TSGuard: Automated User-Centric Incident Diagnosis for AI Workloads in the Cloud
Pith reviewed 2026-05-19 11:52 UTC · model grok-4.3
The pith
TSGuard lets users diagnose AI workload incidents immediately using knowledge from past on-call records and multi-agent reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
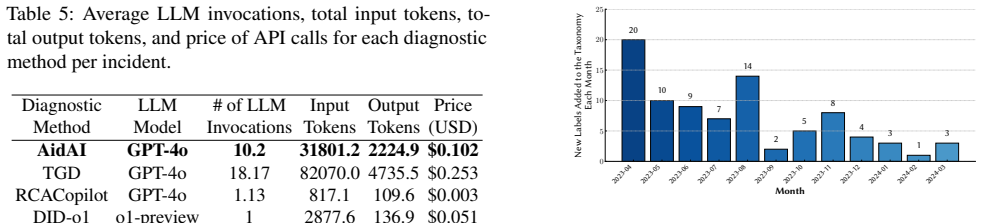
TSGuard constructs domain-specific knowledge bases by mining historical on-call experiences in the offline phase and mimics human expert diagnosis via structured reasoning and iterative trial-and-error in the online phase. When tested on production incident records from Microsoft Azure, it improves diagnostic accuracy by 19.8% over state-of-the-art baselines and reduces the average verification time by 63.4% compared to the sequential execution baseline.
What carries the argument
Offline construction of domain-specific knowledge bases from on-call experiences paired with online multi-agent structured reasoning and iterative trial-and-error to mimic expert diagnosis.
If this is right
- Users get immediate diagnoses for their AI workload incidents without relying on providers.
- Diagnostic accuracy improves by 19.8% compared to existing methods.
- Verification time is reduced by 63.4% relative to sequential execution.
- The approach supports generalizable diagnosis for various AI incidents using the structured knowledge.
Where Pith is reading between the lines
- This method could extend to diagnosing issues in other types of cloud applications by similar knowledge mining.
- Knowledge bases could be updated continuously with new incidents to maintain relevance over time.
- Adopting this user-centric model might encourage cloud providers to share more diagnostic tools with customers.
Load-bearing premise
Historical on-call experiences mined offline hold representative and sufficient domain knowledge that can be turned into knowledge bases for accurate diagnosis when combined with multi-agent structured reasoning online.
What would settle it
Testing the system on a fresh collection of production incidents not used in training or evaluation and measuring if the accuracy improvement and time reduction still hold.
Figures












read the original abstract
AI workloads incur frequent failures and incidents from the underlying infrastructure. The current incident management workflow follows a provider-centric paradigm, where users report incidents to the infrastructure provider who then conducts troubleshooting. Due to the large number of incidents and the manual nature of the troubleshooting process, the provider often takes several days to resolve an incident, resulting in operational delays and productivity loss. To address these challenges, we present TSGuard, a user-centric multi-agent system that delivers immediate incident diagnosis to users who deploy the workloads. The core innovation of TSGuard is twofold: (1) constructing domain-specific knowledge bases by mining historical on-call experiences in the offline phase, and (2) mimicking human expert diagnosis via structured reasoning and iterative trial-and-error in the online phase. Evaluation using production incident records from Microsoft Azure demonstrates that TSGuard significantly outperforms state-of-the-art baselines, improving diagnostic accuracy by 19.8%. Furthermore, TSGuard reduces the average verification time by 63.4% compared to the sequential execution baseline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TSGuard, a user-centric multi-agent system for automated incident diagnosis in AI cloud workloads. It constructs domain-specific knowledge bases offline by mining historical on-call experiences and performs online diagnosis via structured multi-agent reasoning with iterative trial-and-error. Evaluation on Microsoft Azure production incident records reports a 19.8% improvement in diagnostic accuracy over state-of-the-art baselines and a 63.4% reduction in average verification time versus sequential execution.
Significance. If the results hold under a rigorous evaluation protocol, the work has clear practical significance for shifting incident management toward users and reducing operational delays in AI deployments. The use of real production data from a major provider provides moderate empirical grounding for the claims. The combination of offline knowledge mining with online multi-agent reasoning is a substantive applied contribution in cloud systems and software engineering for operations.
major comments (2)
- [§4 (Evaluation)] §4 (Evaluation): The headline claims of 19.8% accuracy gain and 63.4% time reduction rest on the assumption that test incidents are disjoint from and temporally after the historical experiences mined for the knowledge bases. The manuscript must explicitly document the mining window, test-set selection criteria, and any temporal hold-out to rule out retrieval of near-identical past cases rather than genuine generalization.
