Neural Mean-Field Games: Extending Mean-Field Game Theory with Neural Stochastic Differential Equations
Pith reviewed 2026-05-22 19:09 UTC · model grok-4.3
The pith
Neural stochastic differential equations extend mean-field game theory to learn strategic interactions directly from data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Neural mean-field games combine mean-field game theory with neural stochastic differential equations to produce a data-driven, lightweight model that learns extensive strategic interactions from observations, using automatic differentiation to improve robustness over finite-difference methods while solving games of varying complexity and simulating viral dynamics on real data.
What carries the argument
Neural stochastic differential equations that parameterize the dynamics of player distributions in mean-field games and are trained end-to-end via automatic differentiation on observed trajectories.
If this is right
- The model solves mean-field games that differ in complexity, observability, and noise levels.
- It accurately reproduces epidemic outbreak evolution when trained on real-world viral data.
- It learns the data distribution using few observations.
- Automatic differentiation makes the method more robust and objective than finite-difference alternatives.
Where Pith is reading between the lines
- The same neural-SDE construction could be tested on other large-population systems such as traffic or financial markets where analytical mean-field solutions are unavailable.
- If the learned models preserve solution existence and uniqueness in practice, they could serve as a practical workaround for cases where classical mean-field theory breaks down.
- A direct comparison on synthetic data with injected noise would quantify how much the neural approach reduces modeling bias relative to hand-specified interaction functions.
Load-bearing premise
That neural SDEs trained on limited observations can recover the true underlying strategic interactions and distributions without introducing new modeling bias or losing the existence and uniqueness properties of classical mean-field solutions.
What would settle it
Run the trained neural model on a simple mean-field game with a known closed-form analytical solution and check whether the learned distribution and interaction terms match the analytical result within a small error margin.
Figures







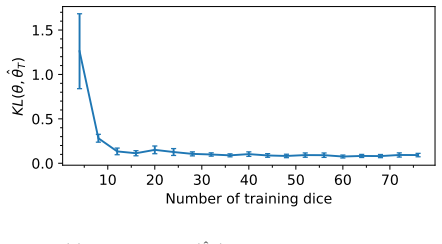


read the original abstract
Mean-field game theory relies on approximating games that are intractable to model due to a very large to infinite population of players. While these kinds of games can be solved analytically via the associated system of partial derivatives, this approach is not model-free, can lead to the loss of the existence or uniqueness of solutions, and may suffer from modelling bias. To reduce the dependency between the model and the game, we introduce neural mean-field games: a combination of mean-field game theory and deep learning in the form of neural stochastic differential equations. The resulting model is data-driven, lightweight, and can learn extensive strategic interactions that are hard to capture using mean-field theory alone. In addition, the model is based on automatic differentiation, making it more robust and objective than approaches based on finite differences. We highlight the efficiency and flexibility of our approach by solving two mean-field games that vary in their complexity, observability, and the presence of noise. Lastly, we illustrate the model's robustness by simulating viral dynamics based on real-world data. Here, we demonstrate that the model's ability to learn from real-world data helps to accurately model the evolution of an epidemic outbreak. Using these results, we show that the model is flexible, generalizable, and requires few observations to learn the distribution underlying the data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces neural mean-field games by combining classical mean-field game (MFG) theory with neural stochastic differential equations (SDEs). The central claim is that this data-driven framework, trained via automatic differentiation on observations, yields a lightweight model that learns strategic interactions while avoiding the modeling bias, loss of existence/uniqueness, and analytical intractability of the classical coupled HJB-Fokker-Planck system. The approach is illustrated on two synthetic MFGs of varying complexity and on real epidemic data, with claims of robustness, generalizability, and the ability to learn from few observations.
Significance. If the neural SDE construction can be shown to recover a valid MFG equilibrium (i.e., a measure flow consistent with best-response optimality), the method would offer a practical route to data-driven MFG modeling in settings where analytical solutions are unavailable. The use of automatic differentiation and limited-data training are potentially useful strengths, but the significance hinges on whether the learned dynamics preserve the game-theoretic fixed-point condition rather than merely matching observed marginals.
major comments (3)
- [Abstract and §3 (method description)] The manuscript replaces the classical HJB-Fokker-Planck fixed-point system with a generic neural SDE trained by auto-diff on trajectories, yet provides no derivation or verification that the learned drift and interaction terms satisfy the best-response optimality condition required for an MFG equilibrium. Without this link, the model may fit observed distributions without solving the underlying game.
