Reading Recognition in the Wild
Pith reviewed 2026-05-19 12:30 UTC · model grok-4.3
The pith
A flexible transformer recognizes reading from egocentric RGB, gaze and head pose on a new 100-hour dataset.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce the first-of-its-kind large-scale multimodal Reading in the Wild dataset, containing 100 hours of reading and non-reading videos in diverse and realistic scenarios. We identify three modalities (egocentric RGB, eye gaze, head pose) that can be used to solve the task of reading recognition, and present a flexible transformer model that performs the task using these modalities, either individually or combined. We show that these modalities are relevant and complementary to the task, and investigate how to efficiently and effectively encode each modality. Additionally, we show the usefulness of this dataset towards classifying types of reading, extending current reading studies to
What carries the argument
Flexible transformer model that encodes and fuses egocentric RGB, eye gaze and head pose to classify reading versus non-reading
If this is right
- The three modalities can be used individually or in any combination to perform reading recognition.
- Each modality admits efficient and effective encoding within the transformer.
- The dataset supports classification of reading types beyond the constraints of prior lab studies.
- Contextual AI systems can maintain records of user reading interactions in everyday settings.
Where Pith is reading between the lines
- Smart glasses equipped with this model could automatically offer reading assistance or generate summaries without explicit user commands.
- The same signals might be combined with other egocentric tasks such as object detection to build richer activity timelines.
- Performance on entirely new user groups or reading materials not present in the 100-hour collection would indicate the degree of true generalization.
Load-bearing premise
The 100 hours of reading and non-reading videos collected in diverse and realistic scenarios are representative enough to train and evaluate models that generalize to real-world reading recognition.
What would settle it
Testing the trained model on a new collection of videos recorded by different users in previously unseen environments and measuring whether accuracy remains comparable to results on the original dataset.
Figures












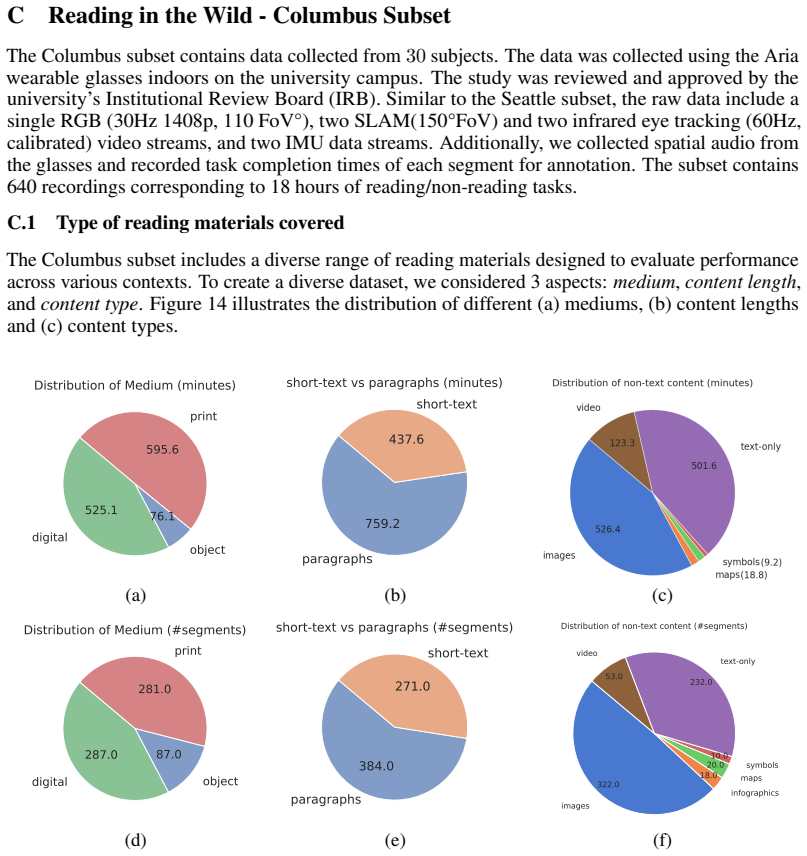




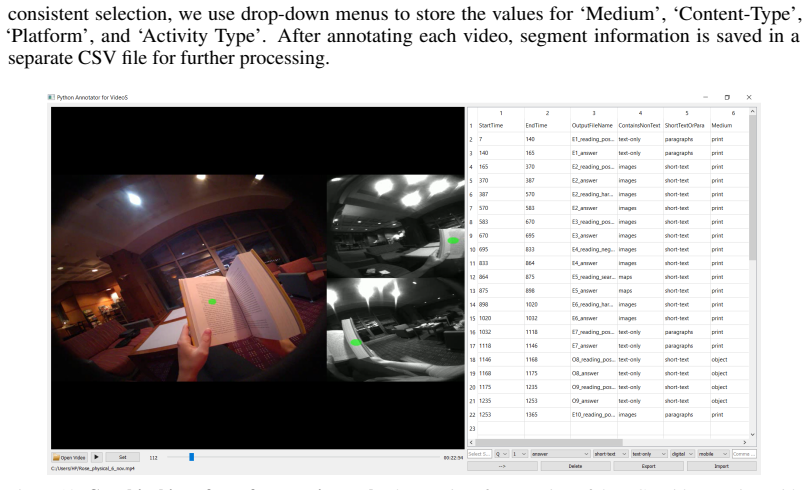













read the original abstract
To enable egocentric contextual AI in always-on smart glasses, it is crucial to be able to keep a record of the user's interactions with the world, including during reading. In this paper, we introduce a new task of reading recognition to determine when the user is reading. We first introduce the first-of-its-kind large-scale multimodal Reading in the Wild dataset, containing 100 hours of reading and non-reading videos in diverse and realistic scenarios. We then identify three modalities (egocentric RGB, eye gaze, head pose) that can be used to solve the task, and present a flexible transformer model that performs the task using these modalities, either individually or combined. We show that these modalities are relevant and complementary to the task, and investigate how to efficiently and effectively encode each modality. Additionally, we show the usefulness of this dataset towards classifying types of reading, extending current reading understanding studies conducted in constrained settings to larger scale, diversity and realism.