Sparse Attention Remapping with Clustering for Efficient LLM Decoding on PIM
Pith reviewed 2026-05-22 16:54 UTC · model grok-4.3
The pith
STARC clusters KV pairs by semantic similarity and remaps them to PIM-aligned memory regions for efficient sparse attention in LLM decoding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
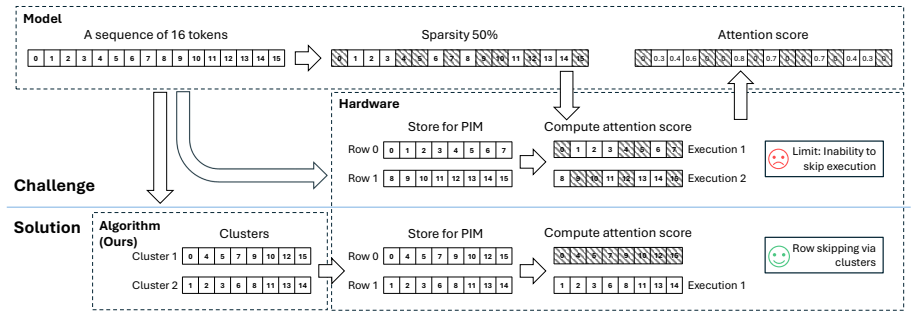
STARC clusters KV pairs by semantic similarity and maps them to contiguous memory regions aligned with PIM bank structures. During decoding, queries retrieve relevant tokens at cluster granularity by matching against precomputed centroids, enabling selective attention and parallel processing without frequent reclustering or data movement overhead.
What carries the argument
Semantic clustering of KV pairs with centroid-based cluster-granularity retrieval, mapped to PIM bank-aligned contiguous regions.
If this is right
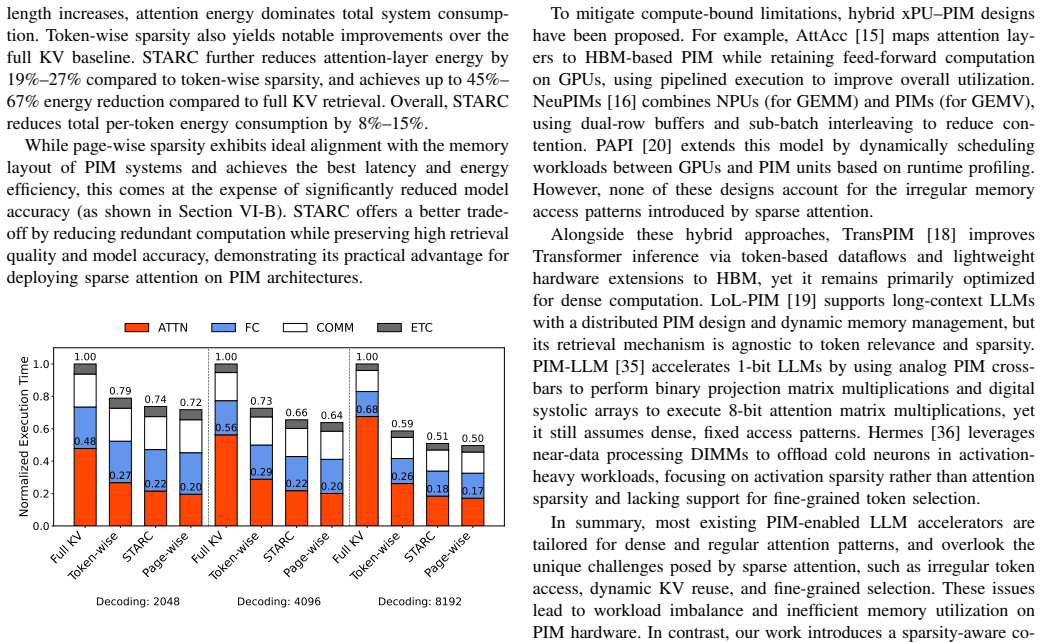
- Attention-layer latency drops 19-31 percent and energy drops 19-27 percent versus common token-wise sparsity methods.
- Under a 1024-token KV budget, latency falls 54-74 percent and energy falls 45-67 percent versus full KV cache retrieval.