- [§4 (synthetic experiments) and §5 (epidemic application)] The claims of robustness and avoidance of existence/uniqueness issues rest on the neural SDE being a faithful proxy for the MFG; however, no analysis (e.g., via fixed-point residual, optimality gap, or comparison to a known analytical equilibrium) is presented to confirm that the trained model satisfies the MFG equilibrium definition rather than producing a non-equilibrium trajectory fit.
- [§5] The epidemic example uses real-world data to demonstrate learning from few observations, but lacks controls (e.g., comparison to a classical MFG fit or ablation on observation density) that would isolate whether the neural component recovers strategic interaction parameters or simply interpolates marginal statistics.
minor comments (2)
- [§3] Notation for the neural SDE drift and diffusion terms should be explicitly related to the classical MFG interaction kernel to clarify the modeling assumptions.
- [§4] Figure captions for the synthetic games should include the ground-truth equilibrium measure or value function for visual comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments. We address each major point below and outline revisions to strengthen the manuscript's connection to mean-field game equilibria while preserving the data-driven focus of the work.
read point-by-point responses
-
Referee: [Abstract and §3 (method description)] The manuscript replaces the classical HJB-Fokker-Planck fixed-point system with a generic neural SDE trained by auto-diff on trajectories, yet provides no derivation or verification that the learned drift and interaction terms satisfy the best-response optimality condition required for an MFG equilibrium. Without this link, the model may fit observed distributions without solving the underlying game.
Authors: We agree that explicit verification of best-response optimality is valuable. Our framework is intentionally data-driven: observed trajectories are treated as samples from an underlying MFG equilibrium, and the neural SDE learns the effective drift and interaction kernel that reproduce the empirical measure flow. In the revised version we will add a dedicated subsection in §3 deriving the link under the assumption that training data arise from equilibrium play, together with a numerical check of the fixed-point residual on the synthetic examples where analytical equilibria are available. revision: yes
-
Referee: [§4 (synthetic experiments) and §5 (epidemic application)] The claims of robustness and avoidance of existence/uniqueness issues rest on the neural SDE being a faithful proxy for the MFG; however, no analysis (e.g., via fixed-point residual, optimality gap, or comparison to a known analytical equilibrium) is presented to confirm that the trained model satisfies the MFG equilibrium definition rather than producing a non-equilibrium trajectory fit.
Authors: We acknowledge the absence of these diagnostics. For the synthetic games in §4 we will report both the fixed-point residual and an optimality-gap metric obtained by comparing the learned policy against the known best-response operator. These additions will directly test whether the trained neural SDE recovers an equilibrium rather than an arbitrary trajectory fit, thereby supporting the robustness claims. revision: yes
-
Referee: [§5] The epidemic example uses real-world data to demonstrate learning from few observations, but lacks controls (e.g., comparison to a classical MFG fit or ablation on observation density) that would isolate whether the neural component recovers strategic interaction parameters or simply interpolates marginal statistics.
Authors: We will add an ablation study varying the number of observations and a comparison against a non-strategic neural-SDE baseline (interaction kernel set to zero) to isolate the contribution of the learned strategic terms. A direct comparison to a classical analytic MFG is infeasible on real epidemic data precisely because of the modeling bias and intractability that motivate the neural approach; we will clarify this limitation in the revised text. revision: partial
Circularity Check
No circularity: neural SDE framework is a distinct modeling proposal, not a reduction to inputs
full rationale
The paper proposes neural mean-field games as a data-driven alternative that replaces the classical coupled HJB-Fokker-Planck system with a neural SDE trained by automatic differentiation on observations. No derivation step is shown to reduce by construction to the same inputs (e.g., no fitted parameter is relabeled as a prediction of equilibrium, and no uniqueness theorem is imported from self-citation). The abstract and described approach emphasize empirical flexibility and robustness on synthetic games and epidemic data rather than a closed mathematical loop. The central claim therefore remains self-contained as an extension rather than an equivalence.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Neural SDEs can represent the mean-field interaction dynamics without loss of solution existence or uniqueness.
