A Survey of Scaling in Large Language Model Reasoning
Pith reviewed 2026-05-22 21:17 UTC · model grok-4.3
The pith
Scaling reasoning in LLMs is more complex than scaling model size and can sometimes reduce performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
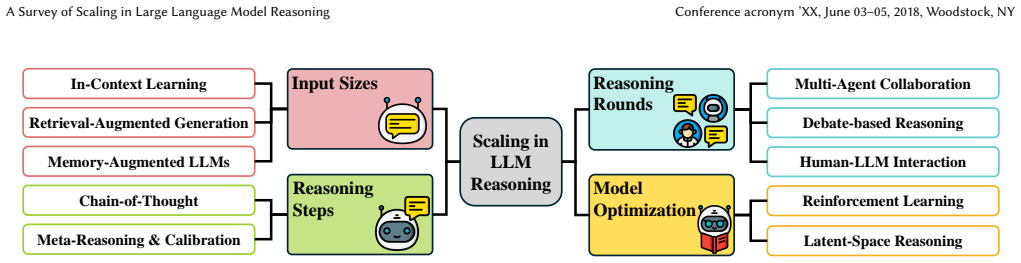
The paper establishes that scaling reasoning in LLMs, unlike scaling data volume or parameter count, produces complex and sometimes negative effects on performance. It organizes the phenomenon into four dimensions: input size scaling, which expands usable context; reasoning steps scaling, which affects multi-step inference and consistency; reasoning rounds scaling, which uses iterative interactions; and training-enabled reasoning scaling, which optimizes through repeated model updates. The central observation is that these forms of scaling can degrade reasoning quality and create new alignment and robustness challenges.
What carries the argument
Taxonomy of four scaling dimensions (input size, reasoning steps, reasoning rounds, training-enabled reasoning) that structures the analysis of how each affects LLM reasoning performance.
If this is right
- Input size scaling allows LLMs to incorporate and use larger contexts for reasoning.
- Scaling the number of reasoning steps can strengthen multi-step inference while risking reduced logical consistency.
- Increasing reasoning rounds through iteration can refine final outputs but adds interaction overhead.
- Training-enabled scaling supports iterative model improvement yet raises alignment and robustness concerns.
Where Pith is reading between the lines
- The results suggest that optimal performance may require deliberate trade-offs among the four dimensions rather than uniform increases.
- Alignment methods developed for standard model scaling may need revision to address outputs from scaled reasoning processes.
- The survey leaves open whether hybrid strategies that combine dimensions in fixed ratios could avoid the negative effects observed in single-dimension scaling.
Load-bearing premise
The four chosen dimensions form a complete and non-overlapping taxonomy of the main ways scaling influences LLM reasoning.
What would settle it
An empirical study that identifies a major scaling behavior on reasoning performance which cannot be placed in any of the four categories.
Figures
read the original abstract
The rapid advancements in large Language models (LLMs) have significantly enhanced their reasoning capabilities, driven by various strategies such as multi-agent collaboration. However, unlike the well-established performance improvements achieved through scaling data and model size, the scaling of reasoning in LLMs is more complex and can even negatively impact reasoning performance, introducing new challenges in model alignment and robustness. In this survey, we provide a comprehensive examination of scaling in LLM reasoning, categorizing it into multiple dimensions and analyzing how and to what extent different scaling strategies contribute to improving reasoning capabilities. We begin by exploring scaling in input size, which enables LLMs to process and utilize a more extensive context for improved reasoning. Next, we analyze scaling in reasoning steps that improve multi-step inference and logical consistency. We then examine scaling in reasoning rounds, where iterative interactions refine reasoning outcomes. Furthermore, we discuss scaling in training-enabled reasoning, focusing on optimization through iterative model improvement. Finally, we outline future directions for further advancing LLM reasoning. By synthesizing these diverse perspectives, this survey aims to provide insights into how scaling strategies fundamentally enhance the reasoning capabilities of LLMs and further guide the development of next-generation AI systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper surveys scaling strategies for improving reasoning in large language models. It argues that, unlike scaling data volume or model size, scaling reasoning is more complex and can degrade performance while raising new issues in alignment and robustness. The survey organizes the topic into four dimensions—scaling input size (for longer context), scaling reasoning steps (for multi-step inference), scaling reasoning rounds (for iterative refinement), and scaling training-enabled reasoning (for iterative model improvement)—and concludes with future directions.
