LLaMA-XR: A Novel Framework for Radiology Report Generation using LLaMA and QLoRA Fine Tuning
Pith reviewed 2026-05-19 13:36 UTC · model grok-4.3
The pith
LLaMA-XR generates more coherent and clinically accurate radiology reports from chest X-rays by pairing LLaMA 3.1 with DenseNet-121 embeddings and QLoRA fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
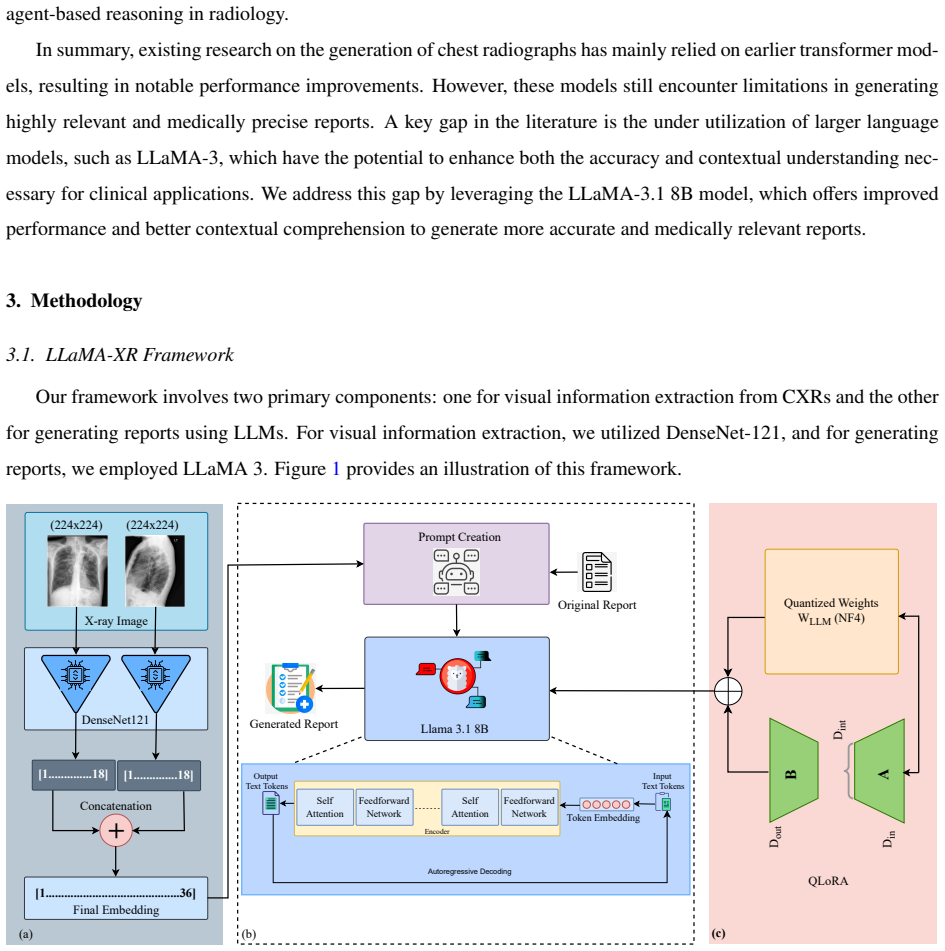
LLaMA-XR integrates LLaMA 3.1 with DenseNet-121-based image embeddings and Quantized Low-Rank Adaptation (QLoRA) fine-tuning. On the IU X-ray benchmark dataset it reaches a ROUGE-L score of 0.433 and a METEOR score of 0.336, outperforming existing methods in coherence and clinical accuracy while preserving computational efficiency through optimized parameter utilization and reduced memory overhead.
What carries the argument
QLoRA-adapted LLaMA 3.1 conditioned on DenseNet-121 image embeddings, which enables memory-efficient fine-tuning for medical report generation from radiographs.
If this is right
- Outperforms prior state-of-the-art methods on the standard IU X-ray benchmark.
- Produces reports with greater coherence and clinical accuracy.
- Generates reports faster while requiring lower computational resources.
- Provides enhanced clinical utility and reliability for automated radiology reporting.