- Model accuracy stays comparable to existing state-of-the-art sparse attention methods.
- Workload imbalance and irregular accesses on PIM are reduced by aligning clusters with bank boundaries.
Where Pith is reading between the lines
- The same clustering logic could be tested on non-PIM accelerators that suffer from irregular memory traffic during sparse attention.
- If cluster stability holds across longer sequences, the method may reduce how often the entire KV cache must be reorganized.
- Combining cluster-level selection with other sparsity patterns such as head-wise or layer-wise pruning could compound the reported gains.
Load-bearing premise
Semantic clustering of KV pairs produces stable groups whose centroids can be matched quickly enough to avoid frequent reclustering or data movement during autoregressive decoding.
What would settle it
Measure whether total decoding latency including initial clustering plus centroid matching exceeds the latency of token-wise sparse attention on the same HBM-PIM system for context lengths beyond 4k tokens.
Figures










read the original abstract
Transformer-based models are the foundation of modern machine learning, but their execution, particularly during autoregressive decoding in large language models (LLMs), places significant pressure on memory systems due to frequent memory accesses and growing key-value (KV) caches. This creates a bottleneck in memory bandwidth, especially as context lengths increase. Processing-in-memory (PIM) architectures are a promising solution, offering high internal bandwidth and compute parallelism near memory. However, current PIM designs are primarily optimized for dense attention and struggle with the dynamic, irregular access patterns introduced by modern KV cache sparsity techniques. Consequently, they suffer from workload imbalance, reducing throughput and resource utilization. In this work, we propose STARC, a novel sparsity-optimized data mapping scheme tailored specifically for efficient LLM decoding on PIM architectures. STARC clusters KV pairs by semantic similarity and maps them to contiguous memory regions aligned with PIM bank structures. During decoding, queries retrieve relevant tokens at cluster granularity by matching against precomputed centroids, enabling selective attention and parallel processing without frequent reclustering or data movement overhead. Experiments on the HBM-PIM system show that, compared to common token-wise sparsity methods, STARC reduces attention-layer latency by 19%--31% and energy consumption by 19%--27%. Under a KV cache budget of 1024, it achieves up to 54%--74% latency reduction and 45%--67% energy reduction compared to full KV cache retrieval. Meanwhile, STARC maintains model accuracy comparable to state-of-the-art sparse attention methods, demonstrating its effectiveness in enabling efficient and hardware-friendly long-context LLM inference on PIM architectures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes STARC, a sparsity-optimized data mapping scheme for efficient LLM decoding on PIM architectures. KV pairs are clustered by semantic similarity and mapped to contiguous memory regions aligned with PIM bank structures. During decoding, queries retrieve relevant tokens at cluster granularity via matching against precomputed centroids, enabling selective attention without frequent reclustering or data movement. Experiments on an HBM-PIM system report 19%--31% attention-layer latency reduction and 19%--27% energy reduction versus token-wise sparsity baselines, with up to 54%--74% latency and 45%--67% energy reduction under a 1024-token KV budget, while maintaining accuracy comparable to state-of-the-art sparse attention methods.
Significance. If the reported gains are reproducible on real hardware and hold under incremental KV cache growth, the work could offer a practical way to mitigate workload imbalance and irregular accesses in sparse attention on PIM systems, supporting more efficient long-context LLM inference.
major comments (2)
- [Abstract and Experiments] Abstract and Experiments section: the central latency and energy claims rest on simulator results, yet no error bars, dataset details for the accuracy comparisons, or ablations on clustering frequency/number of clusters are provided. This directly affects assessment of the 19%--31% and 19%--27% improvements versus token-wise methods.
- [Method section (clustering and decoding procedure)] Method section (clustering and decoding procedure): the claim that precomputed centroids enable retrieval 'without frequent reclustering or data movement overhead' during autoregressive decoding is load-bearing for the performance numbers but lacks a concrete mechanism for assigning new KV vectors to existing clusters as the cache grows token-by-token. Nearest-centroid assignment cost or bounded-drift handling is not quantified, leaving open whether per-token overhead or semantic drift undermines the reported gains once the KV cache exceeds the 1024-token experimental budget.
minor comments (1)
- [Abstract] The ranges in the abstract (e.g., 19%--31%) would benefit from stating whether they represent min/max across models or average values with conditions.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects of experimental rigor and methodological clarity that we address below. We have revised the paper to incorporate additional details and explanations.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: the central latency and energy claims rest on simulator results, yet no error bars, dataset details for the accuracy comparisons, or ablations on clustering frequency/number of clusters are provided. This directly affects assessment of the 19%--31% and 19%--27% improvements versus token-wise methods.
