Incentivizing High-Quality Human Annotations with Golden Questions
Pith reviewed 2026-05-19 13:35 UTC · model grok-4.3
The pith
Strategic annotators in a principal-agent setup make quality hypothesis testing converge only at rate 1 over square root of n log n, which golden questions of high certainty and similar format can address.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By analyzing variance under strategic play, the paper establishes that the principal-agent hypothesis-testing rate is Θ(1/√(n log n)). This rate difference implies that effective monitoring requires golden questions that are both highly certain and similar in format to the main annotation tasks, allowing the bonus scheme to reveal and reward higher effort.
What carries the argument
Principal-agent model with maximum-likelihood estimator and hypothesis test that awards a bonus when the test is passed, applied to a curated set of golden questions.
If this is right
- Companies obtain a practical rule for choosing which items to use as quality checks rather than relying on generic survey questions.
- The bonus scheme becomes incentive-compatible once the golden questions satisfy the two stated criteria.
- Experiments demonstrate that annotator effort is more accurately revealed by these questions than by instructed manipulation checks.
- The overall data quality for supervised fine-tuning and preference alignment improves when the slower strategic rate is accounted for in test design.
Where Pith is reading between the lines
- The same design logic could be tested on other crowdsourced labeling tasks where direct verification is costly.
- Optimal monitoring budgets might be derived by balancing the cost of extra samples against the gain from tighter incentive alignment.
- If the rate result generalizes, platforms could adjust n dynamically based on observed variance in annotator responses.
Load-bearing premise
The annotator knows the principal will examine only a fixed number n of samples and will choose effort to maximize the chance of passing the test.
What would settle it
Measure the empirical rate at which low-effort annotators are detected or high-quality output rises as the number of monitored samples n grows; the observed scaling should track 1/√(n log n) rather than exponential decay.
Figures



read the original abstract
Human-annotated data plays a vital role in training large language models (LLMs), such as supervised fine-tuning and human preference alignment. However, it is not guaranteed that paid human annotators produce high-quality data. In this paper, we study how to incentivize human annotators to do so. We start from a principal-agent model to model the dynamics between the company (the principal) and the annotator (the agent), where the principal can only monitor the annotation quality by examining $n$ samples. We investigate the maximum likelihood estimators (MLE) and the corresponding hypothesis testing to incentivize annotators: the agent is given a bonus if the MLE passes the test. By analyzing the variance of the outcome, we show that the strategic behavior of the agent makes the hypothesis testing very different from traditional ones: Unlike the exponential rate proved by the large deviation theory, the principal-agent model's hypothesis testing rate is of $\Theta(1/\sqrt{n \log n})$. Our theory implies two criteria for the \emph{golden questions} to monitor the performance of the annotators: they should be of (1) high certainty and (2) similar format to normal ones. In that light, we select a set of golden questions in human preference data. By doing incentive-compatible experiments, we find out that the annotators' behavior is better revealed by those golden questions, compared to traditional survey techniques such as instructed manipulation checks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a principal-agent model for incentivizing high-quality human annotations for LLM training. The principal monitors only n samples using maximum likelihood estimation (MLE) and hypothesis testing to award bonuses. By analyzing the variance of the outcome under the agent's strategic best response, the paper claims that the hypothesis testing rate is Θ(1/√(n log n)), in contrast to the exponential rate from large deviation theory. This leads to two criteria for 'golden questions': high certainty and similar format to normal questions. The paper selects such questions from human preference data and conducts incentive-compatible experiments showing that golden questions better reveal annotator behavior than traditional survey techniques.
