A Benchmark Dataset for Graph Regression with Homogeneous and Multi-Relational Variants
Pith reviewed 2026-05-19 13:06 UTC · model grok-4.3
The pith
RelSC provides a new benchmark for graph regression using program graphs labeled by execution time in both homogeneous and multi-relational forms.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RelSC is a graph-regression dataset constructed from program graphs that integrate syntactic and semantic information from source code, with each graph annotated by the execution-time cost of the program. The dataset comes in a homogeneous variant (RelSC-H) with a single edge type and a multi-relational variant (RelSC-M) that maintains multiple edge types, allowing comparison of how representation choice affects model performance. Evaluations demonstrate that graph neural networks exhibit different behaviors across these variants.
What carries the argument
The RelSC dataset and its homogeneous (RelSC-H) versus multi-relational (RelSC-M) variants, which encode program structure for predicting continuous execution costs.
If this is right
- Graph models need to account for both single-relation and multi-relation structures to perform well on diverse data.
- The choice of graph representation significantly influences regression accuracy on execution time.
- Continuous labels from runtime costs provide a regression target distinct from typical discrete or property-based ones in other benchmarks.
- This setup can help develop models that generalize better across homogeneous and heterogeneous graphs.
Where Pith is reading between the lines
- Similar datasets could be created from other programming languages or domains to test broader applicability.
- The performance gaps might point to specific ways multi-relational edges capture semantic dependencies useful for prediction.
- This benchmark could support research into efficient code analysis tools that predict runtime without execution.
Load-bearing premise
The syntactic and semantic information extracted from source code into graph form sufficiently captures the factors that determine execution time.
What would settle it
If experiments show that execution time labels cannot be predicted from the graphs better than a simple baseline or if the performance difference between homogeneous and multi-relational variants disappears under different model trainings.
Figures

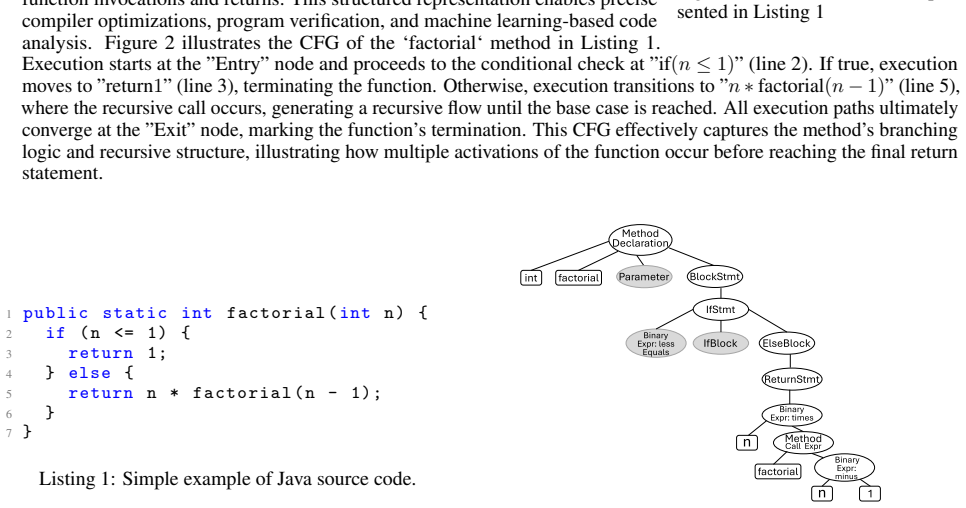










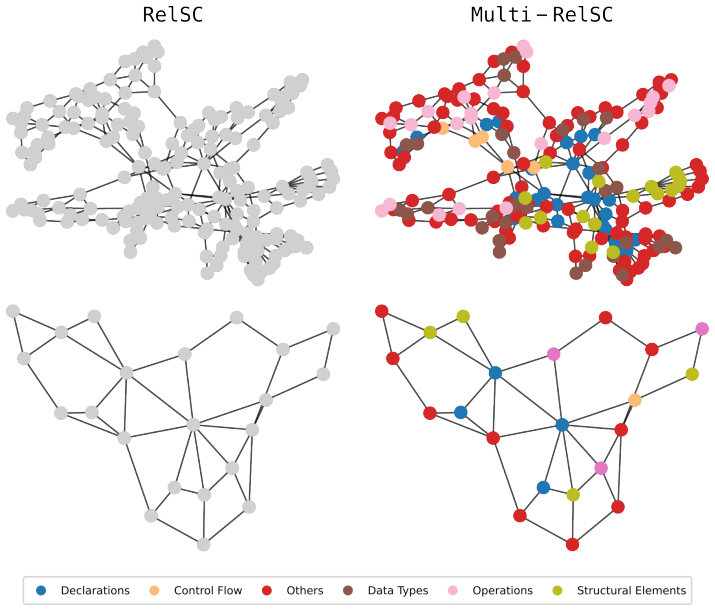


read the original abstract
Graph-level regression underpins many real-world applications, yet public benchmarks remain heavily skewed toward molecular graphs and citation networks. This limited diversity hinders progress on models that must generalize across both homogeneous and heterogeneous graph structures. We introduce RelSC, a new graph-regression dataset built from program graphs that combine syntactic and semantic information extracted from source code. Each graph is labelled with the execution-time cost of the corresponding program, providing a continuous target variable that differs markedly from those found in existing benchmarks. RelSC is released in two complementary variants. RelSC-H supplies rich node features under a single (homogeneous) edge type, while RelSC-M preserves the original multi-relational structure, connecting nodes through multiple edge types that encode distinct semantic relationships. Together, these variants let researchers probe how representation choice influences model behaviour. We evaluate a diverse set of graph neural network architectures on both variants of RelSC. The results