Significance. A well-executed survey that cleanly separates reasoning-specific scaling phenomena from classical scaling laws could usefully organize an emerging literature and highlight failure modes (e.g., alignment drift under iterative refinement) that are not captured by standard scaling analyses. The manuscript’s value therefore hinges on whether the four-dimensional taxonomy is shown to be both exhaustive and non-redundant; if that partition holds, the survey would supply a practical framework for future work on robust LLM reasoning.
major comments (1)
- [Abstract / taxonomy] Abstract and taxonomy section: the central claim that reasoning scaling is categorically more complex than data/model scaling rests on the four dimensions constituting a complete, non-overlapping partition. The manuscript does not demonstrate that these axes are independent (scaling the number of reasoning steps frequently co-occurs with additional rounds or extra training data) or that they exhaust the relevant space (inference-time compute allocation and tool-use scaling are omitted). Without explicit justification or a mapping of the literature onto these axes, the assertion that reasoning scaling introduces distinctly new alignment/robustness challenges cannot be cleanly supported by the survey structure.
minor comments (1)
- [Abstract] The opening sentence references multi-agent collaboration, yet this strategy is not explicitly located within any of the four scaling dimensions; a brief mapping would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the taxonomy. We agree that additional explicit justification will strengthen the manuscript and will revise accordingly.
read point-by-point responses
-
Referee: [Abstract / taxonomy] Abstract and taxonomy section: the central claim that reasoning scaling is categorically more complex than data/model scaling rests on the four dimensions constituting a complete, non-overlapping partition. The manuscript does not demonstrate that these axes are independent (scaling the number of reasoning steps frequently co-occurs with additional rounds or extra training data) or that they exhaust the relevant space (inference-time compute allocation and tool-use scaling are omitted). Without explicit justification or a mapping of the literature onto these axes, the assertion that reasoning scaling introduces distinctly new alignment/robustness challenges cannot be cleanly supported by the survey structure.
Authors: We acknowledge the need for stronger justification of the taxonomy. In the revision we will add a dedicated subsection (likely 2.5 or an expanded Section 2) that: (1) provides a mapping table of representative papers onto the four dimensions, (2) explicitly discusses interdependencies and overlaps (e.g., steps frequently co-occurring with rounds) while arguing that the axes remain analytically useful for isolating distinct scaling phenomena and associated failure modes, and (3) addresses scope by clarifying that inference-time compute allocation is primarily captured under scaling reasoning steps and rounds, while tool-use scaling is subsumed under scaling reasoning steps as an extension of multi-step inference. This addition will directly support the claim regarding new alignment and robustness challenges without changing the core four-dimension structure. revision: yes
Circularity Check
No circularity: survey synthesizes literature without derivations or self-referential reductions
full rationale
This is a survey paper that reviews and categorizes existing research on scaling dimensions for LLM reasoning (input size, reasoning steps, rounds, training). It contains no equations, fitted parameters, predictions, or derivation chains that could reduce to quantities defined by its own inputs. Central claims about complexity and negative impacts are presented as syntheses of prior work rather than self-defined results. No self-citation load-bearing steps, uniqueness theorems, or ansatzes appear that would create circularity by the paper's own structure. The taxonomy is offered as an organizational framework, not as a mathematically forced partition.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 2 Pith papers
-
Towards Reasoning Era: A Survey of Long Chain-of-Thought for Reasoning Large Language Models
The paper unifies perspectives on Long CoT in reasoning LLMs by introducing a taxonomy, detailing characteristics of deep reasoning and reflection, and discussing emergence phenomena and future directions.
-
A Survey of Context Engineering for Large Language Models
The survey organizes Context Engineering into retrieval, processing, management, and integrated systems like RAG and multi-agent setups while identifying an asymmetry where LLMs handle complex inputs well but struggle...
