Deep Visual Servoing of an Aerial Robot Using Keypoint Feature Extraction
Pith reviewed 2026-05-22 22:31 UTC · model grok-4.3
The pith
Deep learning keypoints allow aerial robots to perform visual servoing without artificial markers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A CNN extracts keypoints from monocular RGB images to supply visual features for image-based visual servoing of an aerial robot, bypassing the need for man-made markers and gaining robustness to occlusion, varying illumination, clutter, and background changes, as shown in extensive physics-based ROS Gazebo simulations.
What carries the argument
The CNN keypoint detector that turns camera images into features for the closed-loop visual servoing controller.
If this is right
- Aerial robots can execute visual servoing tasks without any markers placed in the environment.
- The controller remains functional when the camera view is partially blocked or lighting shifts.
- Camera-based motion control applies to unprepared scenes with clutter and changing backgrounds.
- Physics-based simulations provide a more realistic test than idealized models alone.
Where Pith is reading between the lines
- The technique might extend to outdoor flights where backgrounds and light vary even more than in the tested simulations.
- It could combine with other sensors to handle cases where image features temporarily become unreliable.
- Physical robot tests would be required to check whether simulation results hold on real hardware.
Load-bearing premise
The CNN keypoint detector supplies features reliable enough to keep the visual servoing loop stable under occlusion, illumination changes, clutter, and background shifts.
What would settle it
A Gazebo simulation run in which the aerial robot fails to reach the target pose when keypoints become occluded or illumination varies.
Figures








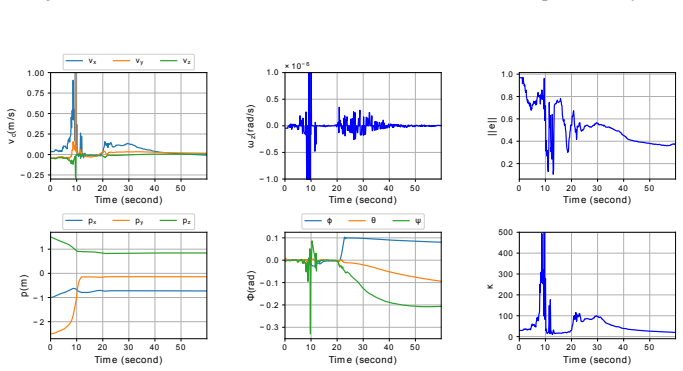
read the original abstract
The problem of image-based visual servoing (IBVS) of an aerial robot using deep-learning-based keypoint detection is addressed in this article. A monocular RGB camera mounted on the platform is utilized to collect the visual data. A convolutional neural network (CNN) is then employed to extract the features serving as the visual data for the servoing task. This paper contributes to the field by circumventing not only the challenge stemming from the need for man-made marker detection in conventional visual servoing techniques, but also enhancing the robustness against undesirable factors including occlusion, varying illumination, clutter, and background changes, thereby broadening the applicability of perception-guided motion control tasks in aerial robots. Additionally, extensive physics-based ROS Gazebo simulations are conducted to assess the effectiveness of this method, in contrast to many existing studies that rely solely on physics-less simulations. A demonstration video is available at https://youtu.be/Dd2Her8Ly-E.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript addresses image-based visual servoing (IBVS) for an aerial robot using a monocular RGB camera and a CNN to extract keypoints as visual features. It claims to eliminate reliance on man-made markers while improving robustness to occlusion, varying illumination, clutter, and background changes, with validation performed via extensive physics-based ROS Gazebo simulations rather than purely kinematic ones.
Significance. A markerless keypoint-based IBVS method for aerial platforms could broaden applicability in unstructured settings if the robustness claims hold. The emphasis on physics-based simulation is a methodological strength relative to many prior works, but the absence of any reported quantitative metrics, error statistics, or disturbance-specific results means the significance cannot be assessed from the current evidence.
major comments (2)
- [Abstract] Abstract: the central claims of robustness enhancement against occlusion, illumination variation, clutter, and background changes, plus effectiveness assessment via simulations, are stated without any quantitative metrics, control-error statistics, feature-stability measures, or baseline comparisons.
- [Simulation description] Simulation description (wherever presented): no explicit account is given of how the listed disturbances (dynamic illumination, partial occlusions, moving clutter, background shifts) are injected into the Gazebo camera and lighting models, so it is impossible to determine whether the simulations actually exercise the conditions required by the robustness claim.
minor comments (1)
- [Abstract] The demonstration video link is supplied but its relation to the quantitative claims cannot be evaluated from the text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comments point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims of robustness enhancement against occlusion, illumination variation, clutter, and background changes, plus effectiveness assessment via simulations, are stated without any quantitative metrics, control-error statistics, feature-stability measures, or baseline comparisons.