- [§4 (Evaluation)] §4 (Evaluation): Baseline implementations, incident selection criteria, and statistical significance testing are insufficiently detailed. Without these, it is impossible to verify that the reported improvements are attributable to TSGuard's multi-agent reasoning rather than differences in knowledge access or experimental setup.
minor comments (2)
- [Abstract] Abstract and §1: Provide the exact names of the state-of-the-art baselines for immediate clarity.
- [§3 (System Design)] §3 (System Design): Clarify the precise interface between the knowledge bases and the iterative trial-and-error loop to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our evaluation protocol. We address each major comment below and will incorporate clarifications to strengthen the rigor of our claims regarding generalization and experimental reproducibility.
read point-by-point responses
-
Referee: [§4 (Evaluation)] §4 (Evaluation): The headline claims of 19.8% accuracy gain and 63.4% time reduction rest on the assumption that test incidents are disjoint from and temporally after the historical experiences mined for the knowledge bases. The manuscript must explicitly document the mining window, test-set selection criteria, and any temporal hold-out to rule out retrieval of near-identical past cases rather than genuine generalization.
Authors: We agree that explicit documentation of the temporal separation is essential to substantiate generalization. The current manuscript describes the use of production incident records but does not detail the exact windows. In the revision we will add a dedicated paragraph in §4.1 specifying: (1) the offline mining window (historical on-call experiences from January 2022 through December 2023), (2) test-set selection criteria (AI-workload incidents reported January–June 2024 with no overlap in incident IDs or near-duplicate symptom descriptions), and (3) a strict temporal hold-out ensuring every test incident post-dates the latest knowledge-base entry. This protocol prevents retrieval of near-identical past cases and will be accompanied by a small illustrative table of timeline splits. revision: yes
-
Referee: [§4 (Evaluation)] §4 (Evaluation): Baseline implementations, incident selection criteria, and statistical significance testing are insufficiently detailed. Without these, it is impossible to verify that the reported improvements are attributable to TSGuard's multi-agent reasoning rather than differences in knowledge access or experimental setup.
Authors: We acknowledge the need for greater transparency. The revision will expand §4.2 and §4.3 with: (a) complete baseline implementation details, including prompt templates, retrieval parameters, and any adaptations made to the original papers; (b) precise incident selection criteria (filtering rules for AI-specific failures, minimum log length, and exclusion of resolved-within-5-minutes cases); and (c) statistical significance testing (McNemar’s test for accuracy differences and paired t-test for verification time, with reported p-values and effect sizes). These additions will allow readers to confirm that gains stem from the structured multi-agent reasoning rather than setup artifacts. revision: yes
Circularity Check
No circularity; empirical system with external evaluation
full rationale
The paper presents an applied system that mines historical on-call experiences offline to build knowledge bases and applies multi-agent structured reasoning online for diagnosis. Central claims rest on empirical evaluation against state-of-the-art baselines using production incident records from Microsoft Azure, with reported accuracy and time improvements. No mathematical derivations, equations, fitted parameters renamed as predictions, or self-citation chains reduce any result to its inputs by construction. The evaluation uses external real-world records and is self-contained against independent benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Historical on-call experiences contain representative domain knowledge sufficient to construct knowledge bases that generalize to new incidents.
