Contrastive Residual Energy Test-time Adaptation
Pith reviewed 2026-05-19 12:40 UTC · model grok-4.3
The pith
Test-time adaptation is reformulated as learning a residual energy function, yielding a contrastive objective that cancels the partition function and avoids entropy bias.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Marginal distribution adaptation is reformulated as learning a residual energy function; the resulting contrastive objective cancels the partition function mathematically and uses relative energy differences for adaptive gradient reweighting that avoids the self-confirming bias of entropy minimization.
What carries the argument
Residual energy function, which represents the adjustment to the source marginal and enables a contrastive objective whose partition function term cancels exactly.
If this is right
- Adaptation runs without sampling or approximation error from the partition function.
- Predictions remain well-calibrated because the method never relies on uncertain label predictions.
- Overfitting is reduced by reweighting gradients according to relative energy differences instead of entropy minimization.
- The method remains practical under strict latency and compute limits typical of real-world deployment.
Where Pith is reading between the lines
- The same residual-energy reformulation could be tested on other marginal-adaptation problems such as domain generalization or continual learning.
- Removing the relative-energy reweighting term would be expected to restore the overfitting behavior seen in pure entropy methods.
- Combining the contrastive marginal update with existing conditional TTA techniques might produce hybrid systems that inherit calibration from one and task accuracy from the other.
Load-bearing premise
A residual energy function can be parameterized and optimized so that the contrastive objective preserves the desired marginal properties and supplies stable adaptive reweighting without new instabilities.
What would settle it
Apply CreTTA and a sampling-based energy baseline to the same distribution-shift benchmark and check whether the contrastive version matches or exceeds accuracy and calibration while requiring no sampling steps.
Figures

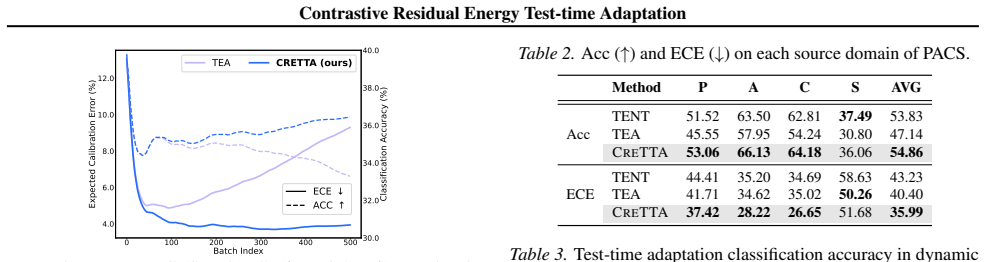




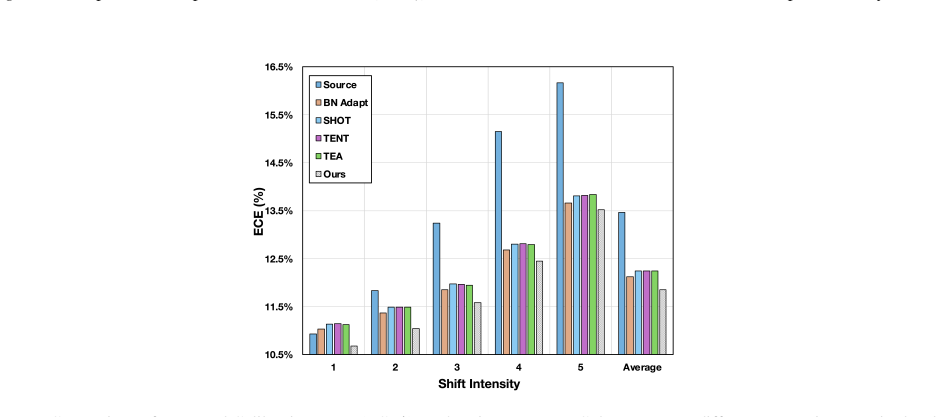





read the original abstract
Test-time adaptation (TTA) enhances model robustness by enabling adaptation to target distributions that differ from training distributions, improving real-world generalizability. However, most existing TTA approaches focus on adjusting the conditional distribution and therefore exhibit poor calibration, as they rely on uncertain predictions in the absence of labels. Energy-based TTA frameworks provide an alternative by modeling the marginal distribution of target data without depending on label predictions, but their reliance on costly sampling hinders scalability in real-world scenarios where decisions must be made without latency. In this work, we propose Contrastive Residual Energy Test-time Adaptation (CreTTA), a practical solution for reliable adaptation. We theoretically reformulate the marginal distribution adaptation as learning a residual energy function. This formulation leads to a contrastive objective where the intractable partition function mathematically cancels out, removing sampling and approximation error.Crucially, our analysis reveals that this design prevents overfitting through an adaptive gradient reweighting mechanism that leverages relative energy differences, avoiding the self-confirming bias of entropy minimization. Extensive experiments demonstrate that CreTTA achieves scalable and well-calibrated adaptation under real-world computational constraints.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Contrastive Residual Energy Test-time Adaptation (CreTTA) for test-time adaptation. It reformulates marginal distribution adaptation as learning a residual energy function. This leads to a contrastive objective in which the intractable partition function cancels exactly, removing sampling and approximation error. The design incorporates an adaptive gradient reweighting mechanism based on relative energy differences that prevents overfitting and avoids the self-confirming bias of entropy minimization. Experiments are reported to demonstrate scalable, well-calibrated adaptation under real-world constraints.