Significance. If the rate result is rigorously established, this work makes a notable contribution to the intersection of mechanism design and data quality in AI. It provides a theoretical explanation for why standard hypothesis testing fails under strategic agents and offers practical guidelines for selecting monitoring questions. The experimental component adds empirical support, though the strength depends on the clarity of the theoretical derivation. This could influence how companies design annotation incentives and monitoring in practice.
major comments (2)
- [§3 (Variance Analysis and Rate Derivation)] §3 (Variance Analysis and Rate Derivation): The central claim that strategic behavior leads to a hypothesis testing rate of Θ(1/√(n log n)) relies on the agent's equilibrium choice producing a specific variance scaling for the MLE statistic. However, the explicit mapping from the best-response action (optimizing expected bonus minus effort cost) to this variance under the n-sample monitoring constraint is not fully verified in the provided derivation. If the agent can achieve lower effective variance or correlate errors across samples, the detectable separation might allow a faster rate, weakening the contrast with large-deviation theory. A step-by-step calculation showing how the n log n term arises would be necessary to confirm the result.
- [§4 (Golden Question Criteria)] §4 (Golden Question Criteria): The implication that the rate result directly yields the two criteria (high certainty and similar format) for golden questions is stated but the logical steps connecting the variance analysis to these specific properties are not detailed. Clarifying how high certainty reduces variance or how format similarity affects the agent's ability to strategize would make this connection load-bearing and transparent.
minor comments (2)
- [Abstract] Abstract: The abstract mentions 'variance analysis yields the rate result' but does not specify the key assumptions on the cost function or annotation support; adding a brief note would improve clarity.
- [Experiments] Experiments section: Figure or table presenting the experimental outcomes (e.g., detection rates or p-values) could be made more prominent to allow readers to assess the practical significance of the golden questions.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address the two major comments below with clarifications on the theoretical derivations. We plan to incorporate additional details in a revision to make the arguments more transparent while preserving the core results.
read point-by-point responses
-
Referee: §3 (Variance Analysis and Rate Derivation): The central claim that strategic behavior leads to a hypothesis testing rate of Θ(1/√(n log n)) relies on the agent's equilibrium choice producing a specific variance scaling for the MLE statistic. However, the explicit mapping from the best-response action (optimizing expected bonus minus effort cost) to this variance under the n-sample monitoring constraint is not fully verified in the provided derivation. If the agent can achieve lower effective variance or correlate errors across samples, the detectable separation might allow a faster rate, weakening the contrast with large-deviation theory. A step-by-step calculation showing how the n log n term arises would be necessary to confirm the result.
Authors: We appreciate this observation and agree that the derivation benefits from greater explicitness. In the model, the agent solves max_e [P(MLE passes test | effort e) * bonus - cost(e)], where the test threshold is calibrated for type-I error control on n samples. The equilibrium effort e*(n) induces a mean shift in the annotation distribution whose magnitude, when plugged into the MLE variance, yields a separation that decays as 1/√(n log n) because the log n factor emerges from the agent's marginal cost-benefit tradeoff at the chosen threshold. Annotations are conditionally independent given effort, so cross-sample correlation is outside the model; any such correlation would require a different information structure not assumed here. In the revision we will insert a lemma with the full chain: agent's first-order condition → equilibrium variance expression → resulting type-II error scaling. revision: partial
-
Referee: §4 (Golden Question Criteria): The implication that the rate result directly yields the two criteria (high certainty and similar format) for golden questions is stated but the logical steps connecting the variance analysis to these specific properties are not detailed. Clarifying how high certainty reduces variance or how format similarity affects the agent's ability to strategize would make this connection load-bearing and transparent.
Authors: We agree the link should be spelled out. The Θ(1/√(n log n)) rate is driven by the equilibrium variance of the monitored statistic. High-certainty questions lower the baseline variance of the true label, which directly shrinks the equilibrium variance term and thereby improves the detectable separation for any fixed n. Format similarity prevents the agent from partitioning the sample into “normal” and “monitored” subsets and applying differential effort, preserving the single-effort equilibrium assumed in the variance calculation. We will add a short paragraph in Section 4 that traces these two properties back to the variance expression derived in Section 3. revision: yes
Circularity Check
No significant circularity; derivation is self-contained against external large-deviation bounds.
