"Don't Do That!": Guiding Embodied Systems through Large Language Model-based Constraint Generation
Pith reviewed 2026-05-19 10:25 UTC · model grok-4.3
The pith
LLMs translate natural-language 'don't do' rules into Python functions that let robots plan fully compliant paths
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
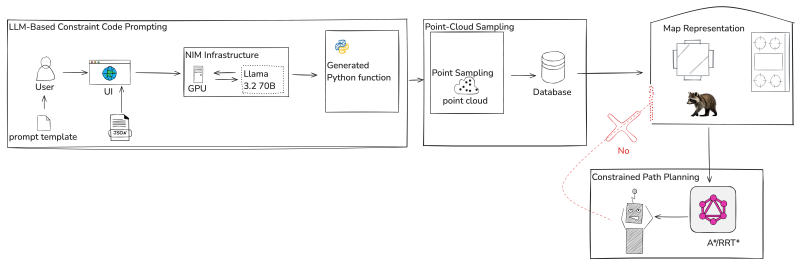
STPR prompts an LLM to produce Python functions that encode spatial, mathematical, and conditional constraints given as natural-language statements of 'what not to do.' These functions are then applied to point-cloud data to score candidate paths, allowing classical search algorithms to return trajectories that satisfy every constraint. Experiments confirm complete compliance in varied Gazebo scenarios, short planning times, and continued effectiveness when smaller LLMs replace larger ones.
What carries the argument
STPR framework that turns LLM-generated Python constraint functions into point-cloud evaluators for use inside classical search planners
If this is right
- Planning stays efficient because the LLM is called only once per constraint set rather than at every planning step.
- Full constraint compliance is achieved without requiring the planner itself to perform symbolic reasoning.
- The method remains practical on compact hardware when smaller code LLMs are substituted.
- Users can add new spatial rules using ordinary language instead of writing custom mathematical code.
Where Pith is reading between the lines
- If the generated functions transfer reliably to noisy real-world sensors, the technique could reduce the engineering effort needed for safe robot deployment.
- Reusable libraries of common constraint functions might emerge, letting new environments inherit safety rules without fresh LLM calls.
- The same code-generation step could feed into optimization-based planners or learned policies instead of pure search.
Load-bearing premise
The large language model will produce correct, executable Python functions that accurately capture the user's intended constraints without logical errors or hallucinations.
What would settle it
A generated function that returns 'valid' for a trajectory the human can see violates one of the stated constraints, such as entering a mathematically forbidden region.
Figures













read the original abstract
Recent advancements in large language models (LLMs) have spurred interest in robotic navigation that incorporates complex spatial, mathematical, and conditional constraints from natural language into the planning problem. Such constraints can be informal yet highly complex, making it challenging to translate into a formal description that can be passed on to a planning algorithm. In this paper, we propose STPR, a constraint generation framework that uses LLMs to translate constraints (expressed as instructions on ``what not to do'') into executable Python functions. STPR leverages the LLM's strong coding capabilities to shift the problem description from language into structured and interpretable code, thus circumventing complex reasoning and avoiding potential hallucinations. We show that these LLM-generated functions accurately describe even complex mathematical constraints, and apply them to point cloud representations with traditional search algorithms. Experiments in a simulated Gazebo environment show that STPR ensures full compliance across several constraints and scenarios, while having short runtimes. We also verify that STPR can be used with smaller code LLMs, making it applicable to a wide range of compact models with low inference cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes STPR, a framework that uses large language models to translate natural-language constraints phrased as 'what not to do' instructions into executable Python functions. These functions are then applied to point-cloud representations of the environment together with traditional search algorithms for embodied navigation. The authors claim that the generated functions accurately capture even complex mathematical constraints, and report that experiments in a Gazebo simulator achieve full compliance across several constraints and scenarios while maintaining short runtimes. The approach is additionally shown to work with smaller code LLMs.
