Super-fast Rates of Convergence for Neural Network Classifiers under the Hard Margin Condition
Pith reviewed 2026-05-22 15:57 UTC · model grok-4.3
The pith
Deep neural networks achieve arbitrarily fast excess risk rates under the hard margin condition for many activations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
For DNNs solving the ERM problem with square loss and ell_p penalty, excess risk bounds of order O(n^{-α}) are achieved with α close to 1 under Tsybakov low-noise and with arbitrarily large α greater than 1 under the hard-margin condition, for a wide range of activations including ReLU, LeakyReLU, ELU, GELU, SiLU and others, provided the Bayes regression function η satisfies a distribution-adapted smoothness condition relative to the marginal distribution ρ_X; when the activation is tanh or sigmoid the rates follow from the standard assumption that η belongs to C^s; minimax lower bounds establish that these rates are optimal whenever the noise exponent q is at least 2.
What carries the argument
A novel decomposition of the excess risk for general ERM-based classifiers together with the distribution-adapted smoothness condition on the Bayes regression function η relative to ρ_X.
If this is right
- Excess risk decays at rates O(n^{-α}) with α arbitrarily large under the hard-margin condition.
- The same DNN training procedure yields rates near n^{-1} under Tsybakov low-noise conditions with any positive exponent.
- The fast rates hold for many common activations including ReLU, GELU, SiLU, and Softplus.
- For tanh and sigmoid activations the rates follow from the classical assumption that the regression function lies in C^s.
- Minimax lower bounds match the upper bounds whenever the noise exponent q is at least 2.
Where Pith is reading between the lines
- The novel excess-risk decomposition may be reusable for analyzing convergence of other ERM classifiers beyond deep networks.
- The distribution-adapted smoothness condition suggests DNNs can be applied in classification settings where standard uniform smoothness assumptions are too restrictive for most activations.
- One could check whether relaxing the smoothness requirement further still permits the arbitrarily fast rates for networks of fixed depth.
Load-bearing premise
The Bayes regression function must satisfy a smoothness condition that is adapted to the specific marginal distribution of the inputs rather than a uniform smoothness requirement that works for every distribution.
What would settle it
Construct a data distribution satisfying the hard-margin condition but where the excess risk achieved by DNN ERM with ReLU activation remains bounded below by a positive constant times n to the power of minus some fixed number; such an example would show that arbitrarily large alpha cannot be attained.
Figures









read the original abstract
We study the classical binary classification problem for hypothesis spaces of Deep Neural Networks (DNNs) under Tsybakov's low-noise condition with exponent $q>0$, as well as its limit case $q=\infty$, which we refer to as the \emph{hard margin condition}. We demonstrate that, for a wide range of commonly used activation functions (including but not limited to ReLU, LeakyReLU, ELU, CELU, SELU, Softplus, GELU, SiLU, Swish, Mish, and Softmax), DNN solutions to the empirical risk minimization (ERM) problem with square loss surrogate and $\ell_p$ penalty on the weights $(0<p<\infty)$ can achieve excess risk bounds of order $\mathcal{O}\left(n^{-\alpha}\right)$ for $\alpha$ close to $1$ under the low-noise condition, and for arbitrarily large $\alpha>1$ under the hard-margin condition, provided that the Bayes regression function $\eta$ satisfies a \emph{distribution-adapted smoothness} condition relative to the marginal data distribution $\rho_{X}$. Furthermore, when the activation function is chosen as $\tanh$ or sigmoid, we show that the same rates follow from the standard assumption that $\eta\in \mathcal{C}^s$. Finally, we establish minimax lower bounds, showing that these rates cannot be improved upon whenever $q\ge2$. Our proof relies on a novel decomposition of the excess risk for general ERM-based classifiers which might be of independent interest.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper establishes excess-risk bounds for DNN classifiers trained by ERM with square loss and ℓ_p weight penalty. Under Tsybakov's low-noise condition (exponent q>0) it obtains rates O(n^{-α}) with α close to 1; under the hard-margin case q=∞ it obtains arbitrarily large α>1. These rates hold for a wide family of activations (ReLU, LeakyReLU, GELU, etc.) provided the Bayes regressor η satisfies a distribution-adapted smoothness condition relative to the marginal ρ_X; for tanh/sigmoid the standard C^s assumption suffices. Matching minimax lower bounds are shown for q≥2. The argument rests on a novel excess-risk decomposition.