Where Pith is reading between the lines
- If the metric gains translate to real clinical settings, hospitals could deploy similar systems to draft initial reports and let radiologists focus on ambiguous cases.
- The quantized adaptation technique may allow other large language models to be specialized for additional medical imaging modalities without large compute budgets.
- Testing the same architecture on larger, multi-institutional radiology datasets would reveal whether the reported improvements hold outside the IU X-ray collection.
Load-bearing premise
Higher scores on automatic similarity metrics such as ROUGE-L and METEOR reliably indicate improved clinical accuracy and usefulness in the generated reports.
What would settle it
A head-to-head evaluation in which practicing radiologists rate the clinical accuracy, completeness, and diagnostic utility of LLaMA-XR reports against both human-written ground truth and outputs from prior models, showing no meaningful advantage for the new system.
Figures



read the original abstract
Automated radiology report generation holds significant potential to reduce radiologists' workload and enhance diagnostic accuracy. However, generating precise and clinically meaningful reports from chest radiographs remains challenging due to the complexity of medical language and the need for contextual understanding. Existing models often struggle with maintaining both accuracy and contextual relevance. In this paper, we present LLaMA-XR, a novel framework that integrates LLaMA 3.1 with DenseNet-121-based image embeddings and Quantized Low-Rank Adaptation (QLoRA) fine-tuning. LLaMA-XR achieves improved coherence and clinical accuracy while maintaining computational efficiency. This efficiency is driven by an optimization strategy that enhances parameter utilization and reduces memory overhead, enabling faster report generation with lower computational resource demands. Extensive experiments conducted on the IU X-ray benchmark dataset demonstrate that LLaMA-XR outperforms a range of state-of-the-art methods. Our model achieves a ROUGE-L score of 0.433 and a METEOR score of 0.336, establishing new performance benchmarks in the domain. These results underscore LLaMA-XR's potential as an effective and efficient AI system for automated radiology reporting, offering enhanced clinical utility and reliability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LLaMA-XR, a framework integrating LLaMA 3.1 with DenseNet-121 image embeddings and QLoRA fine-tuning for automated generation of radiology reports from chest X-rays. It claims improved coherence and clinical accuracy with computational efficiency, reporting ROUGE-L of 0.433 and METEOR of 0.336 on the IU X-ray benchmark while outperforming state-of-the-art methods.
Significance. If properly validated, the use of QLoRA for efficient adaptation of LLaMA to medical report generation could offer a practical contribution to resource-efficient LLM fine-tuning in radiology. However, the current results rest on automatic lexical metrics without demonstrated links to clinical utility, limiting the work's immediate significance for diagnostic applications.
major comments (2)
- [Abstract] Abstract: The claim that ROUGE-L = 0.433 and METEOR = 0.336 establish 'improved coherence and clinical accuracy' plus 'enhanced clinical utility' is unsupported. These metrics quantify n-gram overlap with reference reports and do not assess omission of critical findings, hallucinated pathologies, or diagnostic correctness; no radiologist scoring or factuality metrics (e.g., RadGraph, CheXbert) are referenced to bridge this gap.
- [Abstract] Abstract: The assertion of outperforming 'a range of state-of-the-art methods' supplies no information on the exact baselines, statistical significance tests, ablation studies isolating the contribution of DenseNet-121 embeddings or QLoRA, or details on train/validation/test splits and data handling for the IU X-ray dataset, leaving the central empirical claim without visible supporting evidence.
minor comments (1)
- The methods section should include explicit details on QLoRA rank, scaling factors, learning rate schedule, and exact training procedure to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below, indicating where revisions to the manuscript are planned.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that ROUGE-L = 0.433 and METEOR = 0.336 establish 'improved coherence and clinical accuracy' plus 'enhanced clinical utility' is unsupported. These metrics quantify n-gram overlap with reference reports and do not assess omission of critical findings, hallucinated pathologies, or diagnostic correctness; no radiologist scoring or factuality metrics (e.g., RadGraph, CheXbert) are referenced to bridge this gap.