Reference graph
Works this paper leans on
-
[1]
Amirhesam Abedsoltan, Adityanarayanan Radhakrishnan, Jingfeng Wu, and Mikhail Belkin. 2024. Context-Scaling versus Task-Scaling in In-Context Learn- ing. arXiv e-prints (2024), arXiv–2410
work page 2024
-
[2]
Rishabh Agarwal, Avi Singh, Lei Zhang, Bernd Bohnet, Luis Rosias, Stephanie Chan, Biao Zhang, Ankesh Anand, Zaheer Abbas, Azade Nova, et al. 2024. Many- shot in-context learning. Advances in Neural Information Processing Systems 37 (2024), 76930–76966
work page 2024
-
[3]
Arash Ahmadian, Chris Cremer, Matthias Gallé, Marzieh Fadaee, Julia Kreutzer, Olivier Pietquin, Ahmet Üstün, and Sara Hooker. 2024. Back to basics: Revisiting reinforce style optimization for learning from human feedback in llms. arXiv preprint arXiv:2402.14740 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [4]
-
[5]
Dario Amodei, Chris Olah, Jacob Steinhardt, Paul Christiano, John Schul- man, and Dan Mané. 2016. Concrete problems in AI safety. arXiv preprint arXiv:1606.06565 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
- [6]
-
[7]
Jeesoo Bang, Hyungjong Noh, Yonghee Kim, and Gary Geunbae Lee. 2015. Example-based chat-oriented dialogue system with personalized long-term memory. In 2015 International Conference on Big Data and Smart Computing (BIGCOMP). IEEE, 238–243
work page 2015
- [8]
-
[9]
Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Ruther- ford, Katie Millican, George Bm Van Den Driessche, Jean-Baptiste Lespiau, Bog- dan Damoc, Aidan Clark, et al. 2022. Improving language models by retrieving from trillions of tokens. In International conference on machine learning . PMLR, 2206–2240
work page 2022
-
[10]
Dana Brin, Vera Sorin, Eli Konen, Girish Nadkarni, Benjamin S Glicksberg, and Eyal Klang. 2023. How large language models perform on the united states medical licensing examination: a systematic review. MedRxiv (2023), 2023–09
work page 2023
-
[11]
Bradley Brown, Jordan Juravsky, Ryan Ehrlich, Ronald Clark, Quoc V Le, Christo- pher Ré, and Azalia Mirhoseini. 2024. Large language monkeys: Scaling inference compute with repeated sampling. arXiv preprint arXiv:2407.21787 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners. Advances in neural information processing systems 33 (2020), 1877–1901
work page 2020
- [13]
- [14]
-
[15]
Bei Chen, Gaolei Li, Xi Lin, Zheng Wang, and Jianhua Li. 2024. BlockAgents: To- wards Byzantine-Robust LLM-Based Multi-Agent Coordination via Blockchain. In Proceedings of the ACM Turing A ward Celebration Conference-China 2024 . 187–192
work page 2024
-
[16]
Danqi Chen, Adam Fisch, Jason Weston, and Antoine Bordes. 2017. Reading wikipedia to answer open-domain questions. arXiv preprint arXiv:1704.00051 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[17]
Junying Chen, Zhenyang Cai, Ke Ji, Xidong Wang, Wanlong Liu, Rongsheng Wang, Jianye Hou, and Benyou Wang. 2024. Huatuogpt-o1, towards medical complex reasoning with llms. arXiv preprint arXiv:2412.18925 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [18]
-
[19]
Minze Chen, Zhenxiang Tao, Weitong Tang, Tingxin Qin, Rui Yang, and Chunli Zhu. 2024. Enhancing emergency decision-making with knowledge graphs and large language models. International Journal of Disaster Risk Reduction 113 (2024), 104804
work page 2024
-
[20]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. 2021. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [21]
-
[22]
Xingyu Chen, Jiahao Xu, Tian Liang, Zhiwei He, Jianhui Pang, Dian Yu, Lin- feng Song, Qiuzhi Liu, Mengfei Zhou, Zhuosheng Zhang, et al. 2024. Do not think that much for 2+ 3=? on the overthinking of o1-like llms. arXiv preprint arXiv:2412.21187 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [23]
- [24]
-
[25]
Zeming Chen, Alejandro Hernández Cano, Angelika Romanou, Antoine Bonnet, Kyle Matoba, Francesco Salvi, Matteo Pagliardini, Simin Fan, Andreas Köpf, Amirkeivan Mohtashami, et al. 2023. Meditron-70b: Scaling medical pretraining for large language models. arXiv preprint arXiv:2311.16079 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Zihan Chen, Song Wang, Cong Shen, and Jundong Li. 2024. FastGAS: Fast Graph-based Annotation Selection for In-Context Learning. In Findings of the Association for Computational Linguistics ACL 2024 . 9764–9780
