If Concept Bottlenecks are the Question, are Foundation Models the Answer?
Pith reviewed 2026-05-22 17:47 UTC · model grok-4.3
The pith
Vision-language models supply concept labels for bottleneck models that often differ from expert annotations and whose accuracy does not track their actual quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
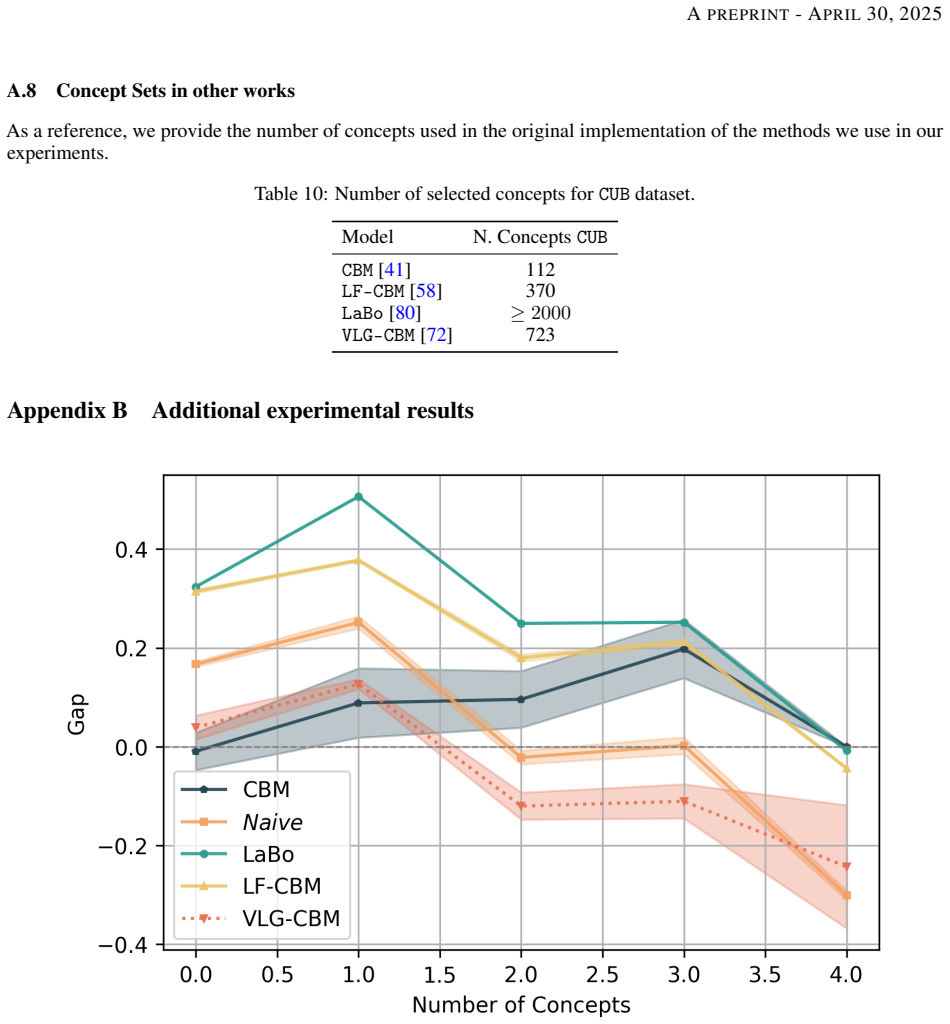
The authors evaluate several VLM-CBM architectures by comparing the concepts they learn under VLM supervision against those learned under expert supervision. They measure concept quality with a selection of established metrics and find that the two sources of supervision diverge substantially on some tasks while agreeing on others. In addition, they report that concept accuracy and the chosen quality metrics are not strongly correlated, implying that accuracy alone is an unreliable indicator of whether a concept will support good performance or clear explanations.
What carries the argument
The empirical comparison of VLM-supervised CBMs against expert-supervised CBMs using a battery of concept quality metrics.
If this is right
- Concept accuracy should not be used as the sole criterion when selecting or validating concepts in bottleneck models.