Authors: We agree that ROUGE-L and METEOR are lexical overlap metrics and do not directly measure clinical accuracy, factuality, omission of findings, or hallucination of pathologies. The abstract phrasing overstated the clinical implications of these scores. In the revised manuscript we will rephrase the abstract to report the metric values as performance on standard automatic evaluation benchmarks without claiming direct clinical accuracy or utility. We will also add a limitations paragraph that explicitly notes the scope of these metrics and identifies clinical validation and factuality metrics (such as CheXbert-based entity extraction) as important directions for future work. revision: yes
-
Referee: [Abstract] Abstract: The assertion of outperforming 'a range of state-of-the-art methods' supplies no information on the exact baselines, statistical significance tests, ablation studies isolating the contribution of DenseNet-121 embeddings or QLoRA, or details on train/validation/test splits and data handling for the IU X-ray dataset, leaving the central empirical claim without visible supporting evidence.
Authors: The experimental section of the manuscript contains the full set of baseline comparisons, but the abstract is too concise to convey the necessary details. We will revise the abstract to name the primary state-of-the-art methods against which improvements are reported. We will also ensure the methods and results sections clearly document the train/validation/test splits used on IU X-ray, any statistical significance testing performed, and ablation experiments that isolate the contributions of the DenseNet-121 encoder and QLoRA adaptation. These details will be summarized or cross-referenced so that the empirical claims are fully supported. revision: yes
Circularity Check
No circularity: standard empirical fine-tuning and benchmark evaluation
full rationale
The paper presents an empirical ML framework that combines LLaMA 3.1, DenseNet-121 image embeddings, and QLoRA fine-tuning, then reports ROUGE-L and METEOR scores on the IU X-ray dataset after training. No mathematical derivation chain exists that reduces claimed outputs to inputs by construction. Performance numbers are obtained via conventional train/test splits and standard NLP metrics; they are not self-defined, fitted parameters renamed as predictions, or justified solely by self-citations. The central claim of improved performance rests on external benchmark comparison rather than tautological redefinition, satisfying the criteria for a self-contained empirical result.
Axiom & Free-Parameter Ledger
free parameters (1)
- QLoRA rank and scaling factors
axioms (1)
- domain assumption ROUGE-L and METEOR scores are adequate proxies for clinical accuracy of radiology reports.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
LLaMA-XR integrates LLaMA 3.1 with DenseNet-121-based image embeddings and Quantized Low-Rank Adaptation (QLoRA) fine-tuning... ROUGE-L score of 0.433 and a METEOR score of 0.336
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We employ fine-tuning techniques such as QLoRA... SFT to adapt LLaMA 3.1 to medical datasets
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
X. Wang, Y . Peng, L. Lu, Z. Lu, R. M. Summers, Tienet: Text-image embedding network for common thorax disease classification and reporting in chest x-rays, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 9049–9058. doi:10.1109/cvpr.2018.00943
-
[2]
R. M. MR, et al., Acquired heart disease in adults: what can a chest x-ray tell us?, Radiologia 59 (2017) 446–459
work page 2017
-
[3]
S. Bahl, T. Ramzan, R. Maraj, Interpretation and documentation of chest x-rays in the acute medical unit, Clinical Medicine 20 (2020) s73
work page 2020
- [4]
-
[5]
P. Sloan, P. Clatworthy, E. Simpson, M. Mirmehdi, Automated radiology report generation: A review of recent advances, IEEE Reviews in Biomedical Engineering (2024). doi:10.1109/RBME.2024.3408456