invented entities (1)
-
TSGuard multi-agent diagnosis system
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
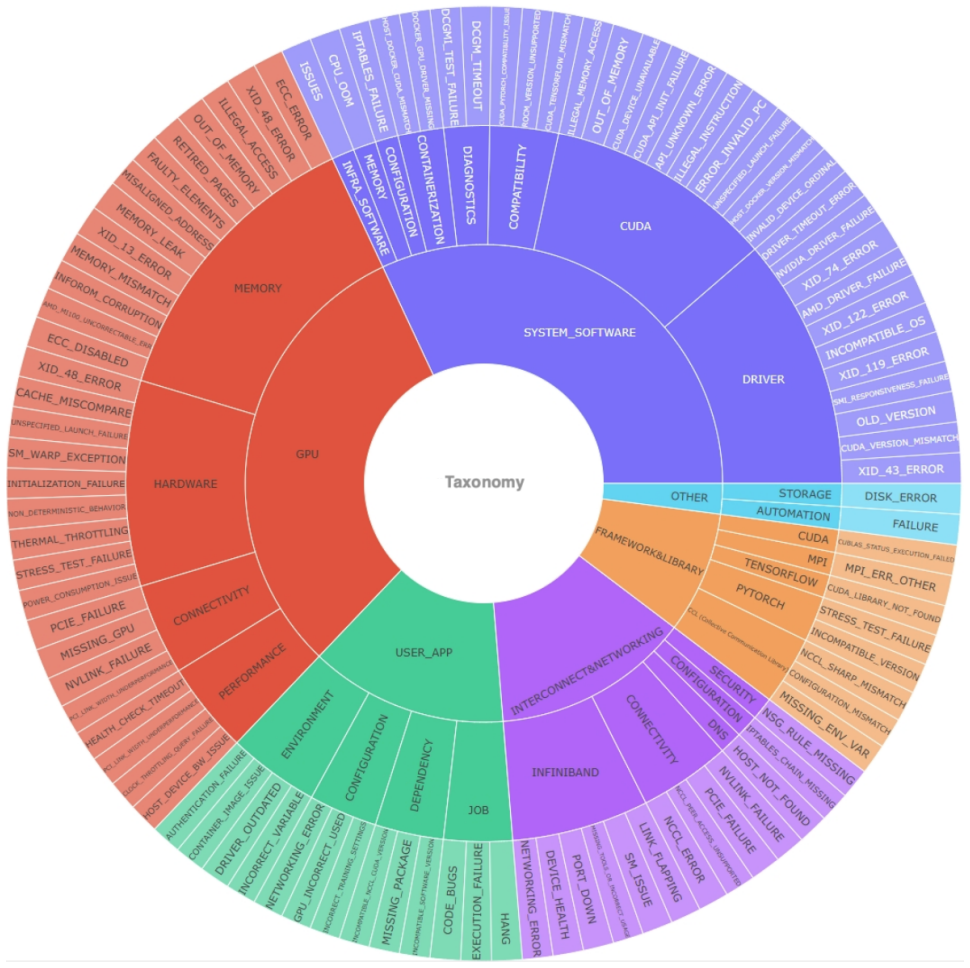
The offline phase constructs a historical incident database, incident taxonomy, and domain-specific knowledge base from on-call experiences; the online phase runs historical-data-driven diagnosis, taxonomy-guided recursive DFS, and root-cause exploration.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
https://anytree.readthedocs.io/en/ latest/
Anytree. https://anytree.readthedocs.io/en/ latest/. Accessed Dec 16, 2024
work page 2024
-
[2]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Recommending root-cause and mitigation steps for cloud incidents using large language models
Toufique Ahmed, Supriyo Ghosh, Chetan Bansal, Thomas Zimmermann, Xuchao Zhang, and Saravan Raj- mohan. Recommending root-cause and mitigation steps for cloud incidents using large language models. In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE), pages 1737–1749. IEEE, 2023
work page 2023
-
[4]
AMD Instinct MI200 Series Acceler- ators
AMD. AMD Instinct MI200 Series Acceler- ators. https://www.amd.com/en/products/ accelerators/instinct/mi200.html. Accessed Dec 12, 2024
work page 2024
-
[5]
Nissist: An incident mitigation copi- lot based on troubleshooting guides
Kaikai An, Fangkai Yang, Junting Lu, Liqun Li, Zhix- ing Ren, Hao Huang, Lu Wang, Pu Zhao, Yu Kang, Hua Ding, et al. Nissist: An incident mitigation copi- lot based on troubleshooting guides. arXiv preprint arXiv:2402.17531, 2024
-
[6]
Fire-flyer ai-hpc: A cost- effective software-hardware co-design for deep learn- ing
Wei An, Xiao Bi, Guanting Chen, Shanhuang Chen, Chengqi Deng, Honghui Ding, Kai Dong, Qiushi Du, Wenjun Gao, Kang Guan, et al. Fire-flyer ai-hpc: A cost- effective software-hardware co-design for deep learn- ing. In SC24: International Conference for High Perfor- mance Computing, Networking, Storage and Analysis, pages 1–23. IEEE, 2024
work page 2024
-
[7]
Karim Buzdar. Linux demsg command. https: //linuxhint.com/dmesg_tutorial/. Accessed Dec 12, 2024
work page 2024
-
[8]
Continuous incident triage for large- scale online service systems
Junjie Chen, Xiaoting He, Qingwei Lin, Hongyu Zhang, Dan Hao, Feng Gao, Zhangwei Xu, Yingnong Dang, and Dongmei Zhang. Continuous incident triage for large- scale online service systems. In 2019 34th IEEE/ACM International Conference on Automated Software Engi- neering (ASE), pages 364–375. IEEE, 2019
work page 2019
-
[9]
Junjie Chen, Shu Zhang, Xiaoting He, Qingwei Lin, Hongyu Zhang, Dan Hao, Yu Kang, Feng Gao, Zhang- wei Xu, Yingnong Dang, et al. How incidental are the incidents? characterizing and prioritizing incidents for 13 large-scale online service systems. In Proceedings of the 35th IEEE/ACM International Conference on Auto- mated Software Engineering, pages 373–384, 2020
work page 2020
-
[10]
Automatic root cause analysis via large language models for cloud incidents
Yinfang Chen, Huaibing Xie, Minghua Ma, Yu Kang, Xin Gao, Liu Shi, Yunjie Cao, Xuedong Gao, Hao Fan, Ming Wen, et al. Automatic root cause analysis via large language models for cloud incidents. In Proceedings of the Nineteenth European Conference on Computer Systems, pages 674–688, 2024
work page 2024
-
[11]
Minder: Faulty machine de- tection for large-scale distributed model training
Yangtao Deng, Xiang Shi, Zhuo Jiang, Xingjian Zhang, Lei Zhang, Zhang Zhang, Bo Li, Zuquan Song, Hang Zhu, Gaohong Liu, et al. Minder: Faulty machine de- tection for large-scale distributed model training. arXiv preprint arXiv:2411.01791, 2024