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the task of reading recognition in egocentric videos for always-on smart glasses, presents the Reading in the Wild dataset comprising 100 hours of multimodal reading and non-reading videos collected in diverse realistic scenarios, identifies three modalities (egocentric RGB, eye gaze, and head pose), proposes a flexible transformer model that processes these modalities individually or in combination, claims to demonstrate that the modalities are relevant and complementary, investigates efficient encoding strategies for each, and shows the dataset's utility for classifying types of reading at larger scale and realism than prior constrained studies.
Significance. If the unreported experiments confirm modality complementarity and dataset utility with appropriate ablations and generalization tests, the work could provide a valuable large-scale benchmark for multimodal egocentric vision and advance contextual AI applications in wearable devices by extending reading understanding beyond lab settings.
major comments (2)
- [Abstract] Abstract: The claim that 'these modalities are relevant and complementary to the task' is load-bearing for the central contribution yet is asserted without any quantitative results, ablation studies, fusion performance deltas, error analysis, or evaluation metrics, making it impossible to verify whether the data supports the assertion.
- [Abstract] Abstract: The load-bearing assumption that the 100 hours of videos 'in diverse and realistic scenarios' are representative enough to train and evaluate models that generalize is stated without details on collection protocol, annotation process, diversity quantification, or train/test splits, preventing assessment of potential biases or leakage.
minor comments (1)
- [Abstract] Abstract: The description of the transformer as 'flexible' and the investigation of 'how to efficiently and effectively encode each modality' would benefit from at least high-level architectural or encoding details even in the abstract.
Simulated Author's Rebuttal
We thank the referee for their detailed review and constructive feedback on our manuscript. We address each of the major comments point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'these modalities are relevant and complementary to the task' is load-bearing for the central contribution yet is asserted without any quantitative results, ablation studies, fusion performance deltas, error analysis, or evaluation metrics, making it impossible to verify whether the data supports the assertion.
Authors: We agree that the abstract, being a concise summary, does not include specific quantitative evidence. The full manuscript contains sections with ablation studies, performance comparisons for individual and combined modalities, and metrics that support the relevance and complementarity of egocentric RGB, eye gaze, and head pose. To improve clarity, we will revise the abstract to include a brief statement referencing these experimental findings. revision: yes
-
Referee: [Abstract] Abstract: The load-bearing assumption that the 100 hours of videos 'in diverse and realistic scenarios' are representative enough to train and evaluate models that generalize is stated without details on collection protocol, annotation process, diversity quantification, or train/test splits, preventing assessment of potential biases or leakage.