full rationale
The paper models the principal-agent interaction explicitly, derives the agent's best-response variance under the n-sample monitoring constraint, and obtains the Θ(1/√(n log n)) rate directly from that variance analysis. This is contrasted with the exponential rate from classical large-deviation theory, which is an independent external benchmark. No load-bearing step reduces to a fitted parameter renamed as a prediction, a self-citation chain, or a self-definitional mapping; the central claim retains independent mathematical content from the model assumptions and the variance calculation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Annotators act as rational agents who adjust their effort to maximize expected utility given the principal's limited monitoring of n samples and the bonus rule.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
By analyzing the variance of the outcome, we show that the strategic behavior of the agent makes the hypothesis testing very different from traditional ones: Unlike the exponential rate proved by the large deviation theory, the principal-agent model's hypothesis testing rate is of Θ(1/√(n log n)).
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We use the classic principal-agent model ... MLE-based hypothesis testing ... Var(Ψ) = O(1/√n log n)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
A marketplace for data: An algorithmic solution
Anish Agarwal, Munther Dahleh, and Tuhin Sarkar. A marketplace for data: An algorithmic solution. In Proceedings of the 2019 ACM Conference on Economics and Computation , pages 701–726,
work page 2019
-
[2]
Bayesian analysis of linear contracts
Tal Alon, Paul Dütting, Yingkai Li, and Inbal Talgam-Cohen. Bayesian analysis of linear contracts. arXiv preprint arXiv:2211.06850 ,
-
[3]
A General Language Assistant as a Laboratory for Alignment
Amanda Askell, Yuntao Bai, Anna Chen, Dawn Drain, Deep Ganguli, Tom Henighan, Andy Jones, Nicholas Joseph, Ben Mann, Nova DasSarma, et al. A general language assistant as a laboratory for alignment. arXiv preprint arXiv:2112.00861 ,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862 ,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Mohaddeseh Bastan, Mahnaz Koupaee, Youngseo Son, Richard Sicoli, and Niranjan Balasubramanian. Author’s sentiment prediction. arXiv preprint arXiv:2011.06128 ,
-
[6]
Principal-agent hypothesis testing
Stephen Bates, Michael I Jordan, Michael Sklar, and Jake A Soloff. Principal-agent hypothesis testing. arXiv preprint arXiv:2205.06812 ,
-
[7]
Creating speech and language data with amazons mechanical turk
Chris Callison-Burch and Mark Dredze. Creating speech and language data with amazons mechanical turk. In Proceedings of the NAACL HLT 2010 workshop on creating speech and language data with Amazons Mechanical Turk, pages 1–12,
work page 2010
-
[8]
Provably robust dpo: Aligning language models with noisy feedback
Sayak Ray Chowdhury, Anush Kini, and Nagarajan Natarajan. Provably robust dpo: Aligning language models with noisy feedback. arXiv preprint arXiv:2403.00409 ,
-
[9]
Association for Computing Machinery. ISBN 9798400707049. doi: 10.1145/3670865.3673607. URL https://doi.org/10.1145/3670865. 3673607. 12 Charles J Corbett and Christopher S Tang. Designing supply contracts: Contract type and information asymmetry. Quantitative models for supply chain management , pages 269–297,
-
[10]
UltraFeedback: Boosting Language Models with Scaled AI Feedback
Ganqu Cui, Lifan Yuan, Ning Ding, Guanming Yao, Wei Zhu, Yuan Ni, Guotong Xie, Zhiyuan Liu, and Maosong Sun. Ultrafeedback: Boosting language models with high-quality feedback. arXiv preprint arXiv:2310.01377,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Mechanism design for large language models
