IEEE Transactions on Robotics37(6), 1874–1890 (2021)
work page 2021
-
[5]
In: Proceedings of the 23rd annual conference on Computer graphics and interactive techniques
Curless, B., Levoy, M.: A volumetric method for building complex models from range images. In: Proceedings of the 23rd annual conference on Computer graphics and interactive techniques. pp. 303–312 (1996)
work page 1996
-
[6]
In: arXiv preprint arXiv:2412.13176 (2024)
Dunn Beltran, A., Rho, D., Niethammer, M., Sengupta, R.: Nfl-ba: Improv- ing endoscopic slam with near-field light bundle adjustment. In: arXiv preprint arXiv:2412.13176 (2024)
-
[7]
arXiv preprint arXiv:2405.16932 (2024)
Elvira, R., Tardós, J.D., Montiel, J.M.M.: CudaSIFT-SLAM: multiple-map vi- sual SLAM for full procedure mapping in real human endoscopy. arXiv preprint arXiv:2405.16932 (2024)
-
[8]
IEEE Transactions on Pattern Analysis and Machine Intelligence40(3), 611–625 (2018)
Engel, J., Koltun, V., Cremers, D.: Direct sparse odometry. IEEE Transactions on Pattern Analysis and Machine Intelligence40(3), 611–625 (2018)
work page 2018
-
[9]
Godard, C., Mac Aodha, O., Firman, M., Brostow, G.J.: Digging into self- supervised monocular depth prediction. ICCV (October 2019)
work page 2019
-
[10]
Guo, J., Wang, J., Kang, D., Dong, W., Wang, W., Liu, Y.h.: Free-surgs: Sfm- free 3d gaussian splatting for surgical scene reconstruction. In: MICCAI. Springer (2024)
work page 2024
-
[11]
Huang,B.,Zheng,J.Q.,Nguyen,A.,Tuch,D.,Vyas,K.,Giannarou,S.,Elson,D.S.: Self-supervised generative adversarial network for depth estimation in laparoscopic images. In: MICCAI (2021)
work page 2021
-
[12]
Karaoglu, M.A., Brasch, N., Stollenga, M., Wein, W., Navab, N., Tombari, F., Ladikos, A.: Adversarial domain feature adaptation for bronchoscopic depth esti- mation. In: MICCAI. pp. 300–310. Springer (2021)
work page 2021
-
[13]
In: 2022 International Conference on Robotics and Automation (ICRA)
Liu, X., Li, Z., Ishii, M., Hager, G.D., Taylor, R.H., Unberath, M.: Sage: Slam with appearance and geometry prior for endoscopy. In: 2022 International Conference on Robotics and Automation (ICRA). pp. 5587–5593 (2022)
work page 2022
-
[14]
Lorensen, W.E., Cline, H.E.: Marching cubes: A high resolution 3d surface con- struction algorithm. SIGGRAPH Comput. Graph.21(4), 163–169 (Aug 1987)
work page 1987
-
[15]
Healthcare Technology Letters6(6), 154 (2019)
Luo, H., Hu, Q., Jia, F.: Details preserved unsupervised depth estimation by fus- ing traditional stereo knowledge from laparoscopic images. Healthcare Technology Letters6(6), 154 (2019)
work page 2019
-
[16]
Medical image analysis72, 102100 (2021)
Ma, R., Wang, R., Zhang, Y., Pizer, S., McGill, S.K., Rosenman, J., Frahm, J.M.: RNNSLAM: Reconstructing the 3D colon to visualize missing regions during a colonoscopy. Medical image analysis72, 102100 (2021)
work page 2021
-
[17]
IEEE transactions on medical imaging38(1), 79–89 (2018) 10 X
Mahmoud, N., Collins, T., Hostettler, A., Soler, L., Doignon, C., Montiel, J.M.M.: Live tracking and dense reconstruction for handheld monocular endoscopy. IEEE transactions on medical imaging38(1), 79–89 (2018) 10 X. Anadón, Javier Rodríguez-Puigvert, J.M.M. Montiel
work page 2018
-
[18]
Frontiers in Gastroenterology3(2024)
Metzger, R., Suppa, P., Li, Z., Vemuri, A.: Augmented reality navigation systems in endoscopy. Frontiers in Gastroenterology3(2024)
