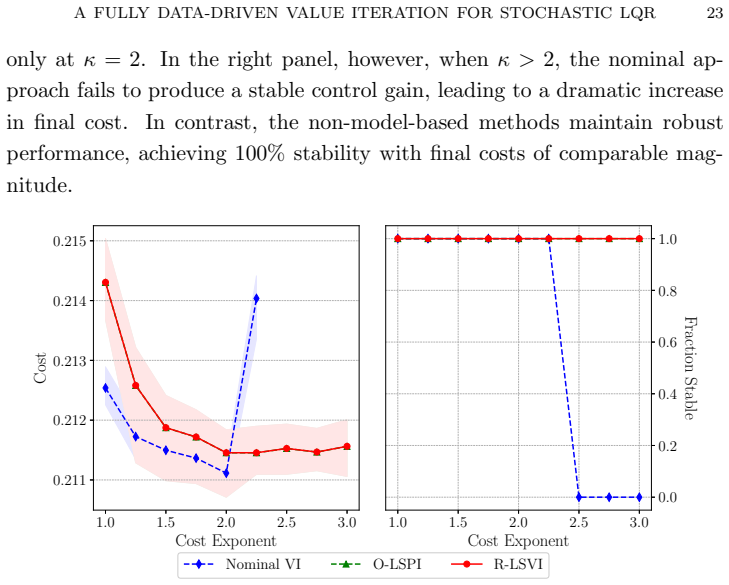
A Fully Data-Driven Value Iteration for Stochastic LQR: Convergence, Robustness and Stability
Pith reviewed 2026-05-22 16:33 UTC · model grok-4.3
The pith
Value iteration for data-driven stochastic LQR is globally exponentially stable from any positive semidefinite initial matrix.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
For discrete-time stochastic linear quadratic regulator problems with completely unknown dynamics and cost, value iteration is globally exponentially stable for any positive semidefinite initial value matrix in the noise-free case. In the presence of external disturbances the iteration exhibits small-disturbance input-to-state stability and converges inside a neighborhood of the optimal solution whose radius shrinks with the disturbance size. A new non-model-based robust adaptive dynamic programming algorithm is introduced that requires no prior knowledge of an initial admissible control policy.
What carries the argument
The direct data-driven value iteration step that updates the value function estimate solely from collected input-state trajectories without any intermediate system identification.
Load-bearing premise
The system must be exactly a discrete-time stochastic linear quadratic regulator and the collected input-state data must be rich enough to support direct policy learning without model identification.
What would settle it
Run the value iteration from a zero initial matrix on a noise-free stochastic LQR system whose input-state data satisfy persistent excitation; divergence or failure to reach the known optimal cost would falsify the global exponential stability claim.
Figures



read the original abstract
Unlike traditional model-based reinforcement learning approaches that estimate system parameters from data, non-model-based data-driven control learns the optimal policy directly from input-state data without any intermediate model identification. Although this direct reinforcement learning approach offers increased adaptability and resilience to model misspecification, its reliance on raw data leaves it vulnerable to system noise and disturbances that may undermine convergence, robustness, and stability. In this article, we establish the convergence, robustness, and stability of value iteration (VI) for data-driven control of stochastic linear quadratic (LQ) systems in discrete-time with entirely unknown dynamics and cost. Our contributions are three-fold. First, we prove that VI is globally exponentially stable for any positive semidefinite initial value matrix in noise-free settings, thereby significantly relaxing restrictive assumptions on initial value functions in existing literature. Second, we extend our analysis to settings with external disturbances, proving that VI maintains small-disturbance input-to-state stability (ISS) and converges within a small neighborhood of the optimal solution when disturbances are sufficiently small. Third, we propose a new non-model-based robust adaptive dynamic programming (ADP) algorithm for adaptive optimal controller design, which, unlike existing procedures, requires no prior knowledge of an initial admissible control policy. Numerical experiments on a ``data center cooling'' problem demonstrate the convergence and stability of the algorithm compared to established methods, highlighting its robustness and adaptability for data-driven control in noisy environments. Finally, we apply the method to dynamic portfolio allocation, demonstrating its practical relevance outside traditional control tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript develops a fully data-driven value iteration (VI) algorithm for discrete-time stochastic linear quadratic regulators with unknown dynamics and quadratic costs. It claims three main results: (i) global exponential stability of the VI iterates for any positive semidefinite initial value matrix in the noise-free case, relaxing the usual requirement of an initial admissible policy; (ii) small-disturbance input-to-state stability (ISS) of the iteration under bounded external disturbances, with convergence to a neighborhood of the optimal solution; and (iii) a robust adaptive dynamic programming procedure that implements the method without prior knowledge of a stabilizing controller. The claims are supported by numerical experiments on a data-center cooling system and a dynamic portfolio allocation task.