- VLM supervision may be adequate for some tasks but requires task-specific validation before it replaces expert labels.
- Quality metrics beyond accuracy become necessary to decide whether a VLM-CBM meets interpretability goals.
Where Pith is reading between the lines
- Designers of future CBMs may need to combine VLM and expert signals rather than treat them as interchangeable.
- The gap between VLM and expert concepts could be narrowed by more targeted prompting or fine-tuning of the foundation model on the target domain.
Load-bearing premise
The chosen metrics for concept quality give a valid and complete picture of what makes concepts useful for both task performance and interpretability.
What would settle it
A follow-up study in which the same models are evaluated with a different set of quality metrics or with direct human judgments of interpretability, and the new metrics reverse the ranking of VLM versus expert concepts.
Figures






read the original abstract
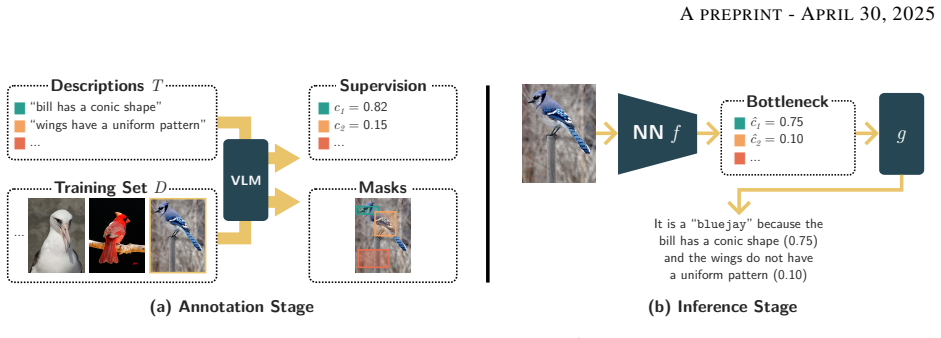
Concept Bottleneck Models (CBMs) are neural networks designed to conjoin high performance with ante-hoc interpretability. CBMs work by first mapping inputs (e.g., images) to high-level concepts (e.g., visible objects and their properties) and then use these to solve a downstream task (e.g., tagging or scoring an image) in an interpretable manner. Their performance and interpretability, however, hinge on the quality of the concepts they learn. The go-to strategy for ensuring good quality concepts is to leverage expert annotations, which are expensive to collect and seldom available in applications. Researchers have recently addressed this issue by introducing "VLM-CBM" architectures that replace manual annotations with weak supervision from foundation models. It is however unclear what is the impact of doing so on the quality of the learned concepts. To answer this question, we put state-of-the-art VLM-CBMs to the test, analyzing their learned concepts empirically using a selection of significant metrics. Our results show that, depending on the task, VLM supervision can sensibly differ from expert annotations, and that concept accuracy and quality are not strongly correlated. Our code is available at https://github.com/debryu/CQA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an empirical study on the use of Vision-Language Models (VLMs) for supervising Concept Bottleneck Models (CBMs) in place of expert annotations. The authors evaluate state-of-the-art VLM-CBM architectures across different tasks using multiple metrics for concept accuracy and quality. Key findings indicate that VLM supervision can differ from expert annotations in a task-dependent manner and that concept accuracy does not strongly correlate with the assessed concept quality.
Significance. Should the empirical results prove robust, this work underscores the challenges in replacing expert supervision with VLMs for CBMs and questions the adequacy of accuracy as a measure of concept quality. It contributes to the field by providing a comparative analysis and releasing code, which aids in assessing the practical utility of VLM-CBMs for interpretable machine learning.
major comments (1)
- [Empirical Analysis] The conclusion that concept accuracy and quality are not strongly correlated hinges on the chosen metrics providing a valid assessment of concept usefulness for CBM performance and interpretability. The manuscript should include analysis showing how these metrics correlate with downstream task accuracy or human-judged interpretability to rule out the possibility that the observed lack of correlation is due to metric selection rather than an inherent property of VLM supervision.
minor comments (1)
- [Abstract] The phrase 'a selection of significant metrics' is vague; specifying the metrics or pointing to the relevant section would improve clarity for readers.