Authors: The abstract summarizes the key aspects of the dataset. Detailed information on the collection protocol, annotation process, measures of diversity, and the train/test splits (designed to prevent data leakage) is provided in the main body of the paper. We acknowledge that incorporating a short reference to these elements in the abstract would help address concerns about generalization and potential biases. We will make this revision. revision: yes
Circularity Check
No circularity: new dataset and empirical claims with no derivation chain present
full rationale
Only the abstract is available, which introduces a new task, a 100-hour multimodal dataset, and a flexible transformer using RGB, gaze, and pose modalities. No equations, fitted parameters, self-citations, or derivations appear that could reduce a claimed result to its own inputs by construction. The contribution is framed as data collection plus empirical model application, which is self-contained against external benchmarks and contains none of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose a flexible multimodal transformer model that takes in different modalities as input... three layers of 1D (gaze and IMU) and 2D (RGB) convolutions... modality dropout... 137k parameters.
-
IndisputableMonolith/Foundation/DimensionForcing.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We identify three modalities (egocentric RGB, eye gaze, head pose) that can be used to solve the task... investigate how to efficiently and effectively encode each modality.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Towards predicting reading comprehension from gaze behavior
Seoyoung Ahn, Conor Kelton, Aruna Balasubramanian, and Greg Zelinsky. Towards predicting reading comprehension from gaze behavior. InETRA, 2020
work page 2020
-
[2]
Whisperx: Time-accurate speech transcrip- tion of long-form audio.INTERSPEECH, 2023
Max Bain, Jaesung Huh, Tengda Han, and Andrew Zisserman. Whisperx: Time-accurate speech transcrip- tion of long-form audio.INTERSPEECH, 2023
work page 2023
-
[3]
A robust realtime reading-skimming classifier
Ralf Biedert, Jörn Hees, Andreas Dengel, and Georg Buscher. A robust realtime reading-skimming classifier. InETRA, 2012
work page 2012
-
[4]
Robust recognition of reading activ- ity in transit using wearable electrooculography
Andreas Bulling, Jamie A Ward, Hans Gellersen, and Gerhard Tröster. Robust recognition of reading activ- ity in transit using wearable electrooculography. InPervasive Computing: 6th International Conference, Pervasive 2008 Sydney, Australia, May 19-22, 2008 Proceedings 6, pages 19–37. Springer, 2008
work page 2008
-
[5]
Simona Caldani, Christophe-Loïc Gerard, Hugo Peyre, and Maria Pia Bucci. Visual attentional training improves reading capabilities in children with dyslexia: An eye tracker study during a reading task.Brain sciences, 10(8), 2020
work page 2020
-
[6]
A robust algorithm for reading detection
Christopher S Campbell and Paul P Maglio. A robust algorithm for reading detection. InPUI, 2001
work page 2001
-
[7]
Quo vadis, action recognition? a new model and the kinetics dataset
Joao Carreira and Andrew Zisserman. Quo vadis, action recognition? a new model and the kinetics dataset. Inproceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6299–6308, 2017
work page 2017
-
[8]
Diana Castilla, Omar Del Tejo Catalá, Patricia Pons, François Signol, Beatriz Rey, Carlos Suso-Ribera, and Juan-Carlos Perez-Cortes. Improving the understanding of web user behaviors through machine learning analysis of eye-tracking data.User Modeling and User-Adapted Interaction, 34(2), 2024
work page 2024
-
[9]
Gazexplain: Learning to predict natural language explanations of visual scanpaths
