Understanding Task Representations in Neural Networks via Bayesian Ablation
Pith reviewed 2026-05-22 13:44 UTC · model grok-4.3
The pith
A Bayesian distribution over neural network units reveals their causal contributions to task performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors argue that defining a distribution over representational units and performing Bayesian ablation lets researchers infer the causal contributions of those units to task performance, while information-theoretic tools simultaneously characterize representational distributedness, manifold complexity, and polysemanticity.
What carries the argument
The central mechanism is the probability distribution placed over representational units, which supports inference of causal contributions through controlled ablation or sampling.
If this is right
- The framework identifies which units are most responsible for success on a specific task.
- It supplies a quantitative measure of how distributed a representation is across units.
- The metrics can evaluate the geometric complexity of the learned manifold.
- It detects polysemantic units that participate in multiple distinct concepts.
Where Pith is reading between the lines
- The same distribution-based ablation could be used to compare representations learned by networks trained under different objectives or architectures.
- Low-contribution units identified by the method might be candidates for removal during model compression.
- The metrics for distributedness and polysemanticity could guide the design of training procedures that encourage more disentangled representations.
Load-bearing premise
Ablating or sampling from a distribution over representational units accurately isolates their causal contributions without being confounded by the network's training dynamics or architecture-specific interactions.
What would settle it
Apply the method to a linear classifier with known feature weights and check whether the inferred causal contributions recover the true importance of each unit.
Figures



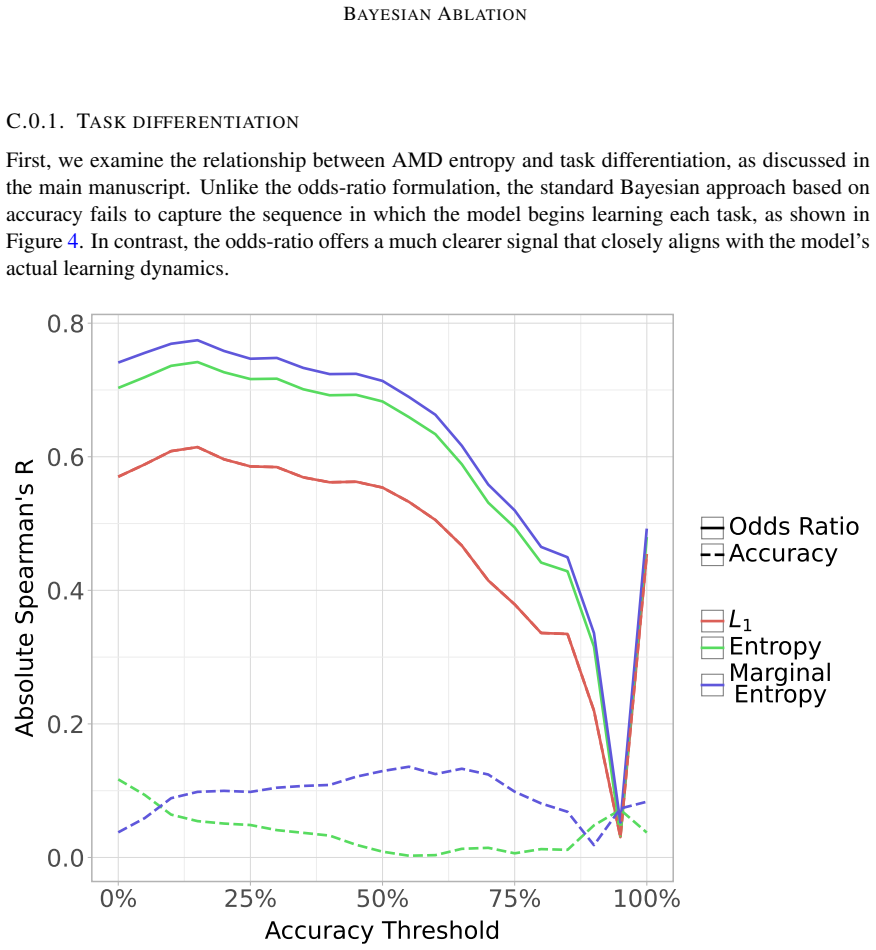
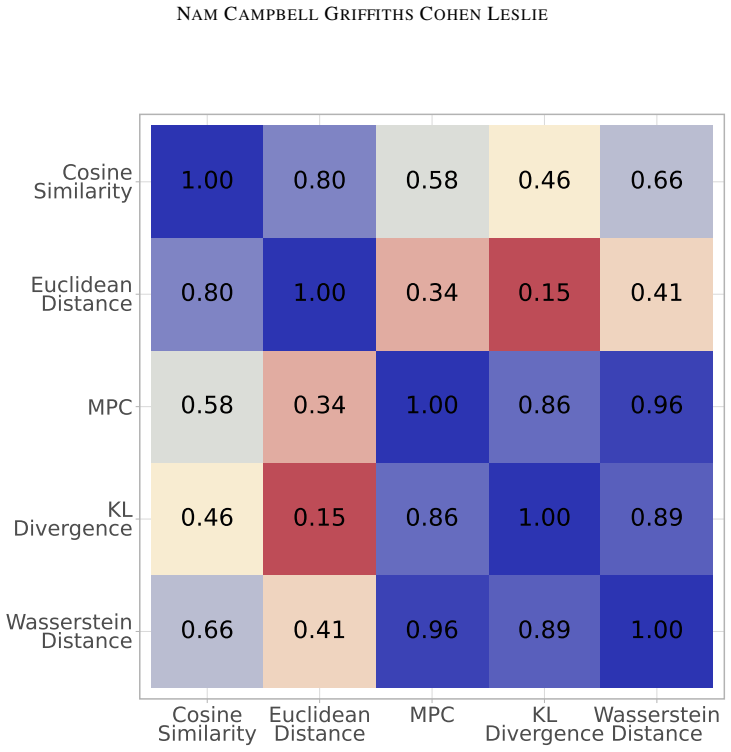


read the original abstract
