Preserve and Personalize: Personalized Text-to-Image Diffusion Models without Distributional Drift
Pith reviewed 2026-05-19 13:59 UTC · model grok-4.3
The pith
A Lipschitz constraint on parameter updates during personalization keeps text-to-image diffusion models from drifting away from their original output distribution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a Lipschitz-based regularization objective, applied during the personalization fine-tuning stage, constrains parameter updates so that the model's output distribution stays close to the pretrained distribution. This simultaneously achieves high fidelity to the reference images and strong adherence to novel text prompts, outperforming prior methods that rely only on reconstruction or prompt-alignment losses.
What carries the argument
Lipschitz-based regularization objective that penalizes large changes in the model's parameters during fine-tuning on reference images.
If this is right
- Personalized models retain the ability to generate varied images for the same prompt instead of copying the reference set.
- Text alignment improves because the model cannot collapse to simply reproducing the training images.
- The approach replaces expensive sampling-based distribution checks with a direct parameter-space penalty that is cheaper to compute.
- The same regularization can be added to different diffusion architectures without changing their training pipelines.
Where Pith is reading between the lines
- The same bounded-update idea might transfer to other generative tasks such as personalized video or 3-D synthesis where distribution drift is also a problem.
- If the Lipschitz bound can be made adaptive per layer, it could further reduce the trade-off between concept learning and preservation.
- The method suggests a general principle for fine-tuning large models: keep the change in function space small even when the parameter change appears large.
Load-bearing premise
Limiting the size of parameter updates through a Lipschitz bound is enough to stop the output distribution from drifting while still allowing the model to learn a new visual concept from a few images.
What would settle it
A test set of prompts and reference images where the regularized model still produces outputs whose distribution (measured by Fréchet distance or similar) deviates as much from the original model as an unregularized personalization run.
Figures







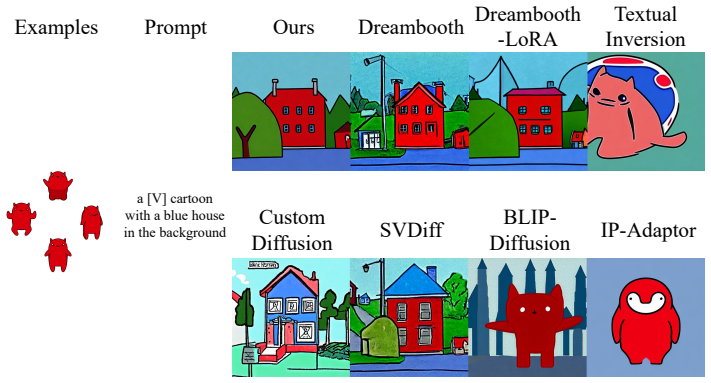




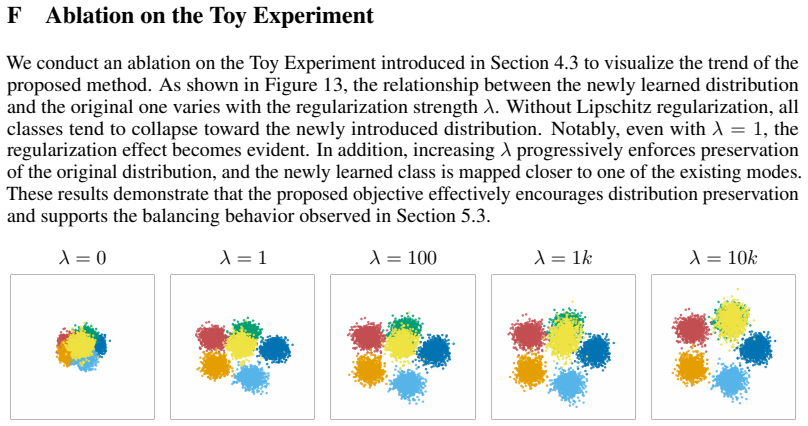

read the original abstract
Personalizing text-to-image diffusion models involves integrating novel visual concepts from a small set of reference images while retaining the model's original generative capabilities. However, this process often leads to overfitting, where the model ignores the user's prompt and merely replicates the reference images. We attribute this issue to a fundamental misalignment between the true goals of personalization, which are subject fidelity and text alignment, and the training objectives of existing methods that fail to enforce both objectives simultaneously. Specifically, prior approaches often overlook the need to explicitly preserve the pretrained model's output distribution, resulting in distributional drift that undermines diversity and coherence. To resolve these challenges, we introduce a Lipschitz-based regularization objective that constrains parameter updates during personalization, ensuring bounded deviation from the original distribution. This promotes consistency with the pretrained model's behavior while enabling accurate adaptation to new concepts. Furthermore, our method offers a computationally efficient alternative to commonly used, resource-intensive sampling techniques. Through extensive experiments across diverse diffusion model architectures, we demonstrate that our approach achieves superior performance in both quantitative metrics and qualitative evaluations, consistently excelling in visual fidelity and prompt adherence. We further support these findings with comprehensive analyses, including ablation studies and visualizations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a Lipschitz-based regularization objective constrains parameter updates during fine-tuning of text-to-image diffusion models for personalization, ensuring bounded deviation from the pretrained output distribution. This prevents overfitting and distributional drift while enabling adaptation to novel concepts from few reference images, yielding superior visual fidelity and prompt adherence across architectures, as shown via quantitative metrics, qualitative results, ablations, and visualizations. It positions the method as a computationally efficient alternative to sampling-based techniques.