Xianyu Chen, Ming Jiang, and Qi Zhao. Gazexplain: Learning to predict natural language explanations of visual scanpaths. InECCV, 2024
work page 2024
-
[10]
Leana Copeland, Tom Gedeon, and B Sumudu U Mendis. Predicting reading comprehension scores from eye movements using artificial neural networks and fuzzy output error.Artif. Intell. Res., 3(3), 2014
work page 2014
-
[11]
Scaling egocentric vision: The epic-kitchens dataset
Dima Damen, Hazel Doughty, Giovanni Maria Farinella, Sanja Fidler, Antonino Furnari, Evangelos Kazakos, Davide Moltisanti, Jonathan Munro, Toby Perrett, Will Price, and Michael Wray. Scaling egocentric vision: The epic-kitchens dataset. InECCV, 2018
work page 2018
-
[12]
Project Aria: A New Tool for Egocentric Multi-Modal AI Research
Jakob Engel, Kiran Somasundaram, Michael Goesele, Albert Sun, Alexander Gamino, Andrew Turner, Arjang Talattof, Arnie Yuan, Bilal Souti, Brighid Meredith, Cheng Peng, Chris Sweeney, Cole Wilson, Dan Barnes, Daniel DeTone, David Caruso, Derek Valleroy, Dinesh Ginjupalli, Duncan Frost, Edward Miller, Elias Mueggler, Evgeniy Oleinik, Fan Zhang, Guruprasad So...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Oat: Object-level attention transformer for gaze scanpath prediction
Yini Fang, Jingling Yu, Haozheng Zhang, Ralf van der Lans, and Bertram Shi. Oat: Object-level attention transformer for gaze scanpath prediction. InECCV, 2024
work page 2024
-
[14]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al- Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024. 11
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Gird- har, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, Miguel Martin, Tushar Nagarajan, Ilija Radosavovic, Santhosh Kumar Ramakrishnan, Fiona Ryan, Jayant Sharma, Michael Wray, Mengmeng Xu, Eric Zhongcong Xu, Chen Zhao, Siddhant Bansal, Dhruv Batra, Vincent Car...
work page 2022
-
[16]
Ego-exo4d: Understanding skilled human activity from first-and third-person perspectives
Kristen Grauman, Andrew Westbury, Lorenzo Torresani, Kris Kitani, Jitendra Malik, Triantafyllos Afouras, Kumar Ashutosh, Vijay Baiyya, Siddhant Bansal, Bikram Boote, et al. Ego-exo4d: Understanding skilled human activity from first-and third-person perspectives. InCVPR, 2024
work page 2024
-
[17]
Nora Hollenstein, Jonathan Rotsztejn, Marius Troendle, Andreas Pedroni, Ce Zhang, and Nicolas Langer. Zuco, a simultaneous eeg and eye-tracking resource for natural sentence reading.Scientific data, 5(1), 2018
work page 2018
-
[18]
Md Farhadul Islam, Meem Arafat Manab, Joyanta Jyoti Mondal, Sarah Zabeen, Fardin Bin Rahman, Md Zahidul Hasan, Farig Sadeque, and Jannatun Noor. Involution fused convnet for classifying eye- tracking patterns of children with autism spectrum disorder.Engineering Applications of Artificial Intelligence, 2025
work page 2025
-
[19]
Icdar 2024 competition on reading documents through aria glasses
Soumya Shamarao Jahagirdar, Ajoy Mondal, Yuheng Ren, Omkar M Parkhi, and CV Jawahar. Icdar 2024 competition on reading documents through aria glasses. InICDAR, 2024
work page 2024
-
[20]
Boosting gaze object prediction via pixel-level supervision from vision foundation model
Yang Jin, Lei Zhang, Shi Yan, Bin Fan, and Binglu Wang. Boosting gaze object prediction via pixel-level supervision from vision foundation model. InECCV, 2024
work page 2024
-
[21]
A theory of reading: from eye fixations to comprehension
Marcel A Just and Patricia A Carpenter. A theory of reading: from eye fixations to comprehension. Psychological review, 87(4), 1980
work page 1980
-
[22]
Epic-fusion: Audio-visual temporal binding for egocentric action recognition
Evangelos Kazakos, Arsha Nagrani, Andrew Zisserman, and Dima Damen. Epic-fusion: Audio-visual temporal binding for egocentric action recognition. InICCV, 2019
work page 2019
-
[23]
Reading detection in real-time