Significance. If the stability proofs are free of gaps in the data-richness argument, the relaxation of the admissible-policy assumption would be a substantive contribution to data-driven LQR methods, as it removes a common practical bottleneck. The small-disturbance ISS extension and the non-model-based robust ADP algorithm add robustness considerations that are relevant for stochastic and noisy environments. The portfolio-allocation example illustrates applicability outside classical control.
major comments (2)
- The global exponential stability result for arbitrary PSD initial value matrices (abstract and stability theorem) presupposes that the collected input-state data matrix satisfies the rank/excitation condition needed to uniquely recover the optimal Q-function from the Bellman residual. When the initial value matrix induces an unstable closed-loop, the generated trajectories may fail to provide persistent excitation. The proof must explicitly show how this rank condition is guaranteed without an auxiliary excitation signal or an initial stabilizing policy; otherwise the contraction-mapping argument does not hold for all PSD starts.
- In the small-disturbance ISS analysis, the size of the ultimate convergence neighborhood is asserted to shrink with the disturbance bound. The manuscript should supply the explicit functional dependence of this neighborhood radius on the disturbance magnitude (e.g., via the constants appearing in the ISS-Lyapunov inequality) and verify that the contraction rate remains uniform over the considered disturbance class.
minor comments (2)
- Clarify the precise assumptions on controllability, observability, and positive-definiteness of the cost matrices at the outset of the theoretical development.
- In the numerical sections, report the condition number or rank of the data matrix for each initial-value choice to allow readers to assess whether the excitation condition was satisfied in the experiments.
Simulated Author's Rebuttal
We are grateful to the referee for the thorough review and valuable suggestions. Below we provide point-by-point responses to the major comments. We believe these clarifications and additions will improve the manuscript.
read point-by-point responses
-
Referee: The global exponential stability result for arbitrary PSD initial value matrices (abstract and stability theorem) presupposes that the collected input-state data matrix satisfies the rank/excitation condition needed to uniquely recover the optimal Q-function from the Bellman residual. When the initial value matrix induces an unstable closed-loop, the generated trajectories may fail to provide persistent excitation. The proof must explicitly show how this rank condition is guaranteed without an auxiliary excitation signal or an initial stabilizing policy; otherwise the contraction-mapping argument does not hold for all PSD starts.
Authors: We thank the referee for highlighting this important point. In our approach, the input-state data is collected offline using a fixed exploratory input sequence that includes sufficient excitation (such as white noise added to a nominal input), which is independent of the initial value matrix and the subsequent value iteration process. This ensures the rank condition on the data matrix holds a priori, regardless of whether the initial value matrix corresponds to a stabilizing policy. The value iteration then proceeds using this fixed data set, and the global exponential stability result applies to the sequence of value functions under this condition. We will revise the manuscript to explicitly state this separation between data collection and the iteration in the relevant sections and add a remark in the stability theorem to address this concern. revision: partial
-
Referee: In the small-disturbance ISS analysis, the size of the ultimate convergence neighborhood is asserted to shrink with the disturbance bound. The manuscript should supply the explicit functional dependence of this neighborhood radius on the disturbance magnitude (e.g., via the constants appearing in the ISS-Lyapunov inequality) and verify that the contraction rate remains uniform over the considered disturbance class.
Authors: We agree that making the dependence explicit will enhance the clarity of the robustness result. In the proof of Theorem Y on small-disturbance ISS, the ultimate bound on the neighborhood is given by a term of the form C * delta / (1 - rho), where delta is the disturbance bound, rho < 1 is the contraction rate, and C is a constant depending on the system parameters and the ISS-Lyapunov function. We show that rho remains uniform (less than some value strictly below 1) for all disturbances satisfying delta < delta_max, where delta_max is derived from the Lipschitz constants and system bounds. We will include these explicit expressions and the uniformity argument in the revised version of the proof. revision: yes
Circularity Check
No significant circularity; claims rest on standard LQR contraction and data excitation assumptions
full rationale
The paper derives global exponential stability of value iteration for arbitrary positive semidefinite initial value matrices from the contraction property of the Bellman operator under the stated rank/excitation condition on collected input-state trajectories. This is a standard first-principles argument in stochastic LQR and does not reduce the target stability result to a quantity defined or fitted by the paper's own equations. The extension to small-disturbance ISS follows similarly from perturbation analysis around the nominal contraction. No load-bearing self-citation, ansatz smuggling, or renaming of known empirical patterns is present; the data-richness assumption is explicitly stated rather than derived from the algorithm outputs themselves. The derivation chain is therefore self-contained against external LQR benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The plant is exactly a discrete-time stochastic linear system with quadratic cost and additive noise.