-
[12]
{AutoARTS}: Taxonomy, insights and tools for root cause labelling of incidents in microsoft azure
Pradeep Dogga, Chetan Bansal, Richard Costleigh, Gopinath Jayagopal, Suman Nath, and Xuchao Zhang. {AutoARTS}: Taxonomy, insights and tools for root cause labelling of incidents in microsoft azure. In 2023 USENIX Annual Technical Conference (USENIX ATC 23), pages 359–372, 2023
work page 2023
-
[13]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
{Check-N-Run}: A checkpointing system for training deep learning recommendation models
Assaf Eisenman, Kiran Kumar Matam, Steven Ingram, Dheevatsa Mudigere, Raghuraman Krishnamoorthi, Kr- ishnakumar Nair, Misha Smelyanskiy, and Murali An- navaram. {Check-N-Run}: A checkpointing system for training deep learning recommendation models. In 19th USENIX Symposium on Networked Systems Design and Implementation (NSDI 22), pages 929–943, 2022
work page 2022
-
[15]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. Gptq: Accurate post-training quantization for generative pre-trained transformers. arXiv preprint arXiv:2210.17323, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[16]
Scouts: Improving the diagnosis process through domain-customized incident routing
Jiaqi Gao, Nofel Yaseen, Robert MacDavid, Fe- lipe Vieira Frujeri, Vincent Liu, Ricardo Bianchini, Ra- maswamy Aditya, Xiaohang Wang, Henry Lee, David Maltz, et al. Scouts: Improving the diagnosis process through domain-customized incident routing. In Pro- ceedings of the Annual conference of the ACM Special Interest Group on Data Communication on the app...
work page 2020
-
[17]
How to fight production incidents? an empirical study on a large-scale cloud service
Supriyo Ghosh, Manish Shetty, Chetan Bansal, and Suman Nath. How to fight production incidents? an empirical study on a large-scale cloud service. In Pro- ceedings of the 13th Symposium on Cloud Computing, pages 126–141, 2022
work page 2022
-
[18]
Pingmesh: A large-scale system for data center network latency measurement and analysis
Chuanxiong Guo, Lihua Yuan, Dong Xiang, Yingnong Dang, Ray Huang, Dave Maltz, Zhaoyi Liu, Vin Wang, Bin Pang, Hua Chen, et al. Pingmesh: A large-scale system for data center network latency measurement and analysis. In Proceedings of the 2015 ACM Confer- ence on Special Interest Group on Data Communication, pages 139–152, 2015
work page 2015
-
[19]
A holistic view of ai-driven network incident management
Pouya Hamadanian, Behnaz Arzani, Sadjad Fouladi, Siva Kesava Reddy Kakarla, Rodrigo Fonseca, Denizcan Billor, Ahmad Cheema, Edet Nkposong, and Ranveer Chandra. A holistic view of ai-driven network incident management. In Proceedings of the 22nd ACM Work- shop on Hot Topics in Networks, pages 180–188, 2023
work page 2023
-
[20]
Similarity measures for text doc- ument clustering
Anna Huang et al. Similarity measures for text doc- ument clustering. In Proceedings of the sixth new zealand computer science research student conference (NZCSRSC2008), Christchurch, New Zealand, volume 4, pages 9–56, 2008
work page 2008
-
[21]
Faultprofit: Hier- archical fault profiling of incident tickets in large-scale cloud systems
Junjie Huang, Jinyang Liu, Zhuangbin Chen, Zhihan Jiang, Yichen Li, Jiazhen Gu, Cong Feng, Zengyin Yang, Yongqiang Yang, and Michael R Lyu. Faultprofit: Hier- archical fault profiling of incident tickets in large-scale cloud systems. In Proceedings of the 46th International Conference on Software Engineering: Software Engi- neering in Practice, pages 392–...