invented entities (1)
-
Neural mean-field game
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we introduce neural mean-field games: a combination of mean-field game theory and deep learning in the form of neural stochastic differential equations... based on automatic differentiation, making it more robust... than approaches based on finite differences
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the Nash equilibrium is a fixed point in the space of the flow in m... solved by numerically solving the partial or stochastic differential equations
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Mean field games: Numerical methods.SIAM Journal on Numerical Analysis, 48(3):1136–1162, 2010
Yves Achdou and Italo Capuzzo-Dolcetta. Mean field games: Numerical methods.SIAM Journal on Numerical Analysis, 48(3):1136–1162, 2010. doi:10.1137/090758477
-
[2]
Mean Field Games and Applications: Numerical Aspects, 2020
Yves Achdou and Mathieu Lauri` ere. Mean Field Games and Applications: Numerical Aspects, 2020. URLhttps://arxiv. org/abs/2003.04444
-
[3]
Mean field games: convergence of a finite difference method,
Yves Achdou, Fabio Camilli, and Italo Capuzzo Dolcetta. Mean field games: convergence of a finite difference method,
-
[4]
URLhttps://arxiv.org/abs/1207.2982
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Springer, Heidelberg, Germany, 2019
Yves Achdou, Pierre Cardaliaguet, Fran¸ cois Delarue, Alessio Porretta, and Filippo Santambrogio.Mean Field Games, volume 2281. Springer, Heidelberg, Germany, 2019. doi:10.1007/978-3-030-59837-2
-
[6]
Yves Achdou, Jiequn Han, Jean-Michel Lasry, Pierre-Louis Lions, and Benjamin Moll. Income and Wealth Distribution in Macroeconomics: A Continuous-Time Approach.The Review of Economic Studies, 89(1):45–86, 04 2021. ISSN 0034-6527. doi:10.1093/restud/rdab002
-
[7]
Adams and Christopher Essex.Calculus: A Com- plete Course
Robert A. Adams and Christopher Essex.Calculus: A Com- plete Course. Pearson, Ontario, 8 edition, 2013. ISBN 978-0- 32-178107-9
work page 2013
-
[8]
J. McKenzie Alexander. Evolutionary Game Theory. In Edward N. Zalta, editor,The Stanford Encyclope- dia of Philosophy. Metaphysics Research Lab, Stanford University, Stanford, CA, Summer 2021 edition, 2021. doi:10.1017/9781108582063
-
[9]
Q- Learning in Regularized Mean-field Games.Dynamic Games and Applications, 13(1):89–117, 2023
Berkay Anahtarci, Can Deha Kariksiz, and Naci Saldi. Q- Learning in Regularized Mean-field Games.Dynamic Games and Applications, 13(1):89–117, 2023. doi:10.1007/s13235- 022-00450-2
- [10]
-
[11]
Mouhcine Assouli and Badr Missaoui. Deep learning for Mean Field Games with non-separable Hamiltonians.Chaos, Solitons & Fractals, 174:113802, 2023. ISSN 0960-0779. doi:10.1016/j.chaos.2023.113802
-
[12]
Mouhcine Assouli and Badr Missaoui. Deep Policy Iteration for high-dimensional mean field games.Applied Mathemat- ics and Computation, 481:128923, 2024. ISSN 0096-3003. doi:10.1016/j.amc.2024.128923
-
[13]
Robert J. Aumann and Lloyd S. Shapley.Values of non- atomic games. Princeton University Press, Princeton, NJ,
-
[14]
doi:10.1515/9781400867080
-
[15]
Alexander Aurell and Boualem Djehiche. Modeling tagged pedestrian motion: A mean-field type game approach.Trans- portation Research Part B: Methodological, 121:168–183,
-
[16]
ISSN 0191-2615. doi:10.1016/j.trb.2019.01.011
-
[17]
The DeepMind JAX Ecosystem, 2020
Igor Babuschkin, Kate Baumli, Alison Bell, Surya Bhupati- raju, Jake Bruce, Peter Buchlovsky, David Budden, Trevor Cai, Aidan Clark, Ivo Danihelka, Antoine Dedieu, Claudio Fantacci, Jonathan Godwin, Chris Jones, Ross Hemsley, Tom Hennigan, Matteo Hessel, Shaobo Hou, Steven Kapturowski, Thomas Keck, Iurii Kemaev, Michael King, Markus Kunesch, Lena Martens,...