Significance. If the central claims are correct, the results would be significant: they deliver super-fast rates under the hard-margin condition for activations beyond the classical tanh/sigmoid setting, and the novel decomposition may be reusable. The matching lower bounds for q≥2 are a clear strength. The distribution-adapted smoothness assumption, however, is the load-bearing premise whose verification and comparison with C^s remain to be fully substantiated.
major comments (3)
- [Definition of distribution-adapted smoothness] Definition of distribution-adapted smoothness (likely §2 or §3): the condition is invoked to obtain the approximation rates needed for general activations, yet the manuscript provides no explicit verification that it holds for standard data-generating processes (e.g., Gaussian mixtures or uniform on the sphere) nor demonstrates that it is strictly weaker than the classical C^s assumption in the regimes where super-fast rates are claimed. This premise directly controls both approximation and excess-risk bounds under q=∞.
- [Excess-risk decomposition] Excess-risk decomposition (the novel step referenced in the abstract): the decomposition separates approximation, estimation, and noise terms; however, the passage from the adapted smoothness of η to the required DNN approximation rate for non-smooth activations is not shown in sufficient detail to confirm that the resulting α can be made arbitrarily large under hard margin.
- [Minimax lower bounds] Minimax lower-bound construction (final section): the lower bounds match the upper bounds for q≥2, but it is unclear whether the adversarial distributions used in the lower-bound argument also satisfy the distribution-adapted smoothness condition required for the upper bounds; if they do not, the claimed optimality is not fully established.
minor comments (2)
- Notation for the marginal ρ_X and the adapted smoothness modulus should be introduced once and used consistently; several passages reuse symbols without redefinition.
- The statement that the rates hold 'for arbitrarily large α>1' under hard margin should be accompanied by an explicit dependence of α on the smoothness parameters and network depth/width.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The comments highlight important points that we can address through clarifications, additional examples, and expanded proof details in a revised manuscript. Below we respond point by point to the major comments.
read point-by-point responses
-
Referee: [Definition of distribution-adapted smoothness] Definition of distribution-adapted smoothness (likely §2 or §3): the condition is invoked to obtain the approximation rates needed for general activations, yet the manuscript provides no explicit verification that it holds for standard data-generating processes (e.g., Gaussian mixtures or uniform on the sphere) nor demonstrates that it is strictly weaker than the classical C^s assumption in the regimes where super-fast rates are claimed. This premise directly controls both approximation and excess-risk bounds under q=∞.
Authors: We agree that concrete verification would improve the presentation. In the revision we will add a dedicated remark (or short subsection) in Section 2 that explicitly verifies the distribution-adapted smoothness condition for standard examples, including isotropic Gaussian mixtures and uniform distributions on the sphere, under mild regularity assumptions on the Bayes regressor η. We will also include a direct comparison with the classical C^s assumption, showing regimes (e.g., when ρ_X has regions of low density) in which the adapted condition is strictly weaker while still permitting arbitrarily large α under q=∞. revision: yes
-
Referee: [Excess-risk decomposition] Excess-risk decomposition (the novel step referenced in the abstract): the decomposition separates approximation, estimation, and noise terms; however, the passage from the adapted smoothness of η to the required DNN approximation rate for non-smooth activations is not shown in sufficient detail to confirm that the resulting α can be made arbitrarily large under hard margin.