Significance. If the regularization truly produces bounded distributional drift without relying on post-hoc tuning or unstated assumptions, the work would offer a practical and theoretically motivated solution to a core limitation in personalized diffusion models. It could reduce reliance on expensive inference-time methods and improve reliability of subject-driven generation in applications.
major comments (2)
- [Abstract and §3] Abstract and §3 (regularization objective): the claim that the Lipschitz constraint 'ensures bounded deviation from the original distribution' lacks any derivation connecting the parameter-level regularization to a bound on the push-forward measure after the full multi-step denoising process. Diffusion sampling composes dozens of network calls; a local Lipschitz bound on weights does not automatically yield a uniform bound on KL, Wasserstein, or total-variation distance to the pretrained distribution unless Lipschitz continuity of the score network along the trajectory or control on the noise schedule is established.
- [§4] §4 (experiments and ablations): no empirical measurement of distributional drift (e.g., on held-out prompts or via FID/KL proxies between pretrained and personalized models) is reported. The superiority claims rest on visual fidelity and prompt adherence metrics, but without direct quantification of the claimed preservation mechanism the central causal link remains unverified.
minor comments (2)
- [§3] Notation for the regularization strength lambda should be introduced with an explicit sensitivity study or selection protocol to avoid the appearance that performance gains depend on implicit fitting.
- [Tables 1-3] Table captions and axis labels in quantitative results would benefit from clearer units and baseline descriptions for immediate readability.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which helps clarify important aspects of our theoretical claims and empirical validation. We respond to each major comment below and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (regularization objective): the claim that the Lipschitz constraint 'ensures bounded deviation from the original distribution' lacks any derivation connecting the parameter-level regularization to a bound on the push-forward measure after the full multi-step denoising process. Diffusion sampling composes dozens of network calls; a local Lipschitz bound on weights does not automatically yield a uniform bound on KL, Wasserstein, or total-variation distance to the pretrained distribution unless Lipschitz continuity of the score network along the trajectory or control on the noise schedule is established.
Authors: We appreciate the referee's observation regarding the theoretical gap. Our §3 derives a bound on the change in the network's output for a single forward pass under the Lipschitz regularization on parameters. However, extending this to a bound on the distributional distance after the complete multi-step sampling process indeed requires additional analysis, such as propagating the Lipschitz constant through the denoising trajectory and considering the specific noise schedule. We did not provide a complete end-to-end derivation in the original manuscript. To address this, we will revise §3 to include a more explicit discussion of the assumptions and a sketch of how the per-step bound implies controlled deviation in the generated distribution, or clarify the scope of our theoretical claims. revision: yes
-
Referee: [§4] §4 (experiments and ablations): no empirical measurement of distributional drift (e.g., on held-out prompts or via FID/KL proxies between pretrained and personalized models) is reported. The superiority claims rest on visual fidelity and prompt adherence metrics, but without direct quantification of the claimed preservation mechanism the central causal link remains unverified.
Authors: The referee correctly identifies that we have not directly quantified distributional drift in our experiments. Our evaluations emphasize the practical outcomes of subject fidelity and prompt adherence, which indirectly reflect preservation of the original capabilities. To provide direct evidence for the preservation mechanism, we will add new experiments in the revised §4, including measurements such as FID between samples from the pretrained and fine-tuned models on a set of held-out prompts, as well as other proxies for distributional similarity. This will help substantiate the causal role of the Lipschitz regularization in mitigating drift. revision: yes
Circularity Check
No significant circularity detected; derivation introduces independent regularization
full rationale
The paper introduces a Lipschitz-based regularization objective on parameter updates as a novel mechanism to bound deviation from the pretrained distribution during personalization. No equations or sections in the provided abstract and description reduce this claim to a self-definition, a fitted hyperparameter renamed as a prediction, or a load-bearing self-citation chain. The central premise rests on the proposed constraint itself rather than re-deriving an input quantity, and the method is positioned as an efficient alternative to sampling techniques with independent empirical validation across architectures. This qualifies as a self-contained contribution without the specific reductions required for a positive circularity finding.
