Towards Reasonable Concept Bottleneck Models
Pith reviewed 2026-05-19 11:11 UTC · model grok-4.3
The pith
CREAM models let users bake concept relationships directly into the architecture of concept bottleneck models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CREAMs extend standard concept bottleneck models by architecturally encoding arbitrary C-C relationships such as mutual exclusivity or hierarchical associations together with potentially sparse C to Y mappings, and they optionally add a regularized side-channel that lets the model reach black-box accuracy under missing concepts while keeping predictions concept-grounded.
What carries the argument
The CREAM architecture that directly wires known concept-concept and concept-task relationships into the model's reasoning layers, plus an optional regularized side-channel for incomplete concept sets.
If this is right
- Direct interventions on concepts become more efficient because the model already respects the encoded relationships.
- Concept leakage is reduced because the architecture prevents the model from bypassing the concept layer.
- Task performance stays competitive with black-box models even when only a subset of concepts is observed.
- Predictions remain more interpretable because the side-channel is regularized and the core reasoning stays concept-grounded.
Where Pith is reading between the lines
- The same wiring approach could be applied to other bottleneck-style architectures beyond classification, such as regression or generative tasks.
- If the encoded relationships turn out to be only approximately correct, the side-channel might still allow graceful degradation rather than catastrophic failure.
- Future work could test whether automatically discovering and then wiring the relationships produces similar gains without requiring manual prior knowledge.
Load-bearing premise
Practitioners already know the correct concept-concept and concept-task relationships and can encode them accurately without adding new errors.
What would settle it
An experiment in which the encoded relationships are deliberately set to incorrect values and the model is then checked for drops in task accuracy, failed interventions, or increased concept leakage compared with a standard CBM.
Figures










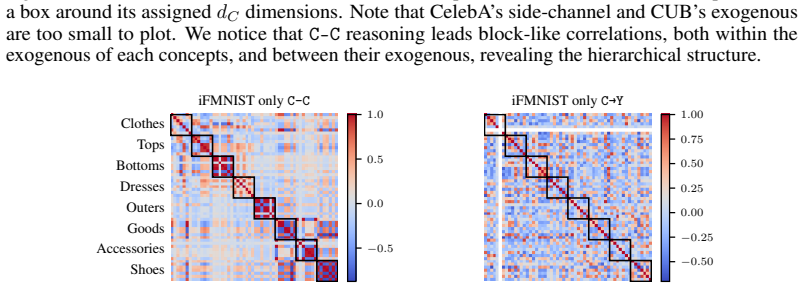






read the original abstract
We propose a novel, flexible, and efficient framework for designing Concept Bottleneck Models (CBMs) that enables practitioners to explicitly encode and extend their prior knowledge and beliefs about the concept-concept ($C-C$) and concept-task ($C \to Y$) relationships within the model's reasoning when making predictions. The resulting $\textbf{C}$oncept $\textbf{REA}$soning $\textbf{M}$odels (CREAMs) architecturally encode arbitrary types of $C-C$ relationships such as mutual exclusivity, hierarchical associations, and/or correlations, as well as potentially sparse $C \to Y$ relationships. Moreover, CREAM can optionally incorporate a regularized side-channel to complement the potentially {incomplete concept sets}, achieving competitive task performance while encouraging predictions to be concept-grounded. To evaluate CBMs in such settings, we introduce a $C \to Y$ agnostic metric that quantifies interpretability when predictions partially rely on the side-channel. In our experiments, we show that, without additional computational overhead, CREAM models support efficient interventions, can avoid concept leakage, and achieve black-box-level performance under missing concepts. We further analyze how an optional side-channel affects interpretability and intervenability. Importantly, the side-channel enables CBMs to remain effective even in scenarios where only a limited number of concepts are available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Concept REAsoning Models (CREAMs), a flexible extension of Concept Bottleneck Models that architecturally encodes prior knowledge on arbitrary C-C relationships (mutual exclusivity, hierarchies, correlations) and sparse C→Y links. It introduces an optional regularized side-channel to handle incomplete concept sets while encouraging concept-grounded predictions, along with a new C→Y agnostic metric for interpretability. Experiments claim that CREAM supports efficient interventions, avoids concept leakage, achieves black-box-level task performance under missing concepts, and remains effective with limited concepts, all without added computational overhead.