reveal consistent performance differences between the homogeneous and multi-relational settings, emphasising the importance of structural representation. These findings demonstrate RelSC's value as a challenging and versatile benchmark for advancing graph regression methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RelSC, a new graph-regression dataset constructed from program graphs that encode both syntactic and semantic information extracted from source code. Each graph is paired with a continuous label given by the execution-time cost of the corresponding program. The dataset is released in two variants: RelSC-H, which uses a single homogeneous edge type together with rich node features, and RelSC-M, which retains the original multi-relational edge types. A range of graph neural network architectures is evaluated on both variants; the results show consistent performance differences between the homogeneous and multi-relational settings, which the authors interpret as evidence that structural representation choice matters for graph regression.
Significance. If the reported performance gaps prove robust, RelSC would supply a useful addition to the limited set of public graph-regression benchmarks. The continuous execution-time target differs from the discrete or molecular-property targets that dominate existing collections, and the paired homogeneous/multi-relational variants enable controlled investigation of representation effects. The explicit release of both variants is a constructive feature that could support future ablation studies.
major comments (2)
- [Evaluation] Evaluation section: the abstract and results description state that consistent performance differences appear between RelSC-H and RelSC-M, yet no information is supplied on train/validation/test splits, hyper-parameter selection protocol, number of random seeds, error bars, or statistical significance tests. Without these details it is impossible to determine whether the observed gaps are stable or sensitive to post-hoc choices.
- [Methods] Methods / Dataset construction: the two variants are described as differing primarily in edge-type encoding, but the manuscript does not state that the node-feature matrices (including feature sets and dimensionality) are identical across RelSC-H and RelSC-M. Any systematic mismatch in node features or preprocessing would confound the attribution of performance differences to relational structure rather than to feature or extraction artifacts.
minor comments (2)
- [Abstract] The abstract refers to “rich node features” for RelSC-H and “original multi-relational structure” for RelSC-M; a short table comparing the exact node-feature dimensions and edge-type counts of the two variants would improve clarity.
- [Introduction] A few sentences in the introduction repeat the motivation for graph regression benchmarks; tightening the prose would reduce redundancy.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of RelSC as a potential benchmark. We address the two major comments point by point below and will revise the manuscript to incorporate the requested clarifications and details.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the abstract and results description state that consistent performance differences appear between RelSC-H and RelSC-M, yet no information is supplied on train/validation/test splits, hyper-parameter selection protocol, number of random seeds, error bars, or statistical significance tests. Without these details it is impossible to determine whether the observed gaps are stable or sensitive to post-hoc choices.