work page 2024
-
[19]
Morlana, J., Tardós, J.D., Montiel, J.: ColonMapper: topological mapping and localization for colonoscopy. In: IEEE ICRA. pp. 6329–6336 (2024)
work page 2024
-
[20]
Mur-Artal, R., Montiel, J.M.M., Tardós, J.D.: ORB-SLAM: a versatile and accu- rate monocular SLAM system. IEEE Trans. on Robotics31(5), 1147–1163 (2015)
work page 2015
- [21]
-
[22]
International Journal of Computer Assisted Radiology and Surgery pp
Rau, A., Edwards, P.E., Ahmad, O.F., Riordan, P., Janatka, M., Lovat, L.B., Stoyanov, D.: Implicit domain adaptation with conditional generative adversarial networks for depth prediction in endoscopy. International Journal of Computer Assisted Radiology and Surgery pp. 1–10 (2019)
work page 2019
-
[23]
IEEE Robotics and Automation Letters6(4), 7225–7232 (2021)
Recasens, D., Lamarca, J., Fácil, J.M., Montiel, J.M.M., Civera, J.: Endo-Depth- and-Motion: Reconstruction and Tracking in Endoscopic Videos Using Depth Net- works and Photometric Constraints. IEEE Robotics and Automation Letters6(4), 7225–7232 (2021)
work page 2021
-
[24]
Rodríguez-Puigvert, J., Batlle, V.M., Montiel, J., Martinez-Cantin, R., Fua, P., Tardós, J.D., Civera, J.: LightDepth: Single-View Depth Self-Supervision from Illumination Decline. In: (ICCV). pp. 21273–21283 (October 2023)
work page 2023
-
[25]
Rodriguez-Puigvert, J., Recasens, D., Civera, J., Martinez-Cantin, R.: On the Un- certain Single-View Depths in Colonoscopies. In: MICCAI. pp. 130–140. Springer (2022)
work page 2022
-
[26]
IEEE Transactions on Robotics40, 4252–4264 (2024)
Rodríguez, J.J.G., Montiel, J.M., Tardós, J.D.: NR-SLAM: Nonrigid monocular SLAM. IEEE Transactions on Robotics40, 4252–4264 (2024)
work page 2024
-
[27]
Ronneberger, O., Fischer, P., Brox, T.: U-Net: Convolutional Networks for Biomed- ical Image Segmentation. In: MICCAI. pp. 234–241. Springer (2015)
work page 2015
-
[28]
Journal of the American Statistical Association79(388), 871–880 (1984)
Rousseeuw, P.J.: Least Median of Squares Regression. Journal of the American Statistical Association79(388), 871–880 (1984)
work page 1984
- [29]
-
[30]
International Journal of Computer Assisted Radiology and Surgery12(7), 1089–1099 (Jul 2017)
Visentini-Scarzanella, M., Sugiura, T., Kaneko, T., Koto, S.: Deep monocular 3D reconstruction for assisted navigation in bronchoscopy. International Journal of Computer Assisted Radiology and Surgery12(7), 1089–1099 (Jul 2017)
work page 2017
-
[31]
Wang, K., Yang, C., Wang, Y., Li, S., Wang, Y., Dou, Q., Yang, X., Shen, W.: EndoGSLAM: Real-Time Dense Reconstruction and Tracking in Endoscopic Surg- eries using Gaussian Splatting. arXiv preprint arXiv:2403.15124 (2024)
- [32]
-
[33]
Wang, S., Paruchuri, A., Zhang, Z., McGill, S., Sengupta, R.: Structure-preserving Image Translation for Depth Estimation in Colonoscopy Video. In: MICCAI. vol. LNCS 15011, pp. 667–677. Springer (October 2024)
work page 2024
-
[34]
Wang, Y., Long, Y., Fan, S.H., Dou, Q.: Neural Rendering for Stereo 3D Recon- struction of Deformable Tissues in Robotic Surgery. In: MICCAI. pp. 431–441. Springer (2022)
work page 2022
-
[35]
Open3D: A Modern Library for 3D Data Processing
Zhou, Q.Y., Park, J., Koltun, V.: Open3D: A modern library for 3D data process- ing. arXiv:1801.09847 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.