Significance. If the central claims hold, this work offers a practical way to inject domain knowledge into CBMs via architecture rather than post-hoc constraints, addressing a key limitation when concept sets are incomplete. The side-channel plus regularization and the new metric could improve both performance and evaluable interpretability in real-world settings. The manuscript's strengths include explicit handling of prior relationships and analysis of side-channel effects on intervenability.
major comments (2)
- [§3] The central claim that architectural encoding of C-C and C→Y priors plus side-channel regularization forces predictions to remain concept-grounded (even with missing concepts) is load-bearing for the 'avoid concept leakage' and 'black-box-level performance' assertions, yet §3 provides no derivation or constraint showing that the chosen regularization term mathematically prevents the side-channel from learning non-concept shortcuts.
- [§4.3] Table 2 and §4.3: the reported competitive performance and intervention results lack quantitative baselines, effect sizes, and cross-dataset behavior of the new C→Y agnostic metric, leaving the claim of black-box-level performance under missing concepts insufficiently verified.
minor comments (2)
- [Abstract] The abstract states 'without additional computational overhead' but this is not supported by explicit runtime or parameter counts in the experiments section.
- [§3.2] Notation for the side-channel regularization strength (listed as a free parameter) should be defined consistently with the loss term in Eq. (X) of §3.2.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address the major concerns regarding the theoretical justification for the side-channel regularization and the empirical validation of our results and metric.
read point-by-point responses
-
Referee: [§3] The central claim that architectural encoding of C-C and C→Y priors plus side-channel regularization forces predictions to remain concept-grounded (even with missing concepts) is load-bearing for the 'avoid concept leakage' and 'black-box-level performance' assertions, yet §3 provides no derivation or constraint showing that the chosen regularization term mathematically prevents the side-channel from learning non-concept shortcuts.
Authors: We agree that a formal mathematical derivation would provide stronger theoretical support. The regularization term is designed to minimize the side-channel's influence on the final prediction by penalizing deviations from concept-based reasoning. While we do not claim a hard constraint that completely eliminates shortcuts, the combination with the architectural priors encourages grounded predictions, as evidenced by our intervention experiments and leakage analyses. We will revise §3 to include a more detailed explanation of the regularization's intended effect and discuss its limitations in preventing all possible shortcuts. revision: partial
-
Referee: [§4.3] Table 2 and §4.3: the reported competitive performance and intervention results lack quantitative baselines, effect sizes, and cross-dataset behavior of the new C→Y agnostic metric, leaving the claim of black-box-level performance under missing concepts insufficiently verified.
Authors: We appreciate this point and will enhance the presentation in §4.3 and Table 2 by including quantitative baselines from standard CBMs and black-box models, along with effect sizes for the performance differences. Additionally, we will report the behavior of the C→Y agnostic metric across multiple datasets to better substantiate the interpretability claims under incomplete concept sets. revision: yes
Circularity Check
CREAM proposal introduces explicit architectural priors and a new agnostic metric; performance claims rest on external benchmarks rather than self-referential fits or definitions.
full rationale
The paper's core contribution is a new modeling framework that takes practitioner-provided C-C and C-Y relationships as explicit inputs and encodes them directly into the architecture (mutual exclusivity, hierarchies, sparse links, optional regularized side-channel). These encodings are not derived from the evaluation data; they are user-specified priors. The introduced C→Y agnostic metric is defined to measure reliance on the side-channel and is not fitted to the same performance numbers used to claim black-box-level results. Experiments compare against baselines on standard datasets, with no evidence that any reported prediction or grounding property reduces by construction to a parameter fit on the test set or to a self-citation chain. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- side-channel regularization strength