Authors: We agree that these details improve transparency. The reported results are from a cycle-accurate simulator validated against HBM-PIM hardware parameters. In the revised Experiments section, we have added error bars (standard deviation over five runs with different clustering initializations) to all latency and energy plots. Accuracy comparisons now explicitly reference the LongBench benchmark suite with per-task breakdowns provided in an appendix. We have also added a new ablation study varying the number of clusters (k = 4, 8, 16, 32) and reclustering frequency (every 128, 256, or 512 tokens), confirming that the 19--31% latency and 19--27% energy gains remain stable across these settings. revision: yes
-
Referee: [Method section (clustering and decoding procedure)] Method section (clustering and decoding procedure): the claim that precomputed centroids enable retrieval 'without frequent reclustering or data movement overhead' during autoregressive decoding is load-bearing for the performance numbers but lacks a concrete mechanism for assigning new KV vectors to existing clusters as the cache grows token-by-token. Nearest-centroid assignment cost or bounded-drift handling is not quantified, leaving open whether per-token overhead or semantic drift undermines the reported gains once the KV cache exceeds the 1024-token experimental budget.
Authors: We have expanded the Method section with a precise description of the incremental procedure. Each newly generated KV vector is assigned to the nearest precomputed centroid using a single-pass cosine similarity computation against the small set of centroids (k typically 8--16). This per-token assignment cost is O(k) and has been quantified in a new table as contributing under 2% to total attention latency. For semantic drift, we apply a lightweight bounded-drift check: centroids are recomputed only when the mean intra-cluster distance exceeds a fixed threshold or at fixed intervals of 512 tokens. The overhead of these infrequent updates is amortized and already reflected in the 1024-token budget experiments; we have extended the evaluation to 2048 tokens to demonstrate that gains persist without degradation. revision: yes
Circularity Check
No circularity: empirical clustering mapping evaluated on external simulator
full rationale
The paper presents STARC as a practical data-mapping technique that clusters KV pairs by semantic similarity and aligns them to PIM bank structures for cluster-granularity retrieval. Performance numbers (19-31% latency reduction, etc.) are obtained from direct measurements on an HBM-PIM simulator under stated KV budgets, not from any closed-form derivation, fitted parameter renamed as prediction, or self-citation chain. No equations appear that define a quantity in terms of itself, and the method does not invoke uniqueness theorems or prior author work to force its design choices. The derivation chain is therefore self-contained and externally falsifiable.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
STARC clusters KV pairs by semantic similarity and maps them to contiguous memory regions aligned with PIM bank structures... queries retrieve relevant tokens at cluster granularity by matching against precomputed centroids... without frequent reclustering or data movement overhead.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We apply the standard K-means algorithm to all KV pairs... using cosine similarity as the distance metric... re-cluster every 128 decoding steps.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat et al. , “Gpt-4 technical report,” arXiv preprint arXiv:2303.08774 , 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Toolqa: A dataset for llm question answering with external tools,
Y . Zhuang, Y . Yu, K. Wang, H. Sun, and C. Zhang, “Toolqa: A dataset for llm question answering with external tools,” Advances in Neural Information Processing Systems , vol. 36, 2024
work page 2024
-
[3]
