Data-Free Class-Incremental Gesture Recognition with Prototype-Guided Pseudo Feature Replay
Pith reviewed 2026-05-19 13:12 UTC · model grok-4.3
The pith
Prototype-guided pseudo features let gesture recognition models add new classes without old data or catastrophic forgetting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors establish that the Prototype-Guided Pseudo Feature Replay framework, built from pseudo feature generation with batch prototypes, variational prototype replay for old classes, truncated cross-entropy for new classes, and continual classifier re-training, overcomes catastrophic forgetting in data-free class-incremental gesture recognition by dynamically creating and replaying pseudo features that approximate past distributions.
What carries the argument
The Prototype-Guided Pseudo Feature Replay framework, which creates pseudo features on the fly from old class prototypes plus covariance matrices and new batch prototypes to maintain knowledge across incremental steps.
If this is right
- Models can incorporate new gesture classes sequentially while retaining high accuracy on all prior classes.
- No storage or access to original video samples or features from earlier training sessions is required.
- Mean global accuracy rises by 11.8% on SHREC 2017 3D and 12.8% on EgoGesture 3D over existing state-of-the-art methods.
- The continual classifier re-training step limits overfitting to newly added classes.
Where Pith is reading between the lines
- The same prototype-based pseudo replay idea could transfer to other video or sensor-based continual learning settings where data retention raises privacy concerns.
- Extending the generation process to explicitly model temporal sequences in gestures might improve handling of dynamic actions.
- Testing the method on streaming real-world gesture data with changing user styles would check whether the online prototype updates remain stable.
Load-bearing premise
That pseudo features sampled from prototypes and covariance matrices of old classes can approximate real feature distributions closely enough to prevent forgetting.
What would settle it
Directly comparing accuracy on old classes when training with real held-out features versus the generated pseudo features alone; a large drop with pseudo features would indicate the approximation fails to preserve necessary information.
Figures






read the original abstract
Gesture recognition is an important research area in the field of computer vision. Most gesture recognition efforts focus on close-set scenarios, thereby limiting the capacity to effectively handle unseen or novel gestures. We aim to address class-incremental gesture recognition, which entails the ability to accommodate new and previously unseen gestures over time. Specifically, we introduce a Prototype-Guided Pseudo Feature Replay (PGPFR) framework for data-free class-incremental gesture recognition. This framework comprises four components: Pseudo Feature Generation with Batch Prototypes (PFGBP), Variational Prototype Replay (VPR) for old classes, Truncated Cross-Entropy (TCE) for new classes, and Continual Classifier Re-Training (CCRT). To tackle the issue of catastrophic forgetting, the PFGBP dynamically generates a diversity of pseudo features in an online manner, leveraging class prototypes of old classes along with batch class prototypes of new classes. Furthermore, the VPR enforces consistency between the classifier's weights and the prototypes of old classes, leveraging class prototypes and covariance matrices to enhance robustness and generalization capabilities. The TCE mitigates the impact of domain differences of the classifier caused by pseudo features. Finally, the CCRT training strategy is designed to prevent overfitting to new classes and ensure the stability of features extracted from old classes. Extensive experiments conducted on two widely used gesture recognition datasets, namely SHREC 2017 3D and EgoGesture 3D, demonstrate that our approach outperforms existing state-of-the-art methods by 11.8\% and 12.8\% in terms of mean global accuracy, respectively. The code is available on https://github.com/sunao-101/PGPFR-3/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a Prototype-Guided Pseudo Feature Replay (PGPFR) framework for data-free class-incremental gesture recognition. The framework includes Pseudo Feature Generation with Batch Prototypes (PFGBP) to dynamically generate diverse pseudo features online from old-class prototypes and new-class batch prototypes, Variational Prototype Replay (VPR) to enforce consistency between classifier weights and old-class prototypes using covariance matrices, Truncated Cross-Entropy (TCE) to mitigate domain shifts for new classes, and Continual Classifier Re-Training (CCRT) to prevent overfitting to new classes while stabilizing old-class features. Experiments on SHREC 2017 3D and EgoGesture 3D datasets report outperformance of existing state-of-the-art methods by 11.8% and 12.8% in mean global accuracy, with code released publicly.