Axiom & Free-Parameter Ledger
free parameters (1)
- regularization strength lambda
axioms (1)
- domain assumption Lipschitz continuity of the parameter update map implies bounded deviation in the generated output distribution
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
If the diffusion model ε_θ is Lipschitz continuous in θ, then … D_KL(p_θ1 ∥ p_θ2) ≤ λ · ||θ1 − θ2||_k (Theorem 2)
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Lipschitz regularization on ∥θ_per − θ_base∥_k provides a bound on the distributional shift
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Prafulla Dhariwal and Alexander Quinn Nichol. Diffusion models beat gans on image synthesis.Advances in Neural Information Processing Systems, 34:8780–8794, 2021
work page 2021
-
[2]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
work page 2020
-
[3]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[4]
Improved denoising diffusion probabilistic models
Alexander Quinn Nichol and Prafulla Dhariwal. Improved denoising diffusion probabilistic models. In International conference on machine learning, pages 8162–8171. PMLR, 2021
work page 2021
-
[5]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[6]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[7]
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models.Advances in neural information processing systems, 35:26565–26577, 2022
work page 2022
-
[8]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
work page 2022
-
[9]
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to- image diffusion models with deep language understanding.Advances in neural information processing systems, 35:36479–36494, 2022
work page 2022
-
[10]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents.arXiv preprint arXiv:2204.06125, 1(2):3, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[11]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis.arXiv preprint arXiv:2307.01952, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Dream- booth: Fine tuning text-to-image diffusion models for subject-driven generation
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dream- booth: Fine tuning text-to-image diffusion models for subject-driven generation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22500–22510, 2023
work page 2023
-
[13]
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit H Bermano, Gal Chechik, and Daniel Cohen-Or. An image is worth one word: Personalizing text-to-image generation using textual inversion. arXiv preprint arXiv:2208.01618, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[14]
Prompting hard or hardly prompting: Prompt inversion for text-to-image diffusion models
Shweta Mahajan, Tanzila Rahman, Kwang Moo Yi, and Leonid Sigal. Prompting hard or hardly prompting: Prompt inversion for text-to-image diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6808–6817, 2024
work page 2024
-
[15]
Generating images of rare con- cepts using pre-trained diffusion models
Dvir Samuel, Rami Ben-Ari, Simon Raviv, Nir Darshan, and Gal Chechik. Generating images of rare con- cepts using pre-trained diffusion models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 4695–4703, 2024
work page 2024
-
[16]
Dvir Samuel, Rami Ben-Ari, Nir Darshan, Haggai Maron, and Gal Chechik. Norm-guided latent space exploration for text-to-image generation.Advances in Neural Information Processing Systems, 36:57863– 57875, 2023
work page 2023
-
[17]
Safe latent diffusion: Mitigating inappropriate degeneration in diffusion models
Patrick Schramowski, Manuel Brack, Björn Deiseroth, and Kristian Kersting. Safe latent diffusion: Mitigating inappropriate degeneration in diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22522–22531, 2023
work page 2023
-
[18]
Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
work page 2022
-
[19]
Multi-concept customization of text-to-image diffusion
Nupur Kumari, Bingliang Zhang, Richard Zhang, Eli Shechtman, and Jun-Yan Zhu. Multi-concept customization of text-to-image diffusion. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1931–1941, 2023. 10
work page 1931
-
[20]
Key-locked rank one editing for text-to-image personalization
Yoad Tewel, Rinon Gal, Gal Chechik, and Yuval Atzmon. Key-locked rank one editing for text-to-image personalization. InACM SIGGRAPH 2023 conference proceedings, pages 1–11, 2023
work page 2023
-
[21]
Zeju Qiu, Weiyang Liu, Haiwen Feng, Yuxuan Xue, Yao Feng, Zhen Liu, Dan Zhang, Adrian Weller, and Bernhard Schölkopf. Controlling text-to-image diffusion by orthogonal finetuning.Advances in Neural Information Processing Systems, 36:79320–79362, 2023
work page 2023
-
[22]
Svdiff: Compact parameter space for diffusion fine-tuning