work page 2024
-
[27]
Zhaorun Chen, Zhen Xiang, Chaowei Xiao, Dawn Song, and Bo Li. 2024. Agent- poison: Red-teaming llm agents via poisoning memory or knowledge bases. Advances in Neural Information Processing Systems 37 (2024), 130185–130213
work page 2024
- [28]
- [29]
-
[30]
Tianzhe Chu, Yuexiang Zhai, Jihan Yang, Shengbang Tong, Saining Xie, Dale Schuurmans, Quoc V Le, Sergey Levine, and Yi Ma. 2025. Sft memorizes, rl generalizes: A comparative study of foundation model post-training. arXiv preprint arXiv:2501.17161 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, et al
-
[32]
Journal of Machine Learning Research 25, 70 (2024), 1–53
Scaling instruction-finetuned language models. Journal of Machine Learning Research 25, 70 (2024), 1–53
work page 2024
-
[33]
Gianluca Demartini, Stefano Mizzaro, and Damiano Spina. 2020. Human-in-the- loop Artificial Intelligence for Fighting Online Misinformation: Challenges and Opportunities. IEEE Data Eng. Bull. 43, 3 (2020), 65–74. Conference acronym ’XX, June 03–05, 2018, Woodstock, NY Trovato et al
work page 2020
- [34]
-
[35]
Dr S Rama Devi, Ommi U CH BhagyaSri, R Sravanthi, SL Chaitrika, MN Priyanka, M Swarna, and M Srilekha. 2024. AI-Enhanced Cursor Navigator. R. and Chaitrika, SL and Priyanka, MN and Swarna, M. and Srilekha, M., AI-Enhanced Cursor Navigator (May 10, 2024) (2024)
work page 2024
-
[36]
Shehzaad Dhuliawala, Mojtaba Komeili, Jing Xu, Roberta Raileanu, Xian Li, Asli Celikyilmaz, and Jason Weston. 2024. Chain-of-Verification Reduces Hallucina- tion in Large Language Models. In Findings of the Association for Computational Linguistics ACL 2024. 3563–3578
work page 2024
- [37]
-
[38]
Kefan Dong and Tengyu Ma. 2025. STP: Self-play LLM Theorem Provers with Iterative Conjecturing and Proving. arXiv e-prints (2025), arXiv–2502
work page 2025
-
[39]
Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Jingyuan Ma, Rui Li, Heming Xia, Jingjing Xu, Zhiyong Wu, Baobao Chang, et al. 2024. A Survey on In-context Learning. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 1107–1128
work page 2024
-
[40]
Vitor Gaboardi dos Santos, Guto Leoni Santos, Theo Lynn, and Boualem Bena- tallah. 2024. Identifying citizen-related issues from social media using llm-based data augmentation. In International Conference on Advanced Information Systems Engineering. Springer, 531–546
work page 2024
-
[41]
Yilun Du, Shuang Li, Antonio Torralba, Joshua B Tenenbaum, and Igor Mor- datch. 2023. Improving factuality and reasoning in language models through multiagent debate. In Forty-first International Conference on Machine Learning
work page 2023
- [42]
- [43]
- [44]
- [45]
- [46]
-
[47]
Álvaro García-Barragán, Alberto González Calatayud, Lucía Prieto-Santamaría, Víctor Robles, Ernestina Menasalvas, and Alejandro Rodríguez. 2024. Step- forward structuring disease phenotypic entities with LLMs for disease under- standing. In 2024 IEEE 37th International Symposium on Computer-Based Medical Systems (CBMS). IEEE, 213–218
work page 2024
-
[48]
Jonas Geiping, Sean McLeish, Neel Jain, John Kirchenbauer, Siddharth Singh, Brian R Bartoldson, Bhavya Kailkhura, Abhinav Bhatele, and Tom Goldstein
-
[49]
Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach
Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach. arXiv preprint arXiv:2502.05171 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
Ethan Goh, Robert Gallo, Jason Hom, Eric Strong, Yingjie Weng, Hannah Kerman, Joséphine A Cool, Zahir Kanjee, Andrew S Parsons, Neera Ahuja, et al. 2024. Large language model influence on diagnostic reasoning: a randomized clinical trial. JAMA Network Open 7, 10 (2024), e2440969–e2440969
work page 2024
-
[51]
Zhibin Gou, Zhihong Shao, Yeyun Gong, Yelong Shen, Yujiu Yang, Nan Duan, and Weizhu Chen. 2023. Critic: Large language models can self-correct with tool-interactive critiquing. arXiv preprint arXiv:2305.11738 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[52]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al . 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[54]