Simulated Author's Rebuttal
We are grateful to the referee for the positive assessment of our work and the detailed feedback. Below we provide a point-by-point response to the major comment.
read point-by-point responses
-
Referee: [Empirical Analysis] The conclusion that concept accuracy and quality are not strongly correlated hinges on the chosen metrics providing a valid assessment of concept usefulness for CBM performance and interpretability. The manuscript should include analysis showing how these metrics correlate with downstream task accuracy or human-judged interpretability to rule out the possibility that the observed lack of correlation is due to metric selection rather than an inherent property of VLM supervision.
Authors: We appreciate this suggestion, which helps strengthen the validity of our conclusions. In the original manuscript, we selected metrics based on established practices in the CBM literature to assess concept quality in terms of their alignment with semantic meaning and contribution to interpretability. To address the referee's concern directly, we will add a new analysis in the revised manuscript that examines the correlation between our quality metrics and the downstream task accuracy for each VLM-CBM architecture and task. This will provide evidence that the observed weak correlation between concept accuracy and quality metrics reflects a genuine property rather than a limitation of the metrics. We note that conducting human-judged interpretability studies would require additional resources and participant recruitment, which we did not perform in the current work; however, we will expand the discussion to acknowledge this and suggest it as future work. revision: partial
Circularity Check
No circularity: purely empirical comparison against external annotations
full rationale
The paper performs direct empirical evaluation of VLM-CBM concept quality against expert annotations and independent metrics on multiple tasks. No derivations, fitted parameters renamed as predictions, self-citation load-bearing premises, or ansatzes appear in the reported results. All claims rest on observable differences between VLM outputs and held-out expert labels, making the analysis self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Expert annotations represent a reliable ground-truth benchmark for evaluating the quality of learned concepts.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We measure disentanglement with DCI... OIS = 2/k ∑ |Rij − R(gt)ij|²
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
LEAK = 1/k · Z ∑ max(gapℓ, 0)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
To Believe or Not to Believe Your LLM: Iterative Prompting for Estimating Epistemic Uncertainty
Yasin Abbasi Yadkori et al. To Believe or Not to Believe Your LLM: Iterative Prompting for Estimating Epistemic Uncertainty. NeurIPS, 2024
work page 2024
-
[2]
Towards robust interpretability with self-explaining neural networks
David Alvarez Melis and Tommi Jaakkola. Towards robust interpretability with self-explaining neural networks. NeurIPS, 2018
work page 2018
-
[3]
Jason Ansel et al. PyTorch 2: Faster Machine Learning Through Dynamic Python Bytecode Transformation and Graph Compilation. In ASPLOS, 2024
work page 2024
-
[4]
Debiasing concept-based explanations with causal analysis
Mohammad Taha Bahadori and David Heckerman. Debiasing concept-based explanations with causal analysis. In ICLR, 2021
work page 2021
-
[5]
Entropy-based logic explanations of neural networks
Pietro Barbiero et al. Entropy-based logic explanations of neural networks. In AAAI, 2022
work page 2022
-
[6]
Interpretable neural-symbolic concept reasoning
Pietro Barbiero et al. Interpretable neural-symbolic concept reasoning. In ICML, 2023
work page 2023
-
[7]
Relational concept bottleneck models
Pietro Barbiero et al. Relational concept bottleneck models. NeurIPS, 2024
work page 2024
-
[8]
Neural interpretable reasoning
Pietro Barbiero et al. Neural interpretable reasoning. arXiv:2502.11639, 2025
-
[9]
Concept-level debugging of part-prototype networks
Andrea Bontempelli et al. Concept-level debugging of part-prototype networks. In ICLR, 2023