Conor Kelton, Zijun Wei, Seoyoung Ahn, Aruna Balasubramanian, Samir R Das, Dimitris Samaras, and Gregory Zelinsky. Reading detection in real-time. InETRA, 2019
work page 2019
-
[24]
Yunsoo Kim, Jinge Wu, Yusuf Abdulle, Yue Gao, and Honghan Wu. Enhancing human-computer interaction in chest x-ray analysis using vision and language model with eye gaze patterns. InMICCAI, 2024
work page 2024
-
[25]
Gaze-detr: Using expert gaze to reduce false positives in vulvovaginal candidiasis screening
Yan Kong, Sheng Wang, Jiangdong Cai, Zihao Zhao, Zhenrong Shen, Yonghao Li, Manman Fei, and Qian Wang. Gaze-detr: Using expert gaze to reduce false positives in vulvovaginal candidiasis screening. In MICCAI, 2024
work page 2024
-
[26]
Robert Konrad, Nitish Padmanaban, J Gabriel Buckmaster, Kevin C Boyle, and Gordon Wetzstein. Gazegpt: Augmenting human capabilities using gaze-contingent contextual ai for smart eyewear.arXiv preprint arXiv:2401.17217, 2024
-
[27]
I know what you are reading: recognition of document types using mobile eye tracking
Kai Kunze, Yuzuko Utsumi, Yuki Shiga, Koichi Kise, and Andreas Bulling. I know what you are reading: recognition of document types using mobile eye tracking. InISWC, 2013
work page 2013
-
[28]
Classification of reading and not reading behavior based on eye movement analysis
Manuel Landsmann, Olivier Augereau, and Koichi Kise. Classification of reading and not reading behavior based on eye movement analysis. InISWC, 2019
work page 2019
-
[29]
In the eye of beholder: Joint learning of gaze and actions in first person video
Yin Li, Miao Liu, and James M Rehg. In the eye of beholder: Joint learning of gaze and actions in first person video. InECCV, 2018
work page 2018
-
[30]
Classification of reading patterns based on gaze information
Wen-Hung Liao, Chin-Wen Chang, and Yi-Chieh Wu. Classification of reading patterns based on gaze information. In2017 IEEE International Symposium on Multimedia (ISM). IEEE, 2017. 12
work page 2017
-
[31]
Zhi-Yi Lin, Jouh Yeong Chew, Jan van Gemert, and Xucong Zhang. Gazehta: End-to-end gaze target detection with head-target association.arXiv preprint arXiv:2404.10718, 2024
-
[32]
Gem: Context-aware gaze estimation with visual search behavior matching for chest radiograph
Shaonan Liu, Wenting Chen, Jie Liu, Xiaoling Luo, and Linlin Shen. Gem: Context-aware gaze estimation with visual search behavior matching for chest radiograph. InMICCAI, 2024
work page 2024
-
[33]
Using eye-tracking measures to predict reading comprehension.Reading Research Quarterly, 58(3), 2023
Diane C Mézière, Lili Yu, Erik D Reichle, Titus V on Der Malsburg, and Genevieve McArthur. Using eye-tracking measures to predict reading comprehension.Reading Research Quarterly, 58(3), 2023
work page 2023
-
[34]
Integrating human gaze into attention for egocentric activity recognition
Kyle Min and Jason J Corso. Integrating human gaze into attention for egocentric activity recognition. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 1069–1078, 2021
work page 2021
-
[35]
Look hear: Gaze prediction for speech-directed human attention
Sounak Mondal, Seoyoung Ahn, Zhibo Yang, Niranjan Balasubramanian, Dimitris Samaras, Gregory Zelinsky, and Minh Hoai. Look hear: Gaze prediction for speech-directed human attention. InECCV, 2024
work page 2024
-
[36]
Thumb’s rule tested: Visual angle of thumb’s width is about 2 deg.Perception, 20, 1991
Robert O’Shea. Thumb’s rule tested: Visual angle of thumb’s width is about 2 deg.Perception, 20, 1991
work page 1991
-
[37]
A transformer-based model for the prediction of human gaze behavior on videos
Süleyman Özdel, Yao Rong, Berat Mert Albaba, Yen-Ling Kuo, Xi Wang, and Enkelejda Kasneci. A transformer-based model for the prediction of human gaze behavior on videos. InETRA, 2024