Authors: We will expand the relevant proof section (currently Section 4) to include a more detailed, step-by-step derivation that explicitly connects the distribution-adapted smoothness of η to the DNN approximation error for non-smooth activations such as ReLU. The added steps will track the dependence on the smoothness parameters and demonstrate how α can be made arbitrarily large by increasing the smoothness index of η while respecting the hard-margin condition q=∞. revision: yes
-
Referee: [Minimax lower bounds] Minimax lower-bound construction (final section): the lower bounds match the upper bounds for q≥2, but it is unclear whether the adversarial distributions used in the lower-bound argument also satisfy the distribution-adapted smoothness condition required for the upper bounds; if they do not, the claimed optimality is not fully established.
Authors: We will revise the lower-bound section to clarify that the adversarial distributions can be constructed so that the associated regression function η satisfies the distribution-adapted smoothness condition while preserving the Tsybakov exponent q≥2 (or the hard-margin case). This is achieved by selecting sufficiently regular η that still induce the desired noise behavior; the revised argument will explicitly verify that the same class of distributions is used for both upper and lower bounds, thereby establishing matching minimax rates under the paper’s assumptions. revision: yes
Circularity Check
No significant circularity; derivation rests on explicit assumptions and novel decomposition
full rationale
The paper derives excess-risk bounds from the low-noise/hard-margin conditions plus the stated distribution-adapted smoothness assumption on η (or C^s for tanh/sigmoid). A novel decomposition of excess risk for general ERM classifiers is introduced and used to control approximation and estimation errors. This decomposition supplies independent content rather than reducing the target rates to a fit or to a self-citation chain. The smoothness premise is an input assumption, not a quantity fitted to the excess-risk target or smuggled via prior self-citation. Minimax lower bounds are proved separately and do not rely on the upper-bound construction. No quoted equation or step equates the claimed rates to the inputs by definition.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Tsybakov's low-noise condition with exponent q>0 (and its limit q=∞ as hard margin)
- domain assumption Distribution-adapted smoothness of the Bayes regression function η relative to ρ_X
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We demonstrate that ... DNN solutions to the ERM problem with square loss surrogate and ℓ_p penalty ... achieve excess risk bounds of order O(n^{-α}) ... provided that the Bayes regression function η satisfies a distribution-adapted smoothness condition relative to the marginal data distribution ρ_X.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our proof relies on a novel decomposition of the excess risk for general ERM-based classifiers
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
40 Published in Transactions on Machine Learning Research (05/2026) Mahyar Fazlyab, Alexander Robey, Hamed Hassani, Manfred Morari, and George Pappas. Efficient and accurate estimation of lipschitz constants for deep neural networks.Advances in Neural Information Processing Systems, 32,