Authors: We agree that these experimental details are essential for reproducibility and for confirming that the observed performance differences are robust. In the revised manuscript we will expand the Evaluation section to explicitly describe the train/validation/test splits, the hyper-parameter selection protocol, the number of random seeds, the reporting of error bars, and the statistical significance tests used to compare results between the two variants. revision: yes
-
Referee: [Methods] Methods / Dataset construction: the two variants are described as differing primarily in edge-type encoding, but the manuscript does not state that the node-feature matrices (including feature sets and dimensionality) are identical across RelSC-H and RelSC-M. Any systematic mismatch in node features or preprocessing would confound the attribution of performance differences to relational structure rather than to feature or extraction artifacts.
Authors: We confirm that the node-feature matrices (feature sets and dimensionality) are identical in RelSC-H and RelSC-M; the variants differ only in edge-type encoding. To eliminate any possible ambiguity we will add an explicit statement to this effect in the Methods / Dataset construction section of the revised manuscript. revision: yes
Circularity Check
No circularity: dataset introduction with empirical observations only
full rationale
The paper introduces the RelSC benchmark dataset from program graphs labeled by execution time and releases two variants (RelSC-H homogeneous with rich node features; RelSC-M multi-relational). It then reports empirical GNN performance differences between variants. No derivation chain, first-principles prediction, equation, or fitted parameter is claimed or present; the work contains no self-definitional steps, no predictions that reduce to inputs by construction, and no load-bearing self-citations of uniqueness theorems. The central claims rest on dataset construction and direct experimental comparison, which are self-contained against external benchmarks and do not reduce to the paper's own fitted values or prior author work.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce RelSC, a new graph-regression dataset built from program graphs that combine syntactic and semantic information extracted from source code. Each graph is labelled with the execution-time cost of the corresponding program
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
RelSC-H supplies rich node features under a single (homogeneous) edge type, while RelSC-M preserves the original multi-relational structure
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
The graph neural network model.IEEE transactions on neural networks, 20(1):61–80, 2008
Franco Scarselli, Marco Gori, Ah Chung Tsoi, Markus Hagenbuchner, and Gabriele Monfardini. The graph neural network model.IEEE transactions on neural networks, 20(1):61–80, 2008
work page 2008
-
[2]
Alessio Micheli. Neural network for graphs: A contextual constructive approach.IEEE Transactions on Neural Networks, 20(3):498–511, 2009
work page 2009
-
[3]
Semi-Supervised Classification with Graph Convolutional Networks
Thomas N Kipf and Max Welling. Semi-supervised classification with graph convolutional networks.arXiv preprint arXiv:1609.02907, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[4]
Will Hamilton, Zhitao Ying, and Jure Leskovec. Inductive representation learning on large graphs.Advances in neural information processing systems, 30, 2017
work page 2017
-
[5]
Petar Veliˇckovi´c, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Li`o, and Yoshua Bengio. Graph attention networks. InInternational Conference on Learning Representations, 2018
work page 2018
-
[6]
Johannes Gasteiger, Aleksandar Bojchevski, and Stephan G ¨unnemann. Predict then propagate: Graph neural networks meet personalized pagerank.arXiv preprint arXiv:1810.05997, 2018
-
[7]
Muhan Zhang and Yixin Chen. Link prediction based on graph neural networks.Advances in neural information processing systems, 31, 2018
work page 2018
-
[8]
Simplifying graph convolutional networks
Felix Wu, Amauri Souza, Tianyi Zhang, Christopher Fifty, Tao Yu, and Kilian Weinberger. Simplifying graph convolutional networks. InInternational conference on machine learning, pages 6861–6871. PMLR, 2019. 8https://anonymous.4open.science/r/graph_regression_datasets-407E/ 12
work page 2019
-
[9]
Muhan Zhang, Pan Li, Yinglong Xia, Kai Wang, and Long Jin. Labeling trick: A theory of using graph neural networks for multi-node representation learning.Advances in Neural Information Processing Systems, 34:9061–9073, 2021
