Frankentext: Stitching random text fragments into long-form narratives
Pith reviewed 2026-05-19 12:52 UTC · model grok-4.3
The pith
LLMs generate higher-quality long stories by mostly copying and stitching random human text fragments rather than writing freely.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Frankentexts are produced by giving an LLM a writing prompt plus thousands of randomly sampled human paragraphs and instructing it to form a narrative while copying most tokens verbatim from the supplied fragments. The LLM explores the combinatorial possibilities of choosing and sequencing these snippets, then stitches them with light edits to maintain coherence and prompt relevance. Automatic and human evaluations find that the resulting texts exceed vanilla LLM outputs in writing quality, diversity, and originality, remain coherent, and are frequently misclassified as human-written by state-of-the-art detectors such as Pangram.
What carries the argument
The Frankentext procedure that treats the LLM as a composer selecting, ordering, and minimally stitching random human snippets under a high verbatim-copy constraint.
If this is right
- Long-form generation can achieve higher originality and diversity without increasing the amount of newly generated text.
- Current AI-text detectors become significantly less reliable when outputs are built by stitching existing human fragments.
- Questions of authorship and copyright intensify when the raw material is human-written and the LLM only orchestrates it.
- The method offers a way to control stylistic and tonal variety by varying the source snippet pool.
Where Pith is reading between the lines
- This stitching approach may generalize to other creative tasks such as script or poetry generation where source material is abundant.
- Training data policies for LLMs could need revision if outputs are shown to be largely derivative of specific human sources.
- New legal or technical mechanisms for attributing contributions from the original snippet authors may become necessary.
Load-bearing premise
An LLM can implicitly explore the combinatorial space of selecting and ordering thousands of random snippets to form a coherent story while copying most tokens verbatim with only minimal new text.
What would settle it
A head-to-head comparison in which the same set of random snippets is given to skilled human writers who must also copy most tokens and produce stories; if humans produce clearly superior results or if improved detectors correctly flag most Frankentexts, the performance claims would not hold.
Figures






















read the original abstract
We introduce Frankentexts, a long-form narrative generation paradigm that treats an LLM as a composer of existing texts rather than as an author. Given a writing prompt and thousands of randomly sampled human-written snippets, the model is asked to produce a narrative under the extreme constraint that most tokens (e.g., 90%) must be copied verbatim from the provided paragraphs. This task is effectively intractable for humans: selecting and ordering snippets yields a combinatorial search space that an LLM implicitly explores, before minimally editing and stitching together selected fragments into a coherent long-form story. Despite the extreme challenge of the task, we observe through extensive automatic and human evaluation that Frankentexts significantly improve over vanilla LLM generations in terms of writing quality, diversity, and originality while remaining coherent and relevant to the prompt. Furthermore, Frankentexts pose a fundamental challenge to detectors of AI-generated text: 72% of Frankentexts produced by our best Gemini 2.5 Pro configuration are misclassified as human-written by Pangram, a state-of-the-art detector. Human annotators praise Frankentexts for their inventive premises, vivid descriptions, and dry humor; on the other hand, they identify issues with abrupt tonal shifts and uneven grammar across segments, particularly in longer pieces. The emergence of high-quality Frankentexts raises serious questions about authorship and copyright: when humans provide the raw materials and LLMs orchestrate them into new narratives, who truly owns the result?
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Frankentexts, a long-form narrative generation method in which an LLM is prompted to select, order, and minimally stitch thousands of randomly sampled human-written text snippets into a coherent story, subject to an explicit constraint that the great majority of output tokens (target ~90%) must be copied verbatim from the provided fragments. The central empirical claims are that the resulting texts outperform standard LLM generations on writing quality, diversity, and originality while preserving coherence and prompt relevance, and that they substantially evade state-of-the-art AI-text detectors (72% misclassification rate by Pangram for the best Gemini 2.5 Pro configuration).
Significance. If the results are robust, the work demonstrates that LLMs can implicitly solve a large-scale combinatorial selection-and-ordering task over noisy human fragments while satisfying a strict verbatim-copy constraint. This has direct implications for constrained generation, hybrid human-AI authorship, copyright questions, and the reliability of current detectors. The combination of automatic metrics, human judgments, and a concrete detector-evasion result supplies a falsifiable empirical contribution.
major comments (1)
- [Method / Experimental Setup] Method / Experimental Setup (exact section not numbered in abstract but referenced via the 90% verbatim instruction): the manuscript states that the LLM is instructed to copy most tokens verbatim yet reports no post-generation verification of the realized copy rate. No LCS, n-gram overlap, or normalized edit-distance statistics against the input snippet pool are provided. Because the quality, diversity, and 72% detector-evasion claims rest on the premise that the model is performing true stitching rather than ordinary generation with incidental fragment insertion, the absence of this measurement is load-bearing for the central interpretation.
minor comments (2)
- [Evaluation] Human evaluation protocol: specify the exact number of annotators, inter-annotator agreement (e.g., Krippendorff’s alpha or Fleiss’ kappa), and the precise rating scales used for coherence, originality, and tonal-shift judgments.