work page 2024
-
[38]
Egoblur: Responsible innovation in aria, 2023
Nikhil Raina, Guruprasad Somasundaram, Kang Zheng, Sagar Miglani, Steve Saarinen, Jeff Meissner, Mark Schwesinger, Luis Pesqueira, Ishita Prasad, Edward Miller, Prince Gupta, Mingfei Yan, Richard Newcombe, Carl Ren, and Omkar M Parkhi. Egoblur: Responsible innovation in aria, 2023
work page 2023
-
[39]
Karolina Rataj, Anna Przekoracka-Krawczyk, and Rob HJ Van der Lubbe. On understanding creative language: the late positive complex and novel metaphor comprehension.Brain research, 1678, 2018
work page 2018
-
[40]
Learning user embeddings from human gaze for personalised saliency prediction
Florian Strohm, Mihai Bâce, and Andreas Bulling. Learning user embeddings from human gaze for personalised saliency prediction. InETRA, 2024
work page 2024
-
[41]
Sara: Smart ai reading assistant for reading comprehension
Enkeleda Thaqi, Mohamed Omar Mantawy, and Enkelejda Kasneci. Sara: Smart ai reading assistant for reading comprehension. InETRA, 2024
work page 2024
-
[42]
Jie Tian, Lingxiao Yang, Ran Ji, Yuexin Ma, Lan Xu, Jingyi Yu, Ye Shi, and Jingya Wang. Gaze-guided hand-object interaction synthesis: Benchmark and method.arXiv preprint arXiv:2403.16169, 2024
-
[43]
Gazeprompt: Enhancing low vision people’s reading experience with gaze-aware augmentations
Ru Wang, Zach Potter, Yun Ho, Daniel Killough, Linxiu Zeng, Sanbrita Mondal, and Yuhang Zhao. Gazeprompt: Enhancing low vision people’s reading experience with gaze-aware augmentations. InCHI Conference on Human Factors in Computing Systems, 2024
work page 2024
-
[44]
Gaze-directed vision gnn for mitigating shortcut learning in medical image
Shaoxuan Wu, Xiao Zhang, Bin Wang, Zhuo Jin, Hansheng Li, and Jun Feng. Gaze-directed vision gnn for mitigating shortcut learning in medical image. InMICCAI, 2024
work page 2024
-
[45]
Fast and accurate text classification: Skimming, rereading and early stopping
Keyi Yu, Yang Liu, Alexander G Schwing, and Jian Peng. Fast and accurate text classification: Skimming, rereading and early stopping. InICLR, 2018
work page 2018
-
[46]
Interead: An eye tracking dataset of interrupted reading
Francesca Zermiani, Prajit Dhar, Ekta Sood, Fabian Kögel, Andreas Bulling, and Maria Wirzberger. Interead: An eye tracking dataset of interrupted reading. InLREC-COLING, 2024
work page 2024
-
[47]
Can gaze inform egocentric action recognition? InETRA, 2022
Zehua Zhang, David Crandall, Michael Proulx, Sachin Talathi, and Abhishek Sharma. Can gaze inform egocentric action recognition? InETRA, 2022
work page 2022
-
[48]
name": "13. Write or type texts - Read Out Loud 21
Yue Zhao, Ishan Misra, Philipp Krähenbühl, and Rohit Girdhar. Learning video representations from large language models. InCVPR, 2023. 13 Reading Recognition in the Wild —Supplementary Material— A Introduction Additional dataset details.Our dataset is the first instance of reading activity recognition dataset in unconstrained environments and is also the ...
work page 2023
-
[49]
Enabled modalities Gaze ✗ ✗✓ ✓ RGB ✓ ✓✗✓ IMU ✗ ✗ ✗✓ Fusion ✓✗ ✗✓
-
[50]
On-device Feasibility ✗ ✗✓ ✓ Number of parameters 11B 25M 1k 130k Sensing cost (power) high high low low RGB requirements full RGB full RGB video - foveated patch (5° FoV) (dominates sensing cost) (optional) Real-time ✗ ✗✓ ✓ Inference time (ms) 567.410 895.511 (incl. flow) 0.310 0.545
-
[51]
Performance Zero-shot capability ✓✗ ✗✓ Acc / F1 on RiTW Columbus 76.7 / 65.6 - -82.9 / 88.8 Acc / F1 on EGTEA dataset 89.6 / 61.5 88.8 / 65.8 85.8 / 62.889.6 / 70.6 Table 13:Comparison of alternative methods.This table compares approaches for reading recognition, including (i) vision-language models (VLMs), (ii) action recognition models, and (iii) altern...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.