Paul Duetting, Vahab Mirrokni, Renato Paes Leme, Haifeng Xu, and Song Zuo. Mechanism design for large language models. In Proceedings of the ACM on Web Conference 2024 , pages 144–155,
work page 2024
-
[12]
Simple versus optimal contracts
Paul Dütting, Tim Roughgarden, and Inbal Talgam-Cohen. Simple versus optimal contracts. In Pro- ceedings of the 2019 ACM Conference on Economics and Computation , pages 369–387,
work page 2019
-
[13]
Mira Frick, Ryota Iijima, and Yuhta Ishii. Monitoring with rich data. arXiv preprint arXiv:2312.16789 ,
-
[14]
Impact of preference noise on the alignment performance of generative language models
Yang Gao, Dana Alon, and Donald Metzler. Impact of preference noise on the alignment performance of generative language models. arXiv preprint arXiv:2404.09824 ,
-
[15]
George Georgiadis and Balazs Szentes. Optimal monitoring design. Econometrica, 88(5):2075–2107,
work page 2075
-
[16]
Cicero: A dataset for contextualized commonsense inference in dialogues
Deepanway Ghosal, Siqi Shen, Navonil Majumder, Rada Mihalcea, and Soujanya Poria. Cicero: A dataset for contextualized commonsense inference in dialogues. arXiv preprint arXiv:2203.13926 ,
-
[17]
Interactive proofs for verifying machine learning
Shafi Goldwasser, Guy N Rothblum, Jonathan Shafer, and Amir Yehudayoff. Interactive proofs for verifying machine learning. In 12th Innovations in Theoretical Computer Science Conference (ITCS 2021). Schloss-Dagstuhl-Leibniz Zentrum für Informatik,
work page 2021
-
[18]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al- Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783 ,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Online learning from strategic human feedback in llm fine-tuning
Shugang Hao and Lingjie Duan. Online learning from strategic human feedback in llm fine-tuning. arXiv preprint arXiv:2412.16834 ,
-
[20]
Algorithmic persuasion through simulation.arXiv preprint arXiv:2311.18138, 2023
Keegan Harris, Nicole Immorlica, Brendan Lucier, and Aleksandrs Slivkins. Algorithmic persuasion through simulation: Information design in the age of generative ai. arXiv preprint arXiv:2311.18138 ,
-
[21]
Enhancing reliability using peer consistency evaluation in human computation
Shih-Wen Huang and Wai-Tat Fu. Enhancing reliability using peer consistency evaluation in human computation. In Proceedings of the 2013 conference on Computer supported cooperative work , pages 639–648,
work page 2013
-
[22]
Principal-agent reinforcement learning: Orchestrating ai agents with contracts
Dima Ivanov, Paul Dütting, Inbal Talgam-Cohen, Tonghan Wang, and David C Parkes. Principal-agent reinforcement learning: Orchestrating ai agents with contracts. arXiv preprint arXiv:2407.18074,
-
[23]
Pku-saferlhf: Towards multi-level safety alignment for llms with human preference
Jiaming Ji, Donghai Hong, Borong Zhang, Boyuan Chen, Josef Dai, Boren Zheng, Tianyi Qiu, Boxun Li, and Yaodong Yang. Pku-saferlhf: Towards multi-level safety alignment for llms with human preference. arXiv preprint arXiv:2406.15513 , 2024a. Jiaming Ji, Mickel Liu, Josef Dai, Xuehai Pan, Chi Zhang, Ce Bian, Boyuan Chen, Ruiyang Sun, Yizhou Wang, and Yaodon...
-
[24]
A survey of reinforcement learning from human feedback
Timo Kaufmann, Paul Weng, Viktor Bengs, and Eyke Hüllermeier. A survey of reinforcement learning from human feedback. arXiv preprint arXiv:2312.14925 ,
-
[25]
Analyzing dataset annotation quality management in the wild
Jan-Christoph Klie, Richard Eckart de Castilho, and Iryna Gurevych. Analyzing dataset annotation quality management in the wild. Computational Linguistics , 50(3):817–866, 2024a. Jan-Christoph Klie, Juan Haladjian, Marc Kirchner, and Rahul Nair. On efficient and statistical quality estimation for data annotation. arXiv preprint arXiv:2405.11919 , 2024b. Kla...