work page 2020
-
[18]
Rani Basna, Astrid Hilbert, and Vassili N Kolokoltsov. An epsilon-Nash equilibrium for non-linear Markov games of mean-field-type on finite spaces.Communications on Stochas- tic Analysis, 8(4):449–468, 2014. doi:10.31390/cosa.8.4.02
-
[19]
A Markovian decision process.Jour- nal of mathematics and mechanics, 6(5):679–684, 1957
Richard Bellman. A Markovian decision process.Jour- nal of mathematics and mechanics, 6(5):679–684, 1957. doi:10.1512/IUMJ.1957.6.56038
-
[20]
Daniel Biles and Paul Binding. On carath´ eodory’s conditions for the initial value problem.Proceedings of the American Mathematical Society, 125, 01 1997. doi:10.1090/S0002-9939- 97-03942-7
-
[21]
Luis Brice˜ no-Arias, Dante Kalise, Ziad Kobeissi, Mathieu Lauri` ere,´Alvaro Mateos Gonz´ alez, and Francisco Silva. On the implementation of a primal-dual algorithm for second order time-dependent Mean Field Games with local cou- plings.ESAIM: Proceedings and Surveys, 65:330–348, 01
-
[22]
doi:10.1051/proc/201965330
-
[23]
PhD thesis, School of Com- puter Science, Carnegie Mellon University, 2020
Noam Brown.Equilibrium Finding for Large Adversarial Imperfect-Information Games. PhD thesis, School of Com- puter Science, Carnegie Mellon University, 2020
work page 2020
-
[24]
John Wiley & Sons, Chich- ester, United Kingdom, 2016
John Charles Butcher.Numerical Methods for Ordi- nary Differential Equations. John Wiley & Sons, Chich- ester, United Kingdom, 2016. ISBN 9781119121534. doi:10.1002/9781119121534
-
[25]
Notes on Mean Field Games, 09 2013
Pierre Cardaliaguet. Notes on Mean Field Games, 09 2013
work page 2013
-
[26]
An introduction to Mean Field Game theory
Pierre Cardaliaguet and Alessio Porretta. An introduction to Mean Field Game theory. InMean Field Games: Cetraro, Italy 2019, pages 1–158. Springer, Heidelberg, Germany, 2021. 7
work page 2019
-
[27]
Ren´ e Carmona and Fran¸ cois Delarue. Probabilistic analysis of mean-field games.SIAM Journal on Control and Optimiza- tion, 51(4):2705–2734, 2013. doi:10.1137/120883499
-
[28]
Ren´ e Carmona and Mathieu Lauri` ere. Convergence Analy- sis of Machine Learning Algorithms for the Numerical Solu- tion of Mean Field Control and Games I: The Ergodic Case. SIAM Journal on Numerical Analysis, 59(3):1455–1485, 2021. doi:10.1137/19M1274377
-
[29]
Rene Carmona and Mathieu Lauri` ere. Convergence analysis of machine learning algorithms for the numerical solution of mean field control and games: II—the finite horizon case.The Annals of Applied Probability, 32, 12 2022. doi:10.1214/21- AAP1715
work page doi:10.1214/21- 2022
-
[30]
Springer Nature, Heidelberg, Germany, 3 2018
Ren´ e Carmona, Fran¸ cois Delarue, et al.Probabilistic Theory of Mean Field Games with Applications I-II. Springer Nature, Heidelberg, Germany, 3 2018. ISBN 978-3-319-56437-1
work page 2018
-
[31]
Alekos Cecchin and Markus Fischer. Probabilistic Approach to Finite State Mean Field Games.Applied Mathemat- ics & Optimization, 81(2):253–300, 2020. ISSN 1432-0606. doi:10.1007/s00245-018-9488-7
-
[32]
Ricky T. Q. Chen, Yulia Rubanova, Jesse Bettencourt, and David K. Duvenaud. Neural ordinary differential equations. Advances in Neural Information Processing Systems, 31,
-
[33]
doi:10.48550/arXiv.1806.07366
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1806.07366
-
[34]
Mean-Field Games with Explicit Interactions.Preprint hal-01277098,
Josu Doncel, Nicolas Gast, and Bruno Gaujal. Mean-Field Games with Explicit Interactions.Preprint hal-01277098,
-
[35]
URLhttps://inria.hal.science/hal-01277098v1. working paper or preprint
-
[36]