Significance. If the pseudo features generated from prototypes and covariances faithfully approximate old-class distributions, the work could advance practical data-free continual learning for gesture recognition in privacy-sensitive settings. The reported empirical gains on two standard 3D gesture datasets and the public code release are strengths that support reproducibility and further research in class-incremental computer vision.
major comments (2)
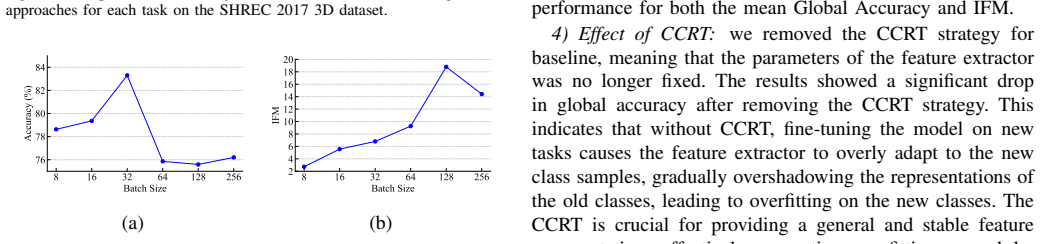
- [Method (PFGBP and VPR descriptions)] The central claim that PFGBP and VPR prevent catastrophic forgetting rests on the assumption that pseudo features generated from class prototypes and covariance matrices sufficiently approximate true old-class feature distributions. However, no direct quantitative validation such as MMD, Wasserstein distance, or per-class reconstruction error between generated pseudo features and held-out real features is reported, leaving open whether gains arise from faithful replay or auxiliary components.
- [Experiments and results] The abstract and results claim 11.8% and 12.8% mean global accuracy improvements, but the experimental section lacks details on exact baseline implementations, comprehensive ablations isolating PFGBP/VPR/TCE/CCRT contributions, number of runs for statistical significance, and full hyperparameter protocols, undermining verifiability of the empirical claims.
minor comments (1)
- [Abstract] The abstract description of the four components is somewhat dense; breaking it into shorter sentences would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and describe the revisions that will be incorporated to strengthen the manuscript.
read point-by-point responses
-
Referee: [Method (PFGBP and VPR descriptions)] The central claim that PFGBP and VPR prevent catastrophic forgetting rests on the assumption that pseudo features generated from class prototypes and covariance matrices sufficiently approximate true old-class feature distributions. However, no direct quantitative validation such as MMD, Wasserstein distance, or per-class reconstruction error between generated pseudo features and held-out real features is reported, leaving open whether gains arise from faithful replay or auxiliary components.
Authors: We agree that direct quantitative validation of the pseudo-feature approximation would provide stronger support for the core assumption. While our current ablations and overall performance gains offer indirect evidence, we will add explicit distribution-matching experiments in the revision. Specifically, we will report MMD and Wasserstein distances (and optionally per-class reconstruction error) between the generated pseudo features and held-out real features from prior tasks. These new results will be placed in the experimental section to clarify the fidelity of the replay mechanism. revision: yes
-
Referee: [Experiments and results] The abstract and results claim 11.8% and 12.8% mean global accuracy improvements, but the experimental section lacks details on exact baseline implementations, comprehensive ablations isolating PFGBP/VPR/TCE/CCRT contributions, number of runs for statistical significance, and full hyperparameter protocols, undermining verifiability of the empirical claims.
Authors: We acknowledge that additional experimental details are required for full reproducibility and verifiability. In the revised manuscript we will expand the experimental section to include: (i) precise descriptions of how each baseline was re-implemented or adapted, (ii) comprehensive ablation tables that isolate the contribution of PFGBP, VPR, TCE, and CCRT, (iii) results averaged over at least five independent runs with standard deviations, and (iv) a complete hyperparameter table together with the exact training protocol. The updated code repository will also contain the corresponding configuration files. revision: yes
Circularity Check
No significant circularity; framework components and gains are experimentally grounded rather than tautological
full rationale
The paper proposes the PGPFR framework with four explicitly motivated components (PFGBP for online pseudo-feature generation from class prototypes plus batch prototypes, VPR for weight-prototype consistency using covariances, TCE for domain-shift mitigation, and CCRT for overfitting control). These are presented as distinct algorithmic choices to address forgetting in the data-free setting, with performance claims (11.8% and 12.8% mean global accuracy gains on SHREC 2017 3D and EgoGesture 3D) resting on comparative experiments against external SOTA baselines. No equations or claims reduce a prediction to a fitted parameter by construction, no load-bearing uniqueness theorem is imported via self-citation, and the central replay mechanism is a proposed generative procedure rather than a renaming or self-definition of the target distribution. The derivation chain therefore remains self-contained against the reported empirical benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Class prototypes and covariance matrices sufficiently represent the feature distributions of old gesture classes for replay purposes.