work page 2023
-
[10]
Shortcuts and identifiability in concept-based models from a neuro-symbolic lens
Samuele Bortolotti et al. Shortcuts and identifiability in concept-based models from a neuro-symbolic lens. arXiv:2502.11245, 2025
-
[11]
Logically consistent language models via neuro-symbolic integration
Diego Calanzone et al. Logically consistent language models via neuro-symbolic integration. In ICLR, 2025
work page 2025
-
[12]
Interactive concept bottleneck models
Kushal Chauhan et al. Interactive concept bottleneck models. In AAAI, 2023
work page 2023
-
[13]
This looks like that: Deep learning for interpretable image recognition
Chaofan Chen et al. This looks like that: Deep learning for interpretable image recognition. NeurIPS, 2019
work page 2019
-
[14]
Concept whitening for interpretable image recognition
Zhi Chen et al. Concept whitening for interpretable image recognition. Nature Machine Intelligence, 2020
work page 2020
-
[15]
Xtuner: A toolkit for efficiently fine-tuning llm
XTuner Contributors. Xtuner: A toolkit for efficiently fine-tuning llm. https://github.com/InternLM/ xtuner, 2023
work page 2023
-
[16]
Corinna Cortes and Vladimir Vapnik. Support-vector networks. Machine learning, 1995
work page 1995
-
[17]
Causally reliable concept bottleneck models
Giovanni De Felice et al. Causally reliable concept bottleneck models. arXiv:2503.04363, 2025
-
[18]
Interpretable concept-based memory reasoning
David Debot et al. Interpretable concept-based memory reasoning. arXiv:2407.15527, 2024
-
[19]
Anycbms: How to turn any black box into a concept bottleneck model, 2024
Gabriele Dominici et al. Anycbms: How to turn any black box into a concept bottleneck model, 2024
work page 2024
-
[20]
Causal concept graph models: Beyond causal opacity in deep learning.arXiv:2405.16507, 2024
Gabriele Dominici et al. Causal concept graph models: Beyond causal opacity in deep learning.arXiv:2405.16507, 2024
-
[21]
Counterfactual concept bottleneck models
Gabriele Dominici et al. Counterfactual concept bottleneck models. arXiv:2402.01408, 2024
-
[22]
A framework for the quantitative evaluation of disentangled representations
Cian Eastwood and Christopher KI Williams. A framework for the quantitative evaluation of disentangled representations. In ICLR, 2018
work page 2018
-
[23]
Learning to receive help: Intervention-aware concept embedding models
Mateo Espinosa Zarlenga et al. Learning to receive help: Intervention-aware concept embedding models. NeurIPS, 2023
work page 2023
-
[24]
Learning to receive help: Intervention-aware concept embedding models
Mateo Espinosa Zarlenga et al. Learning to receive help: Intervention-aware concept embedding models. NeurIPS, 2024
work page 2024
-
[25]
Bayesian concept bottleneck models with llm priors
Jean Feng et al. Bayesian concept bottleneck models with llm priors. arXiv:2410.15555, 2024
-
[26]
Hidde Fokkema et al. Sample-efficient learning of concepts with theoretical guarantees: from data to concepts without interventions. arXiv:2502.06536, 2025
-
[27]
Towards a deeper understanding of concept bottleneck models through end-to-end explanation
Jack Furby et al. Towards a deeper understanding of concept bottleneck models through end-to-end explanation. In Workshop on Representation Learning for Responsible Human-Centric AI @ AAAI, 2023
work page 2023
-
[28]
Aaron Grattafiori et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Addressing leakage in concept bottleneck models
Marton Havasi et al. Addressing leakage in concept bottleneck models. In NeurIPS, 2022
work page 2022
-
[30]
Deep residual learning for image recognition
Kaiming He et al. Deep residual learning for image recognition. In CVPR, 2016
work page 2016
-
[31]
Towards a Definition of Disentangled Representations
Irina Higgins et al. Towards a definition of disentangled representations. arXiv:1812.02230, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[32]
Lei Huang et al. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions. ACM TOIS, 2023
work page 2023
-
[33]
Aaron Hurst et al. Gpt-4o system card. arXiv:2410.21276, 2024. 11 A PREPRINT - A PRIL 30, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Concept bottleneck generative models
