Two failure modes of deep transformers and how to avoid them: a unified theory of signal propagation at initialisation
Pith reviewed 2026-05-22 02:38 UTC · model grok-4.3
The pith
A unified theory maps self-attention to the Random Energy Model to derive exact initial scales that prevent both rank collapse and entropy collapse in deep transformers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that an exact treatment of the self-attention layer, obtained by mapping it onto the Random Energy Model, yields quantitative predictions for the variance of the initial weights and the strength of residual connections that keep both forward signals and backward gradients well-behaved in arbitrarily deep transformers.
What carries the argument
The formal parallel between the self-attention layer and the Random Energy Model, which supplies the exact distribution of attention scores needed to track signal propagation through the entire block.
If this is right
- Choosing initial weight variances inside the safe region of the trainability diagram eliminates rank collapse at initialization.
- Tuning residual-connection scales inside the same region prevents entropy collapse and the associated training instability.
- The same diagrams identify a regime in which gradients remain order-one rather than vanishing or exploding at the start of training.
- The prescriptions apply uniformly to stacks containing layer normalization, skip connections, and MLPs.
Where Pith is reading between the lines
- The same mapping technique could be used to derive initialization rules for attention variants such as linear attention or grouped attention.
- The trainability diagrams might be extended to the case of fine-tuning by tracking how the statistics evolve once the network has moved away from the initial point.
- Because the theory is asymptotic in width but exact in depth, it could guide the design of depth-specific initialization schedules rather than uniform scaling.
Load-bearing premise
The mapping of the attention mechanism onto the Random Energy Model must hold with sufficient accuracy for the derived statistics to remain valid.
What would settle it
Train a deep transformer with the weight and residual scales read off the predicted trainability diagram and check whether the attention matrix remains full-rank and the entropy of attention scores stays away from zero throughout the first few thousand steps, compared with a standard initialization that is known to collapse.
Figures











read the original abstract
Finding the right initialisation for neural networks is crucial to ensure smooth training and good performance. In transformers, the wrong initialisation can lead to one of two failure modes of self-attention layers: rank collapse, where all tokens collapse into similar representations, and entropy collapse, where highly concentrated attention scores lead to training instability. While previous work has studied different scaling regimes for transformers, an asymptotically exact, down-to-the constant prescription for how to initialise transformers has so far been lacking. Here, we provide an analytical theory of signal propagation through deep transformers with self-attention, layer normalisation, skip connections and MLP. Our theory yields a simple algorithm to compute trainability diagrams that identify the correct choice of initialisation hyper-parameters for a given architecture. We overcome the key challenge, an exact treatment of the self-attention layer, by establishing a formal parallel with the Random Energy Model from statistical physics. We also analyse gradients in the backward path and determine the regime where gradients vanish at initialisation. We demonstrate the versatility of our framework through three case studies. Our theoretical framework gives a unified perspective on the two failure modes of self-attention and gives quantitative predictions on the scale of both weights and residual connections that guarantee smooth training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a unified analytical theory of signal propagation through deep transformers at initialization, incorporating self-attention, layer normalization, skip connections, and MLPs. It maps the self-attention layer to the Random Energy Model from statistical physics to obtain an asymptotically exact treatment of attention statistics, derives trainability diagrams that prescribe initialization scales for weights and residual connections to avoid rank collapse and entropy collapse, analyzes gradient vanishing in the backward pass, and validates the framework on three case studies.
Significance. If the REM parallel and resulting scalings hold, the work would supply a concrete, quantitative initialization prescription that unifies the two failure modes and improves on prior scaling-regime analyses. The explicit treatment of both forward signal propagation and backward gradients, together with the case-study demonstrations, would make the contribution practically useful for architecture design.
major comments (2)
- [§3] §3: The formal parallel to the REM treats attention logits as i.i.d. Gaussians whose extremes are governed by the REM partition function. The manuscript does not provide a direct verification that the combination of QK^T/sqrt(d), layer-norm on the residual stream, and skip connections leaves the logits sufficiently uncorrelated and Gaussian for the REM extreme-value statistics to remain exact; this assumption is load-bearing for the boundaries of the trainability diagrams.