Reference graph
Works this paper leans on
-
[1]
Computer vision-based hand gesture recognition for human-robot interaction: a review,
J. Qi, L. Ma, Z. Cui, and Y . Yu, “Computer vision-based hand gesture recognition for human-robot interaction: a review,”Complex & Intelli- gent Systems, vol. 10, no. 1, pp. 1581–1606, 2024
work page 2024
-
[2]
Searching multi-rate and multi-modal temporal enhanced networks for gesture recognition,
Z. Yu, B. Zhou, J. Wan, P. Wang, H. Chen, X. Liu, S. Z. Li, and G. Zhao, “Searching multi-rate and multi-modal temporal enhanced networks for gesture recognition,”IEEE Transactions on Image Processing, vol. 30, pp. 5626–5640, 2021
work page 2021
-
[3]
3d skeletal gesture recognition via hidden states exploration,
X. Liu, H. Shi, X. Hong, H. Chen, D. Tao, and G. Zhao, “3d skeletal gesture recognition via hidden states exploration,”IEEE Transactions on Image Processing, vol. 29, pp. 4583–4597, 2020
work page 2020
-
[4]
Foundation model for skeleton-based human action understanding,
H. Wang, W. Weng, J. Wang, F. Zhao, G.-S. Xie, X. Geng, and L. Wang, “Foundation model for skeleton-based human action understanding,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
work page 2025
-
[5]
icarl: Incremental classifier and representation learning,
S.-A. Rebuffi, A. Kolesnikov, G. Sperl, and C. H. Lampert, “icarl: Incremental classifier and representation learning,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 2001–2010
work page 2017
-
[6]
On Tiny Episodic Memories in Continual Learning
A. Chaudhry, M. Rohrbach, M. Elhoseiny, T. Ajanthan, P. K. Dokania, P. H. Torr, and M. Ranzato, “On tiny episodic memories in continual learning,”arXiv preprint arXiv:1902.10486, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1902
-
[7]
Self-sustaining representation expansion for non-exemplar class-incremental learning,
K. Zhu, W. Zhai, Y . Cao, J. Luo, and Z.-J. Zha, “Self-sustaining representation expansion for non-exemplar class-incremental learning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 9296–9305
work page 2022
-
[8]
Dreaming to distill: Data-free knowledge transfer via deepinversion,
H. Yin, P. Molchanov, J. M. Alvarez, Z. Li, A. Mallya, D. Hoiem, N. K. Jha, and J. Kautz, “Dreaming to distill: Data-free knowledge transfer via deepinversion,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 8715–8724
work page 2020
-
[9]
Data- free class-incremental hand gesture recognition,
S. Aich, J. Ruiz-Santaquiteria, Z. Lu, P. Garg, K. Joseph, A. F. Garcia, V . N. Balasubramanian, K. Kin, C. Wan, N. C. Camgozet al., “Data- free class-incremental hand gesture recognition,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 20 958–20 967
work page 2023
-
[10]
Fetril: Feature translation for exemplar-free class-incremental learning,
G. Petit, A. Popescu, H. Schindler, D. Picard, and B. Delezoide, “Fetril: Feature translation for exemplar-free class-incremental learning,” in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2023, pp. 3911–3920
work page 2023
-
[11]
Generative feature replay for class- incremental learning,
X. Liu, C. Wu, M. Menta, L. Herranz, B. Raducanu, A. D. Bagdanov, S. Jui, and J. v. de Weijer, “Generative feature replay for class- incremental learning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 2020, pp. 226– 227
work page 2020
-
[12]
Always be dreaming: A new approach for data-free class-incremental learning,
J. Smith, Y .-C. Hsu, J. Balloch, Y . Shen, H. Jin, and Z. Kira, “Always be dreaming: A new approach for data-free class-incremental learning,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 9374–9384
work page 2021
-
[13]
Real-time hand ges- ture detection and classification using convolutional neural networks,
O. K ¨op¨ukl¨u, A. Gunduz, N. Kose, and G. Rigoll, “Real-time hand ges- ture detection and classification using convolutional neural networks,” in IEEE international conference on automatic face & gesture recognition. IEEE, 2019, pp. 1–8