work page 2024
-
[22]
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Wei- hua Peng, Xiaocheng Feng, Bing Qin, et al. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions. ACM Trans- actions on Information Systems, 2023
work page 2023
-
[23]
Towards mitigating llm halluci- nation via self reflection
Ziwei Ji, Tiezheng Yu, Yan Xu, Nayeon Lee, Etsuko Ishii, and Pascale Fung. Towards mitigating llm halluci- nation via self reflection. In Findings of the Association for Computational Linguistics: EMNLP 2023 , pages 1827–1843, 2023
work page 2023
-
[24]
Xpert: Empowering inci- dent management with query recommendations via large language models
Yuxuan Jiang, Chaoyun Zhang, Shilin He, Zhihao Yang, Minghua Ma, Si Qin, Yu Kang, Yingnong Dang, Saravan Rajmohan, Qingwei Lin, et al. Xpert: Empowering inci- dent management with query recommendations via large language models. In Proceedings of the IEEE/ACM 46th International Conference on Software Engineering, pages 1–13, 2024
work page 2024
-
[25]
{MegaScale}: Scal- ing large language model training to more than 10,000 {GPUs}
Ziheng Jiang, Haibin Lin, Yinmin Zhong, Qi Huang, Yangrui Chen, Zhi Zhang, Yanghua Peng, Xiang Li, Cong Xie, Shibiao Nong, et al. {MegaScale}: Scal- ing large language model training to more than 10,000 {GPUs}. In 21st USENIX Symposium on Networked Systems Design and Implementation (NSDI 24), pages 745–760, 2024. 14
work page 2024
-
[26]
Assess and summarize: Improve outage understanding with large language models
Pengxiang Jin, Shenglin Zhang, Minghua Ma, Haozhe Li, Yu Kang, Liqun Li, Yudong Liu, Bo Qiao, Chaoyun Zhang, Pu Zhao, et al. Assess and summarize: Improve outage understanding with large language models. In Proceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Founda- tions of Software Engineering, pages 1657–1668, 2023
work page 2023
-
[27]
Revisiting reliability in large-scale machine learn- ing research clusters
Apostolos Kokolis, Michael Kuchnik, John Hoffman, Adithya Kumar, Parth Malani, Faye Ma, Zachary De- Vito, Shubho Sengupta, Kalyan Saladi, and Carole-Jean Wu. Revisiting reliability in large-scale machine learn- ing research clusters. arXiv preprint arXiv:2410.21680, 2024
-
[28]
Exploring the effectiveness of llms in automated log- ging generation: An empirical study
Yichen Li, Yintong Huo, Zhihan Jiang, Renyi Zhong, Pinjia He, Yuxin Su, Lionel Briand, and Michael R Lyu. Exploring the effectiveness of llms in automated log- ging generation: An empirical study. arXiv preprint arXiv:2307.05950, 2023
-
[29]
Parrot: Efficient serving of llm-based applications with seman- tic variable
Chaofan Lin, Zhenhua Han, Chengruidong Zhang, Yuqing Yang, Fan Yang, Chen Chen, and Lili Qiu. Parrot: Efficient serving of llm-based applications with seman- tic variable. arXiv preprint arXiv:2405.19888, 2024
-
[30]
Jerry Liu. Llamaindex. https://github.com/ run-llama/llama_index. Accessed Dec 12, 2024
work page 2024
-
[31]
Meta. Meta Llama 3.1 70B Instruct. https: //huggingface.co/neuralmagic/Meta-Llama-3. 1-70B-Instruct-FP8 . Accessed Dec 6, 2024
work page 2024
-
[32]
Meta. Meta Llama 3.1 8B Instruct. https: //huggingface.co/meta-llama/Llama-3. 1-8B-Instruct. Accessed Dec 6, 2024
work page 2024
-
[33]
Microsoft Azure. Azure OpenAI Service. https://azure.microsoft.com/en-us/products/ ai-services/openai-service. Accessed Nov 3, 2024
work page 2024
-
[34]
Microsoft Azure. Azure OpenAI Service pricing. https://azure.microsoft.com/en-us/pricing/ details/cognitive-services/openai-service/ #pricing. Accessed Oct 12, 2024
work page 2024
-
[35]
Microsoft Azure. AzureHPC Node Health Check. https://github.com/Azure/ azurehpc-health-checks. Accessed Dec 12, 2024