Ligong Han, Yinxiao Li, Han Zhang, Peyman Milanfar, Dimitris Metaxas, and Feng Yang. Svdiff: Compact parameter space for diffusion fine-tuning. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 7323–7334, 2023
work page 2023
-
[23]
arXiv preprint arXiv:2303.09522 (2023)
Andrey V oynov, Qinghao Chu, Daniel Cohen-Or, and Kfir Aberman. p+: Extended textual conditioning in text-to-image generation.arXiv preprint arXiv:2303.09522, 2023
-
[24]
Dreamblend: Advancing personalized fine-tuning of text-to-image diffusion models
Shwetha Ram, Tal Neiman, Qianli Feng, Andrew Stuart, Son Tran, and Trishul Chilimbi. Dreamblend: Advancing personalized fine-tuning of text-to-image diffusion models. 2025
work page 2025
-
[25]
Shangyu Chen, Zizheng Pan, Jianfei Cai, and Dinh Phung. Para: Personalizing text-to-image diffusion via parameter rank reduction.arXiv preprint arXiv:2406.05641, 2024
-
[26]
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associations in gpt.Advances in neural information processing systems, 35:17359–17372, 2022
work page 2022
-
[27]
Dongxu Li, Junnan Li, and Steven Hoi. Blip-diffusion: Pre-trained subject representation for controllable text-to-image generation and editing.Advances in Neural Information Processing Systems, 36:30146– 30166, 2023
work page 2023
-
[28]
Elite: Encoding visual concepts into textual embeddings for customized text-to-image generation
Yuxiang Wei, Yabo Zhang, Zhilong Ji, Jinfeng Bai, Lei Zhang, and Wangmeng Zuo. Elite: Encoding visual concepts into textual embeddings for customized text-to-image generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15943–15953, 2023
work page 2023
-
[29]
Wenhu Chen, Hexiang Hu, Yandong Li, Nataniel Ruiz, Xuhui Jia, Ming-Wei Chang, and William W Cohen. Subject-driven text-to-image generation via apprenticeship learning.Advances in Neural Information Processing Systems, 36:30286–30305, 2023
work page 2023
-
[30]
Kosmos-g: Generating images in context with multimodal large language models
Xichen Pan, Li Dong, Shaohan Huang, Zhiliang Peng, Wenhu Chen, and Furu Wei. Kosmos-g: Generating images in context with multimodal large language models. InThe Twelfth International Conference on Learning Representations
-
[31]
Subject-diffusion: Open domain personalized text-to-image generation without test-time fine-tuning
Jian Ma, Junhao Liang, Chen Chen, and Haonan Lu. Subject-diffusion: Open domain personalized text-to-image generation without test-time fine-tuning. InACM SIGGRAPH 2024 Conference Papers, pages 1–12, 2024
work page 2024
-
[32]
Emanuele Aiello, Umberto Michieli, Diego Valsesia, Mete Ozay, and Enrico Magli. Dream- cache: Finetuning-free lightweight personalized image generation via feature caching.arXiv preprint arXiv:2411.17786, 2024
-
[33]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. InProceedings of the IEEE/CVF international conference on computer vision, pages 3836–3847, 2023
work page 2023
-
[34]
Chong Mou, Xintao Wang, Liangbin Xie, Yanze Wu, Jian Zhang, Zhongang Qi, and Ying Shan. T2i- adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models. In Proceedings of the AAAI conference on artificial intelligence, volume 38, pages 4296–4304, 2024
work page 2024
-
[35]
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. InInternational conference on machine learning, pages 12888–12900. PMLR, 2022
work page 2022
-
[36]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning, pages 19730–19742. PMLR, 2023
work page 2023
-
[37]
DreamFusion: Text-to-3D using 2D Diffusion
Ben Poole, Ajay Jain, Jonathan T Barron, and Ben Mildenhall. Dreamfusion: Text-to-3d using 2d diffusion. arXiv preprint arXiv:2209.14988, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[38]
Amir Hertz, Kfir Aberman, and Daniel Cohen-Or. Delta denoising score. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2328–2337, 2023. 11
work page 2023
-
[39]
Zhengyi Wang, Cheng Lu, Yikai Wang, Fan Bao, Chongxuan Li, Hang Su, and Jun Zhu. Prolificdreamer: High-fidelity and diverse text-to-3d generation with variational score distillation.Advances in Neural Information Processing Systems, 36:8406–8441, 2023
work page 2023
-
[40]
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis.Communications of the ACM, 65(1):99–106, 2021
work page 2021
-
[41]
Zhengyang Yu, Zhaoyuan Yang, and Jing Zhang. Dreamsteerer: Enhancing source image conditioned editability using personalized diffusion models.Advances in Neural Information Processing Systems, 37:120699–120734, 2024
work page 2024
-
[42]
One-step diffusion with distribution matching distillation