- [Results] Detector result: state the total number of Frankentexts evaluated for the 72% Pangram figure, the exact prompt template and snippet count for the “best Gemini 2.5 Pro configuration,” and whether the same detector was run on the vanilla-LLM baseline for direct comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for highlighting the importance of verifying the core mechanism underlying Frankentext generation. We address the single major comment below and will revise the manuscript accordingly to strengthen the empirical foundation of our claims.
read point-by-point responses
-
Referee: the manuscript states that the LLM is instructed to copy most tokens verbatim yet reports no post-generation verification of the realized copy rate. No LCS, n-gram overlap, or normalized edit-distance statistics against the input snippet pool are provided. Because the quality, diversity, and 72% detector-evasion claims rest on the premise that the model is performing true stitching rather than ordinary generation with incidental fragment insertion, the absence of this measurement is load-bearing for the central interpretation.
Authors: We agree that post-generation verification of the verbatim copy rate is necessary to confirm that the outputs result from the intended large-scale stitching process under the explicit constraint rather than from standard unconstrained generation. The submitted manuscript relied on the prompt's explicit instruction to copy ~90% of tokens verbatim and on qualitative inspection of samples, but did not report quantitative overlap statistics. In the revised version we will add a dedicated analysis (in the Experiments section or Appendix) that computes longest common subsequence (LCS) lengths, normalized edit distance, and n-gram overlap (e.g., 5-grams) between each generated Frankentext and the full pool of input snippets. This will quantify the realized copy rate, demonstrate adherence to the constraint, and directly support the interpretation of the quality, diversity, and detector-evasion results. revision: yes
Circularity Check
No significant circularity in empirical task and evaluation
full rationale
The paper introduces Frankentexts as an empirical generation paradigm and supports its claims of improved quality, diversity, originality, coherence, and detector evasion through automatic metrics and human evaluation. No mathematical derivations, equations, fitted parameters, or predictions are presented that reduce to inputs by construction. The task definition (copying ~90% tokens from random snippets) and results are externally verifiable via the described experiments rather than self-referential. This is a standard non-circular empirical systems paper with independent content in its evaluations.
Axiom & Free-Parameter Ledger
free parameters (1)
- verbatim copy rate =
90%
axioms (1)
- domain assumption LLMs can implicitly explore the combinatorial space of selecting and ordering thousands of random snippets to form coherent narratives
invented entities (1)
-
Frankentext
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Given a writing prompt and thousands of randomly sampled human-written snippets, the model is asked to produce a narrative under the extreme constraint that most tokens (e.g., 90%) must be copied verbatim
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Frankentexts improve over vanilla LLM generations in key writing quality metrics such as diversity and novelty
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
All that‘s ‘human’ is not gold: Evaluating human evaluation of generated text. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 7282–7296, Online. Association for Computational Linguistics. Isaac David and Arth...
-
[2]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capa- bility in llms via reinforcement learning.Preprint, arXiv:2501.12948. Liam Dugan, Alyssa Hwang, Filip Trhlík, Andrew Zhu, Josh Magnus Ludan, Hainiu Xu, Daphne Ip- polito, and Chris Callison-Burch. 2024. RAID: A shared benchmark for robust evaluation of machine- generated text detectors. InProceedings of the 62nd ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
InProceedings of the 41st International Conference on Machine Learning, ICML’24
Spotting llms with binoculars: zero-shot detection of machine-generated text. InProceedings of the 41st International Conference on Machine Learning, ICML’24. JMLR.org. Jessica He, Stephanie Houde, and Justin D. Weisz. 2025. Which contributions deserve credit? perceptions of attribution in human-ai co-creation. InProceedings of the 2025 CHI Conference on ...
-
[4]
Outfox: Llm-generated essay detection through in-context learning with adversarially gen- erated examples. InProceedings of the Thirty- Eighth AAAI Conference on Artificial Intelligence and Thirty-Sixth Conference on Innovative Applica- tions of Artificial Intelligence and Fourteenth Sym- posium on Educational Advances in Artificial Intelli- gence, AAAI’2...
-
[5]
AI use in American newspapers is widespread, uneven, and rarely disclosed
Towards coherent and consistent use of entities in narrative generation. InInternational Conference on Machine Learning, pages 17278–17294. PMLR. Chau Minh Pham, Simeng Sun, and Mohit Iyyer. 2024. Suri: Multi-constraint instruction following in long- form text generation. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 1722–...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Skywork: A more open bilingual foundation model.Preprint, arXiv:2310.19341. 14 Yuhao Wu, Ming Shan Hee, Zhiqiang Hu, and Roy Ka-Wei Lee. 2025. Longgenbench: Benchmark- ing long-form generation in long context LLMs. In The Thirteenth International Conference on Learning Representations. Zhuohan Xie, Trevor Cohn, and Jey Han Lau. 2023. The next chapter: A s...