work page 2024
-
[36]
Microsoft Azure. GPT-4o and GPT- 4 Turbo. https://learn.microsoft. com/en-us/azure/ai-services/openai/ concepts/models?tabs=global-standard% 2Cstandard-chat-completions# gpt-4o-and-gpt-4-turbo . Accessed Dec 12, 2024
work page 2024
-
[37]
Microsoft Azure. o1 and o1-mini mod- els. https://learn.microsoft.com/ en-us/azure/ai-services/openai/ concepts/models?tabs=global-standard% 2Cstandard-chat-completions# o1-and-o1-mini-models-limited-access . Ac- cessed Dec 12, 2024
work page 2024
-
[38]
NVIDIA. NVIDIA A100 Tensor Core GPU. https:// www.nvidia.com/en-us/data-center/a100/. Ac- cessed Dec 12, 2024
work page 2024
-
[39]
NVIDIA Data Center GPU Manager
NVIDIA. NVIDIA Data Center GPU Manager. https: //github.com/NVIDIA/DCGM. Accessed Dec 12, 2024
work page 2024
-
[40]
NVIDIA. NVIDIA H100 Tensor Core GPU. https:// www.nvidia.com/en-us/data-center/h100/. Ac- cessed Dec 12, 2024
work page 2024
-
[41]
NVIDIA. NVIDIA NCCL Tests. https://github. com/NVIDIA/nccl-tests. Accessed Dec 12, 2024
work page 2024
-
[42]
NVIDIA NVLink and NVLink Switch
NVIDIA. NVIDIA NVLink and NVLink Switch. https://www.nvidia.com/en-us/data-center/ nvlink/. Accessed Dec 12, 2024
work page 2024
-
[43]
NVIDIA System Management In- terface
NVIDIA. NVIDIA System Management In- terface. https://developer.nvidia.com/ nvidia-system-management-interface . Ac- cessed Dec 12, 2024
work page 2024
-
[44]
The NVIDIA Quantum InfiniBand Platform
NVIDIA. The NVIDIA Quantum InfiniBand Platform. https://www.nvidia.com/en-us/networking/ products/infiniband/. Accessed Dec 12, 2024
work page 2024
-
[45]
Liangming Pan, Michael Saxon, Wenda Xu, Deepak Nathani, Xinyi Wang, and William Yang Wang. Auto- matically correcting large language models: Surveying the landscape of diverse self-correction strategies. arXiv preprint arXiv:2308.03188, 2023
-
[46]
ART: Automatic multi-step reasoning and tool-use for large language models
Bhargavi Paranjape, Scott Lundberg, Sameer Singh, Hannaneh Hajishirzi, Luke Zettlemoyer, and Marco Tulio Ribeiro. Art: Automatic multi-step reasoning and tool-use for large language models. arXiv preprint arXiv:2303.09014, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[47]
Alibaba hpn: A data center network for large language model training
Kun Qian, Yongqing Xi, Jiamin Cao, Jiaqi Gao, Yichi Xu, Yu Guan, Binzhang Fu, Xuemei Shi, Fangbo Zhu, Rui Miao, et al. Alibaba hpn: A data center network for large language model training. In Proceedings of the ACM SIGCOMM 2024 Conference, pages 691–706, 2024
work page 2024
-
[48]
Zhen Qin, Rolf Jagerman, Kai Hui, Honglei Zhuang, Junru Wu, Le Yan, Jiaming Shen, Tianqi Liu, Jialu Liu, Donald Metzler, et al. Large language models are effec- tive text rankers with pairwise ranking prompting.arXiv preprint arXiv:2306.17563, 2023. 15
-
[49]
Qwen 2.5 32B Instruct.https://huggingface
Qwen. Qwen 2.5 32B Instruct.https://huggingface. co/Qwen/Qwen2.5-32B-Instruct-GPTQ-Int4 . Ac- cessed Dec 6, 2024
work page 2024
-
[50]
Qwen 2.5 72B Instruct.https://huggingface
Qwen. Qwen 2.5 72B Instruct.https://huggingface. co/Qwen/Qwen2.5-72B-Instruct-GPTQ-Int4 . Ac- cessed Dec 6, 2024
work page 2024
-
[51]
Qwen. Qwen 2.5 7B Instruct. https://huggingface. co/Qwen/Qwen2.5-7B-Instruct-GPTQ-Int4 . Ac- cessed Dec 6, 2024
work page 2024
-
[52]
Kunal Sawarkar, Abhilasha Mangal, and Shivam Raj Solanki. Blended rag: Improving rag (retriever- augmented generation) accuracy with semantic search and hybrid query-based retrievers. arXiv preprint arXiv:2404.07220, 2024
-
[53]