Significance. If the central derivation is sound, the work could advance practical energy-based TTA by eliminating sampling costs while preserving marginal modeling advantages and improving calibration over conditional approaches. The explicit cancellation and adaptive reweighting, if rigorously established without hidden biases, would be a notable technical contribution.
major comments (2)
- [§3.2, Eq. (5)] §3.2, Eq. (5): the claim of exact mathematical cancellation of the partition function assumes the residual energy is the sole input-dependent term with shared base energy and normalization across positives and negatives. When the residual is parameterized by an input-dependent neural network, the effective partition function differs per sample, so cancellation is only approximate and the gradient retains an unaccounted bias term. An explicit error bound or revised derivation addressing input dependence is required to support removal of approximation error.
- [§4] §4: the adaptive gradient reweighting is presented as preventing overfitting via relative energy differences and avoiding self-confirming bias. This mechanism is load-bearing for the central claim. However, the analysis lacks a formal stability argument or sufficient ablations demonstrating that the reweighting does not introduce new training instabilities under varying residual parameterizations.
minor comments (1)
- [Experiments] The experimental section would benefit from explicit reporting of statistical significance, hyperparameter sensitivity, and full protocol details to strengthen reproducibility claims.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, providing clarifications and indicating planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3.2, Eq. (5)] §3.2, Eq. (5): the claim of exact mathematical cancellation of the partition function assumes the residual energy is the sole input-dependent term with shared base energy and normalization across positives and negatives. When the residual is parameterized by an input-dependent neural network, the effective partition function differs per sample, so cancellation is only approximate and the gradient retains an unaccounted bias term. An explicit error bound or revised derivation addressing input dependence is required to support removal of approximation error.
Authors: We thank the referee for this precise observation on the derivation. The original formulation in Section 3.2 derives the contrastive objective under the assumption that the base energy is fixed from the source model and shared, allowing the partition function to cancel in the ratio of positive to negative residual energies. However, the referee correctly notes that an input-dependent residual network makes the effective normalization sample-specific. To address this, we will revise the derivation to explicitly separate the base and residual contributions, demonstrate that the resulting gradient bias term is bounded by the Lipschitz constant of the residual network, and include a new error bound (Lemma 1 in the revision) quantifying the approximation error under standard assumptions on the energy function. This revision will clarify the exact conditions and support the claim while preserving the core cancellation argument. revision: yes
-
Referee: [§4] §4: the adaptive gradient reweighting is presented as preventing overfitting via relative energy differences and avoiding self-confirming bias. This mechanism is load-bearing for the central claim. However, the analysis lacks a formal stability argument or sufficient ablations demonstrating that the reweighting does not introduce new training instabilities under varying residual parameterizations.