Pythia: Ai-assisted code completion system,
A. Svyatkovskiy, Y . Zhao, S. Fu, and N. Sundaresan, “Pythia: Ai-assisted code completion system,” in Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining , 2019, pp. 2727–2735
work page 2019
-
[4]
Code Llama: Open Foundation Models for Code
B. Roziere, J. Gehring, F. Gloeckle, S. Sootla, I. Gat, X. E. Tan, Y . Adi, J. Liu, T. Remez, J. Rapin et al., “Code llama: Open foundation models for code,” arXiv preprint arXiv:2308.12950 , 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Reflex- ion: Language agents with verbal reinforcement learning,
N. Shinn, F. Cassano, A. Gopinath, K. Narasimhan, and S. Yao, “Reflex- ion: Language agents with verbal reinforcement learning,” Advances in Neural Information Processing Systems , vol. 36, pp. 8634–8652, 2023
work page 2023
-
[6]
Tree of thoughts: Deliberate problem solving with large language models,
S. Yao, D. Yu, J. Zhao, I. Shafran, T. Griffiths, Y . Cao, and K. Narasimhan, “Tree of thoughts: Deliberate problem solving with large language models,” Advances in neural information processing systems , vol. 36, pp. 11 809–11 822, 2023
work page 2023
-
[7]
Pre-trained language models for in- teractive decision-making,
S. Li, X. Puig, C. Paxton, Y . Du, C. Wang, L. Fan, T. Chen, D.-A. Huang, E. Aky¨urek, A. Anandkumar et al., “Pre-trained language models for in- teractive decision-making,” Advances in Neural Information Processing Systems, vol. 35, pp. 31 199–31 212, 2022
work page 2022
-
[8]
Efficiently scaling transformer inference,
R. Pope, S. Douglas, A. Chowdhery, J. Devlin, J. Bradbury, J. Heek, K. Xiao, S. Agrawal, and J. Dean, “Efficiently scaling transformer inference,” Proceedings of Machine Learning and Systems , vol. 5, pp. 606–624, 2023
work page 2023
-
[9]
Efficient memory management for large language model serving with pagedattention,
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, J. Gonzalez, H. Zhang, and I. Stoica, “Efficient memory management for large language model serving with pagedattention,” in Proceedings of the 29th Symposium on Operating Systems Principles , 2023, pp. 611–626
work page 2023
-
[10]
Computedram: In-memory compute using off-the-shelf drams,
F. Gao, G. Tziantzioulis, and D. Wentzlaff, “Computedram: In-memory compute using off-the-shelf drams,” in Proceedings of the 52nd annual IEEE/ACM international symposium on microarchitecture , 2019, pp. 100–113
work page 2019
-
[11]
Newton: A dram-maker’s accelerator-in-memory (aim) architecture for machine learning,
M. He, C. Song, I. Kim, C. Jeong, S. Kim, I. Park, M. Thottethodi, and T. Vijaykumar, “Newton: A dram-maker’s accelerator-in-memory (aim) architecture for machine learning,” in 2020 53rd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO). IEEE, 2020, pp. 372–385
work page 2020
-
[12]
Pathfinding future pim archi- tectures by demystifying a commercial pim technology,
B. Hyun, T. Kim, D. Lee, and M. Rhu, “Pathfinding future pim archi- tectures by demystifying a commercial pim technology,” in 2024 IEEE International Symposium on High-Performance Computer Architecture (HPCA). IEEE, 2024, pp. 263–279
work page 2024
-
[13]
Accelerating neural network inference with processing-in-dram: from the edge to the cloud,
G. F. Oliveira, J. G ´omez-Luna, S. Ghose, A. Boroumand, and O. Mutlu, “Accelerating neural network inference with processing-in-dram: from the edge to the cloud,” IEEE Micro, vol. 42, no. 6, pp. 25–38, 2022
work page 2022
-
[14]
Floatpim: In-memory acceleration of deep neural network training with high precision,
M. Imani, S. Gupta, Y . Kim, and T. Rosing, “Floatpim: In-memory acceleration of deep neural network training with high precision,” in Proceedings of the 46th International Symposium on Computer Archi- tecture, 2019, pp. 802–815
work page 2019
-
[15]
Attacc! unleashing the power of pim for batched transformer- based generative model inference,