Neural networks are powerful tools for cognitive modeling due to their flexibility and emergent properties. However, interpreting their learned representations remains challenging due to their sub-symbolic semantics. In this work, we introduce a novel probabilistic framework for interpreting latent task representations in neural networks. Inspired by Bayesian inference, our approach defines a distribution over representational units to infer their causal contributions to task performance. Using ideas from information theory, we propose a suite of tools and metrics to illuminate key model properties, including representational distributedness, manifold complexity, and polysemanticity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a novel probabilistic framework for interpreting latent task representations in neural networks. It defines a distribution over representational units to infer their causal contributions to task performance and proposes information-theoretic metrics to quantify properties including representational distributedness, manifold complexity, and polysemanticity.
Significance. If the causal inferences hold after accounting for training dynamics, the framework could provide a principled Bayesian approach to neural interpretability, extending cognitive modeling tools with quantitative metrics for distributed and polysemantic representations.
major comments (1)
- [§3] The central claim that ablation/sampling from the distribution over units isolates causal contributions (abstract and §3) is load-bearing but lacks a derivation showing how the posterior accounts for unmodeled dependencies such as compensatory effects during training or architecture-specific unit interactions; without this, performance changes may reflect redundancies rather than true causality.
minor comments (2)
- [Methods] Clarify the exact form of the proposed distribution over representational units and how it is fit from data.
- [Related Work] Add explicit comparison to existing ablation or attribution methods (e.g., integrated gradients or causal mediation analysis) to highlight novelty.
Simulated Author's Rebuttal
We thank the referee for their constructive and insightful comments on our manuscript. The feedback on the causal interpretation of the Bayesian ablation framework is particularly valuable, and we have revised the paper to address the concerns raised while clarifying the scope and assumptions of our approach.
read point-by-point responses
-
Referee: [§3] The central claim that ablation/sampling from the distribution over units isolates causal contributions (abstract and §3) is load-bearing but lacks a derivation showing how the posterior accounts for unmodeled dependencies such as compensatory effects during training or architecture-specific unit interactions; without this, performance changes may reflect redundancies rather than true causality.