work page 2019
-
[14]
Res3atn-deep 3d residual attention network for hand gesture recognition in videos,
N. Dhingra and A. Kunz, “Res3atn-deep 3d residual attention network for hand gesture recognition in videos,” inInternational Conference on 3D Vision. IEEE, 2019, pp. 491–501
work page 2019
-
[15]
A. Elboushaki, R. Hannane, K. Afdel, and L. Koutti, “Multid-cnn: A multi-dimensional feature learning approach based on deep convo- lutional networks for gesture recognition in rgb-d image sequences,” Expert Systems with Applications, vol. 139, p. 112829, 2020
work page 2020
-
[16]
3d hand pose and shape estimation from rgb images for keypoint-based hand gesture recognition,
D. Avola, L. Cinque, A. Fagioli, G. L. Foresti, A. Fragomeni, and D. Pannone, “3d hand pose and shape estimation from rgb images for keypoint-based hand gesture recognition,”Pattern Recognition, vol. 129, p. 108762, 2022. JOURNAL OF LATEX CLASS FILES, VOL. XX, NO. XX, XX 2017 10
work page 2022
-
[17]
Y . Li, H. Chen, G. Feng, and Q. Miao, “Learning robust representa- tions with information bottleneck and memory network for rgb-d-based gesture recognition,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 20 968–20 978
work page 2023
-
[18]
H. Wang and L. Wang, “Beyond joints: Learning representations from primitive geometries for skeleton-based action recognition and detec- tion,”IEEE Transactions on Image Processing, vol. 27, no. 9, pp. 4382– 4394, 2018
work page 2018
-
[19]
Structural knowledge distilla- tion for efficient skeleton-based action recognition,
C. Bian, W. Feng, L. Wan, and S. Wang, “Structural knowledge distilla- tion for efficient skeleton-based action recognition,”IEEE Transactions on Image Processing, vol. 30, pp. 2963–2976, 2021
work page 2021
-
[20]
Hypergraph neural network for skeleton-based action recognition,
X. Hao, J. Li, Y . Guo, T. Jiang, and M. Yu, “Hypergraph neural network for skeleton-based action recognition,”IEEE Transactions on Image Processing, vol. 30, pp. 2263–2275, 2021
work page 2021
-
[21]
A neural network based on spd manifold learning for skeleton-based hand gesture recognition,
X. S. Nguyen, L. Brun, O. L ´ezoray, and S. Bougleux, “A neural network based on spd manifold learning for skeleton-based hand gesture recognition,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 12 036–12 045
work page 2019
-
[22]
Heterogeneous hand gesture recognition using 3d dynamic skeletal data,
Q. De Smedt, H. Wannous, and J.-P. Vandeborre, “Heterogeneous hand gesture recognition using 3d dynamic skeletal data,”Computer Vision and Image Understanding, vol. 181, pp. 60–72, 2019
work page 2019
-
[23]
Decoupled representation learning for skeleton-based gesture recognition,
J. Liu, Y . Liu, Y . Wang, V . Prinet, S. Xiang, and C. Pan, “Decoupled representation learning for skeleton-based gesture recognition,” inPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 5751–5760
work page 2020
-
[24]
Normalized edge convolutional networks for skeleton-based hand gesture recognition,
F. Guo, Z. He, S. Zhang, X. Zhao, J. Fang, and J. Tan, “Normalized edge convolutional networks for skeleton-based hand gesture recognition,” Pattern Recognition, vol. 118, p. 108044, 2021
work page 2021
-
[25]
Dynamic hand gesture recognition using improved spatio-temporal graph convolutional network,
J.-H. Song, K. Kong, and S.-J. Kang, “Dynamic hand gesture recognition using improved spatio-temporal graph convolutional network,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 32, no. 9, pp. 6227–6239, 2022
work page 2022
-
[26]
Temporal decoupling graph convolutional network for skeleton-based gesture recognition,
J. Liu, X. Wang, C. Wang, Y . Gao, and M. Liu, “Temporal decoupling graph convolutional network for skeleton-based gesture recognition,” IEEE Transactions on Multimedia, 2023
work page 2023
-
[27]