work page 2021
-
[10]
A simple and expressive graph neural network based method for structural link representation
Veronica Lachi, Francesco Ferrini, Antonio Longa, Bruno Lepri, and Andrea Passerini. A simple and expressive graph neural network based method for structural link representation. InICML 2024 Workshop on Geometry- grounded Representation Learning and Generative Modeling, 2024
work page 2024
-
[11]
Sheaf diffusion goes nonlinear: Enhancing GNNs with adaptive sheaf laplacians
Olga Zaghen, Antonio Longa, Steve Azzolin, Lev Telyatnikov, Andrea Passerini, and Pietro Lio. Sheaf diffusion goes nonlinear: Enhancing GNNs with adaptive sheaf laplacians. InICML 2024 Workshop on Geometry-grounded Representation Learning and Generative Modeling, 2024
work page 2024
-
[12]
Linkbench: a database benchmark based on the facebook social graph
Timothy G Armstrong, Vamsi Ponnekanti, Dhruba Borthakur, and Mark Callaghan. Linkbench: a database benchmark based on the facebook social graph. InProceedings of the 2013 ACM SIGMOD International Conference on Management of Data, pages 1185–1196, 2013
work page 2013
-
[13]
Weihua Hu, Matthias Fey, Marinka Zitnik, Yuxiao Dong, Hongyu Ren, Bowen Liu, Michele Catasta, and Jure Leskovec. Open graph benchmark: Datasets for machine learning on graphs.Advances in neural information processing systems, 33:22118–22133, 2020
work page 2020
-
[14]
arXiv preprint arXiv:2007.08663 , year=
Christopher Morris, Nils M Kriege, Franka Bause, Kristian Kersting, Petra Mutzel, and Marion Neumann. Tudataset: A collection of benchmark datasets for learning with graphs.arXiv preprint arXiv:2007.08663, 2020
-
[15]
Long range graph benchmark.Advances in Neural Information Processing Systems, 35:22326–22340, 2022
Vijay Prakash Dwivedi, Ladislav Ramp´aˇsek, Michael Galkin, Ali Parviz, Guy Wolf, Anh Tuan Luu, and Dominique Beaini. Long range graph benchmark.Advances in Neural Information Processing Systems, 35:22326–22340, 2022
work page 2022
-
[16]
Zhou Zhiyao, Sheng Zhou, Bochao Mao, Xuanyi Zhou, Jiawei Chen, Qiaoyu Tan, Daochen Zha, Yan Feng, Chun Chen, and Can Wang. Opengsl: A comprehensive benchmark for graph structure learning.Advances in Neural Information Processing Systems, 36, 2024
work page 2024
-
[17]
Shenyang Huang, Farimah Poursafaei, Jacob Danovitch, Matthias Fey, Weihua Hu, Emanuele Rossi, Jure Leskovec, Michael Bronstein, Guillaume Rabusseau, and Reihaneh Rabbany. Temporal graph benchmark for machine learning on temporal graphs.Advances in Neural Information Processing Systems, 36, 2024
work page 2024
-
[18]
Xiao-Meng Zhang, Li Liang, Lin Liu, and Ming-Jing Tang. Graph neural networks and their current applications in bioinformatics.Frontiers in genetics, 12:690049, 2021
work page 2021
-
[19]
Biognn: how graph neural networks can solve biological problems
Pietro Bongini, Niccol`o Pancino, Franco Scarselli, and Monica Bianchini. Biognn: how graph neural networks can solve biological problems. InArtificial Intelligence and Machine Learning for Healthcare: Vol. 1: Image and Data Analytics, pages 211–231. Springer, 2022
work page 2022
-
[20]
Weiwei Jiang and Jiayun Luo. Graph neural network for traffic forecasting: A survey.Expert Systems with Applications, 207:117921, 2022
work page 2022
-
[21]
Xiao Li, Li Sun, Mengjie Ling, and Yan Peng. A survey of graph neural network based recommendation in social networks.Neurocomputing, 549:126441, 2023
work page 2023
-
[22]
Graph neural networks for social recommendation
Wenqi Fan, Yao Ma, Qing Li, Yuan He, Eric Zhao, Jiliang Tang, and Dawei Yin. Graph neural networks for social recommendation. InThe world wide web conference, pages 417–426, 2019
work page 2019
-
[23]
Dejun Jiang, Zhenxing Wu, Chang-Yu Hsieh, Guangyong Chen, Ben Liao, Zhe Wang, Chao Shen, Dongsheng Cao, Jian Wu, and Tingjun Hou. Could graph neural networks learn better molecular representation for drug discovery? a comparison study of descriptor-based and graph-based models.Journal of Cheminformatics, 13(1):12, Feb 2021
work page 2021
-
[24]
Oliver Wieder, Stefan Kohlbacher, M´elaine Kuenemann, Arthur Garon, Pierre Ducrot, Thomas Seidel, and Thierry Langer. A compact review of molecular property prediction with graph neural networks.Drug Discovery Today: Technologies, 37:1–12, 2020
work page 2020
-
[25]