work page 2026
-
[2]
Ian Goodfellow, Yoshua Bengio, and Aaron Courville.Deep Learning
URLhttp://dblp.uni-trier.de/db/conf/iclr/ iclr2019.html#FrankleC19. Ian Goodfellow, Yoshua Bengio, and Aaron Courville.Deep Learning. MIT Press, 2016.http://www. deeplearningbook.org. László Györfi, Michael Köhler, Adam Krzyżak, and Harro Walk.A distribution-free theory of nonparametric regression, volume
work page 2016
-
[3]
Tianyang Hu, Jun Wang, Wenjia Wang, and Zhenguo Li. Understanding square loss in training over- parametrized neural network classifiers.arXiv preprint arXiv:2112.03657,
-
[4]
Onexcessriskconvergenceratesofneuralnetworkclassifiers
HyunoukKo, NamjoonSuh, andXiaomingHuo. Onexcessriskconvergenceratesofneuralnetworkclassifiers. arXiv preprint arXiv:2309.15075,
-
[5]
Vladimir Koltchinskii.Oracle inequalities in empirical risk minimization and sparse recovery problems: Ecole D’Eté de Probabilités de Saint-Flour XXXVIII-2008, volume
work page 2008
-
[6]
Exponential convergence rates in classification
Vladimir Koltchinskii and Olexandra Beznosova. Exponential convergence rates in classification. InLearning Theory: 18th Annual Conference on Learning Theory, COLT 2005, Bertinoro, Italy, June 27-30,
work page 2005
-
[7]
URLhttps://www.numdam.org/item/10.5802/aif
doi: 10.5802/aif.1638. URLhttps://www.numdam.org/item/10.5802/aif. 1638.pdf. GuoyinLiandTingKeiPong. Calculusoftheexponentofkurdyka–łojasiewiczinequalityanditsapplications to linear convergence of first-order methods.Foundations of computational mathematics, 18(5):1199–1232,
-
[8]
41 Published in Transactions on Machine Learning Research (05/2026) Ziming Liu, Yixuan Wang, Sachin Vaidya, Fabian Ruehle, James Halverson, Marin Soljacic, Thomas Y. Hou, and Max Tegmark. KAN: Kolmogorov–arnold networks. InThe Thirteenth International Conference on Learning Representations,
work page 2026
-
[9]
Philipp Petersen and Felix Voigtlaender. Optimal learning of high-dimensional classification problems using deep neural networks.arXiv preprint arXiv:2112.12555,
-
[10]
doi: 10.1007/978-1-4612-1970-5
ISBN 978-0-8176-3913-4. doi: 10.1007/978-1-4612-1970-5. SteveSmaleandDing-XuanZhou. Learningtheoryestimatesviaintegraloperatorsandtheirapproximations. Constructive approximation, 26(2):153–172,
-
[11]
Fast rates for support vector machines
42 Published in Transactions on Machine Learning Research (05/2026) Ingo Steinwart and Clint Scovel. Fast rates for support vector machines. InLearning Theory: 18th Annual Conference on Learning Theory, COLT 2005, Bertinoro, Italy, June 27-30,
work page 2026
-
[12]
Chuanyun Xu, Wenjian Gao, Tian Li, Nanlan Bai, Gang Li, and Yang Zhang. Teacher-student collaborative knowledge distillation for image classification.Applied Intelligence, 53(2):1997–2009,
work page 1997
-
[13]
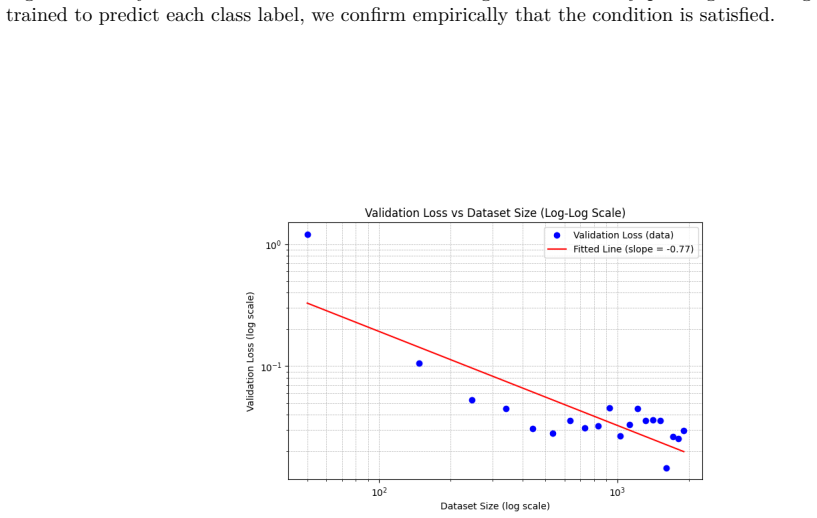
43 Published in Transactions on Machine Learning Research (05/2026) A Margin conditions for real-life datasets The goal of this section is to empirically evaluate the validity of margin conditions on two widely-used benchmark classification datasets: Fashion MNIST and CIFAR-10. Since both datasets contain more than two classes, we fall back to the binary ...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.