axioms (1)
- domain assumption Practitioners can accurately specify C-C and C-to-Y relationships
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/LogicAsFunctionalEquation.leanSatisfiesLawsOfLogic / Translation Theorem unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
CREAM architecturally embeds (bi)directed concept-concept, and concept to task relationships specified by a human expert, while severing undesired information flows... using StrNN binary masks
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel / Jcost uniqueness unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Regularization of side-channel... dropout based regularization strategy... CCI = ϕc / (ϕc + ϕy)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Towards robust interpretability with self-explaining neural networks
David Alvarez Melis and Tommi Jaakkola. Towards robust interpretability with self-explaining neural networks. Advances in neural information processing systems, 2018
work page 2018
-
[2]
The description logic handbook: Theory, implementation and applications
Franz Baader. The description logic handbook: Theory, implementation and applications . Cambridge university press, 2003
work page 2003
-
[3]
Samy Badreddine, Artur d’Avila Garcez, Luciano Serafini, and Michael Spranger. Logic tensor networks. Artificial Intelligence, 2022
work page 2022
-
[4]
Interpretable neural-symbolic concept reasoning
Pietro Barbiero, Gabriele Ciravegna, Francesco Giannini, Mateo Espinosa Zarlenga, Lucie Char- lotte Magister, Alberto Tonda, Pietro Lió, Frederic Precioso, Mateja Jamnik, and Giuseppe Marra. Interpretable neural-symbolic concept reasoning. In International Conference on Machine Learning. PMLR, 2023
work page 2023
-
[5]
Relational concept bottleneck models
Pietro Barbiero, Francesco Giannini, Gabriele Ciravegna, Michelangelo Diligenti, and Giuseppe Marra. Relational concept bottleneck models. In Advances in Neural Information Processing Systems, 2024
work page 2024
-
[6]
Estimating or propagating gradients through stochastic neurons for conditional computation
Yoshua Bengio, Nicholas Léonard, and Aaron Courville. Estimating or propagating gradients through stochastic neurons for conditional computation. ArXiv, 2013
work page 2013
-
[7]
A neuro-symbolic benchmark suite for concept quality and reasoning shortcuts
Samuele Bortolotti, Emanuele Marconato, Tommaso Carraro, Paolo Morettin, Emile van Krieken, Antonio Vergari, Stefano Teso, Andrea Passerini, et al. A neuro-symbolic benchmark suite for concept quality and reasoning shortcuts. Advances in neural information processing systems, 2024
work page 2024
-
[8]
Shortcuts and identifiability in concept-based models from a neuro-symbolic lens
Samuele Bortolotti, Emanuele Marconato, Paolo Morettin, Andrea Passerini, and Stefano Teso. Shortcuts and identifiability in concept-based models from a neuro-symbolic lens. ArXiv, 2025
work page 2025
- [9]
-
[10]
Structured neural networks for density estimation and causal inference
Asic Chen, Ruian Ian Shi, Xiang Gao, Ricardo Baptista, and Rahul G Krishnan. Structured neural networks for density estimation and causal inference. Advances in Neural Information Processing Systems, 2024
work page 2024
-
[11]
Concept whitening for interpretable image recognition
Zhi Chen, Yijie Bei, and Cynthia Rudin. Concept whitening for interpretable image recognition. Nature Machine Intelligence, 2020
work page 2020
-
[12]
Understanding global feature contributions with additive importance measures
Ian Covert, Scott M Lundberg, and Su-In Lee. Understanding global feature contributions with additive importance measures. Advances in Neural Information Processing Systems, 2020
work page 2020
-
[13]
Roxana Daneshjou, Mert Yuksekgonul, Zhuo Ran Cai, Roberto Novoa, and James Y Zou. Skincon: A skin disease dataset densely annotated by domain experts for fine-grained debugging and analysis. In Advances in Neural Information Processing Systems, 2022
work page 2022
-
[14]
Causally reliable concept bottleneck models
Giovanni De Felice, Arianna Casanova Flores, Francesco De Santis, Silvia Santini, Johannes Schneider, Pietro Barbiero, and Alberto Termine. Causally reliable concept bottleneck models. ArXiv, 2025
work page 2025
-
[15]