Spatial-temporal synchronous transformer for skeleton-based hand gesture recognition,
D. Zhao, H. Li, and S. Yan, “Spatial-temporal synchronous transformer for skeleton-based hand gesture recognition,”IEEE Transactions on Circuits and Systems for Video Technology, 2023
work page 2023
-
[28]
Representative task self-selection for flexible clustered lifelong learning,
G. Sun, Y . Cong, Q. Wang, B. Zhong, and Y . Fu, “Representative task self-selection for flexible clustered lifelong learning,”IEEE Transactions on Neural Networks and Learning Systems, vol. 33, no. 4, pp. 1467– 1481, 2020
work page 2020
-
[29]
What and how: Generalized lifelong spectral clustering via dual memory,
G. Sun, Y . Cong, J. Dong, Y . Liu, Z. Ding, and H. Yu, “What and how: Generalized lifelong spectral clustering via dual memory,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 7, pp. 3895–3908, 2021
work page 2021
-
[30]
Create your world: Lifelong text-to-image diffusion,
G. Sun, W. Liang, J. Dong, J. Li, Z. Ding, and Y . Cong, “Create your world: Lifelong text-to-image diffusion,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 9, pp. 6454–6470, 2024
work page 2024
-
[31]
Museummaker: Continual style customization without catastrophic forgetting supple- mentary material,
C. Liu, G. Sun, W. Liang, J. Dong, C. Qin, and Y . Cong, “Museummaker: Continual style customization without catastrophic forgetting supple- mentary material,”IEEE Transactions on Image Processing, vol. 34, pp. 2499–2512, 2025
work page 2025
-
[32]
Z. Li and D. Hoiem, “Learning without forgetting,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 40, no. 12, pp. 2935– 2947, 2017
work page 2017
-
[33]
P. Dhar, R. V . Singh, K.-C. Peng, Z. Wu, and R. Chellappa, “Learning without memorizing,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 5138–5146
work page 2019
-
[34]
Encoder based lifelong learning,
A. Rannen, R. Aljundi, M. B. Blaschko, and T. Tuytelaars, “Encoder based lifelong learning,” inProceedings of the IEEE International Conference on Computer Vision, 2017, pp. 1320–1328
work page 2017
-
[35]
Continual learning with deep generative replay,
H. Shin, J. K. Lee, J. Kim, and J. Kim, “Continual learning with deep generative replay,”Advances in Neural Information Processing Systems, vol. 30, 2017
work page 2017
-
[36]
Catastrophic forgetting, rehearsal and pseudorehearsal,
A. Robins, “Catastrophic forgetting, rehearsal and pseudorehearsal,” Connection Science, vol. 7, no. 2, pp. 123–146, 1995
work page 1995
-
[37]
Gan memory with no forgetting,
Y . Cong, M. Zhao, J. Li, S. Wang, and L. Carin, “Gan memory with no forgetting,”Advances in Neural Information Processing Systems, vol. 33, pp. 16 481–16 494, 2020
work page 2020
-
[38]
Construct dynamic graphs for hand gesture recognition via spatial-temporal atten- tion,
Y . Chen, L. Zhao, X. Peng, J. Yuan, and D. N. Metaxas, “Construct dynamic graphs for hand gesture recognition via spatial-temporal atten- tion,” inBritish Machine Vision Conference, 2019
work page 2019
-
[39]
Decoupling representation and classifier for long-tailed recognition,
B. Kang, S. Xie, M. Rohrbach, Z. Yan, A. Gordo, J. Feng, and Y . Kalantidis, “Decoupling representation and classifier for long-tailed recognition,” inInternational Conference on Learning Representations, 2019
work page 2019
-
[40]
Mediapipe hands: On-device real-time hand tracking,
F. Zhang, V . Bazarevsky, A. Vakunov, A. Tkachenka, G. Sung, C.-L. Chang, and M. Grundmann, “Mediapipe hands: On-device real-time hand tracking,”arXiv preprint arXiv:2006.10214, 2020
-
[41]
R-dfcil: Relation-guided representation learning for data-free class incremental learning,
Q. Gao, C. Zhao, B. Ghanem, and J. Zhang, “R-dfcil: Relation-guided representation learning for data-free class incremental learning,” in Proceedings of the European Conference on Computer Vision. Springer, 2022, pp. 423–439
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.