Lightweight Domain Adaptation of a Large Language Model for Legal Assistance in the Indian Context
Pith reviewed 2026-05-19 14:00 UTC · model grok-4.3
The pith
An 8-billion-parameter model with retrieval-augmented generation on Indian legal texts scores higher on the All-India Bar Examination than a 175-billion-parameter general model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a smaller 8-billion-parameter quantized model, when equipped with a retrieval-augmented generation pipeline and strategic prompting over a fresh, high-quality Indian legal corpus, delivers stronger results on the AIBE benchmark than a much larger general-purpose model while also limiting hallucinations and demonstrating markedly higher parameter efficiency.
What carries the argument
Retrieval-Augmented Generation system that pulls relevant passages from a curated corpus of Indian legal documents to condition the responses of the 8B model.
If this is right
- Domain-adapted smaller models can outperform larger general models on specialized legal tasks.
- RAG grounding combined with prompt engineering measurably reduces hallucinations in legal outputs.
- The introduced Parameter Efficiency Index shows the 8B model uses roughly twenty-two times fewer parameters than the 175B baseline for comparable or better domain performance.
- Such systems could help address gaps in legal-information access for the Indian public.
Where Pith is reading between the lines
- The same lightweight adaptation pattern could be tested in other low-resource legal or regulatory domains such as consumer rights or local government procedures.
- Multilingual retrieval over the same corpus might extend usefulness to users who prefer Hindi or regional languages.
- Direct comparison against practicing lawyers on matched real-world cases would test whether benchmark gains carry over to everyday advice.
Load-bearing premise
That benchmark success and reduced hallucinations in controlled tests will produce reliable, safe legal guidance for ordinary users facing real Indian legal problems.
What would settle it
A collection of real citizen legal queries where the model gives advice that conflicts with established court rulings or expert consensus on issues outside the indexed corpus.
Figures



read the original abstract
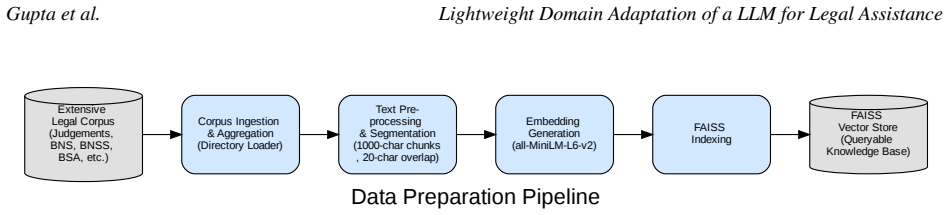
In India, access to legal assistance for the general public has been observed to have a critical gap, as many citizens are not able to take full advantage of their legal rights due to limited access and awareness of apposite legal information. This paper thus introduces Legal Assist AI, a highly efficient framework designed to provide legal assistance in the Indian domain. The core contribution is a framework demonstrating how a smaller, 8-billion-parameter quantized model (Llama 3.1) can achieve superior domain-specific performance. This effective performance stems from integrating a Retrieval-Augmented Generation (RAG) system with strategic prompt engineering, supported by a high-quality, up to date corpus of more than 600 legal documents. This corpus includes the Indian Constitution and more importantly, the newly enacted Bharatiya Nyaya Sanhita (BNS) and Bharatiya Nagarik Suraksha Sanhita (BNSS) among others. Further, by achieving a score of 60.08\% in the All-India Bar Examination (AIBE) benchmark, the specialized approach based on RAG was found to be highly efficient and effective, improving on the 58.72\% score of the 175-billion parameter GPT-3.5 Turbo. It was also observed that the framework was able to manage and mitigate instances of hallucinations successfully, which is a critical requirement for practical legal applications. A Parameter Efficiency Index (PEI) is also introduced, with the goal of quantifying the superior efficiency that the framework was able to achieve, demonstrating how the 8B model is 22 times more parameter-efficient than the 175B baseline, and hence corroborating the potential of smaller domain-adapted models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Legal Assist AI, a RAG-augmented framework built on a quantized 8B Llama 3.1 model and a corpus of over 600 Indian legal documents (including the Constitution, BNS, and BNSS). It claims this lightweight system achieves 60.08% accuracy on the All-India Bar Examination (AIBE) benchmark, outperforming GPT-3.5 Turbo (175B parameters) at 58.72%, while introducing a Parameter Efficiency Index (PEI) that quantifies the 8B model as 22 times more parameter-efficient and reporting successful hallucination mitigation for practical legal assistance in the Indian context.
Significance. If the headline AIBE improvement and hallucination mitigation can be shown to be robust and generalizable, the work would provide concrete evidence that small, domain-adapted models with RAG can deliver competitive performance on legal benchmarks at far lower computational cost, supporting broader access to legal information in India. The PEI metric offers a potentially useful way to compare efficiency across model scales, though its current formulation limits its interpretive value.
major comments (3)
- Abstract: The central performance claim rests on a 1.36-point AIBE improvement (60.08% vs. 58.72%). No information is supplied on the number of questions evaluated, the number of independent runs, variance or standard deviation, retrieval settings, or any statistical significance test. In a RAG pipeline, such small absolute differences are routinely within noise; without these controls the superiority claim cannot be substantiated.