Causal concept graph models: Beyond causal opacity in deep learning
Gabriele Dominici, Pietro Barbiero, Mateo Espinosa Zarlenga, Alberto Termine, Martin Gjoreski, Giuseppe Marra, and Marc Langheinrich. Causal concept graph models: Beyond causal opacity in deep learning. In International Conference on Learning Representations , 2025
work page 2025
-
[16]
Towards a rigorous science of interpretable machine learning
Finale Doshi-Velez and Been Kim. Towards a rigorous science of interpretable machine learning. ArXiv, 2017. 10
work page 2017
-
[17]
Aaron Fisher, Cynthia Rudin, and Francesca Dominici. All models are wrong, but many are useful: Learning a variable’s importance by studying an entire class of prediction models simultaneously. Journal of Machine Learning Research, 2019
work page 2019
-
[18]
Interpretable prognostics with concept bottleneck models
Florent Forest, Katharina Rombach, and Olga Fink. Interpretable prognostics with concept bottleneck models. ArXiv, 2024
work page 2024
-
[19]
Shortcut learning in deep neural networks
Robert Geirhos, Jörn-Henrik Jacobsen, Claudio Michaelis, Richard Zemel, Wieland Brendel, Matthias Bethge, and Felix A Wichmann. Shortcut learning in deep neural networks. Nature Machine Intelligence, 2020
work page 2020
-
[20]
Taming the sigmoid bottleneck: Provably argmaxable sparse multi-label classification
Andreas Grivas, Antonio Vergari, and Adam Lopez. Taming the sigmoid bottleneck: Provably argmaxable sparse multi-label classification. InProceedings of the AAAI Conference on Artificial Intelligence, 2024
work page 2024
-
[21]
Addressing leakage in concept bottleneck models
Marton Havasi, Sonali Parbhoo, and Finale Doshi-Velez. Addressing leakage in concept bottleneck models. Advances in Neural Information Processing Systems, 2022
work page 2022
-
[22]
Naoki Hayashi and Yoshihide Sawada. Upper bound of bayesian generalization error in partial concept bottleneck model (cbm): Partial cbm outperforms naive cbm. ArXiv, 2024
work page 2024
-
[23]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Conference on Computer Vision and Pattern Recognition, 2016
work page 2016
-
[24]
Deep networks with stochastic depth
Gao Huang, Yu Sun, Zhuang Liu, Daniel Sedra, and Kilian Q Weinberger. Deep networks with stochastic depth. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part IV 14. Springer, 2016
work page 2016
-
[25]
Causal normalizing flows: from theory to practice
Adrián Javaloy, Pablo Sánchez-Martín, and Isabel Valera. Causal normalizing flows: from theory to practice. Advances in Neural Information Processing Systems, 2024
work page 2024
-
[26]
Adam: A method for stochastic optimization
Diederik P Kingma. Adam: A method for stochastic optimization. ArXiv, 2014
work page 2014
-
[27]
Pang Wei Koh, Thao Nguyen, Yew Siang Tang, Stephen Mussmann, Emma Pierson, Been Kim, and Percy Liang. Concept bottleneck models. In International conference on machine learning. PMLR, 2020
work page 2020
-
[28]
Himabindu Lakkaraju and Osbert Bastani. " how do i fool you?" manipulating user trust via misleading black box explanations. In ACM Conference on AI, Ethics, and Society, 2020
work page 2020
-
[29]
Zachary C Lipton. The mythos of model interpretability: In machine learning, the concept of interpretability is both important and slippery. Queue, 2018
work page 2018
-
[30]
Deep learning face attributes in the wild
Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang. Deep learning face attributes in the wild. In International Conference on Computer Vision, 2015
work page 2015
-
[31]
Towards learning to explain with concept bottleneck models: mitigating information leakage
Joshua Lockhart, Nicolas Marchesotti, Daniele Magazzeni, and Manuela Veloso. Towards learning to explain with concept bottleneck models: mitigating information leakage. ArXiv, 2022
work page 2022
-
[32]
Promises and pitfalls of black-box concept learning models
Anita Mahinpei, Justin Clark, Isaac Lage, Finale Doshi-Velez, and Weiwei Pan. Promises and pitfalls of black-box concept learning models. ArXiv, 2021
work page 2021
-
[33]
Measuring leakage in concept-based methods: An information theoretic approach
Mikael Makonnen, Moritz Vandenhirtz, Sonia Laguna, and Julia E V ogt. Measuring leakage in concept-based methods: An information theoretic approach. In ICLR 2025 Workshop: XAI4Science: From Understanding Model Behavior to Discovering New Scientific Knowledge, 2025
work page 2025
-
[34]
Deepproblog: Neural probabilistic logic programming