Zehong Zhang, Lifan Chen, Feisheng Zhong, Dingyan Wang, Jiaxin Jiang, Sulin Zhang, Hualiang Jiang, Mingyue Zheng, and Xutong Li. Graph neural network approaches for drug-target interactions.Current Opinion in Structural Biology, 73:102327, 2022
work page 2022
-
[26]
Performance improvements in chrome’s rendering pipeline
Chris Harrelson. Performance improvements in chrome’s rendering pipeline. chromium blog, 2017
work page 2017
-
[27]
Rapid regression detection in software deployments through sequential testing
Michael Lindon, Chris Sanden, and Vach´e Shirikian. Rapid regression detection in software deployments through sequential testing. InProceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 3336–3346, 2022
work page 2022
-
[28]
Pace: A program analysis framework for continuous performance prediction
Chidera Biringa and G¨okhan Kul. Pace: A program analysis framework for continuous performance prediction. ACM Transactions on Software Engineering and Methodology, 33(4):1–23, 2024. 13
work page 2024
-
[29]
John McCarthy. Recursive functions of symbolic expressions and their computation by machine, part i.Communi- cations of the ACM, 3(4):184–195, 1960
work page 1960
-
[30]
Understanding source code evolution using abstract syntax tree matching
Iulian Neamtiu, Jeffrey S Foster, and Michael Hicks. Understanding source code evolution using abstract syntax tree matching. InProceedings of the 2005 international workshop on Mining software repositories, pages 1–5, 2005
work page 2005
-
[31]
A novel neural source code representation based on abstract syntax tree
Jian Zhang, Xu Wang, Hongyu Zhang, Hailong Sun, Kaixuan Wang, and Xudong Liu. A novel neural source code representation based on abstract syntax tree. In2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE), pages 783–794. IEEE, 2019
work page 2019
-
[32]
Ensheng Shi, Yanlin Wang, Lun Du, Hongyu Zhang, Shi Han, Dongmei Zhang, and Hongbin Sun. Cast: Enhancing code summarization with hierarchical splitting and reconstruction of abstract syntax trees. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 4053–4062, 2021
work page 2021
-
[33]
Peter Samoaa, Firas Bayram, Pasquale Salza, and Philipp Leitner. A systematic mapping study of source code representation for deep learning in software engineering.IET Software, 16(4):351–385, 2022
work page 2022
-
[34]
Control flow analysis.ACM Sigplan Notices, 5(7):1–19, 1970
Frances E Allen. Control flow analysis.ACM Sigplan Notices, 5(7):1–19, 1970
work page 1970
-
[35]
Simone Campanoni and Stefano Crespi Reghizzi. Traces of control-flow graphs. InDevelopments in Language Theory: 13th International Conference, DLT 2009, Stuttgart, Germany, June 30-July 3, 2009. Proceedings 13, pages 156–169. Springer, 2009
work page 2009
-
[36]
James Koppel, Jackson Kearl, and Armando Solar-Lezama. Automatically deriving control-flow graph generators from operational semantics.Proceedings of the ACM on Programming Languages, 6(ICFP):742–771, 2022
work page 2022
-
[37]
Survey of malware analysis through control flow graph using machine learning
Shaswata Mitra, Stephen A Torri, and Sudip Mittal. Survey of malware analysis through control flow graph using machine learning. In2023 IEEE 22nd International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom), pages 1554–1561. IEEE, 2023
work page 2023
-
[38]
A preliminary architecture for a basic data-flow processor
Jack B Dennis and David P Misunas. A preliminary architecture for a basic data-flow processor. InProceedings of the 2nd annual symposium on Computer architecture, pages 126–132, 1974
work page 1974
-
[39]
Alan L. Davis and Robert M. Keller. Data flow program graphs.Computer, 15(02):26–41, 1982
work page 1982
-
[40]
A formal definition of data flow graph models.IEEE Transactions on computers, 100(11):940–948, 1986
Kavi, Buckles, and Bhat. A formal definition of data flow graph models.IEEE Transactions on computers, 100(11):940–948, 1986
work page 1986
-
[41]
Zhiqiang Xie, Minjie Wang, Zihao Ye, Zheng Zhang, and Rui Fan. Graphiler: Optimizing graph neural networks with message passing data flow graph.Proceedings of Machine Learning and Systems, 4:515–528, 2022
work page 2022
-
[42]
Tep-gnn: Accurate execution time prediction of functional tests using graph neural networks
Peter Samoaa, Antonio Longa, Mazen Mohamad, Morteza Haghir Chehreghani, and Philipp Leitner. Tep-gnn: Accurate execution time prediction of functional tests using graph neural networks. In Davide Taibi, Marco Kuhrmann, Tommi Mikkonen, Jil Kl¨under, and Pekka Abrahamsson, editors,Product-Focused Software Process Improvement, pages 464–479, Cham, 2022. Spri...