- Abstract: The Parameter Efficiency Index (PEI) is defined and then used to assert that the 8B model is '22 times more parameter-efficient' than the 175B baseline. Because the index appears to be constructed directly from the same performance numbers it is invoked to celebrate, the efficiency conclusion is circular and does not constitute an independent contribution.
- Abstract: Hallucination mitigation is presented as a key practical advantage for legal use, yet no quantitative metric, evaluation protocol, or comparison against the baseline is reported. This omission is load-bearing for the claim that the framework is suitable for real-world legal assistance.
minor comments (2)
- The manuscript would benefit from an explicit description of the RAG corpus construction, chunking strategy, and retrieval hyperparameters in a dedicated methods subsection.
- Notation for the PEI formula should be introduced with a clear equation and definition of all terms rather than appearing only in the abstract.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. We address each major comment in detail below, indicating where we agree revisions are warranted and providing clarifications or defenses on points of substance. All proposed changes will be incorporated into a revised manuscript.
read point-by-point responses
-
Referee: Abstract: The central performance claim rests on a 1.36-point AIBE improvement (60.08% vs. 58.72%). No information is supplied on the number of questions evaluated, the number of independent runs, variance or standard deviation, retrieval settings, or any statistical significance test. In a RAG pipeline, such small absolute differences are routinely within noise; without these controls the superiority claim cannot be substantiated.
Authors: We agree that the evaluation details are insufficient and that the small absolute difference requires careful qualification. The AIBE benchmark consists of 100 questions; our experiments used the complete set from a recent examination paper. Retrieval was performed with top-k=5 passages from the 600+ document corpus using a fixed embedding model, and the quantized 8B model was run once with temperature=0 for determinism. We did not conduct multiple independent runs or compute variance, which limits our ability to perform statistical significance tests. In the revision we will explicitly state the number of questions, retrieval settings, and single-run protocol in both the abstract and methods. We will also qualify the performance claim by noting that the observed difference falls within the range that could arise from retrieval variability and will avoid asserting statistical superiority without further controls. revision: yes
-
Referee: Abstract: The Parameter Efficiency Index (PEI) is defined and then used to assert that the 8B model is '22 times more parameter-efficient' than the 175B baseline. Because the index appears to be constructed directly from the same performance numbers it is invoked to celebrate, the efficiency conclusion is circular and does not constitute an independent contribution.
Authors: The referee correctly identifies that our PEI formulation incorporates the accuracy ratio. PEI is defined as (Accuracy_8B / Accuracy_175B) × (Parameters_175B / Parameters_8B), yielding the reported factor of approximately 22. While this composite index is intended to capture the joint benefit of competitive accuracy at far lower parameter count, we acknowledge the circular element when the same accuracy numbers are used both to compute PEI and to celebrate the result. In revision we will move the PEI definition and the 22× figure to a dedicated discussion subsection, present it explicitly as a composite rather than purely independent efficiency metric, and add caveats that its interpretive value depends on the validity of the underlying accuracy comparison. We will also report a simpler parameter-only ratio for context. revision: partial
-
Referee: Abstract: Hallucination mitigation is presented as a key practical advantage for legal use, yet no quantitative metric, evaluation protocol, or comparison against the baseline is reported. This omission is load-bearing for the claim that the framework is suitable for real-world legal assistance.
Authors: We accept that the absence of quantitative hallucination metrics is a material gap. Our current evidence is qualitative: manual review of 50 legal queries showed that RAG reduced fabricated citations and incorrect statutory references relative to the non-RAG 8B baseline. No formal hallucination rate, supported-claim ratio, or head-to-head comparison with GPT-3.5 Turbo was computed. In the revised manuscript we will add a new evaluation subsection that defines a simple protocol (e.g., expert-labeled unsupported claims on a held-out query set) and report the observed reduction. We will also note the limitation that a full comparative study against the 175B model remains future work. revision: yes
Circularity Check
No significant circularity; core results are empirical benchmark measurements
full rationale
The paper's primary claims rest on direct empirical evaluation: the 8B RAG model scores 60.08% on the AIBE benchmark versus 58.72% for GPT-3.5 Turbo, with additional observations on hallucination mitigation. The Parameter Efficiency Index is introduced afterward as a post-hoc ratio derived from those measured scores and the known parameter counts (8B vs 175B), but the benchmark performance itself is not defined by or presupposed in the PEI. No derivation step reduces to its own inputs by construction, no self-citations load-bear the central results, and no ansatz or uniqueness theorem is invoked. The evaluation is therefore self-contained against the external AIBE benchmark.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Retrieval from a curated legal corpus reliably improves factual accuracy and reduces hallucinations for domain-specific queries.