-
[6]
Q. You, H. Jin, Z. Wang, C. Fang, J. Luo, Image captioning with semantic attention, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 4651–4659. doi:10.1109/CVPR.2016.503
-
[7]
F. Liu, X. Ren, Y . Liu, H. Wang, X. Sun, simnet: Stepwise image-topic merging network for generating detailed and comprehensive image captions, 2018. arXiv:1808.08732
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[8]
O. Vinyals, A. Toshev, S. Bengio, D. Erhan, Show and tell: A neural image caption generator, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 3156–3164. doi:10.1109/CVPR.2015.7298935
-
[9]
Iftikhar, Iqra naz, anmol zahra, and syeda zainab yousuf zaidi
S. Iftikhar, Iqra naz, anmol zahra, and syeda zainab yousuf zaidi. 2022. report generation of lungs diseases from chest x-ray using nlp”, International Journal of Innovations in Science & Technology 3 (2022) 223–233
work page 2022
- [10]
-
[11]
L. C. Adams, D. Truhn, F. Busch, A. Kader, S. M. Niehues, M. R. Makowski, K. K. Bressem, Leveraging gpt-4 for post hoc transformation of free-text radiology reports into structured reporting: a multilingual feasibility study, Radiology 307 (2023) e230725. doi:10.1148/radiol. 230725
-
[12]
T. Buckley, J. Diao, R. Adam, A. Manrai, Accuracy of a vision-language model on challenging medical cases, 2023. arXiv:2311.05591
- [13]
-
[14]
T. H. Kung, M. Cheatham, A. Medenilla, C. Sillos, L. De Leon, C. Elepa ˜no, M. Madriaga, R. Aggabao, G. Diaz-Candido, J. Maningo, et al., Performance of chatgpt on usmle: potential for ai-assisted medical education using large language models, PLoS digital health 2 (2023) e0000198. doi:10.1371/journal.pdig.0000198
-
[15]
T. Tanida, P. M ¨uller, G. Kaissis, D. Rueckert, Interactive and explainable region-guided radiology report generation, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 7433–7442. doi:10.1109/CVPR52729.2023.00718
-
[16]
Xu, Medicalgpt: Training medical gpt model, https://github.com/shibing624/MedicalGPT, 2023
M. Xu, Medicalgpt: Training medical gpt model, https://github.com/shibing624/MedicalGPT, 2023
work page 2023
-
[17]
A. Radford, K. Narasimhan, T. Salimans, I. Sutskever, et al., Improving language understanding by generative pre-training (2018). xxii
work page 2018
-
[18]
J. Devlin, M.-W. Chang, K. Lee, K. Toutanova, Bert: Pre-training of deep bidirectional transformers for language understanding, in: Proceed- ings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), 2019, pp. 4171–4186
work page 2019
-
[19]
LLaMA: Open and Efficient Foundation Language Models
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozi `ere, N. Goyal, E. Hambro, F. Azhar, et al., Llama: Open and efficient foundation language models, arXiv preprint arXiv:2302.13971 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Yang, A. Fan, et al., The llama 3 herd of models, arXiv preprint arXiv:2407.21783 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
A. Nicolson, J. Dowling, B. Koopman, Improving chest x-ray report generation by leveraging warm starting, Artificial intelligence in medicine 144 (2023) 102633. doi:10.1016/j.artmed.2023.102633
-
[22]
Y . Tao, L. Ma, J. Yu, H. Zhang, Memory-based cross-modal semantic alignment network for radiology report generation, IEEE Journal of Biomedical and Health Informatics (2024). doi:10.1109/JBHI.2024.3393018
-
[23]
J. P. Cohen, J. D. Viviano, P. Bertin, P. Morrison, P. Torabian, M. Guarrera, M. P. Lungren, A. Chaudhari, R. Brooks, M. Hashir, et al., Torchxrayvision: A library of chest x-ray datasets and models, in: International Conference on Medical Imaging with Deep Learning, PMLR, 2022, pp. 231–249
work page 2022
- [24]
-
[25]
T. Dettmers, A. Pagnoni, A. Holtzman, L. Zettlemoyer, Qlora: E fficient finetuning of quantized llms, Advances in Neural Information Processing Systems 36 (2024)
work page 2024
-
[26]