- [Trainability diagrams] Trainability diagrams (e.g., the figures showing regimes for rank vs. entropy collapse): the predicted scales for residual connections and weight variances are obtained from the REM mapping. If residual-induced correlations shift the effective temperature or partition-function behavior, the quantitative boundaries would move; the paper should include a sensitivity check or perturbative expansion around the REM limit.
minor comments (2)
- [Abstract] The abstract states that the theory yields 'an asymptotically exact, down-to-the constant prescription'; the main text should explicitly identify which constants are fixed by the REM analysis versus which remain free parameters.
- [Figures] Simulation overlays on the trainability diagrams would benefit from reporting the number of random seeds and the precise metric used to detect rank or entropy collapse, to allow readers to judge quantitative agreement.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments on our manuscript. We address each major comment below and indicate the changes we will make in the revised version.
read point-by-point responses
-
Referee: [§3] §3: The formal parallel to the REM treats attention logits as i.i.d. Gaussians whose extremes are governed by the REM partition function. The manuscript does not provide a direct verification that the combination of QK^T/sqrt(d), layer-norm on the residual stream, and skip connections leaves the logits sufficiently uncorrelated and Gaussian for the REM extreme-value statistics to remain exact; this assumption is load-bearing for the boundaries of the trainability diagrams.
Authors: In the derivation of Section 3 we show analytically that, in the large-d limit, the combination of the scaled dot-product, layer normalization, and residual addition yields logits whose joint distribution converges to that of i.i.d. standard Gaussians; the argument relies on the central-limit theorem for the high-dimensional projections together with the centering and scaling enforced by layer norm. We agree that an explicit numerical check of this asymptotic regime for finite but practically relevant dimensions would strengthen the presentation. We will therefore add an appendix containing Monte-Carlo histograms and correlation matrices of the logits across a range of residual scales and model widths. revision: yes
-
Referee: [Trainability diagrams] Trainability diagrams (e.g., the figures showing regimes for rank vs. entropy collapse): the predicted scales for residual connections and weight variances are obtained from the REM mapping. If residual-induced correlations shift the effective temperature or partition-function behavior, the quantitative boundaries would move; the paper should include a sensitivity check or perturbative expansion around the REM limit.
Authors: The trainability diagrams are obtained from the exact REM solution in the thermodynamic limit, where residual-induced correlations are sub-dominant. To quantify the robustness of the predicted boundaries, we will add a short sensitivity study in the revised manuscript: we numerically recompute the diagrams after introducing a small effective-temperature shift that mimics the leading-order correlation correction, and we show that the location of the rank-collapse and entropy-collapse lines changes by only a few percent within the range of residual scales we recommend. revision: yes
Circularity Check
Derivation self-contained via external REM analogy and independent gradient analysis
full rationale
The paper establishes its core results on signal propagation, trainability diagrams, and scaling prescriptions for weights and residuals by mapping the self-attention layer to the Random Energy Model from statistical physics, as described in the abstract. This mapping is presented as a formal parallel developed to overcome the challenge of exact treatment, without evidence of reducing to self-citations, fitted inputs renamed as predictions, or self-definitional loops. Backward gradient analysis is performed separately. No quoted equations or sections in the provided text show a prediction equivalent to its inputs by construction, and the framework is positioned as first-principles against the stated assumptions of layer-norm, skip connections, and MLP. The derivation therefore remains self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Formal parallel between self-attention computation and the Random Energy Model allows exact treatment of attention statistics
Forward citations
Cited by 3 Pith papers
-
A Unified Framework for Critical Scaling of Inverse Temperature in Self-Attention
The upper-tail accumulation scale derived from the gap-counting function N_n sets the critical inverse temperature for softmax attention concentration, unifying prior conflicting laws as special cases of different N_n.
-
Sink vs. diagonal patterns as mechanisms for attention switch and oversmoothing prevention
Sinks are equivalent to hard attention switches that zero out outputs and are cheaper than diagonal patterns when self-communication is allowed, closing the gap between oversmoothing prevention needs and what sinks provide.