- domain assumption Collected input-state trajectories are sufficiently exciting to permit direct policy learning without model identification.
Forward citations
Cited by 1 Pith paper
-
Data-driven online control for real-time optimal economic dispatch and temperature regulation in district heating systems
A data-driven controller embeds steady-state economic optimality into district heating temperature dynamics for forecast-free convergence to optimal dispatch and temperature regulation.
Reference graph
Works this paper leans on
-
[1]
Y. Abbasi-Yadkori, N. Lazic, and C. Szepesv´ ari. Model- free linear quadratic control via reduction to expert prediction. In The 22nd International Conference on Artificial Intelligence and Statistics , pages 3108–3117. PMLR, 2019
work page 2019
-
[2]
Y. Abbasi-Yadkori and C. Szepesv´ ari. Regret bounds for the adaptive control of linear quadratic systems. In Proceedings of the 24th Annual Conference on Learning Theor y, pages 1–26. JMLR Workshop and Conference Proceedings, 2011
work page 2011
-
[3]
LQG for portfolio optimization
Marc Abeille, Alessandro Lazaric, Xavier Brokmann, et a l. Lqg for portfolio opti- mization. arXiv preprint arXiv:1611.00997 , 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[4]
K. J. ˚ Astr¨ om and B. Wittenmark.Adaptive Control. Addison-Wesley, MA, USA, 2nd edition, 1997. A FULLY DATA-DRIVEN V ALUE ITERATION FOR STOCHASTIC LQR 37
work page 1997
-
[5]
R. W. Beard, G. N. Saridis, and J. T. Wen. Galerkin approxi mations of the generalized Hamilton-Jacobi-Bellman equation. Automatica, 33(12):2159–2177, 1997
work page 1997
-
[6]
R. Bellman. Dynamic Programming. Princeton University Press, Princeton, NJ, 1957
work page 1957
-
[7]
D. P. Bertsekas. Dynamic Programming and Optimal Control , volume 1. Athena Sci- entific, Belmont, MA, 3rd edition, 2011
work page 2011
-
[8]
T. Bian, Y. Jiang, and Z.-P. Jiang. Adaptive dynamic prog ramming and optimal control of nonlinear nonaffine systems. Automatica, 50(10):2624–2632, 2014
work page 2014
-
[9]
T. Bian, Y. Jiang, and Z.-P. Jiang. Adaptive dynamic prog ramming for stochastic systems with state and control dependent noise. IEEE Transactions on Automatic Control, 61(12):4170–4175, 2016
work page 2016
-
[10]
T. Bian and Z.-P. Jiang. Value iteration and adaptive dy namic programming for data-driven adaptive optimal control design. Automatica, 71:348–360, 2016
work page 2016
-
[11]
T. Bian and Z.-P. Jiang. Continuous-time robust dynami c programming. SIAM Jour- nal on Control and Optimization , 57(6):4150–4174, 2019
work page 2019
-
[12]
T. Bian and Z.-P. Jiang. Reinforcement learning and ada ptive optimal control for continuous-time nonlinear systems: A value iteration appr oach. IEEE Transactions on Neural Networks and Learning Systems , 33(7):2781–2790, 2022
work page 2022
-
[13]
T. Bian, D. M. Wolpert, and Z.-P. Jiang. Model-free robu st optimal feedback mech- anisms of biological motor control. Neural Computation , 32(3):562–595, 2020
work page 2020
-
[14]
S. J. Bradtke, B. E. Ydstie, and A. G. Barto. Adaptive lin ear quadratic control using policy iteration. In Proceedings of 1994 American Control Conference , pages 3475–3479, 1994
work page 1994
- [15]
-
[16]
L. Cui, B. Pang, and Z.-P. Jiang. Reinforcement-learni ng-based risk-sensitive opti- mal feedback mechanisms of biological motor control. In 62nd IEEE Conference on Decision and Control (CDC) , pages 7944–7949, 2023
work page 2023
-
[17]
L. Cui, S. Wang, J. Zhang, D. Zhang, J. Lai, Y. Zheng, Z. Zh ang, and Z.-P. Jiang. Learning-based balance control of wheel-legged robots. IEEE Robotics and Automa- tion Letters, 6(4):7667–7674, 2021
work page 2021
-
[18]
S. Dean, H. Mania, N. Matni, B. Recht, and S. Tu. On the sam ple complexity of the linear quadratic regulator. Foundations of Computational Mathematics , 20(4):633– 679, 2020