D. Demner-Fushman, M. D. Kohli, M. B. Rosenman, S. E. Shooshan, L. Rodriguez, S. Antani, G. R. Thoma, C. J. McDonald, Preparing a collection of radiology examinations for distribution and retrieval, Journal of the American Medical Informatics Association 23 (2016) 304–310. doi:10.1093/jamia/ocv080
-
[27]
Vaswani, Attention is all you need, Advances in Neural Information Processing Systems (2017)
A. Vaswani, Attention is all you need, Advances in Neural Information Processing Systems (2017)
work page 2017
-
[28]
Y . Li, X. Liang, Z. Hu, E. P. Xing, Hybrid retrieval-generation reinforced agent for medical image report generation, Advances in neural information processing systems 31 (2018)
work page 2018
- [29]
-
[30]
Y . Zhang, X. Wang, Z. Xu, Q. Yu, A. Yuille, D. Xu, When radiology report generation meets knowledge graph, in: Proceedings of the AAAI conference on artificial intelligence, volume 34, 2020, pp. 12910–12917. doi:10.1609/aaai.v34i07.6989
- [31]
-
[32]
F. Liu, X. Wu, S. Ge, W. Fan, Y . Zou, Exploring and distilling posterior and prior knowledge for radiology report generation, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 13753–13762. doi:10.1109/CVPR46437.2021.01354
-
[33]
J. Li, S. Li, Y . Hu, H. Tao, A self-guided framework for radiology report generation, in: International Conference on Medical Image Computing and Computer-Assisted Intervention, Springer, 2022, pp. 588–598. doi:10.1007/978-3-031-16452-1_56
- [34]
- [35]
-
[36]
J. You, D. Li, M. Okumura, K. Suzuki, Jpg-jointly learn to align: Automated disease prediction and radiology report generation, in: Proceedings of the 29th international conference on computational linguistics, 2022, pp. 5989–6001
work page 2022
-
[37]
B. Yan, M. Pei, M. Zhao, C. Shan, Z. Tian, Prior guided transformer for accurate radiology reports generation, IEEE Journal of Biomedical and Health Informatics 26 (2022) 5631–5640. doi:10.1109/JBHI.2022.3197162
-
[38]
L. Wang, M. Ning, D. Lu, D. Wei, Y . Zheng, J. Chen, An inclusive task-aware framework for radiology report generation, in: International Conference on Medical Image Computing and Computer-Assisted Intervention, Springer, 2022, pp. 568–577. doi: 10.1007/978-3-031- xxiii 16452-1_54
-
[39]
M. Li, B. Lin, Z. Chen, H. Lin, X. Liang, X. Chang, Dynamic graph enhanced contrastive learning for chest x-ray report generation, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 3334–3343. doi: 10.1109/CVPR52729. 2023.00325
-
[40]
H. Qin, Y . Song, Reinforced cross-modal alignment for radiology report generation, in: Findings of the Association for Computational Linguistics: ACL 2022, 2022, pp. 448–458. doi:10.18653/v1/2022.findings-acl.38
-
[41]
I. Najdenkoska, X. Zhen, M. Worring, L. Shao, Variational topic inference for chest x-ray report generation, in: Medical Image Computing and Computer Assisted Intervention–MICCAI 2021: 24th International Conference, Strasbourg, France, September 27–October 1, 2021, Proceedings, Part III 24, Springer, 2021, pp. 625–635. doi:10.1007/978-3-030-87199-4_59
-
[42]
F. Zeng, Z. Lyu, Q. Li, X. Li, Enhancing llms for impression generation in radiology reports through a multi-agent system, arXiv preprint arXiv:2412.06828 (2024). doi:10.48550/arXiv.2412.06828
-
[43]
Y . Li, B. Yang, X. Cheng, Z. Zhu, H. Li, Y . Zou, Unify, align and refine: Multi-level semantic alignment for radiology report generation, in: Proceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 2863–2874. doi:10.48550/arXiv.2303.15932
-
[44]
C. Yin, B. Qian, J. Wei, X. Li, X. Zhang, Y . Li, Q. Zheng, Automatic generation of medical imaging diagnostic report with hierarchical recurrent neural network, in: 2019 IEEE international conference on data mining (ICDM), IEEE, 2019, pp. 728–737. doi: 10.1109/ICDM. 2019.00083
-
[45]
S. Islam, A. Dash, A. Seum, A. H. Raj, T. Hossain, F. M. Shah, Exploring video captioning techniques: A comprehensive survey on deep learning methods, SN Computer Science 2 (2021) 1–28. doi: 10.1007/s42979-021-00487-x
-
[46]