work page 2022
-
[43]
Moleculenet: a benchmark for molecular machine learning.Chemical science, 9(2):513–530, 2018
Zhenqin Wu, Bharath Ramsundar, Evan N Feinberg, Joseph Gomes, Caleb Geniesse, Aneesh S Pappu, Karl Leswing, and Vijay Pande. Moleculenet: a benchmark for molecular machine learning.Chemical science, 9(2):513–530, 2018
work page 2018
-
[44]
Rafael G´omez-Bombarelli, Jennifer N Wei, David Duvenaud, Jos´e Miguel Hern´andez-Lobato, Benjam´ın S´anchez- Lengeling, Dennis Sheberla, Jorge Aguilera-Iparraguirre, Timothy D Hirzel, Ryan P Adams, and Al´an Aspuru- Guzik. Automatic chemical design using a data-driven continuous representation of molecules.ACS central science, 4(2):268–276, 2018
work page 2018
-
[45]
Yuquan Li, Chang-Yu Hsieh, Ruiqiang Lu, Xiaoqing Gong, Xiaorui Wang, Pengyong Li, Shuo Liu, Yanan Tian, Dejun Jiang, Jiaxian Yan, et al. An adaptive graph learning method for automated molecular interactions and properties predictions.nature machine intelligence, 4(7):645–651, 2022
work page 2022
-
[46]
David L Mobley and J Peter Guthrie. Freesolv: a database of experimental and calculated hydration free energies, with input files.Journal of computer-aided molecular design, 28:711–720, 2014
work page 2014
-
[47]
Zhihai Liu, Yan Li, Li Han, Jie Li, Jie Liu, Zhixiong Zhao, Wei Nie, Yuchen Liu, and Renxiao Wang. Pdb-wide collection of binding data: current status of the pdbbind database.Bioinformatics, 31(3):405–412, 2015
work page 2015
-
[48]
Graph rationalization with environment-based augmentations
Gang Liu, Tong Zhao, Jiaxin Xu, Tengfei Luo, and Meng Jiang. Graph rationalization with environment-based augmentations. InProceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 1069–1078, 2022
work page 2022
-
[49]
Graph neural network for source code defect prediction.IEEE access, 10:10402–10415, 2022
Lucija ˇSiki´c, Adrian Satja Kurdija, Klemo Vladimir, and Marin ˇSili´c. Graph neural network for source code defect prediction.IEEE access, 10:10402–10415, 2022. 14
work page 2022
-
[50]
Regvd: Revisiting graph neural networks for vulnerability detection
Van-Anh Nguyen, Dai Quoc Nguyen, Van Nguyen, Trung Le, Quan Hung Tran, and Dinh Phung. Regvd: Revisiting graph neural networks for vulnerability detection. InProceedings of the ACM/IEEE 44th International Conference on Software Engineering: Companion Proceedings, pages 178–182, 2022
work page 2022
-
[51]
Miltiadis Allamanis. Graph neural networks in program analysis.Graph neural networks: foundations, frontiers, and applications, pages 483–497, 2022
work page 2022
-
[52]
Learning graph-based code representations for source-level functional similarity detection
Jiahao Liu, Jun Zeng, Xiang Wang, and Zhenkai Liang. Learning graph-based code representations for source-level functional similarity detection. In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE), pages 345–357. IEEE, 2023
work page 2023
-
[53]
Learning to represent programs with graphs
Miltiadis Allamanis, Marc Brockschmidt, and Mahmoud Khademi. Learning to represent programs with graphs. InInternational Conference on Learning Representations, 2018
work page 2018
-
[54]
Graphcodebert: Pre-training code representations with data flow, 2021
Daya Guo, Shuo Ren, Shuai Lu, Zhangyin Feng, Duyu Tang, Shujie Liu, Long Zhou, Nan Duan, Alexey Svyatkovskiy, Shengyu Fu, Michele Tufano, Shao Kun Deng, Colin Clement, Dawn Drain, Neel Sundaresan, Jian Yin, Daxin Jiang, and Ming Zhou. Graphcodebert: Pre-training code representations with data flow, 2021
work page 2021
-
[55]
Contrastive code representation learning
Paras Jain, Ajay Jain, Tianjun Zhang, Pieter Abbeel, Joseph Gonzalez, and Ion Stoica. Contrastive code representation learning. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2021