Significance. If the accuracy of the LLM-to-code translation step can be more rigorously established, the work would offer a practical route for incorporating informal yet mathematically complex constraints into robotic planning without manual formalization. Shifting the burden to code generation and then using established search methods is a sensible design choice that may reduce certain classes of hallucination. Demonstrating usability with compact models further increases potential applicability. At present the empirical support remains thin, limiting the assessed significance.
major comments (2)
- Abstract: the claim that the LLM-generated functions 'accurately describe even complex mathematical constraints' is supported only by end-to-end Gazebo compliance and runtime figures; no quantitative accuracy metrics, error rates, constraint-complexity measures, or test-coverage statistics are supplied, leaving the central translation claim only partially evidenced.
- Evaluation (Gazebo experiments): full compliance is reported, yet the manuscript provides no direct verification that the generated Python functions correctly implement the intended point-cloud constraints (e.g., via unit tests, edge-case analysis, or comparison against ground-truth oracles). This gap is load-bearing because simulation success could mask subtle logical errors in the generated code.
minor comments (2)
- The abstract and experimental description would be clearer if a table or appendix listed the specific constraints tested, their mathematical form, and the corresponding compliance/runtimes observed.
- Consider adding one or two concrete examples of LLM-generated Python functions (with the original natural-language constraint) to illustrate the translation quality.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address the major concerns point by point below and describe the revisions that will be incorporated to strengthen the evidence for our claims.
read point-by-point responses
-
Referee: Abstract: the claim that the LLM-generated functions 'accurately describe even complex mathematical constraints' is supported only by end-to-end Gazebo compliance and runtime figures; no quantitative accuracy metrics, error rates, constraint-complexity measures, or test-coverage statistics are supplied, leaving the central translation claim only partially evidenced.
Authors: We agree that the abstract claim currently rests on indirect evidence from end-to-end simulation results. While full compliance in Gazebo across multiple scenarios and constraints demonstrates practical utility, direct quantitative assessment of the LLM-to-code translation would provide stronger support. In the revised manuscript we will add a new evaluation subsection that reports (i) the fraction of generated functions that pass manual correctness review against the natural-language intent, (ii) a simple complexity measure (e.g., number of mathematical operations and conditional branches) for each tested constraint, and (iii) success rates when the same prompts are given to the smaller code LLMs already evaluated in the paper. revision: yes
-
Referee: Evaluation (Gazebo experiments): full compliance is reported, yet the manuscript provides no direct verification that the generated Python functions correctly implement the intended point-cloud constraints (e.g., via unit tests, edge-case analysis, or comparison against ground-truth oracles). This gap is load-bearing because simulation success could mask subtle logical errors in the generated code.
Authors: The referee correctly notes that end-to-end compliance does not isolate potential errors inside the generated constraint functions. We will therefore augment the evaluation section with direct verification: (a) unit tests executed on synthetic point clouds that exercise both nominal and edge-case inputs for each constraint, (b) explicit comparison of a representative subset of LLM-generated functions against hand-written oracle implementations, and (c) reporting of any discrepancies found. These additions will be presented alongside the existing Gazebo results so that readers can assess both system-level and function-level correctness. revision: yes
Circularity Check