work page 2020
-
[19]
Value iteration for LQR cont rol of unknown stochastic- parameter linear systems
Wenwu Fan and Junlin Xiong. Value iteration for LQR cont rol of unknown stochastic- parameter linear systems. Systems & Control Letters , 185:105731, 2024
work page 2024
-
[20]
Machine learning applications for data center optimization
Jim Gao. Machine learning applications for data center optimization. White Paper 21, Google, Mountain View, CA, USA, 2014
work page 2014
-
[21]
N. Gˆ arleanu and L. H. Pedersen. Dynamic trading with predictable returns and trans- action costs. The Journal of Finance , 68(6):2309–2340, 2013
work page 2013
-
[22]
W. Y. Ha, S. Chakraborty, Y. Yu, S. Ghasemi, and Z.-P. Jia ng. Automated lane changing through learning-based control: An experimental study. In IEEE 26th Inter- national Conference on Intelligent Transportation System s (ITSC) , pages 4215–4220, 2023. 38LEILEI CUI, ZHONG-PING JIANG, PETTER N. KOLM, GREGOIRE G. MACQUERON
work page 2023
-
[23]
G. Hewer. An iterative technique for the computation of the steady state gains for the discrete optimal regulator. IEEE Transactions on Automatic Control , 16(4):382–384, 1971
work page 1971
-
[24]
Roger A Horn and Charles R Johnson. Matrix analysis . Cambridge University Press, 2012
work page 2012
-
[25]
R. A. Howard. Dynamic Programming and Markov Processes . John Wiley & Sons, New York, 1960
work page 1960
-
[26]
M. Huang, Z.-P. Jiang, and K. Ozbay. Learning-based ada ptive optimal control for connected vehicles in mixed traffic: Robustness to driver rea ction time. IEEE Trans- actions on Cybernetics , 52(6):5267–5277, 2022
work page 2022
-
[27]
Y. Jiang and Z.-P. Jiang. Computational adaptive optim al control for continuous-time linear systems with completely unknown dynamics. Automatica, 48(10):2699–2704, 2012
work page 2012
-
[28]
Y. Jiang and Z.-P. Jiang. Adaptive dynamic programming as a theory of sensorimotor control. Biological Cybernetics, 108(4):459–473, 2014
work page 2014
-
[29]
Y. Jiang and Z.-P. Jiang. Robust Adaptive Dynamic Programming. Wiley-IEEE Press, Hoboken, New Jersey, 2017
work page 2017
-
[30]
Adaptive optimal control of networked control systems with two-channel stoc hastic dropouts
Yi Jiang, Weinan Gao, Ci Chen, Tianyou Chai, and Frank L L ewis. Adaptive optimal control of networked control systems with two-channel stoc hastic dropouts. SIAM Journal on Control and Optimization , 61(5):3183–3208, October 2023
work page 2023
-
[31]
Yi Jiang, Lu Liu, and Gang Feng. Adaptive linear quadrat ic control for stochastic discrete-time linear systems with unmeasurable multiplic ative and additive noises. IEEE Transactions on Automatic Control , 69(11):7808–7815, November 2024
work page 2024
- [32]
- [33]
-
[34]
R. Kalman. Contribution to the theory of optimal contro l. Bolet ´ ın de la Sociedad Matem´ atica Mexicana, 5(2):102–119, 1960
work page 1960
-
[35]
R. Kamalapurkar, P. Walters, J. Rosenfeld, and W. Dixon . Reinforcement Learning for Optimal Feedback Control . Springer, Berlin, 2018
work page 2018
-
[36]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stocha stic optimization. arXiv preprint arXiv:1412.6980 , 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[37]
B. Kiumarsi, K. G. Vamvoudakis, H. Modares, and F. L. Lew is. Optimal and au- tonomous control using reinforcement learning: A survey. IEEE Transactions on Neural Networks and Learning Systems , 29(6):2042–2062, 2017
work page 2042
- [38]
- [39]
-
[40]
Petter N. Kolm and Nicholas Westray. Mean-variance opt imization for simulation of order flow. Journal of Portfolio Management , 48(6), 2022. A FULLY DATA-DRIVEN V ALUE ITERATION FOR STOCHASTIC LQR 39
work page 2022