work page 2021
-
[56]
Yaqin Zhou, Shangqing Liu, Jingkai Siow, Xiaoning Du, and Yang Liu. Devign: Effective vulnerability identifi- cation by learning comprehensive program semantics via graph neural networks. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alch´e-Buc, E. Fox, and R. Garnett, editors,Advances in Neural Information Processing Systems, volume 32. Curran Assoc...
work page 2019
-
[57]
David Hin, Andrey Kan, Huaming Chen, and M. Ali Babar. Linevd: statement-level vulnerability detection using graph neural networks. InProceedings of the 19th International Conference on Mining Software Repositories, MSR ’22, page 596–607, New York, NY , USA, 2022. Association for Computing Machinery
work page 2022
-
[58]
A novel neural source code representation based on abstract syntax tree
Jian Zhang, Xu Wang, Hongyu Zhang, Hailong Sun, Kaixuan Wang, and Xudong Liu. A novel neural source code representation based on abstract syntax tree. InProceedings of the 41st International Conference on Software Engineering, ICSE ’19, page 783–794. IEEE Press, 2019
work page 2019
-
[59]
Cclearner: A deep learning-based clone detection approach
Liuqing Li, He Feng, Wenjie Zhuang, Na Meng, and Barbara Ryder. Cclearner: A deep learning-based clone detection approach. In2017 IEEE international conference on software maintenance and evolution (ICSME), pages 249–260. IEEE, 2017
work page 2017
-
[60]
Automated vulnerability detection in source code using deep representation learning
Rebecca Russell, Louis Kim, Lei Hamilton, Tomo Lazovich, Jacob Harer, Onur Ozdemir, Paul Ellingwood, and Marc McConley. Automated vulnerability detection in source code using deep representation learning. In2018 17th IEEE international conference on machine learning and applications (ICMLA), pages 757–762. IEEE, 2018
work page 2018
-
[61]
Md Nakhla Rafi, Dong Jae Kim, An Ran Chen, Tse-Hsun (Peter) Chen, and Shaowei Wang. Towards better graph neural network-based fault localization through enhanced code representation.Proc. ACM Softw. Eng., 1(FSE), July 2024
work page 2024
-
[62]
Codebert: A pre-trained model for programming and natural languages, 2020
Zhangyin Feng, Daya Guo, Duyu Tang, Nan Duan, Xiaocheng Feng, Ming Gong, Linjun Shou, Bing Qin, Ting Liu, Daxin Jiang, and Ming Zhou. Codebert: A pre-trained model for programming and natural languages, 2020
work page 2020
-
[63]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
work page 2021
-
[64]
Dobf: a deobfuscation pre- training objective for programming languages
Marie-Anne Lachaux, Baptiste Roziere, Marc Szafraniec, and Guillaume Lample. Dobf: a deobfuscation pre- training objective for programming languages. InProceedings of the 35th International Conference on Neural Information Processing Systems, NIPS ’21, Red Hook, NY , USA, 2021. Curran Associates Inc
work page 2021
-
[65]
Dobf: A deobfuscation pre-training objective for programming languages, 2021
Baptiste Roziere, Marie-Anne Lachaux, Marc Szafraniec, and Guillaume Lample. Dobf: A deobfuscation pre-training objective for programming languages, 2021
work page 2021
-
[66]
Codegen: An open large language model for code with multi-turn program synthesis, 2023
Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, and Caiming Xiong. Codegen: An open large language model for code with multi-turn program synthesis, 2023. 15
work page 2023
-
[67]
Yue Wang, Weishi Wang, Shafiq Joty, and Steven C.H. Hoi. CodeT5: Identifier-aware unified pre-trained encoder- decoder models for code understanding and generation. In Marie-Francine Moens, Xuanjing Huang, Lucia Specia, and Scott Wen-tau Yih, editors,Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 8696–8708, O...