Josu Doncel, Nicolas Gast, and Bruno Gaujal. Discrete mean field games: Existence of equilibria and convergence.Journal of Dynamics and Games, 6(3):221–239, 2019. ISSN 2164-
work page 2019
-
[37]
doi:10.3934/jdg.2019016
-
[38]
Josu Doncel, Nicolas Gast, and Bruno Gaujal. A Mean Field Game analysis of SIR dynamics with Vaccination.Probabil- ity in the Engineering and Informational Sciences, 36(2):482– 499, 2022
work page 2022
-
[39]
Cambridge university press, Cambridge, UK, 2010
David Easley, Jon Kleinberg, et al.Networks, crowds, and markets: Reasoning about a highly connected world, vol- ume 1. Cambridge university press, Cambridge, UK, 2010. doi:10.1017/CBO9780511761942
-
[40]
Noufel Frikha, Maximilien Germain, Mathieu Lauri` ere, Huyˆ en Pham, and Xuanye Song. Actor-critic learning for mean-field control in continuous time.Journal of Machine Learning Re- search, 26(127):1–42, 2025
work page 2025
-
[41]
Implementing the nelder-mead simplex algorithm with adaptive parameters.Comput
Fuchang Gao and Lixing Han. Implementing the nelder- mead simplex algorithm with adaptive parameters.Compu- tational Optimization and Applications, 51(1):259–277, 2012. ISSN 1573-2894. doi:10.1007/s10589-010-9329-3. URLhttps: //doi.org/10.1007/s10589-010-9329-3
-
[42]
Princeton University Press, Princeton, NJ, 1992
Robert Gibbons.Game Theory for Applied Economists. Princeton University Press, Princeton, NJ, 1992. ISBN 9780691003955
work page 1992
-
[43]
Gomes, Joana Mohr, and Rafael Rig˜ ao Souza
Diogo A. Gomes, Joana Mohr, and Rafael Rig˜ ao Souza. Con- tinuous Time Finite State Mean Field Games.Applied Mathe- matics & Optimization, 68(1):99–143, 2013. ISSN 1432-0606. doi:10.1007/s00245-013-9202-8
-
[44]
Mean Field Games and Applications, pages 205–266
Olivier Gu´ eant, Jean-Michel Lasry, and Pierre-Louis Lions. Mean Field Games and Applications, pages 205–266. Springer Berlin Heidelberg, Berlin, Heidelberg, 2011. ISBN 978-3-642- 14660-2. doi:10.1007/978-3-642-14660-2 3
-
[45]
A cross-country database of covid-19 testing.Scientific Data, 7(1):345, 2020
Joe Hasell, Edouard Mathieu, Diana Beltekian, Bobbie Mac- donald, Charlie Giattino, Esteban Ortiz-Ospina, Max Roser, and Hannah Ritchie. A cross-country database of covid-19 testing.Scientific Data, 7(1):345, 2020. ISSN 2052-4463. doi:10.1038/s41597-020-00688-8. URLhttps://doi.org/10. 1038/s41597-020-00688-8
-
[46]
Deep residual learning for image recognition,
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep Residual Learning for Image Recognition. In2016 IEEE Conference on Computer Vision and Pattern Recogni- tion (CVPR), pages 770–778, Cambridge, Boston, MA, 2016. IEEE. doi:10.1109/CVPR.2016.90
-
[47]
Minyi Huang, Roland P. Malham´ e, and Peter E. Caines. Large population stochastic dynamic games: closed-loop McKean- Vlasov systems and the Nash certainty equivalence principle. Communications in Information & Systems, 6(3):221 – 252,
-
[48]
doi:10.4310/CIS.2006.v6.n3.a5
-
[49]
Junteng Jia and Austin R Benson. Neural Jump Stochastic Differential Equations.Advances in Neural Information Pro- cessing Systems, 32, 2019
work page 2019
-
[50]
Nonlinear sdes driven by l´ evy processes and related pdes,
Benjamin Jourdain, Sylvie M´ el´ eard, and Wojbor Woyczyn- ski. Nonlinear sdes driven by l´ evy processes and related pdes,
-
[51]
URLhttps://arxiv.org/abs/0707.2723
work page internal anchor Pith review Pith/arXiv arXiv
-
[52]
William Ogilvy Kermack, A. G. McKendrick, and Gilbert Thomas Walker. A contribution to the math- ematical theory of epidemics.Proceedings of the Royal Society of London. Series A, Containing Pa- pers of a Mathematical and Physical Character, 115 (772):700–721, 1927. doi:10.1098/rspa.1927.0118. URL https://royalsocietypublishing.org/doi/abs/10.1098/ rspa.1927.0118