-
[26]
John Le, Andy Edmonds, Vaughn Hester, and Lukas Biewald
URL http://www.nber.org/papers/w13480. John Le, Andy Edmonds, Vaughn Hester, and Lukas Biewald. Ensuring quality in crowdsourced search relevance evaluation: The effects of training question distribution. In SIGIR 2010 workshop on crowd- sourcing for search evaluation , volume 2126, pages 22–32,
work page 2010
-
[27]
Chu Li, Zhihan Zhang, Michael Saugstad, Esteban Safranchik, Chaitanyashareef Kulkarni, Xiaoyu Huang, Shwetak Patel, Vikram Iyer, Tim Althoff, and Jon E Froehlich. Labelaid: Just-in-time ai interventions for improving human labeling quality and domain knowledge in crowdsourcing systems. In Proceedings of the 2024 CHI Conference on Human Factors in Computing...
work page 2024
-
[28]
Robust preference optimization with provable noise tolerance for llms
Xize Liang, Chao Chen, Jie Wang, Yue Wu, Zhihang Fu, Zhihao Shi, Feng Wu, and Jieping Ye. Robust preference optimization with provable noise tolerance for llms. arXiv preprint arXiv:2404.04102 ,
-
[29]
Skywork-Reward: Bag of Tricks for Reward Modeling in LLMs
Chris Yuhao Liu, Liang Zeng, Jiacai Liu, Rui Yan, Jujie He, Chaojie Wang, Shuicheng Yan, Yang Liu, and Yahui Zhou. Skywork-reward: Bag of tricks for reward modeling in llms. arXiv preprint arXiv:2410.18451,
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
How Humans Help LLMs: Assessing and Incentivizing Human Preference Annotators
Shang Liu, Hanzhao Wang, Zhongyao Ma, and Xiaocheng Li. How humans help llms: Assessing and incentivizing human preference annotators. arXiv preprint arXiv:2502.06387 ,
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Nash learning from human feedback
Rémi Munos, Michal Valko, Daniele Calandriello, Mohammad Gheshlaghi Azar, Mark Rowland, Zhao- han Daniel Guo, Yunhao Tang, Matthieu Geist, Thomas Mesnard, Andrea Michi, et al. Nash learning from human feedback. arXiv preprint arXiv:2312.00886 ,
-
[32]
Annotation inconsistency and entity bias in multiwoz
Kun Qian, Ahmad Beirami, Zhouhan Lin, Ankita De, Alborz Geramifard, Zhou Yu, and Chinnadhurai Sankar. Annotation inconsistency and entity bias in multiwoz. arXiv preprint arXiv:2105.14150 ,
-
[33]
Mechanism design for llm fine- tuning with multiple reward models
Haoran Sun, Yurong Chen, Siwei Wang, Wei Chen, and Xiaotie Deng. Mechanism design for llm fine- tuning with multiple reward models. arXiv preprint arXiv:2405.16276 ,
-
[34]
Llama 2: Open Foundation and Fine-Tuned Chat Models
16 Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 ,
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Secrets of rlhf in large language models part ii: Reward modeling
Binghai Wang, Rui Zheng, Lu Chen, Yan Liu, Shihan Dou, Caishuang Huang, Wei Shen, Senjie Jin, Enyu Zhou, Chenyu Shi, et al. Secrets of rlhf in large language models part ii: Reward modeling. arXiv preprint arXiv:2401.06080 ,
-
[36]
Helpsteer: Multi-attribute helpfulness dataset for steerlm
Zhilin Wang, Yi Dong, Jiaqi Zeng, Virginia Adams, Makesh Narsimhan Sreedhar, Daniel Egert, Olivier Delalleau, Jane Polak Scowcroft, Neel Kant, Aidan Swope, et al. Helpsteer: Multi-attribute helpfulness dataset for steerlm. arXiv preprint arXiv:2311.09528 ,
-
[37]
arXiv preprint arXiv:2305.10425 , year=
Yao Zhao, Rishabh Joshi, Tianqi Liu, Misha Khalman, Mohammad Saleh, and Peter J Liu. Slic-hf: Sequence likelihood calibration with human feedback. arXiv preprint arXiv:2305.10425 ,
-
[38]
Fine-Tuning Language Models from Human Preferences
Daniel M Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B Brown, Alec Radford, Dario Amodei, Paul Chris- tiano, and Geoffrey Irving. Fine-tuning language models from human preferences. arXiv preprint arXiv:1909.08593,
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[39]
RLHF has become a primary method for aligning large language models (LLMs) with human preferences
17 A Related Literature A.1 Annotation monitoring and management Effective monitoring mechanisms help ensure annotators produce high-quality data, especially crucial for reinforcement learning from human feedback (RLHF) and direct preference optimization (DPO). RLHF has become a primary method for aligning large language models (LLMs) with human preference...