Authors: We agree that the abstract would benefit from quantitative support for the robustness claims. In the revised manuscript we will update the abstract to include key simulation results such as control-error statistics, feature-stability measures, and any baseline comparisons that are present in the body of the paper. revision: yes
-
Referee: [Simulation description] Simulation description (wherever presented): no explicit account is given of how the listed disturbances (dynamic illumination, partial occlusions, moving clutter, background shifts) are injected into the Gazebo camera and lighting models, so it is impossible to determine whether the simulations actually exercise the conditions required by the robustness claim.
Authors: We acknowledge that the current simulation description lacks explicit implementation details for the disturbances. We will expand the relevant section to describe how dynamic illumination, partial occlusions, moving clutter, and background shifts are realized within the Gazebo camera and lighting models. revision: yes
Circularity Check
No circularity; method and validation are independent of self-referential constructions
full rationale
The paper describes a CNN-based keypoint detector for markerless IBVS on an aerial robot and reports results from Gazebo simulations. No equations, parameters, or claims reduce by construction to fitted inputs or prior self-citations. The robustness statement is an empirical claim tested in simulation rather than a tautology or self-citation chain. The derivation chain (camera image → CNN keypoints → IBVS control law) contains no self-definitional or fitted-prediction steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption CNN keypoint detection from monocular RGB images yields features sufficiently accurate and robust for IBVS control under occlusion, illumination variation, clutter, and background changes.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The feature error is stabilized using cvc = λ cL† e ... interaction matrix cLi ...
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
CNN ... VGG-19 ... predicts eight pixel coordinates ... MAE dropped from 0.3 to 0.007
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
N. Amiri and F. Janabi-Sharifi, “High-performance coupled kinematics of aerial continuum manipulation systems for control applications,” SSRN, 2024. Available at SSRN: ssrn.com/abstract=4973345 or doi:10.2139/ssrn.4973345
-
[2]
Stereo image-based visual servoing towards feature-based grasping,
A. Enyedy, A. Aswale, B. Calli, and M. Gennert, “Stereo image-based visual servoing towards feature-based grasping,” in2024 IEEE Interna- tional Conference on Robotics and Automation (ICRA) , pp. 7325–7331, 2024
work page 2024
-
[3]
Adaptive ibvs based planar non-holonomic target tracking for quadrotors,
Y . Kumar, S. B. Roy, and S. P.B., “Adaptive ibvs based planar non-holonomic target tracking for quadrotors,” in 2024 International Conference on Unmanned Aircraft Systems (ICUAS) , pp. 201–208, 2024
work page 2024
-
[4]
Robust image-based visual servoing of an aerial robot using self- organizing neural networks,
S. Sepahvand, F. Janabi-Sharifi, H. Masnavi, F. Aghili, and N. Amiri, “Robust image-based visual servoing of an aerial robot using self- organizing neural networks,”International Journal of Control, Automa- tion and Systems , vol. 22, pp. 3762–3776, Dec 2024
work page 2024
-
[5]
Autonomous landing guidance for quad-uavs based on visual image and altitude estimation,
L. Mu, S. Cao, Y . Zhang, X. Zhang, N. Feng, and Y . Zhang, “Autonomous landing guidance for quad-uavs based on visual image and altitude estimation,” Drones, vol. 9, no. 1, 2025
work page 2025
-
[6]
A novel fuzzy image-based uav landing using rgbd data and visual slam,
S. Sepahvand, N. Amiri, H. Masnavi, I. Mantegh, and F. Janabi-Sharifi, “A novel fuzzy image-based uav landing using rgbd data and visual slam,” Drones, vol. 8, no. 10, 2024
work page 2024
-
[7]
6d object position estimation from 2d images: a literature review,
G. Marullo, L. Tanzi, P. Piazzolla, and E. Vezzetti, “6d object position estimation from 2d images: a literature review,” Multimedia Tools and Applications, vol. 82, pp. 24605–24643, Jul 2023
work page 2023
-
[8]