-
[7]
search – query the FAISS semantic index
-
[8]
fetch – retrieve the full excerpt/passage for a selected result. For each prompt iteration, you must make at least 20 calls to the MCP server to get enough materials to write a story. Figure 13: System prompt for MCP calls Copy Rate Average AI Fraction 0 10 20 30 40 50 60 70 80 90 Percentage (%) 74.8% 15.5% 68.4% 23.1% r/WritingPrompts T ell me a story Fi...
-
[9]
Plot/Event Incoherence: Events that happen without believable causes or effects, or an outcome contradicts earlier set-ups
-
[10]
Character Incoherence: A character’s characteristics (personality, knowledge, or abilities) and actions suddenly change without explanations
-
[11]
Spatial Incoherence: The physical layout of settings (rooms, cities, or worlds) changes suddenly
-
[12]
Thematic Incoherence: Central messages clash or disappear; symbolism introduced early never pays off, themes collide, The mood, register, or genre conventions shift without motivation
-
[13]
First, read the story: {story} Answer TRUE if the story is coherent
Surface-Level Incoherence: Pronouns, tense, narrative voice, or names flip mid-sentence; repeated or missing words; malformed sentences. First, read the story: {story} Answer TRUE if the story is coherent. Answer FALSE if the story is incoherent, i.e. contains issues that, if left unresolved, significantly affect the reader’s ability to understand the mai...
-
[14]
Ignoring or misinterpretating the premise: Key plot events, characters, or settings required by the premise are not included or falsely represented in the story
-
[15]
Hallucinating details that contradict the premise: The story introduces details that make the premise impossible
-
[16]
Failure to maintain the specified tones, genres, or other constraints: The story do not use the surface-level constraints (correct tones, genres, point of views, length, etc.), as required by the premise. First, read the premise: {writing_prompt} Next, read the story: {story} Answer TRUE if the story is faithful to the premise. Answer FALSE if the story c...
-
[17]
Penalize neat, overly structured, or cinematic arcs that feel artificial or generic
Plot: Favor stories with surprising turns and creative structures. Penalize neat, overly structured, or cinematic arcs that feel artificial or generic
-
[18]
Penalize reliance on cliches, tropes, or smooth but unremarkable devices
Creativity: Reward originality of perspective, voice, and risk-taking. Penalize reliance on cliches, tropes, or smooth but unremarkable devices
-
[19]
Do not reward over-explained or archetypal development
Development: Characters and settings should feel psychologically complex. Do not reward over-explained or archetypal development
-
[20]
Penalize polished, ornamental, or overly literary prose that feels mechanical or detached
Language Use: Prefer authentic, striking, and emotionally charged expression, even if rough , fragmented, or unusual. Penalize polished, ornamental, or overly literary prose that feels mechanical or detached. Provide a detailed assessment of the story in terms of these four dimensions. Conclude your assessment with scores using the template below. Do not ...
work page 2025
-
[22]
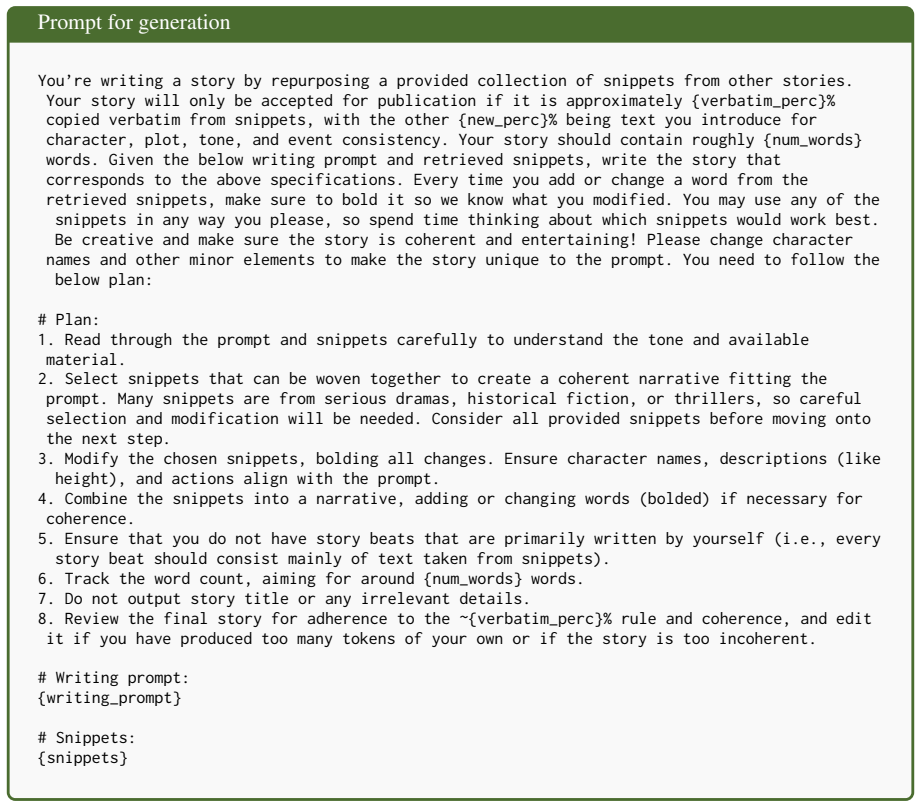
Select snippets that can be woven together to create a coherent narrative fitting the prompt. Many snippets are from serious dramas, historical fiction, or thrillers, so careful selection and modification will be needed. Consider all provided snippets before moving onto the next step
-
[24]
Combine the snippets into a narrative, adding or changing words (bolded) if necessary for coherence
-
[25]
Ensure that you do not have story beats that are primarily written by yourself (i.e., every story beat should consist mainly of text taken from snippets)
-
[27]
Do not output story title or any irrelevant details
-
[28]