J. Park, J. Choi, K. Kyung, M. J. Kim, Y . Kwon, N. S. Kim, and J. H. Ahn, “Attacc! unleashing the power of pim for batched transformer- based generative model inference,” in Proceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2 , 2024, pp. 103–119
work page 2024
-
[16]
Neupims: Npu-pim heterogeneous acceleration for batched llm inferencing,
G. Heo, S. Lee, J. Cho, H. Choi, S. Lee, H. Ham, G. Kim, D. Ma- hajan, and J. Park, “Neupims: Npu-pim heterogeneous acceleration for batched llm inferencing,” in Proceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3 , 2024, pp. 722–737
work page 2024
-
[17]
Quest: Query-Aware Sparsity for Efficient Long-Context LLM Inference
J. Tang, Y . Zhao, K. Zhu, G. Xiao, B. Kasikci, and S. Han, “Quest: Query-aware sparsity for efficient long-context llm inference,” arXiv preprint arXiv:2406.10774, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Transpim: A memory- based acceleration via software-hardware co-design for transformer,
M. Zhou, W. Xu, J. Kang, and T. Rosing, “Transpim: A memory- based acceleration via software-hardware co-design for transformer,” in 2022 IEEE International Symposium on High-Performance Computer Architecture (HPCA). IEEE, 2022, pp. 1071–1085
work page 2022
-
[19]
Lol-pim: Long-context llm decoding with scalable dram-pim system,
H. Kwon, K. Koo, J. Kim, W. Lee, M. Lee, H. Lee, Y . Jung, J. Park, Y . Song, B. Yang et al. , “Lol-pim: Long-context llm decoding with scalable dram-pim system,” arXiv preprint arXiv:2412.20166 , 2024
-
[20]
Y . He, H. Mao, C. Giannoula, M. Sadrosadati, J. G ´omez-Luna, H. Li, X. Li, Y . Wang, and O. Mutlu, “Papi: Exploiting dynamic parallelism in large language model decoding with a processing-in-memory-enabled computing system,” arXiv preprint arXiv:2502.15470 , 2025
-
[21]
Model tells you where to merge: Adaptive kv cache merging for llms on long-context tasks,
Z. Wang, B. Jin, Z. Yu, and M. Zhang, “Model tells you where to merge: Adaptive kv cache merging for llms on long-context tasks,”arXiv preprint arXiv:2407.08454, 2024
-
[22]
How long can open-source llms truly promise on context length?
D. Li, R. Shao, A. Xie, Y . Sheng, L. Zheng, J. E. Gonzalez, I. Stoica, X. Ma, and H. Zhang, “How long can open-source llms truly promise on context length?” June 2023. [Online]. Available: https://lmsys.org/blog/2023-06-29-longchat
work page 2023
-
[23]
LongBench: A bilingual, multitask benchmark for long context understanding,
Y . Bai, X. Lv, J. Zhang, H. Lyu, J. Tang, Z. Huang, Z. Du, X. Liu, A. Zeng, L. Hou, Y . Dong, J. Tang, and J. Li, “LongBench: A bilingual, multitask benchmark for long context understanding,” in Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) . Bangkok, Thailand: Association for Computationa...
work page 2024
-
[24]
HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering
Z. Yang, P. Qi, S. Zhang, Y . Bengio, W. W. Cohen, R. Salakhutdinov, and C. D. Manning, “Hotpotqa: A dataset for diverse, explainable multi-hop question answering,” arXiv preprint arXiv:1809.09600 , 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[25]
A dataset of information-seeking questions and answers anchored in research papers,
P. Dasigi, K. Lo, I. Beltagy, A. Cohan, N. A. Smith, and M. Gardner, “A dataset of information-seeking questions and answers anchored in research papers,” arXiv preprint arXiv:2105.03011 , 2021
-
[26]
The narrativeqa reading comprehension challenge,
T. Ko ˇcisk`y, J. Schwarz, P. Blunsom, C. Dyer, K. M. Hermann, G. Melis, and E. Grefenstette, “The narrativeqa reading comprehension challenge,” Transactions of the Association for Computational Linguistics , vol. 6, pp. 317–328, 2018
work page 2018
-
[27]
TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension
M. Joshi, E. Choi, D. S. Weld, and L. Zettlemoyer, “Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension,” arXiv preprint arXiv:1705.03551 , 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[28]
Samsum corpus: A human-annotated dialogue dataset for abstractive summarization