Tool- former: Language models can teach themselves to use tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettle- moyer, Nicola Cancedda, and Thomas Scialom. Tool- former: Language models can teach themselves to use tools. Advances in Neural Information Processing Sys- tems, 36:68539–68551, 2023
work page 2023
-
[54]
Face it yourselves: An llm-based two-stage strategy to localize configuration errors via logs
Shiwen Shan, Yintong Huo, Yuxin Su, Yichen Li, Dan Li, and Zibin Zheng. Face it yourselves: An llm-based two-stage strategy to localize configuration errors via logs. In Proceedings of the 33rd ACM SIGSOFT Inter- national Symposium on Software Testing and Analysis, pages 13–25, 2024
work page 2024
-
[55]
Neural knowledge extraction from cloud service inci- dents
Manish Shetty, Chetan Bansal, Sumit Kumar, Nikitha Rao, Nachiappan Nagappan, and Thomas Zimmermann. Neural knowledge extraction from cloud service inci- dents. In 2021 IEEE/ACM 43rd International Confer- ence on Software Engineering: Software Engineering in Practice (ICSE-SEIP), pages 218–227. IEEE, 2021
work page 2021
-
[56]
Au- totsg: learning and synthesis for incident troubleshoot- ing
Manish Shetty, Chetan Bansal, Sai Pramod Upad- hyayula, Arjun Radhakrishna, and Anurag Gupta. Au- totsg: learning and synthesis for incident troubleshoot- ing. In Proceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, pages 1477– 1488, 2022
work page 2022
-
[57]
Teola: Towards end-to-end optimization of llm-based applica- tions
Xin Tan, Yimin Jiang, Yitao Yang, and Hong Xu. Teola: Towards end-to-end optimization of llm-based applica- tions. arXiv preprint arXiv:2407.00326, 2024
-
[58]
{NetAssistant}: Dialogue based network diagnosis in data center networks
Haopei Wang, Anubhavnidhi Abhashkumar, Changyu Lin, Tianrong Zhang, Xiaoming Gu, Ning Ma, Chang Wu, Songlin Liu, Wei Zhou, Yongbin Dong, et al. {NetAssistant}: Dialogue based network diagnosis in data center networks. In 21st USENIX Symposium on Networked Systems Design and Implementation (NSDI 24), pages 2011–2024, 2024
work page 2011
-
[59]
Searching for best practices in retrieval-augmented generation
Xiaohua Wang, Zhenghua Wang, Xuan Gao, Feiran Zhang, Yixin Wu, Zhibo Xu, Tianyuan Shi, Zhengyuan Wang, Shizheng Li, Qi Qian, et al. Searching for best practices in retrieval-augmented generation. In Pro- ceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 17716–17736, 2024
work page 2024
-
[60]
Rcagent: Cloud root cause anal- ysis by autonomous agents with tool-augmented large language models
Zefan Wang, Zichuan Liu, Yingying Zhang, Aoxiao Zhong, Jihong Wang, Fengbin Yin, Lunting Fan, Lingfei Wu, and Qingsong Wen. Rcagent: Cloud root cause anal- ysis by autonomous agents with tool-augmented large language models. In Proceedings of the 33rd ACM In- ternational Conference on Information and Knowledge Management, pages 4966–4974, 2024
work page 2024
-
[61]
Gemini: Fast failure recovery in distributed training with in-memory checkpoints
Zhuang Wang, Zhen Jia, Shuai Zheng, Zhen Zhang, Xin- wei Fu, TS Eugene Ng, and Yida Wang. Gemini: Fast failure recovery in distributed training with in-memory checkpoints. In Proceedings of the 29th Symposium on Operating Systems Principles, pages 364–381, 2023
work page 2023
-
[62]
Falcon: Pinpointing and mit- igating stragglers for large-scale hybrid-parallel training
Tianyuan Wu, Wei Wang, Yinghao Yu, Siran Yang, Wen- chao Wu, Qinkai Duan, Guodong Yang, Jiamang Wang, Lin Qu, and Liping Zhang. Falcon: Pinpointing and mit- igating stragglers for large-scale hybrid-parallel training. arXiv preprint arXiv:2410.12588, 2024
-
[63]
Zhiqiang Xie, Yujia Zheng, Lizi Ottens, Kun Zhang, Christos Kozyrakis, and Jonathan Mace. Cloud at- las: Efficient fault localization for cloud systems using language models and causal insight. arXiv preprint arXiv:2407.08694, 2024