work page 2021
-
[68]
Predicting unstable software benchmarks using static source code features.Empirical Softw
Christoph Laaber, Mikael Basmaci, and Pasquale Salza. Predicting unstable software benchmarks using static source code features.Empirical Softw. Engg., 26(6), November 2021
work page 2021
-
[69]
Deepperf: performance prediction for configurable software with deep sparse neural network
Huong Ha and Hongyu Zhang. Deepperf: performance prediction for configurable software with deep sparse neural network. InProceedings of the 41st International Conference on Software Engineering, ICSE ’19, page 1095–1106. IEEE Press, 2019
work page 2019
-
[70]
Batch mode deep active learning for regression on graph data
Peter Samoaa, Linus Aronsson, Philipp Leitner, and Morteza Haghir Chehreghani. Batch mode deep active learning for regression on graph data. In2023 IEEE International Conference on Big Data (BigData), pages 5904–5913, 2023
work page 2023
-
[71]
Patrick Thomson. Static analysis: An introduction: The fundamental challenge of software engineering is one of complexity.Queue, 19(4):29–41, September 2021
work page 2021
-
[72]
Vuldeepecker: A deep learning-based system for vulnerability detection
Zhen Li, Deqing Zou, Shouhuai Xu, Xinyu Ou, Hai Jin, Sujuan Wang, Zhijun Deng, and Yuyi Zhong. Vuldeepecker: A deep learning-based system for vulnerability detection. InProceedings 2018 Network and Distributed System Security Symposium, NDSS 2018. Internet Society, 2018
work page 2018
-
[73]
Dfept: Data flow embedding for enhancing pre-trained model based vulnerability detection
Zhonghao Jiang, Weifeng Sun, Xiaoyan Gu, Jiaxin Wu, Tao Wen, Haibo Hu, and Meng Yan. Dfept: Data flow embedding for enhancing pre-trained model based vulnerability detection. InProceedings of the 15th Asia-Pacific Symposium on Internetware, Internetware ’24, page 95–104, New York, NY , USA, 2024. Association for Computing Machinery
work page 2024
-
[74]
Hellendoorn, Charles Sutton, Rishabh Singh, Petros Maniatis, and David Bieber
Vincent J. Hellendoorn, Charles Sutton, Rishabh Singh, Petros Maniatis, and David Bieber. Global relational models of source code. InInternational Conference on Learning Representations, 2020
work page 2020
-
[75]
Neural message passing for quantum chemistry
Justin Gilmer, Samuel S Schoenholz, Patrick F Riley, Oriol Vinyals, and George E Dahl. Neural message passing for quantum chemistry. InInternational conference on machine learning, pages 1263–1272. PMLR, 2017
work page 2017
-
[76]
Spectral Networks and Locally Connected Networks on Graphs
Joan Bruna, Wojciech Zaremba, Arthur Szlam, and Yann LeCun. Spectral networks and locally connected networks on graphs.arXiv preprint arXiv:1312.6203, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[77]
Structpool: Structured graph pooling via conditional random fields
Hao Yuan and Shuiwang Ji. Structpool: Structured graph pooling via conditional random fields. InProceedings of the 8th International Conference on Learning Representations, 2020
work page 2020
-
[78]
Amir Hosein Khasahmadi, Kaveh Hassani, Parsa Moradi, Leo Lee, and Quaid Morris. Memory-based graph networks. InInternational Conference on Learning Representations, 2020
work page 2020
-
[79]
Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. How powerful are graph neural networks? In International Conference on Learning Representations, 2019
work page 2019
-
[80]
Micha¨el Defferrard, Xavier Bresson, and Pierre Vandergheynst. Convolutional neural networks on graphs with fast localized spectral filtering.Advances in neural information processing systems, 29, 2016
work page 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.