B. Gliwa, I. Mochol, M. Biesek, and A. Wawer, “Samsum corpus: A human-annotated dialogue dataset for abstractive summarization,” arXiv preprint arXiv:1911.12237, 2019
-
[29]
Exploring the limits of transfer learning with a unified text-to-text transformer,
C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y . Zhou, W. Li, and P. J. Liu, “Exploring the limits of transfer learning with a unified text-to-text transformer,” Journal of machine learning research, vol. 21, no. 140, pp. 1–67, 2020
work page 2020
-
[30]
Longcoder: A long- range pre-trained language model for code completion,
D. Guo, C. Xu, N. Duan, J. Yin, and J. McAuley, “Longcoder: A long- range pre-trained language model for code completion,” in International Conference on Machine Learning . PMLR, 2023, pp. 12 098–12 107
work page 2023
-
[31]
Compressive Transformers for Long-Range Sequence Modelling
J. W. Rae, A. Potapenko, S. M. Jayakumar, and T. P. Lillicrap, “Com- pressive transformers for long-range sequence modelling,”arXiv preprint arXiv:1911.05507, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[32]
W. Lee, J. Lee, J. Seo, and J. Sim, “ {InfiniGen}: Efficient generative inference of large language models with dynamic {KV} cache manage- ment,” in 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24) , 2024, pp. 155–172
work page 2024
-
[33]
Sparq attention: Bandwidth-efficient llm inference,
L. Ribar, I. Chelombiev, L. Hudlass-Galley, C. Blake, C. Luschi, and D. Orr, “Sparq attention: Bandwidth-efficient llm inference,” arXiv preprint arXiv:2312.04985, 2023
-
[34]
Accelerating bandwidth-bound deep learning inference with main-memory accelerators,
B. Y . Cho, J. Jung, and M. Erez, “Accelerating bandwidth-bound deep learning inference with main-memory accelerators,” in Proceedings of the International Conference for High Performance Computing, Net- working, Storage and Analysis , 2021, pp. 1–14
work page 2021
-
[35]
Pim-llm: A high-throughput hybrid pim architecture for 1-bit llms,
J. Malekar, P. Chandarana, M. H. Amin, M. E. Elbtity, and R. Zand, “Pim-llm: A high-throughput hybrid pim architecture for 1-bit llms,” arXiv preprint arXiv:2504.01994 , 2025
-
[36]
Make llm inference affordable to everyone: Augmenting gpu memory with ndp-dimm,
L. Liu, S. Zhao, B. Li, H. Ren, Z. Xu, M. Wang, X. Li, Y . Han, and Y . Wang, “Make llm inference affordable to everyone: Augmenting gpu memory with ndp-dimm,” in 2025 IEEE International Symposium on High Performance Computer Architecture (HPCA) . IEEE, 2025, pp. 1751–1765
work page 2025
-
[37]
H2o: Heavy-hitter oracle for efficient generative inference of large language models,
Z. Zhang, Y . Sheng, T. Zhou, T. Chen, L. Zheng, R. Cai, Z. Song, Y . Tian, C. R´e, C. Barrett et al., “H2o: Heavy-hitter oracle for efficient generative inference of large language models,” Advances in Neural Information Processing Systems , vol. 36, pp. 34 661–34 710, 2023
work page 2023
-
[38]
Z. Liu, A. Desai, F. Liao, W. Wang, V . Xie, Z. Xu, A. Kyrillidis, and A. Shrivastava, “Scissorhands: Exploiting the persistence of importance hypothesis for llm kv cache compression at test time,” Advances in Neural Information Processing Systems , vol. 36, pp. 52 342–52 364, 2023
work page 2023
-
[39]
Model Tells You What to Discard: Adaptive KV Cache Compression for LLMs
S. Ge, Y . Zhang, L. Liu, M. Zhang, J. Han, and J. Gao, “Model tells you what to discard: Adaptive kv cache compression for llms,” arXiv preprint arXiv:2310.01801, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[40]
G. Liu, C. Li, J. Zhao, C. Zhang, and M. Guo, “Clusterkv: Manipulating llm kv cache in semantic space for recallable compression,” arXiv preprint arXiv:2412.03213, 2024
-
[41]
Squeezed attention: Accelerat- ing long context length llm inference,
C. Hooper, S. Kim, H. Mohammadzadeh, M. Maheswaran, J. Paik, M. W. Mahoney, K. Keutzer, and A. Gholami, “Squeezed attention: Accelerat- ing long context length llm inference,” arXiv preprint arXiv:2411.09688, 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.