-
[53]
PhD thesis, University of Oxford, 2021
Patrick Kidger.On Neural Differential Equations. PhD thesis, University of Oxford, 2021
work page 2021
-
[54]
Patrick Kidger and Cristian Garcia. Equinox: neural net- works in JAX via callable PyTrees and filtered transforma- tions.Differentiable Programming workshop at Neural Infor- mation Processing Systems 2021, 2021
work page 2021
-
[55]
Efficient and Accurate Gradients for Neural SDEs
Patrick Kidger, James Foster, Xuechen Li, and Terry Lyons. Efficient and Accurate Gradients for Neural SDEs. InAd- vances in Neural Information Processing Systems 34. Curran Associates, Inc., 2021
work page 2021
-
[56]
Kolokoltsov.Nonlinear Markov Processes and Kinetic Equations
Vassili N. Kolokoltsov.Nonlinear Markov Processes and Kinetic Equations. Cambridge Tracts in Mathematics. Cambridge University Press, Cambridge, 2010. ISBN 9780521111843. doi:10.1017/CBO9780511760303
-
[57]
Laetitia Laguzet and Gabriel Turinici. Individual Vaccination as Nash Equilibrium in a SIR Model with Application to the 2009–2010 Influenza A (H1N1) Epidemic in France. Bulletin of Mathematical Biology, 77(10):1955–1984, 2015. ISSN 1522-9602. doi:10.1007/s11538-015-0111-7. URL https://doi.org/10.1007/s11538-015-0111-7https:// link.springer.com/article/10...
-
[58]
Jean-Michel Lasry and Pierre-Louis Lions. Jeux ` a champ moyen. i – le cas stationnaire.Comptes Rendus Mathematique, 343(9):619–625, 2006. ISSN 1631-073X. doi:https://doi.org/10.1016/j.crma.2006.09.019. URL https://www.sciencedirect.com/science/article/pii/ S1631073X06003682
-
[59]
Jean-Michel Lasry and Pierre-Louis Lions. Jeux ` a champ moyen. ii – horizon fini et contrˆ ole optimal.Comptes Rendus Mathematique, 343(10):679–684, 2006. ISSN 1631- 073X. doi:https://doi.org/10.1016/j.crma.2006.09.018. URL https://www.sciencedirect.com/science/article/pii/ S1631073X06003670
-
[60]
Mean Field Games.Japanese Journal of Mathematics, 2:229–260, 03
Jean-Michel Lasry and Pierre-Louis Lions. Mean Field Games.Japanese Journal of Mathematics, 2:229–260, 03
-
[61]
doi:10.1007/s11537-007-0657-8
-
[62]
Learning Mean Field Games: A Survey.arXiv, 05
Mathieu Lauri` ere, Sarah Perrin, Matthieu Geist, and Olivier Pietquin. Learning Mean Field Games: A Survey.arXiv, 05
-
[63]
doi:10.48550/arXiv.2205.12944
-
[64]
Continuous control with deep reinforcement learning
Timothy Lillicrap, Jonathan Hunt, Alexander Pritzel, Nicolas Heess, Tom Erez, Yuval Tassa, David Silver, and Daan Wier- stra. Continuous Control with Deep Reinforcement Learning. CoRR, 09 2015. doi:10.48550/arXiv.1509.02971
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1509.02971 2015
-
[65]
Alex Tong Lin, Samy Wu Fung, Wuchen Li, Levon Nurbekyan, and Stanley J. Osher. Alternating the population and control neural networks to solve high-dimensional stochastic mean- field games.Proceedings of the National Academy of Sciences, 118(31):e2024713118, 2021. doi:10.1073/pnas.2024713118
-
[66]
Neural SDE: Stabilizing Neural ODE Networks with Stochastic Noise
Xuanqing Liu, Tesi Xiao, Si Si, Qin Cao, Sanjiv Kumar, and Cho-Jui Hsieh. Neural SDE: Stabilizing Neural ODE Net- works with Stochastic Noise, 2019. URLhttps://arxiv.org/ abs/1906.02355
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[67]
Tchavdar T. Marinov and Rossitza S. Marinova. Adap- tive sir model with vaccination: simultaneous identifi- cation of rates and functions illustrated with covid-19. Scientific Reports, 12(1):15688, 2022. ISSN 2045-2322. doi:10.1038/s41598-022-20276-7. URLhttps://doi.org/10. 1038/s41598-022-20276-7