Aya Abdelsalam Ismail et al. Concept bottleneck generative models. In ICLR, 2023
work page 2023
-
[35]
A comprehensive survey on self-interpretable neural networks
Yang Ji et al. A comprehensive survey on self-interpretable neural networks. arXiv:2501.15638, 2025
-
[36]
Is disentanglement all you need? comparing concept-based & disentanglement approaches
Dmitry Kazhdan et al. Is disentanglement all you need? comparing concept-based & disentanglement approaches. arXiv:2104.06917, 2021
-
[37]
Interpretability beyond feature attribution: Quantitative testing with concept activation vectors
Been Kim et al. Interpretability beyond feature attribution: Quantitative testing with concept activation vectors. In ICML, 2018
work page 2018
-
[38]
Probabilistic concept bottleneck models
Eunji Kim et al. Probabilistic concept bottleneck models. In ICML, 2023
work page 2023
-
[39]
Hyunjik Kim and Andriy Mnih. Disentangling by factorising. In ICML, 2018
work page 2018
-
[40]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[41]
Pang Wei Koh et al. Concept bottleneck models. In ICML, 2020
work page 2020
-
[42]
Beyond concept bottleneck models: How to make black boxes intervenable? NeurIPS, 2024
Sonia Laguna et al. Beyond concept bottleneck models: How to make black boxes intervenable? NeurIPS, 2024
work page 2024
-
[43]
Faithful vision-language interpretation via concept bottleneck models
Songning Lai et al. Faithful vision-language interpretation via concept bottleneck models. In ICLR, 2024
work page 2024
-
[44]
Find: human-in-the-loop debugging deep text classifiers
Piyawat Lertvittayakumjorn et al. Find: human-in-the-loop debugging deep text classifiers. In EMNLP, 2020
work page 2020
-
[45]
Oscar Li et al. Deep learning for case-based reasoning through prototypes: A neural network that explains its predictions. In AAAI, 2018
work page 2018
-
[46]
On erroneous agreements of clip image embeddings
Siting Li et al. On erroneous agreements of clip image embeddings. arXiv:2411.05195, 2024
-
[47]
Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
Shilong Liu et al. Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection. In ECCV, 2024
work page 2024
-
[48]
Deep learning face attributes in the wild
Ziwei Liu et al. Deep learning face attributes in the wild. In ICCV, 2015
work page 2015
-
[49]
Towards learning to explain with concept bottleneck models: mitigating information leakage
Joshua Lockhart et al. Towards learning to explain with concept bottleneck models: mitigating information leakage. arXiv:2211.03656, 2022
-
[50]
Promises and pitfalls of black-box concept learning models
Anita Mahinpei et al. Promises and pitfalls of black-box concept learning models. In Workshop on Theoretic Foundation, Criticism, and Application Trend of Explainable AI @ ICML, 2021
work page 2021
-
[51]
GlanceNets: Interpretabile, Leak-proof Concept-based Models
Emanuele Marconato et al. GlanceNets: Interpretabile, Leak-proof Concept-based Models. In NeurIPS, 2022
work page 2022
-
[52]
Emanuele Marconato et al. Interpretability is in the mind of the beholder: A causal framework for human- interpretable representation learning. Entropy, 2023
work page 2023
-
[53]
Not all neuro-symbolic concepts are created equal: Analysis and mitigation of reasoning shortcuts
Emanuele Marconato et al. Not all neuro-symbolic concepts are created equal: Analysis and mitigation of reasoning shortcuts. NeurIPS, 2024
work page 2024
-
[54]
Do concept bottleneck models learn as intended? arXiv:2105.04289, 2021
Andrei Margeloiu et al. Do concept bottleneck models learn as intended? arXiv:2105.04289, 2021
-
[55]
Evaluating the stability of semantic concept representations in CNNs for robust explainability
Georgii Mikriukov et al. Evaluating the stability of semantic concept representations in CNNs for robust explainability. In World Conference on Explainable Artificial Intelligence, 2023
work page 2023
-
[56]
Lost in latent space: Examining failures of disentangled models at combinatorial generalisa- tion
Milton Montero et al. Lost in latent space: Examining failures of disentangled models at combinatorial generalisa- tion. NeurIPS, 2022
work page 2022
-
[57]