-
[64]
{SuperBench}: Improving cloud {AI} infrastructure reliability with proactive vali- dation
Yifan Xiong, Yuting Jiang, Ziyue Yang, Lei Qu, Gu- oshuai Zhao, Shuguang Liu, Dong Zhong, Boris Pinzur, Jie Zhang, Yang Wang, et al. {SuperBench}: Improving cloud {AI} infrastructure reliability with proactive vali- dation. In 2024 USENIX Annual Technical Conference (USENIX ATC 24), pages 835–850, 2024
work page 2024
-
[65]
Hallucination is Inevitable: An Innate Limitation of Large Language Models
Ziwei Xu, Sanjay Jain, and Mohan Kankanhalli. Hal- lucination is inevitable: An innate limitation of large language models. arXiv preprint arXiv:2401.11817 , 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[66]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. Qwen2. 5 technical report. arXiv preprint arXiv:2412.15115, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[67]
Diffusion-based time series data imputation for cloud failure prediction at microsoft 365
Fangkai Yang, Wenjie Yin, Lu Wang, Tianci Li, Pu Zhao, Bo Liu, Paul Wang, Bo Qiao, Yudong Liu, Mårten Björk- man, et al. Diffusion-based time series data imputation for cloud failure prediction at microsoft 365. In Pro- ceedings of the 31st ACM Joint European Software Engi- neering Conference and Symposium on the Foundations of Software Engineering, pages...
work page 2050
-
[68]
Gpt4tools: Teaching large lan- guage model to use tools via self-instruction
Rui Yang, Lin Song, Yanwei Li, Sijie Zhao, Yixiao Ge, Xiu Li, and Ying Shan. Gpt4tools: Teaching large lan- guage model to use tools via self-instruction. Advances in Neural Information Processing Systems, 36, 2024
work page 2024
-
[69]
Dylan Zhang, Xuchao Zhang, Chetan Bansal, Pedro Las- Casas, Rodrigo Fonseca, and Saravan Rajmohan. Pace: Prompting and augmentation for calibrated confidence estimation with gpt-4 in cloud incident root cause anal- ysis. arXiv preprint arXiv:2309.05833, 2023
-
[70]
Deepview: Virtual disk failure diagnosis and pattern detection for azure
Qiao Zhang, Guo Yu, Chuanxiong Guo, Yingnong Dang, Nick Swanson, Xinsheng Yang, Randolph Yao, Murali Chintalapati, Arvind Krishnamurthy, and Thomas An- derson. Deepview: Virtual disk failure diagnosis and pattern detection for azure. In 15th USENIX Sympo- sium on Networked Systems Design and Implementation (NSDI 18), pages 519–532, 2018
work page 2018
-
[71]
Automated root causing of cloud incidents using in- context learning with gpt-4
Xuchao Zhang, Supriyo Ghosh, Chetan Bansal, Rujia Wang, Minghua Ma, Yu Kang, and Saravan Rajmohan. Automated root causing of cloud incidents using in- context learning with gpt-4. In Companion Proceed- ings of the 32nd ACM International Conference on the Foundations of Software Engineering, pages 266–277, 2024
work page 2024
-
[72]
Real-time incident prediction for online service systems
Nengwen Zhao, Junjie Chen, Zhou Wang, Xiao Peng, Gang Wang, Yong Wu, Fang Zhou, Zhen Feng, Xiaohui Nie, Wenchi Zhang, et al. Real-time incident prediction for online service systems. In Proceedings of the 28th ACM Joint Meeting on European Software Engineer- ing Conference and Symposium on the Foundations of Software Engineering, pages 315–326, 2020
work page 2020
-
[73]
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Jeff Huang, Chuyue Sun, Cody Hao Yu, Shiyi Cao, Chris- tos Kozyrakis, Ion Stoica, Joseph E Gonzalez, et al. Efficiently programming large language models using sglang. arXiv e-prints, pages arXiv–2312, 2023. 17 Appendices A Summarization of Example Incidents Figure 16 shows the output of the summarization agent...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.