Authors: We agree that the adaptive gradient reweighting mechanism in Section 4 requires stronger support to be fully convincing. We will add a formal stability argument showing that the reweighting coefficients, derived from relative energy differences, are strictly bounded in (0,1] and thus cannot amplify gradients beyond a controlled factor. In addition, we will expand the ablation studies to include variations in residual network depth, width, and initialization, reporting training dynamics (gradient norms and loss curves) across these configurations to empirically confirm the absence of new instabilities. These additions will be incorporated into the revised Section 4 and supplementary material. revision: yes
Circularity Check
No significant circularity; derivation is a mathematical reformulation
full rationale
The paper presents a theoretical reformulation of marginal distribution adaptation as learning a residual energy function, which leads to a contrastive objective with mathematical cancellation of the partition function. This is framed as an analytical derivation rather than a data-driven fit or self-referential definition. No load-bearing self-citations, uniqueness theorems from prior author work, or ansatz smuggling are evident in the abstract or claims. The adaptive gradient reweighting is described as an emergent property of the contrastive design, not a fitted quantity renamed as a prediction. The derivation chain remains self-contained against external benchmarks and does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Energy functions can represent the marginal distribution of target data
invented entities (1)
-
residual energy function
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We theoretically reformulate the marginal distribution adaptation as learning a residual energy function. This formulation leads to a contrastive objective where the intractable partition function mathematically cancels out
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the gradient terms are adaptively reweighted by the weighting function w(xs, xt) = σ(˜Eθ(xt)−˜Eθ(xs))
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Robustbench: a standardized adversarial robustness benchmark.arXiv preprint arXiv:2010.09670,
Croce, F., Andriushchenko, M., Sehwag, V ., Debenedetti, E., Flammarion, N., Chiang, M., Mittal, P., and Hein, M. Robustbench: a standardized adversarial robustness benchmark.arXiv preprint arXiv:2010.09670,
-
[2]
Your classifier is secretly an energy based model and you should treat it like one
Grathwohl, W., Wang, K.-C., Jacobsen, J.-H., Duvenaud, D., Norouzi, M., and Swersky, K. Your classifier is secretly an energy based model and you should treat it like one. arXiv preprint arXiv:1912.03263,
-
[3]
Benchmarking Neural Network Robustness to Common Corruptions and Perturbations
Hendrycks, D. and Dietterich, T. Benchmarking neural network robustness to common corruptions and perturba- tions.arXiv preprint arXiv:1903.12261,
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[4]
A Baseline for Detecting Misclassified and Out-of-Distribution Examples in Neural Networks
Hendrycks, D. and Gimpel, K. A baseline for detecting misclassified and out-of-distribution examples in neural networks.arXiv preprint arXiv:1610.02136,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Deep Directed Generative Models with Energy-Based Probability Estimation
Kim, T. and Bengio, Y . Deep directed generative models with energy-based probability estimation.arXiv preprint arXiv:1606.03439,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Kingma, D. P. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Towards stable test-time adaptation in dynamic wild world, 2023
Niu, S., Wu, J., Zhang, Y ., Wen, Z., Chen, Y ., Zhao, P., and Tan, M. Towards stable test-time adaptation in dynamic wild world.arXiv preprint arXiv:2302.12400,
-
[8]
How to Train Your Energy - Based Models
Song, Y . and Kingma, D. P. How to train your energy-based models.arXiv preprint arXiv:2101.03288,
-
[9]
Tent: Fully Test-time Adaptation by Entropy Minimization
Wang, D., Shelhamer, E., Liu, S., Olshausen, B., and Darrell, T. Tent: Fully test-time adaptation by entropy minimiza- tion.arXiv preprint arXiv:2006.10726,
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[10]
URL https://arxiv. org/abs/2312.10165. Yair, O. and Michaeli, T. Contrastive divergence learning is a time reversal adversarial game. In9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7,
-
[11]
Zagoruyko, S. Wide residual networks.arXiv preprint arXiv:1605.07146,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
10 Contrastive Residual Energy Test-time Adaptation A
URL https://arxiv.org/ abs/2306.03536. 10 Contrastive Residual Energy Test-time Adaptation A. Technical Appendices A.1. Derivation and Function of CRETTA A.1.1. DERIVATION OFCRETTA The marginal distribution of target datapθ can be written as the product of the pretrained source modelqϕ and an exponential residual term: pθ(x) = 1 Z qϕ(x) exp(−1 β ˜Eθ(x)), ...
-
[13]
Table 16.Target energy and ECE of CRETTA vs
during adaptation, comparing CRETTA against the variant where the contrastive terms are ablated. Table 16.Target energy and ECE of CRETTA vs. without contrastive terms during adaptation on CIFAR100-C (Severity 5). Target Energy ECE Batch Idx w/ Contrastive w/o Contrastive w/ Contrastive w/0 Contrastive 0 -9.9781 -9.9781 11.11% 11.56% 9 -10.1208 -10.9536 1...
work page 1904
-
[14]
Method CIFAR10-C CIFAR100-C TinyImageNet-C Acc(↑) ECE(↓) Acc(↑) ECE(↓) Acc(↑) ECE(↓) CRETTA88.30 4.15 64.52 7.99 40.30 13.52 CRETTA with single source sample 87.62 5.39 62.67 8.9340.3014.13 Extended Buffer Ablation.While the specific content of the buffer has less impact on performance, as shown in Table 6, this does not imply that the source buffer itsel...
-
[15]
and reported results over three different random seeds. These settings ensured consistency across experiments while highlighting the robustness and effectiveness of CRETTA. For the PACS domain-generalization task, we used a learning rate of 1e−3, a batch size of 100, applying source-sample augmentation in the same way as for CIFAR100-C. All experiments we...
work page 2019
-
[16]
is a metric used to measure the calibration quality of a probabilistic model. Calibration refers to how closely the predicted probabilities of a model match the actual probabilities. ECE quantifies the discrepancy between predicted confidence and actual accuracy. ECE is calculated as shown in Equation 9: ECE= MX m=1 |binm| N · |confidencem −accuracy m|(9)...
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.