Tianwei Yin, Michaël Gharbi, Richard Zhang, Eli Shechtman, Fredo Durand, William T Freeman, and Taesung Park. One-step diffusion with distribution matching distillation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6613–6623, 2024
work page 2024
-
[43]
Tianwei Yin, Michaël Gharbi, Taesung Park, Richard Zhang, Eli Shechtman, Fredo Durand, and Bill Freeman. Improved distribution matching distillation for fast image synthesis.Advances in neural information processing systems, 37:47455–47487, 2024
work page 2024
-
[44]
Adversarial diffusion distillation
Axel Sauer, Dominik Lorenz, Andreas Blattmann, and Robin Rombach. Adversarial diffusion distillation. InEuropean Conference on Computer Vision, pages 87–103. Springer, 2024
work page 2024
-
[45]
Deep unsupervised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. InInternational conference on machine learning, pages 2256–2265. pmlr, 2015
work page 2015
-
[46]
Stanley Chan et al. Tutorial on diffusion models for imaging and vision.Foundations and Trends® in Computer Graphics and Vision, 16(4):322–471, 2024
work page 2024
-
[47]
Understanding diffusion models: A unified perspective,
Calvin Luo. Understanding diffusion models: A unified perspective.arXiv preprint arXiv:2208.11970, 2022
-
[48]
Step-by-step diffusion: An elementary tutorial.arXiv preprint arXiv:2406.08929, 2024
Preetum Nakkiran, Arwen Bradley, Hattie Zhou, and Madhu Advani. Step-by-step diffusion: An elementary tutorial.arXiv preprint arXiv:2406.08929, 2024
-
[49]
LAION-400M: Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs
Christoph Schuhmann, Richard Vencu, Romain Beaumont, Robert Kaczmarczyk, Clayton Mullis, Aarush Katta, Theo Coombes, Jenia Jitsev, and Aran Komatsuzaki. Laion-400m: Open dataset of clip-filtered 400 million image-text pairs.arXiv preprint arXiv:2111.02114, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[50]
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, et al. Laion-5b: An open large-scale dataset for training next generation image-text models.Advances in neural information processing systems, 35:25278–25294, 2022
work page 2022
-
[51]
Deep learning.nature, 521(7553):436–444, 2015
Yann LeCun, Yoshua Bengio, and Geoffrey Hinton. Deep learning.nature, 521(7553):436–444, 2015
work page 2015
-
[52]
Norm-based capacity control in neural networks
Behnam Neyshabur, Ryota Tomioka, and Nathan Srebro. Norm-based capacity control in neural networks. InConference on learning theory, pages 1376–1401. PMLR, 2015
work page 2015
-
[53]
Lipschitz continuity in model-based reinforcement learning
Kavosh Asadi, Dipendra Misra, and Michael Littman. Lipschitz continuity in model-based reinforcement learning. InInternational Conference on Machine Learning, pages 264–273. PMLR, 2018
work page 2018
-
[54]
Bradley Efron. Tweedie’s formula and selection bias.Journal of the American Statistical Association, 106(496):1602–1614, 2011
work page 2011
-
[55]
Generative modeling by estimating gradients of the data distribution
Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data distribution. Advances in neural information processing systems, 32, 2019
work page 2019
-
[56]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 9650–9660, 2021
work page 2021
-
[57]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 12
work page 2021
-
[58]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009
work page 2009
-
[59]
Improved techniques for training gans.Advances in neural information processing systems, 29, 2016
Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved techniques for training gans.Advances in neural information processing systems, 29, 2016
work page 2016
-
[60]
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
work page 2017
-
[61]
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. Overcoming catastrophic forgetting in neural networks.Proceedings of the national academy of sciences, 114(13):3521–3526, 2017
work page 2017
-
[62]
Kavosh Asadi, Rasool Fakoor, Omer Gottesman, Taesup Kim, Michael Littman, and Alexander J Smola. Faster deep reinforcement learning with slower online network.Advances in Neural Information Processing Systems, 35:19944–19955, 2022
work page 2022
-
[63]
Frank Nielsen, Jean-Daniel Boissonnat, and Richard Nock. Bregman voronoi diagrams: Properties, algorithms and applications.arXiv preprint arXiv:0709.2196, 2007
-
[64]
TM Cover and JA Thomas. Elements of information theory 2nd ed., 2006. 13 Appendix A Proof of Theorem 1 Theorem 1.Let p∗(x, c) denote the reference distribution, and let the model parameters θbase have distributionp θbase(x, c)satisfying, for anyϵ >0, p∗(x, c)−p θbase(x, c) < ε. The model is adapted by gradient descent on the denoising loss LDenoise from E...
work page 2006
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.