Authors: We agree that the original manuscript would benefit from a more explicit derivation and discussion of assumptions regarding causal isolation. In the revised version, we have added a formal derivation in §3 that applies Bayes' rule to compute the posterior over units, with the likelihood defined in terms of the observed change in task performance following ablation or sampling. This derivation proceeds under the modeling assumption of conditional independence among units given the performance metric. We have also inserted a dedicated limitations subsection that directly addresses unmodeled dependencies, including compensatory effects that may arise during training and architecture-specific interactions. The text now explicitly states that performance changes could reflect redundancies in some settings and that the inferred contributions are best viewed as effective causal roles under the stated assumptions rather than exhaustive causal attributions. To help readers diagnose such cases, we have expanded the description of the information-theoretic metrics (distributedness, manifold complexity, and polysemanticity) as diagnostic tools. Additional controlled experiments have been included to illustrate the framework's behavior when redundancies are present. These revisions clarify the claims without overstating the isolation of causality. revision: partial
Circularity Check
Bayesian ablation framework introduces new definitions without reducing to self-referential inputs
full rationale
The paper presents a novel probabilistic framework that defines a distribution over representational units and uses ablation/sampling to quantify causal contributions, drawing on Bayesian inference and information theory concepts. No equations, fitted parameters, or self-citations are shown in the provided text that would make any claimed result equivalent to its inputs by construction. The central contribution is the introduction of this interpretive tool itself, which remains self-contained as a methodological proposal rather than a derivation that loops back to presuppose its own outputs. No load-bearing steps reduce predictions to prior fits or author-specific uniqueness theorems.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Bayesian inference can be used to define distributions over representational units and infer causal contributions to task performance.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Ale- man, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Centaur: a foundation model of human cognition.arXiv preprint arXiv:2410.20268,
Marcel Binz, Elif Akata, Matthias Bethge, Franziska Br ¨andle, Fred Callaway, Julian Coda-Forno, Peter Dayan, Can Demircan, Maria K Eckstein, No´emi ´Eltet˝o, et al. Centaur: a foundation model of human cognition.arXiv preprint arXiv:2410.20268,
-
[3]
Sparks of Artificial General Intelligence: Early experiments with GPT-4
https://transformer- circuits.pub/2023/monosemantic-features/index.html. S´ebastien Bubeck, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Ka- mar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott Lundberg, et al. Sparks of artificial general intelligence: Early experiments with gpt-4.arXiv preprint arXiv:2303.12712,
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
doi: 10.1214/aos/1176344552. Nelson Elhage, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, Shauna Kravec, Zac Hatfield-Dodds, Robert Lasenby, Dawn Drain, Carol Chen, Roger Grosse, Sam McCandlish, Jared Kaplan, Dario Amodei, Martin Wattenberg, and Christopher Olah. Toy models of superposition.Transformer Circuits Thread,
-
[5]
Kayson Fakhar and Claus C Hilgetag
https://transformer- circuits.pub/2022/toy model/index.html. Kayson Fakhar and Claus C Hilgetag. Systematic perturbation of an artificial neural network: A step towards quantifying causal contributions in the brain.PLOS Computational Biology, 18(6): e1010250,
work page 2022
-
[6]
Adam: A Method for Stochastic Optimization
Diederik P Kingma. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
An analytic theory of generalization dynamics and transfer learning in deep linear networks
Andrew K Lampinen and Surya Ganguli. An analytic theory of generalization dynamics and transfer learning in deep linear networks.arXiv preprint arXiv:1809.10374,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
The Thirty-Ninth Annual Conference on Neural Information Processing Systems (NeurIPS 2025). Radford M Neal. Probabilistic inference using markov chain monte carlo methods
work page 2025
-
[9]
https://transformer-circuits.pub/2022/in-context-learning-and-induction-heads/index.html. OpenAI. Gpt-5 system card. Technical report, OpenAI, August
work page 2022
-
[10]
G Storms. Flemish category norms for exemplars of 39 categories: A replication of the battig and montague (1969) category norms: Pet studies.Brain, 124:1619–1634,
work page 1969
-
[11]
Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned
Elena V oita, David Talbot, Fedor Moiseev, Rico Sennrich, and Ivan Titov. Analyzing multi-head self-attention: Specialized heads do the heavy lifting, the rest can be pruned.arXiv preprint arXiv:1905.09418,
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[12]
Understanding Neural Networks Through Deep Visualization
Jason Yosinski, Jeff Clune, Anh Nguyen, Thomas Fuchs, and Hod Lipson. Understanding neural networks through deep visualization.arXiv preprint arXiv:1506.06579,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Skill-mix: A flexible and expandable family of evaluations for ai models
Dingli Yu, Simran Kaur, Arushi Gupta, Jonah Brown-Cohen, Anirudh Goyal, and Sanjeev Arora. Skill-mix: A flexible and expandable family of evaluations for ai models.arXiv preprint arXiv:2310.17567,
-
[14]
Visualizing and understanding convolutional networks
Matthew D Zeiler and Rob Fergus. Visualizing and understanding convolutional networks. In Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6- 12, 2014, Proceedings, Part I 13, pages 818–833. Springer,
work page 2014
-
[15]
with a learning rate of 0.001. Appendix E. Tables and figures A-Category A-Name A-Size C-coord C-subord C-super C-syn E-abstract E-beh E-excomp E-exsurfNV E-exsurfV E-incomp E-insurfNV E-insurfV E-mat E-quant E-sys E-whole I-contin I-emot I-eval LEX-exp LEX-fcc S-action S-build S-event S-function S-living S-loc S-manner S-object S-person S-physt S-socart ...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.