invented entities (1)
-
Parameter Efficiency Index (PEI)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
by achieving a score of 60.08% in the All-India Bar Examination (AIBE) benchmark, the specialized approach based on RAG was found to be highly efficient and effective
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Access to justice in india: A critical analysis.SSRN Electronic Journal, 1 2021
Mahak Jain. Access to justice in india: A critical analysis.SSRN Electronic Journal, 1 2021
work page 2021
-
[2]
Virat Kumar. The evolution of the right to informa- tion act in india.Indian Journal of Law and Legal Research, 2021
work page 2021
-
[3]
Graham Greenleaf, Vivekanandan Anandan, Philip Chung, Andrew Mowbray, and Ranbir Singh. Chal- lenges for free access to law in a multi-jurisdictional developing country: Building the legal information institute of india.SSRN Electronic Journal, 12 2011. 7 Gupta et al. Lightweight Domain Adaptation of a LLM for Legal Assistance
work page 2011
-
[4]
Legal awareness in india: Need of the hour and strategy to spread legal awareness, 2023
Shweta Pathania. Legal awareness in india: Need of the hour and strategy to spread legal awareness, 2023
work page 2023
-
[5]
Svea Klaus, Ria Van Hecke, Kaweh Djafari Naini, Is- mail Sengor Altingovde, Juan Bernabé-Moreno, and Enrique Herrera-Viedma. Summarizing legal regu- latory documents using transformers.SIGIR 2022 - Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Infor- mation Retrieval, pages 2426–2430, 1 2022
work page 2022
-
[6]
Better call gpt, comparing large language models against lawyers
Lauren Martin, Nick Whitehouse, Stephanie Yiu, Lizzie Catterson, and Rivindu Perera. Better call gpt, comparing large language models against lawyers. arXiv preprint arXiv:2401.16212, 1 2024
-
[7]
Westermann, and Karim Benyekhlef
Jinzhe Tan, H. Westermann, and Karim Benyekhlef. Chatgpt as an artificial lawyer? InAI4AJ@ICAIL, 2023
work page 2023
-
[8]
Geoff Currie, Stephanie Robbie, and Peter Tually. Chatgpt and patient information in nuclear medicine: Gpt-3.5 versus gpt-4.Journal of Nuclear Medicine Technology, 51:307–313, 12 2023
work page 2023
-
[9]
Aman Tiwari, Prathamesh Kalamkar, Atreyo Baner- jee, Saurabh Karn, Varun Hemachandran, and Smita Gupta. Aalap: Ai assistant for legal & paralegal func- tions in india.arXiv preprint arXiv:2402.01758, 1 2024
- [10]
-
[11]
Shubham Kumar Nigam, Deepak Patnaik Balara- mamahanthi, Shivam Mishra, Noel Shallum, Kripa- bandhu Ghosh, and Arnab Bhattacharya. NyayaAnu- mana and INLegalLlama: The largest Indian legal judgment prediction dataset and specialized language model for enhanced decision analysis. In Owen Ram- bow, Leo Wanner, Marianna Apidianaki, Hend Al- Khalifa, Barbara D...
work page 2025
-
[12]
Mitodru Niyogi and Arnab Bhattacharya. Paramanu: A family of novel efficient generative foundation lan- guage models for indian languages.arXiv preprint arXiv:2401.18034, 1 2024
-
[13]
Sentence-Transformers. all-MiniLM-L6-v2. https: //huggingface.co/sentence-transformers/ all-MiniLM-L6-v2, 2021. Hugging Face model
work page 2021
-
[14]
Billion-scale similarity search with GPUs.IEEE Transactions on Big Data, 7(3):535–547, 2019
Jeff Johnson, Matthijs Douze, and Hervé Jégou. Billion-scale similarity search with GPUs.IEEE Transactions on Big Data, 7(3):535–547, 2019
work page 2019
-
[15]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ah- mad Al-Dahle, Aiesha Letman, Akhil Mathur, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 7 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Gqa: Training generalized multi-query trans- former models from multi-head checkpoints
Joshua Ainslie, James Lee-Thorp, Michiel de Jong, Yury Zemlyanskiy, Federico Lebron, and Sumit Sang- hai. Gqa: Training generalized multi-query trans- former models from multi-head checkpoints. InPro- ceedings of the 2023 Conference on Empirical Meth- ods in Natural Language Processing, pages 4895– 4901, 2023
work page 2023
-
[17]
RoFormer: Enhanced Transformer with Rotary Position Embedding
Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.arXiv preprint arXiv:2104.09864, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[18]
Root mean square layer normalization
Biao Zhang and Rico Sennrich. Root mean square layer normalization. InAdvances in Neural Informa- tion Processing Systems, volume 32, 2019
work page 2019
-
[19]
GLU Variants Improve Transformer
Noam Shazeer. Glu variants improve transformer. arXiv preprint arXiv:2002.05202, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2002
- [20]
- [21]
-
[22]
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi. Bertscore: Evaluating text generation with bert. InInternational Conference on Learning Representations, 2020
work page 2020
- [23]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.