Challenges for monocular 6-d object pose estimation in robotics,
S. Thalhammer, D. Bauer, P. H ¨onig, J.-B. Weibel, J. Garc´ıa-Rodr´ıguez, and M. Vincze, “Challenges for monocular 6-d object pose estimation in robotics,” IEEE Transactions on Robotics , vol. 40, pp. 4065–4084, 2024
work page 2024
-
[9]
PoseCNN: A Convolutional Neural Network for 6D Object Pose Estimation in Cluttered Scenes
Y . Xiang, T. Schmidt, V . Narayanan, and D. Fox, “Posecnn: A convolutional neural network for 6d object pose estimation in cluttered scenes,” arXiv preprint arXiv:1711.00199 , 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[10]
Learning 6d object pose estimation using 3d object coordinates,
E. Brachmann, A. Krull, F. Michel, S. Gumhold, J. Shotton, and C. Rother, “Learning 6d object pose estimation using 3d object coordinates,” in Computer Vision – ECCV 2014 (D. Fleet, T. Pajdla, B. Schiele, and T. Tuytelaars, eds.), (Cham), pp. 536–551, Springer International Publishing, 2014
work page 2014
-
[11]
Normalized object coordinate space for category-level 6d object pose and size estimation,
H. Wang, S. Sridhar, J. Huang, J. Valentin, S. Song, and L. J. Guibas, “Normalized object coordinate space for category-level 6d object pose and size estimation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pp. 2642–2651, 2019
work page 2019
-
[12]
Clearpose: Large-scale transparent object dataset and benchmark,
X. Chen, H. Zhang, Z. Yu, A. Opipari, and O. Chadwicke Jenkins, “Clearpose: Large-scale transparent object dataset and benchmark,” in European conference on computer vision, pp. 381–396, Springer, 2022. 0 10 20 30 40 50 Tim e (second) −0.2 0.0 0.2 0.4 v c(m /s) vx vy vz 0 10 20 30 40 50 Tim e (second) −1.0 −0.5 0.0 0.5 1.0 ωz(rad/s) × 10 −6 0 10 20 30 40 ...
work page 2022
-
[13]
P. Wang, H. Jung, Y . Li, S. Shen, R. P. Srikanth, L. Garattoni, S. Meier, N. Navab, and B. Busam, “Phocal: A multi-modal dataset for category- level object pose estimation with photometrically challenging objects,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 21222–21231, 2022
work page 2022
-
[14]
Z. He, Y . Chao, M. Wu, Y . Hu, and X. Zhao, “G-gop: generative pose estimation of reflective texture-less metal parts with global- observation-point priors,” IEEE/ASME Transactions on Mechatronics , vol. 29, no. 1, pp. 154–165, 2023
work page 2023
-
[15]
Keypose: Multi-view 3d labeling and keypoint estimation for transparent ob- jects,
X. Liu, R. Jonschkowski, A. Angelova, and K. Konolige, “Keypose: Multi-view 3d labeling and keypoint estimation for transparent ob- jects,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pp. 11602–11610, 2020
work page 2020
-
[16]
Corke, Vision-Based Control, pp
P. Corke, Vision-Based Control, pp. 667–696. Cham: Springer Inter- national Publishing, 2023
work page 2023
-
[17]
C. Yu, Z. Cai, H. Pham, and Q.-C. Pham, “Siamese convolutional neural network for sub-millimeter-accurate camera pose estimation and visual servoing,” in 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pp. 935–941, 2019
work page 2019
-
[18]
Convolutional neural network- based visual servoing for eye-to-hand manipulator,
F. Tokuda, S. Arai, and K. Kosuge, “Convolutional neural network- based visual servoing for eye-to-hand manipulator,” IEEE Access , vol. 9, pp. 91820–91835, 2021
work page 2021
-
[19]
Dfbvs: Deep feature-based visual servo,
N. Adrian, V .-T. Do, and Q.-C. Pham, “Dfbvs: Deep feature-based visual servo,” in 2022 IEEE 18th International Conference on Au- tomation Science and Engineering (CASE) , pp. 1783–1789, 2022
work page 2022
-
[20]
Keypoint detection tech- nique for image-based visual servoing of manipulators,
N. Amiri, G. Wang, and F. Janabi-Sharifi, “Keypoint detection tech- nique for image-based visual servoing of manipulators,” in 2024 IEEE 20th International Conference on Automation Science and Engineering (CASE), pp. 3557–3562, 2024
work page 2024
-
[21]
Adaptive image- based visual servoing for an underactuated quadrotor system,
D. Lee, H. Lim, H. J. Kim, Y . Kim, and K. J. Seong, “Adaptive image- based visual servoing for an underactuated quadrotor system,” Journal of Guidance, Control, and Dynamics , vol. 35, no. 4, pp. 1335–1353, 2012
work page 2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.