Review the final story for adherence to the ~{verbatim_perc}% rule and coherence, and edit it if you have produced too many tokens of your own or if the story is too incoherent. # Writing prompt: {writing_prompt} # Snippets: {snippets} Figure 21: Prompt for generation Prompt for generation revise This story contains way too much of your own writing! It’s ...
-
[29]
Read the generated story and writing prompt to understand the established context, plot, characters, and tone
-
[32]
Implement the changes. Keep additions minimal, but feel free to delete larger spans ( phrases, sentences, paragraphs, etc.) whenever material is irrelevant or incoherent
-
[33]
Review the final story for coherence adherence to the ~{verbatim_perc}% rule and coherence, and edit it if you have produced too many tokens of your own or if the story is too incoherent
-
[34]
Output the edited writing and no other details. If there is no edit to be made, output "NO EDITS" Figure 23: Prompt for editing the first draft ofFrankentexts 38 Prompt for nonfiction generation You’re writing a news article by repurposing a provided collection of snippets from other stories. Your news article will only be accepted for publication if it i...
-
[35]
Read through the prompt and snippets carefully to understand the tone and available material
-
[36]
Select snippets that can be woven together to create a coherent and factual narrative fitting the prompt. Many snippets are from serious dramas, historical fiction, or thrillers, so careful selection and modification will be needed. Consider all provided snippets before moving onto the next step
-
[37]
Ensure character names, descriptions (like height), and actions align with the prompt
Modify the chosen snippets, bolding all changes. Ensure character names, descriptions (like height), and actions align with the prompt
-
[38]
Combine the snippets into a narrative, adding or changing words (bolded) if necessary for coherence and factuality
-
[39]
Ensure that you do not have news article beats that are primarily written by yourself (i.e ., every news article beat should consist mainly of text taken from snippets)
-
[40]
Track the word count, aiming for around {num_words} words
-
[41]
Do not output news article title or any irrelevant details
-
[42]
Review the final news article for adherence to the ~{verbatim_perc}% rule, factuality and coherence, and edit it if you have produced too many tokens of your own or if the news article is too incoherent or non-factual. # Writing prompt: {writing_prompt} # Snippets: {snippets} Figure 24: Prompt for nonfiction generation Prompt for nonfiction generation rev...
-
[43]
Read the generated news article and writing prompt to understand the established context, plot, characters, and tone
-
[44]
For each sentence in the text, identify the specific spans of inconsistency within the generated text
-
[45]
Identify minimal edits needed to correct these inconsistencies while respecting the { verbatim_perc}% rule. - Contradictions: Information that conflicts with other details within the text (e.g., character traits, setting descriptions, established facts). - Continuity errors: Actions or details that conflict with the established timeline or sequence of eve...
-
[46]
Implement the changes. Keep additions minimal, but feel free to delete larger spans ( phrases, sentences, paragraphs, etc.) whenever material is irrelevant, incoherent, or non- factual
-
[47]
Review the final news article for coherence adherence to the ~{verbatim_perc}% rule and coherence, and edit it if you have produced too many tokens of your own or if the news article is too incoherent or non-factual
-
[48]
Output the edited writing and no other details. If there is no edit to be made, output "NO EDITS". Figure 26: Prompt for nonfiction edit Prompt for generating vanilla stories Your task is to write a coherent and engaging story based on the provided writing prompt. Your story should contain approximately {num_words} words. First, read the writing prompt ca...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.