Diconstruct: Causal concept-based explanations through black-box distillation
Ricardo Moreira et al. Diconstruct: Causal concept-based explanations through black-box distillation. arXiv:2401.08534, 2024
-
[58]
Label-free concept bottleneck models
Tuomas Oikarinen et al. Label-free concept bottleneck models. In ICLR, 2023
work page 2023
-
[59]
Concept-based explainable artificial intelligence: A survey
Eleonora Poeta et al. Concept-based explainable artificial intelligence: A survey. arXiv:2312.12936, 2023
-
[60]
Learning transferable visual models from natural language supervision
Alec Radford et al. Learning transferable visual models from natural language supervision. In ICML, 2021
work page 2021
-
[61]
From causal to concept-based representation learning
Goutham Rajendran et al. From causal to concept-based representation learning. NeurIPS, 2024
work page 2024
-
[62]
Naveen Raman et al. Do concept bottleneck models obey locality? In XAI in Action: Past, Present, and Future Applications, 2023
work page 2023
-
[63]
Discover-then-name: Task-agnostic concept bottlenecks via automated concept discovery, 2024
Sukrut Rao et al. Discover-then-name: Task-agnostic concept bottlenecks via automated concept discovery, 2024
work page 2024
-
[64]
Unpacking large language models with conceptual consistency
Pritish Sahu et al. Unpacking large language models with conceptual consistency. arXiv:2209.15093, 2022
-
[65]
C-senn: Contrastive self-explaining neural network
Yoshihide Sawada and Keigo Nakamura. C-senn: Contrastive self-explaining neural network. arXiv:2206.09575, 2022
-
[66]
Concept bottleneck model with additional unsupervised concepts
Yoshihide Sawada and Keigo Nakamura. Concept bottleneck model with additional unsupervised concepts. IEEE Access, 2022. 12 A PREPRINT - A PRIL 30, 2025
work page 2022
-
[67]
Bernhard Schölkopf et al. New support vector algorithms. Neural computation, 2000
work page 2000
-
[68]
Toward causal representation learning
Bernhard Schölkopf et al. Toward causal representation learning. IEEE, 2021
work page 2021
-
[69]
Concept bottleneck models without predefined concepts
Simon Schrodi et al. Concept bottleneck models without predefined concepts. arXiv:2407.03921, 2024
-
[70]
Concept embedding analysis: A review
Gesina Schwalbe. Concept embedding analysis: A review. arXiv:2203.13909, 2022
-
[71]
A closer look at the intervention procedure of concept bottleneck models
Sungbin Shin et al. A closer look at the intervention procedure of concept bottleneck models. In ICML, 2023
work page 2023
-
[72]
VLG-CBM: Training Concept Bottleneck Models with Vision-Language Guidance
Divyansh Srivastava et al. VLG-CBM: Training Concept Bottleneck Models with Vision-Language Guidance. In NeurIPS, 2024
work page 2024
-
[73]
Right for the Right Concept: Revising Neuro-Symbolic Concepts by Interacting with their Explanations
Wolfgang Stammer et al. Right for the Right Concept: Revising Neuro-Symbolic Concepts by Interacting with their Explanations. In CVPR, 2021
work page 2021
-
[74]
Learning to intervene on concept bottlenecks
David Steinmann et al. Learning to intervene on concept bottlenecks. In ICML, 2024
work page 2024
-
[75]
Raphael Suter et al. Robustly disentangled causal mechanisms: Validating deep representations for interventional robustness. In ICML, 2019
work page 2019
-
[76]
Leveraging explanations in interactive machine learning: An overview
Stefano Teso et al. Leveraging explanations in interactive machine learning: An overview. Frontiers in Artificial Intelligence, 2023
work page 2023
-
[77]
Stochastic concept bottleneck models
Moritz Vandenhirtz et al. Stochastic concept bottleneck models. arXiv:2406.19272, 2024
-
[78]
The caltech-ucsd birds-200-2011 dataset
Catherine Wah et al. The caltech-ucsd birds-200-2011 dataset. 2011
work page 2011
-
[79]
Leveraging sparse linear layers for debuggable deep networks
Eric Wong et al. Leveraging sparse linear layers for debuggable deep networks. In ICML, 2021
work page 2021
-
[80]
Yue Yang et al. Language in a bottle: Language model guided concept bottlenecks for interpretable image classification. In CVPR, 2023
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.