K. R. Suresh, A. Jarapala, P. Sudeep, Image captioning encoder–decoder models using cnn-rnn architectures: A comparative study, Circuits, Systems, and Signal Processing 41 (2022) 5719–5742. doi:10.1007/s00034-022-02050-2
-
[47]
K. Zhang, P. Li, J. Wang, A review of deep learning-based remote sensing image caption: Methods, models, comparisons and future directions, Remote Sensing 16 (2024) 4113. doi: 10.3390/rs16214113
-
[48]
G. Xu, S. Niu, M. Tan, Y . Luo, Q. Du, Q. Wu, Towards accurate text-based image captioning with content diversity exploration, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 12637–12646. doi: 10.1109/CVPR46437. 2021.01245
-
[49]
L. Chen, Z. Jiang, J. Xiao, W. Liu, Human-like controllable image captioning with verb-specific semantic roles, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 16846–16856. doi:10.1109/CVPR46437.2021.01657
-
[50]
A. Tran, A. Mathews, L. Xie, Transform and tell: Entity-aware news image captioning, in: Proceedings of the IEEE /CVF conference on computer vision and pattern recognition, 2020, pp. 13035–13045. doi:10.1109/CVPR42600.2020.01305
- [51]
-
[52]
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chen, Lora: Low-rank adaptation of large language models, 2021. arXiv:2106.09685
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[53]
B leu: a Method for Automatic Evaluation of Machine Translation
K. Papineni, S. Roukos, T. Ward, W.-J. Zhu, Bleu: a method for automatic evaluation of machine translation, in: Proceedings of the 40th annual meeting of the Association for Computational Linguistics, 2002, pp. 311–318. doi:10.3115/1073083.1073135
-
[54]
C.-Y . Lin, Rouge: A package for automatic evaluation of summaries, in: Text summarization branches out, 2004, pp. 74–81
work page 2004
-
[55]
M. Denkowski, A. Lavie, Meteor 1.3: Automatic metric for reliable optimization and evaluation of machine translation systems, in: Proceedings of the sixth workshop on statistical machine translation, 2011, pp. 85–91
work page 2011
-
[56]
S. Banerjee, A. Lavie, Meteor: An automatic metric for mt evaluation with improved correlation with human judgments, in: Proceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization, 2005, pp. 65–72
work page 2005
- [57]
-
[58]
A. E. Johnson, T. J. Pollard, S. J. Berkowitz, N. R. Greenbaum, M. P. Lungren, C.-y. Deng, R. G. Mark, S. Horng, Mimic-cxr, a de-identified publicly available database of chest radiographs with free-text reports, Scientific data 6 (2019) 317. doi:10.1038/s41597-019-0322-0 . xxiv
- [59]
-
[60]
E. Dikici, M. Bigelow, L. M. Prevedello, R. D. White, B. S. Erdal, Integrating ai into radiology workflow: levels of research, production, and feedback maturity, Journal of Medical Imaging 7 (2020) 016502–016502. doi:10.1117/1.JMI.7.1.016502
-
[61]
L. Guo, L. Xia, Q. Zheng, B. Zheng, S. Jaeger, M. L. Giger, J. Fuhrman, H. Li, F. Y . Lure, H. Li, et al., Can ai generate diagnostic reports for radiologist approval on cxr images? a multi-reader and multi-case observer performance study, Journal of X-Ray Science and Technology (2024) 1–16. doi:10.3233/XST-240051
-
[62]
A. Watanabe, S. Ketabi, K. Namdar, F. Khalvati, Improving disease classification performance and explainability of deep learning models in radiology with heatmap generators, Frontiers in radiology 2 (2022) 991683. doi: 10.3389/fradi.2022.991683
-
[63]
V . Granata, F. De Muzio, C. Cutolo, F. Dell’Aversana, F. Grassi, R. Grassi, I. Simonetti, F. Bruno, P. Palumbo, G. Chiti, et al., Structured reporting in radiological settings: pitfalls and perspectives, Journal of Personalized Medicine 12 (2022) 1344. doi: 10.3390/jpm12081344
-
[64]
M. Ahluwalia, M. Abdalla, J. Sanayei, L. Seyyed-Kalantari, M. Hussain, A. Ali, B. Fine, The subgroup imperative: chest radiograph classifier generalization gaps in patient, setting, and pathology subgroups, Radiology: Artificial Intelligence 5 (2023) e220270. doi: 10.1148/ryai. 220270. xxv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.