-
[68]
Covid-19 pandemic.Our World in Data, 2020
Edouard Mathieu, Hannah Ritchie, Lucas Rod´ es- Guirao, Cameron Appel, Daniel Gavrilov, Charlie Giattino, Joe Hasell, Bobbie Macdonald, Saloni Dat- tani, Diana Beltekian, Esteban Ortiz-Ospina, and Max Roser. Covid-19 pandemic.Our World in Data, 2020. https://ourworldindata.org/coronavirus. 8
work page 2020
-
[69]
Model-Free Reinforcement Learning for Mean Field Games
Rajesh Mishra, Deepanshu Vasal, and Sriram Vishwanath. Model-Free Reinforcement Learning for Mean Field Games. IEEE Transactions on Control of Network Systems, 10(4): 2141–2151, 2023. doi:10.1109/TCNS.2023.3264934
-
[70]
Infinitely deep neural networks as diffusion processes, 2020
Stefano Peluchetti and Stefano Favaro. Infinitely deep neural networks as diffusion processes, 2020. URLhttps://arxiv. org/abs/1905.11065
-
[71]
Mean Field Games Flock! The Reinforcement Learning Way
Sarah Perrin, Mathieu Lauri` ere, P´ erolat Julien, Matthieu Geist, Romuald Elie, and Olivier Pietquin. Mean Field Games Flock! The Reinforcement Learning Way. InPro- ceedings of the Thirtieth International Joint Conference on Artificial Intelligence (IJCAI-21), pages 356–362, 08 2021. doi:10.24963/ijcai.2021/50
-
[72]
Springer, Heidelberg, Germany, 2008
Hans Peters.Game Theory: A Multi-Leveled Approach. Springer, Heidelberg, Germany, 2008. ISBN 978-3-540-69290-
work page 2008
-
[73]
L.S. Pontryagin, E.F. Mishchenko, G.V. Boltyanskii, and R.V. Gamkrelidze.Mathematical Theory of Optimal Pro- cesses. Routledge, London, UK, 1962. ISBN 9782881240775. doi:10.1201/9780203749319
-
[74]
Universal Differential Equations for Scientific Machine Learning
Christopher Rackauckas, Yingbo Ma, Julius Martensen, Collin Warner, Kirill Zubov, Rohit Supekar, Dominic Skinner, Ali Ramadhan, and Alan Edelman. Universal differential equations for scientific machine learning.arXiv preprint arXiv:2001.04385, 2020. doi:10.48550/arXiv.2001.04385
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2001.04385 2001
-
[75]
Equilibrium Points of Non-Atomic Games.Journal of Statistical Physics, 7:295–300, May 1973
David Schmeidler. Equilibrium Points of Non-Atomic Games.Journal of Statistical Physics, 7:295–300, May 1973. doi:10.1007/BF01014905
-
[76]
J. Su and J. E. Renaud. Automatic Differentiation in Robust Optimization.AIAA Journal, 35(6):1072–1079, June 1997. doi:10.2514/2.196
-
[77]
Taylor, Mark Crowley, and Pascal Poupart
Sriram Ganapathi Subramanian, Matthew E. Taylor, Mark Crowley, and Pascal Poupart. Partially Observ- able Mean Field Reinforcement Learning. InProceed- ings of the 20th International Conference on Autonomous Agents and MultiAgent Systems, page 537–545, 2021. doi:10.48550/arXiv.2012.15791
-
[78]
The Japanese Ministry of Health, Labour and Welfare. Regarding the number of vaccinations of the new coronavirus vaccine during the special temporary vaccination period. https://www.mhlw.go.jp/stf/seisakunitsuite/bunya/ kenkou_iryou/kenkou/kekkaku-kansenshou/yobou-sesshu/ syukeihou_00002.html. Accessed on 12-08-2025
work page 2025
-
[79]
Belinda Tzen and Maxim Raginsky. Neural Stochastic Differ- ential Equations: Deep Latent Gaussian Models in the Diffu- sion Limit, 2019. URLhttps://arxiv.org/abs/1905.09883
-
[80]
Zejian Zhou and M. Sami Fadali and Hao Xu. Biomimetic Optimal Tracking Control using Mean Field Games and Spik- ing Neural Networks.IFAC-PapersOnLine, 53(2):8112–8117,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.