No significant circularity; evaluation uses independent simulator and traditional algorithms
full rationale
The paper's core chain translates natural-language constraints into LLM-generated Python functions, then applies those functions to point-cloud data via standard search algorithms inside an external Gazebo simulator. Compliance results are measured against the simulator's independent dynamics rather than any fitted parameter or self-referential definition internal to the paper. No equations, ansatzes, or uniqueness theorems are invoked that reduce the accuracy claim to a prior fit or self-citation by construction. The reported evidence (full compliance and short runtimes) is therefore externally falsifiable and does not collapse into the input generation step.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models can translate informal natural-language constraints into accurate executable Python code without hallucinations or logical errors.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
STPR employs LLMs to translate high-level natural language constraints into executable Python boolean functions... applied to point cloud representations with traditional search algorithms (A*, RRT*)
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We show that these LLM-generated functions accurately describe even complex mathematical constraints
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
Sparks of Artificial General Intelligence: Early experiments with GPT-4
S. Bubeck, V . Chandrasekaran, R. Eldan, J. Gehrke, E. Horvitz, E. Kamar, P. Lee, Y . T. Lee, Y . Li, S. Lundberg, et al. Sparks of Artificial General Intelligence: Early Experiments with GPT-4. arXiv preprint arXiv:2303.12712, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [3]
-
[4]
Evaluation of openai o1: Opportunities and challenges of agi,
T. Zhong, Z. Liu, Y . Pan, Y . Zhang, Y . Zhou, S. Liang, Z. Wu, Y . Lyu, P. Shu, X. Yu, et al. Evaluation of OpenAI o1: Opportunities and Challenges of AGI. arXiv preprint arXiv:2409.18486, 2024
-
[5]
S. Chib and E. Greenberg. Understanding the Metropolis-Hastings Algorithm. The american statistician, 49(4):327–335, 1995
work page 1995
-
[6]
P. E. Hart, N. J. Nilsson, and B. Raphael. A Formal Basis for the Heuristic Determination of Minimum Cost Paths. Systems Science and Cybernetics, IEEE Transactions on, 4(2):100–107, 1968
work page 1968
-
[7]
S. Karaman and E. Frazzoli. Sampling-Based Algorithms for Optimal Motion Planning. Int. J. Robot. Res.(IJRR), 30(7):846–894, 2011
work page 2011
-
[8]
N. Koenig and A. Howard. Design and Use Paradigms for Gazebo, an Open-Source Multi-Robot Simulator. In Proc. of IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), volume 3, pages 2149–2154 vol.3, 2004. doi:10.1109/IROS.2004.1389727
-
[9]
C. R. Qi, H. Su, K. Mo, and L. J. Guibas. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proc. of IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 652–660, 2017
work page 2017
-
[10]
S. Shi, X. Wang, and H. Li. PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud. In Proc. of IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 770–779, 2019
work page 2019
-
[11]
W. R. Gilks and P. Wild. Adaptive Rejection Sampling for Gibbs Sampling. Journal of the Royal Statistical Society: Series C (Applied Statistics), 41(2):337–348, 1992
work page 1992
-
[12]
J. L. Bentley. Multidimensional Binary Search Trees Used for Associative Searching. Commun. ACM, 18(9):509–517, Sept. 1975. ISSN 0001-0782. doi:10.1145/361002.361007. URL https: //doi.org/10.1145/361002.361007
-
[13]
J. D. Gammell, S. S. Srinivasa, and T. D. Barfoot. Informed RRT*: Optimal Sampling-Based Path Planning Focused via Direct Sampling of an Admissible Ellipsoidal Heuristic. In Proc. of IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 2997–3004. IEEE, 2014
work page 2014
-
[14]
Y . Li, Z. Littlefield, and K. E. Bekris. Asymptotically Optimal Sampling-Based Kinodynamic Planning. Int. J. Robot. Res.(IJRR), 35(5):528–564, 2016
work page 2016
-
[15]
D. Fox, W. Burgard, and S. Thrun. The Dynamic Window Approach to Collision Avoidance. IEEE Robotics & Automation Magazine, 4(1):23–33, 1997
work page 1997
-
[16]
S. Macenski and I. Jambrecic. SLAM Toolbox: SLAM for the Dynamic World. Journal of Open Source Software, 6:2783, 05 2021. doi:10.21105/joss.02783