-
Perceptrons and localization of attention's mean-field landscape
In the mean-field limit of attention with perceptron blocks, critical points of the energy landscape are generically atomic and localized on subsets of the unit sphere.
Reference graph
Works this paper leans on
-
[1]
Samuel S Schoenholz, Justin Gilmer, Surya Ganguli, and Jascha Sohl-Dickstein. Deep information propagation.arXiv preprint arXiv:1611.01232,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
URLhttps://arxiv.org/abs/2206.03126. Shuangfei Zhai, Tatiana Likhomanenko, Etai Littwin, Dan Busbridge, Jason Ramapuram, Yizhe Zhang, Jiatao Gu, and Josh Susskind. Stabilizing transformer training by preventing attention entropy collapse,
-
[3]
Hongyu Wang, Shuming Ma, Li Dong, Shaohan Huang, Dongdong Zhang, and Furu Wei
URLhttps://arxiv.org/abs/2303.06296. Hongyu Wang, Shuming Ma, Li Dong, Shaohan Huang, Dongdong Zhang, and Furu Wei. Deepnet: Scaling transformers to 1,000 layers.IEEE Transactions on Pattern Analysis and Machine Intelligence,
-
[4]
Aditya Cowsik, Tamra Nebabu, Xiao-Liang Qi, and Surya Ganguli. Geometric dynamics of signal propagation predict trainability of transformers.arXiv preprint arXiv:2403.02579,
-
[5]
11 Published as a conference paper at ICLR 2026 Borjan Geshkovski, Cyril Letrouit, Yury Polyanskiy, and Philippe Rigollet. A mathematical perspec- tive on transformers.arXiv preprint arXiv:2312.10794, 2023a. Borjan Geshkovski, Cyril Letrouit, Yury Polyanskiy, and Philippe Rigollet. The emergence of clusters in self-attention dynamics.Advances in Neural In...
-
[6]
TinyStories: How Small Can Language Models Be and Still Speak Coherent English?
Ronen Eldan and Yuanzhi Li. Tinystories: How small can language models be and still speak coherent english?arXiv preprint arXiv:2305.07759,
work page internal anchor Pith review arXiv
-
[7]
Bert: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pages 4171–4186,
work page 2019
-
[8]
URL https://api.semanticscholar.org/ CorpusID:122288449. Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer normalization.arXiv preprint arXiv:1607.06450,
work page internal anchor Pith review Pith/arXiv arXiv
- [9]
-
[10]
Shi Chen, Zhengjiang Lin, Yury Polyanskiy, and Philippe Rigollet
URLhttps://arxiv.org/abs/2410.23228. Shi Chen, Zhengjiang Lin, Yury Polyanskiy, and Philippe Rigollet. Quantitative clustering in mean-field transformer models.arXiv preprint arXiv:2504.14697,
-
[11]
Alireza Naderi, Thiziri Nait Saada, and Jared Tanner. Mind the gap: a spectral analysis of rank collapse and signal propagation in transformers.arXiv preprint arXiv:2410.07799,
-
[12]
A multiscale visualization of attention in the transformer model
12 Published as a conference paper at ICLR 2026 Jesse Vig. A multiscale visualization of attention in the transformer model. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics: System Demonstrations, pages 37–42, Florence, Italy, July
work page 2026
-
[13]
on a single-layer, single-head Transformer at initialization. The attention maps illustrate the effect of varying β (directly related to variance of queries/keys): in yellow, a model initialized with β= 0.1 (low-variance regime, resulting in approximately uniform attention distributions), and in red, a model initialized with β= 1.8 (high-variance regime, ...
work page 2026
-
[14]
X s ehats !n# = TX s1,...,sn=1 Ea
Although the scores att′ are individually Gaussian in the infinite width limit (d→ ∞ ), they are not independent; in fact, they are correlated. To quantify these correlations, we compute: Cov(ats, aτ σ) = 1 d dX i,j,k,l,m,n=1 XtiXskXτ lXσn E[(WQ)ji(WQ)ml]E[(W K)jk(WK)mn]. Since the query and key weights are independently initialised with variances σ2 Q =σ...