Large Language Model based Multi-Agents: A Survey of Progress and Challenges
Taicheng Guo, Xiuying Chen, Yaqi Wang, Ruidi Chang, Shichao Pei, Nitesh V. Chawla, Olaf Wiest, and Xiangliang Zhang. 2024. Large Language Model based Multi-Agents: A Survey of Progress and Challenges. arXiv:2402.01680 [cs.CL] https://arxiv.org/abs/2402.01680
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[55]
Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Mingwei Chang
-
[56]
In International confer- ence on machine learning
Retrieval augmented language model pre-training. In International confer- ence on machine learning . PMLR, 3929–3938
-
[57]
Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason Weston, and Yuandong Tian. 2024. Training large language models to reason in a continuous latent space. arXiv preprint arXiv:2412.06769 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [58]
-
[59]
Tiantian He, An Zhao, Elinor Thompson, Anna Schroder, Ahmed Abdulaal, Frederik Barkhof, and Daniel C Alexander. [n. d.]. LLM-guided spatio-temporal disease progression modelling. ([n. d.])
- [60]
-
[61]
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Ceyao Zhang, Jinlin Wang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and Jürgen Schmidhuber. 2023. MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework. arXiv:2308.00352 [cs.AI] https://arxiv.org/abs/2308.00352
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [62]
-
[63]
Jian Hu. 2025. REINFORCE++: A Simple and Efficient Approach for Aligning Large Language Models. arXiv preprint arXiv:2501.03262 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [64]
-
[65]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al
-
[66]
Openai o1 system card. arXiv preprint arXiv:2412.16720 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[67]
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. 2023. Survey of hallucination in natural language generation. ACM computing surveys 55, 12 (2023), 1–38
work page 2023
- [68]
- [69]
-
[70]
Juyong Jiang, Fan Wang, Jiasi Shen, Sungju Kim, and Sunghun Kim. 2024. A survey on large language models for code generation. arXiv preprint arXiv:2406.00515 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [71]
-
[73]
Zhengbao Jiang, Frank F Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig. 2023. Active retrieval aug- mented generation. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing . 7969–7992
work page 2023
-
[74]
Kartheek Kalluri. 2024. Scalable fine-tunning strategies for llms in finance domain-specific application for credit union
work page 2024
-
[75]
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. 2020. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[76]
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick SH Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense Passage Retrieval for Open-Domain Question Answering.. In EMNLP (1). 6769–6781
work page 2020
- [77]
-
[78]
Akbir Khan, John Hughes, Dan Valentine, Laura Ruis, Kshitij Sachan, Ansh Radhakrishnan, Edward Grefenstette, Samuel R Bowman, Tim Rocktäschel, and Ethan Perez. 2024. Debating with more persuasive LLMs leads to more truthful answers. In Proceedings of the 41st International Conference on Machine Learning . 23662–23733
work page 2024
-
[79]
Gangwoo Kim, Sungdong Kim, Byeongguk Jeon, Joonsuk Park, and Jaewoo Kang
-
[80]
In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing
Tree of clarifications: Answering ambiguous questions with retrieval- augmented large language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing . 996–1009
work page 2023
- [81]
-
[82]
Hyuhng Joon Kim, Hyunsoo Cho, Junyeob Kim, Taeuk Kim, Kang Min Yoo, and Sang-goo Lee. 2022. Self-generated in-context learning: Leveraging auto- regressive language models as a demonstration generator. arXiv preprint A Survey of Scaling in Large Language Model Reasoning Conference acronym ’XX, June 03–05, 2018, Woodstock, NY arXiv:2206.08082 (2022)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.