-
[17]
NVIDIA. Isaac ROS Visual SLAM , 2025. URL https://nvidia-isaac-ros.github.io/ repositories_and_packages/isaac_ros_visual_slam/index.html. Accessed: 2025-04-09
work page 2025
-
[18]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughan, et al. The Llama 3 Herd of Models. arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Cox, Ruchir Puri, and Rameswar Panda
M. Mishra, M. Stallone, G. Zhang, Y . Shen, A. Prasad, A. M. Soria, M. Merler, P. Selvam, S. Suren- dran, S. Singh, et al. Granite Code Models: A Family of Open Foundation Models for Code Intelligence. arXiv preprint arXiv:2405.04324, 2024. 10
-
[20]
R. E. Fikes, P. E. Hart, and N. J. Nilsson. Learning and Executing Generalized Robot Plans.Artificial Intelligence, 3(1-3):251–288, 1972. doi:10.1016/0004-3702(72)90051-3
-
[21]
M. Ahn, A. Brohan, N. Brown, Y . Chebotar, O. Cortes, B. David, C. Finn, C. Fu, K. Gopalakrishnan, K. Hausman, et al. Do As I Can and Not As I Say: Grounding Language in Robotic Affordances. In Proc. of Conference on Robot Learning, pages 287–318. PMLR, 2023
work page 2023
-
[22]
B. Liu, Y . Jiang, X. Zhang, Q. Liu, S. Zhang, J. Biswas, and P. Stone. LLM+P: Empowering Large Language Models with Optimal Planning Proficiency. arXiv preprint arXiv:2304.11477, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [23]
-
[24]
Y . Chen, J. Arkin, C. Dawson, Y . Zhang, N. Roy, and C. Fan. AutoTAMP: Autoregressive Task and Motion Planning with LLMs as Translators and Checkers. In Proc. of IEEE International Conference on Robotics and Automaton (ICRA), pages 6695–6702. IEEE, 2024
work page 2024
-
[25]
Y . Hao, Y . Zhang, and C. Fan. Planning Anything with Rigor: General-Purpose Zero-Shot Planning with LLM-based Formalized Programming. In Proc. of the International Conference on Learning Representations (ICLR), 2025. URL https://openreview.net/forum?id=0K1OaL6XuK
work page 2025
-
[26]
M. Katz, H. Kokel, K. Srinivas, and S. Sohrabi Araghi. Thought of Search: Planning with Language Models Through the Lens of Efficiency. Proc. of the Advances in Neural Information Processing Systems (Neurips), 37:138491–138568, 2024
work page 2024
-
[27]
W. Guo, Z. K. Kingston, and L. E. Kavraki. CaStL: Constraints as Specifications through LLM Translation for Long-Horizon Task and Motion Planning. In Proc. of the Advances in Neural Information Processing Systems (Neurips), 2024
work page 2024
- [28]
-
[29]
L. Blackmore, M. Ono, and B. C. Williams. Chance-Constrained Optimal Path Planning with Obstacles. IEEE Transactions on Robotics, 27(6):1080–1094, 2011
work page 2011
- [30]
-
[31]
C. Peng, F. Xia, M. Naseriparsa, and F. Osborne. Knowledge Graphs: Opportunities and Challenges. Artificial Intelligence Review, 56(11):13071–13102, 2023
work page 2023
-
[32]
S. M. LaValle and J. J. Kuffner. Randomized Kinodynamic Planning. IJRR, 20(5):378–400, 2001
work page 2001
-
[33]
P. Cheng and S. M. LaValle. Resolution Complete Rapidly-Exploring Random Trees. In Proc. of IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , volume 1, pages 267–272. IEEE, 2002
work page 2002
-
[34]
O. Salzman and D. Halperin. Asymptotically Near-Optimal RRT for Fast, High-Quality Motion Planning. IEEE Transactions on Robotics, 32(3):473–483, 2016. 11 A Naive LLM-Based Planning This section describes the details of naive end-to-end LLM-based path generation. Fig. 5 and Fig. 6 show the annotated image and the corresponding prompt used for scenario (S1...
work page 2016
-
[35]
Select a random state xrand from the entire free space X ,
-
[36]
Select the nearest neighbor xnearest of xrand from the set of nodes of the tree, 19
-
[37]
Generate a new state xnew by generating a collision-free path from xnearest to xrand using a local planner
-
[38]
Add an edge (xnearest, xnew) to the tree
-
[39]
Terminate if xnew satisfies a goal criteria (e.g., proximity to a goal state xgoal). In RRT*, Step 4 instead adds an edge from one of the nodes already in the tree that are close to xnew (within a dynamically shrinking radius as a function of |V |) and has the smallest cost from the root, if the cost is smaller than that of xnearest. Goal-biased sampling ...
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.