- [41]
-
[42]
Value iteration for stochastic LQR with con- vergence guarantees
Jing Lai, Junlin Xiong, and Yu Kang. Value iteration for stochastic LQR with con- vergence guarantees. IEEE Transactions on Neural Networks and Learning Systems , 2025
work page 2025
-
[43]
R. J. Leake and R.-W. Liu. Construction of suboptimal co ntrol sequences. SIAM Journal on Control , 5(1):54–63, 1967
work page 1967
-
[44]
D. Lee. Convergence of dynamic programming on the semid efinite cone for discrete- time infinite-horizon LQR. IEEE Transactions on Automatic Control , 67(10):5661– 5668, 2022
work page 2022
-
[45]
F. L. Lewis, D. Vrabie, and V. L. Syrmos. Optimal Control . John Wiley & Sons, Hoboken, New Jersey, 2012
work page 2012
-
[46]
J. R. Magnus and H. Neudecker. Matrix Differential Calculus with Applications in Statistics and Econometrics . John Wiley & Sons, Hoboken, New Jersey, 2019
work page 2019
-
[47]
Dynamic portfoli o choice with linear re- balancing rules
Ciamac C Moallemi and Mehmet Sa˘ glam. Dynamic portfoli o choice with linear re- balancing rules. Journal of Financial and Quantitative Analysis , 52(3):1247–1278, 2017
work page 2017
-
[48]
B. Pang and Z. P. Jiang. Robust reinforcement learning: A case study in linear quadratic regulation. In Proceedings of the AAAI conference on artificial intelligen ce, volume 35, pages 9303–9311, 2021
work page 2021
-
[49]
B. Pang and Z.-P. Jiang. Reinforcement learning for ada ptive optimal station- ary control of linear stochastic systems. IEEE Transactions on Automatic Control , 68(4):2383–2390, 2022
work page 2022
-
[50]
M. L. Puterman. Markov Decision Processes: Discrete Stochastic Dynamic Pr ogram- ming. John Wiley & Sons, Hoboken, New Jersey, 2014
work page 2014
-
[51]
B. Recht. A tour of reinforcement learning: The view fro m continuous control. Annual Review of Control, Robotics, and Autonomous Systems , 2:253–279, 2019
work page 2019
-
[52]
Data-driven near optimization for fast sampling singularly perturbed syste ms
Hao Shen, Chuanjun Peng, Huaicheng Yan, and Shengyuan X u. Data-driven near optimization for fast sampling singularly perturbed syste ms. IEEE Transactions on Automatic Control, 69(7):4689–4694, 2024
work page 2024
-
[53]
Converge nce and robustness of value and policy iteration for the linear quadratic regul ator
Bowen Song, Chenxuan Wu, and Andrea Iannelli. Converge nce and robustness of value and policy iteration for the linear quadratic regul ator. arXiv preprint arXiv:2411.04548, 2024
-
[54]
E. D. Sontag. Smooth stabilization implies coprime fac torization. IEEE Transactions on Automatic Control , 34(4):435–443, 1989
work page 1989
-
[55]
E. D. Sontag. Input-to-State Stability: Basic Concepts and Results , pages 163–220. Lecture Notes in Mathematics. Springer Verlag, Germany, 20 08
-
[56]
B. L. Stevens, F. L. Lewis, and E. N. Johnson. Aircraft Control and Simulation: Dynamics, Controls Design, and Autonomous Systems . John Wiley & Sons, Hoboken, New Jersey, 2015
work page 2015
-
[57]
R. S. Sutton and A. G. Barto. Reinforcement Learning: An Introduction . MIT Press, Cambridge, MA, 2nd edition, 2018. 40LEILEI CUI, ZHONG-PING JIANG, PETTER N. KOLM, GREGOIRE G. MACQUERON
work page 2018
-
[58]
G. Teschl. Ordinary Differential Equations and Dynamical Systems , volume 140. American Mathematical Society, Providence, Rhode Island, 2024
work page 2024
- [59]
- [60]
-
[61]
J. C. Willems, P. Rapisarda, I. Markovsky, and B. L. M. De Moor. A note on persis- tency of excitation. Systems & Control Letters , 54(4):325–329, 2005
work page 2005
-
[62]
X. Zhang and T. Ba¸ sar. Revisiting LQR control from the p erspective of receding- horizon policy gradient. IEEE Control Systems Letters , 7:1664–1669, 2023
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.