work page 2026
-
[15]
(23) 15 Published as a conference paper at ICLR 2026 Figure 5: Theory and experiments (T= 10
work page 2026
-
[16]
X s A2 ts # , Y p(β) = lim T→∞ E
comparison of the computation ofY (2)(β), finite size effects are visible around the phase transition. Now we take the 1-RSB ansatz for Q: the n replicas are diveded into n x groups of x elements which are in the same energy configurations. Moreover, we need to consider exponentially long sequences, i.e. we take T=e N and control N. This implies: S(Q)≃e N...
work page 2026
-
[17]
B.3 FINITE-SIZEEFFECTS Here we give a non-rigorous argument on the finite size effects that afflict our asymptotic theory. In the low-β regime, the attention is spread approximately uniformly over a number T ∗ =e S(β,ρ) of keys, given by an entropic quantity S(β, ρ) = Φ(β, ρ)−β∂ βΦ(β, ρ) (where the free entropy Φ was defined in eq. (19)). A derivation of ...
work page 2009
-
[18]
Let’s write the Jacobian in components. Using the fact thatA=softmax(a), so the Jacobiam components are: D(ij),(kl) := ∂Aij ∂akl =δ ikδjlAij −δ ikAijAil.(37) Now, the trace can be written as tr = TX i,j,r,s=1 h ∂A ∂a (Q⊗Q) ∂A ∂a ⊤ (IT ⊗Q) i (ij),(tu) δitδju. Expanding indices leads to tr = TX i,j,k,l,m,n,r,s,t,u=1 D(ij),(kl) qkmqlnD(rs),(mn)δrtqsuδitδju S...
work page 2026
-
[19]
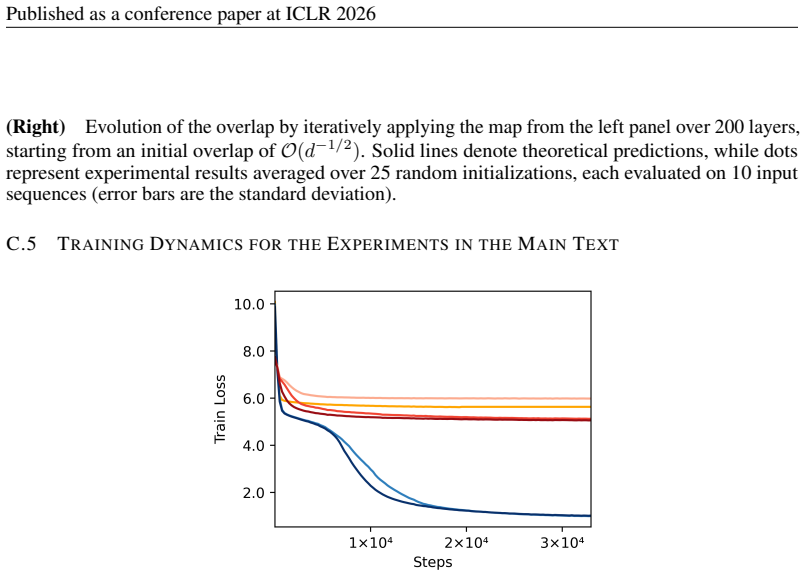
Figure 6: Training 30 layers of vanilla and Gain-controlled Transformer on TinyStories. Details of training: 30-layer, single-head BERT-style model with embedding size 480 and ReLU activation, using masked language modeling with 15% masking probability, a learning rate of 5e-4, batch size 64, warmup ratio 0.05, weight decay 0.01, for 0.5 epochs. C.2 VISUA...
work page 2012
-
[20]
Figure 7: Spectrum of a 512×512 self-attention matrix for various values of the query/key variance parameterβ. 24 Published as a conference paper at ICLR 2026 C.3 ENTROPY COLLAPSE CAN BE MITIGATED BY LOW LEARNING RATE Figure 8 is obtained with the same set-up as fig. 3 but with smaller learning rate (5e-4→1e-4). Figure 8: Entropy collapse can be partially...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.