work page 2021
-
[40]
However, preference data annotation faces two unique challenges
for more details. However, preference data annotation faces two unique challenges. First, annotator heterogeneity makes traditional quality assessment difficult due to a lack of ground-truth labels. Second, the unclear link between annotation quality and downstream model performance complicates evaluation. These issues limit the effectiveness of traditional ...
work page 2019
-
[41]
compares golden questions and peer-consistency checks, [ Harris, 2011] finds positive incentives based on these questions improve worker accuracy. However, the golden question mechanism can be vulnerable to collusion among annotators [Checco et al. , 2018]. [ Shah and Zhou , 2016] suggests payment systems encouraging workers to only answer confident questio...
work page 2011
-
[42]
provide a thorough overview. Our work extends the literature by proposing an efficient method to select highly certain preference questions as golden questions, enhancing incentive alignment for annotators in large language model contexts. B Proofs and Discussions B.1 Discussions on θa(Fn) = θ∗ To help the discussions, we define a more restricted definition o...
work page 2023
-
[43]
= Θ ϕ √n · (θa − τ ) · 1√n · (θa − τ ) = Θ 1√n log n . For general distributions, the target is to show that, as ˜Z(θa) converges to the standard normal distribution, the above arguments still hold. The most important property is the convergence rate of 23 ˜Z(θa) to N (0, 1), where we adopt the Berry-Esseen type bounds to achieve so. To achieve that, we d...
work page 1965
-
[44]
The lower bound is a direct corollary of the lower bound part of Theorem 4.6 of Liu et al
Proof of the lower bound part. The lower bound is a direct corollary of the lower bound part of Theorem 4.6 of Liu et al. [2025], noticing that the sample average of a binomial distribution is the MLE. In that sense, the lower bound in Liu et al
work page 2025
-
[45]
Then the payment level is wa = 1 n Pd j=1 fn(dj). We denote all those contracts by F lin n , and the corresponding second-best values within F lin n by Clin n . Algorithm 3 Linear contract Input: A dataset Dn = {d1, ..., dn} used to assess the annotator performance and a linear contract Fn specified by fn The company pays the annotator wa = 1 n nX i=1 fn(d...
work page 2025
-
[46]
This is an attention check question. Please select Response 1 to receive the bonus
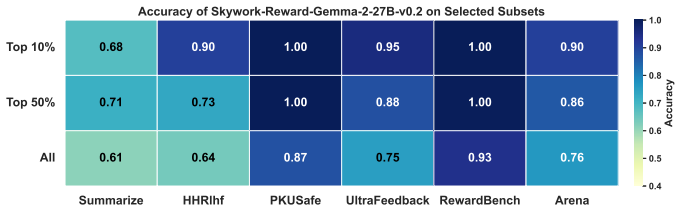
Despite variations in average accuracy across different models, their performance consistently aligns closely with human annotations on high-certainty samples. C.2 Setup and more results for Figure 2 Experiment setup We conduct our experiments using the PKU-SafeRLHF dataset [ Ji et al. , 2024a]. 27 /uni00000036/uni00000058/uni00000050/uni00000050/uni000000...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.