Robin Manhaeve, Sebastijan Dumancic, Angelika Kimmig, Thomas Demeester, and Luc De Raedt. Deepproblog: Neural probabilistic logic programming. Advances in neural informa- tion processing systems, 2018
work page 2018
-
[35]
Glancenets: Interpretable, leak-proof concept-based models
Emanuele Marconato, Andrea Passerini, and Stefano Teso. Glancenets: Interpretable, leak-proof concept-based models. Advances in Neural Information Processing Systems, 2022
work page 2022
-
[36]
Emanuele Marconato, Andrea Passerini, and Stefano Teso. Interpretability is in the mind of the beholder: A causal framework for human-interpretable representation learning. Entropy, 2023
work page 2023
-
[37]
Not all neuro- symbolic concepts are created equal: Analysis and mitigation of reasoning shortcuts
Emanuele Marconato, Stefano Teso, Antonio Vergari, and Andrea Passerini. Not all neuro- symbolic concepts are created equal: Analysis and mitigation of reasoning shortcuts. Advances in Neural Information Processing Systems, 2023. 11
work page 2023
-
[38]
Do concept bottleneck models learn as intended? ArXiv, 2021
Andrei Margeloiu, Matthew Ashman, Umang Bhatt, Yanzhi Chen, Mateja Jamnik, and Adrian Weller. Do concept bottleneck models learn as intended? ArXiv, 2021
work page 2021
-
[39]
Interpretable Machine Learning
Christoph Molnar. Interpretable Machine Learning. 3 edition, 2025. ISBN 978-3-911578-03-5. URL https://christophm.github.io/interpretable-ml-book
work page 2025
-
[40]
Tuomas Oikarinen, Subhro Das, Lam M. Nguyen, and Tsui-Wei Weng. Label-free concept bottleneck models. In International Conference on Learning Representations, 2023
work page 2023
-
[41]
Pytorch: An imperative style, high-performance deep learning library
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library. Advances in neural information processing systems, 2019
work page 2019
-
[42]
J. Pearl. Causality. Causality: Models, Reasoning, and Inference. Cambridge Univer- sity Press, 2009. ISBN 9780521895606. URL https://books.google.de/books?id= f4nuexsNVZIC
work page 2009
-
[43]
Concept- based explainable artificial intelligence: A survey
Eleonora Poeta, Gabriele Ciravegna, Eliana Pastor, Tania Cerquitelli, and Elena Baralis. Concept- based explainable artificial intelligence: A survey. ArXiv, 2023
work page 2023
-
[44]
Tree-based leakage inspection and control in concept bottleneck models
Angelos Ragkousis and Sonali Parbhoo. Tree-based leakage inspection and control in concept bottleneck models. ArXiv, 2024
work page 2024
-
[45]
From causal to concept-based representation learning
Goutham Rajendran, Simon Buchholz, Bryon Aragam, Bernhard Schölkopf, and Pradeep Ravikumar. From causal to concept-based representation learning. Advances in Neural Infor- mation Processing Systems, 37:101250–101296, 2024
work page 2024
-
[46]
Zuko: Normalizing flows in pytorch, 2022
François Rozet et al. Zuko: Normalizing flows in pytorch, 2022. URL https://pypi.org/ project/zuko
work page 2022
-
[47]
Cynthia Rudin. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. Nature machine intelligence, 2019
work page 2019
-
[48]
Interpretable machine learning: Fundamental principles and 10 grand challenges
Cynthia Rudin, Chaofan Chen, Zhi Chen, Haiyang Huang, Lesia Semenova, and Chudi Zhong. Interpretable machine learning: Fundamental principles and 10 grand challenges. Statistic Surveys, 2022
work page 2022
-
[49]
Explainable AI: interpreting, explaining and visualizing deep learning
Wojciech Samek, Grégoire Montavon, Andrea Vedaldi, Lars Kai Hansen, and Klaus-Robert Müller. Explainable AI: interpreting, explaining and visualizing deep learning. Springer Nature, 2019
work page 2019
-
[50]
Improving the interpretability of gnn predictions through conformal-based graph sparsification
Pablo Sanchez-Martin, Kinaan Aamir Khan, and Isabel Valera. Improving the interpretability of gnn predictions through conformal-based graph sparsification. ArXiv, 2024
work page 2024
-
[51]
Concept bottleneck model with additional unsuper- vised concepts
Yoshihide Sawada and Keigo Nakamura. Concept bottleneck model with additional unsuper- vised concepts. IEEE Access, 2022
work page 2022
-
[52]
Hierarchical convolutional neural networks for fashion image classification
Yian Seo and Kyung-shik Shin. Hierarchical convolutional neural networks for fashion image classification. Expert systems with applications, 2019
work page 2019
- [53]
-
[54]
Auxiliary losses for learning generalizable concept- based models
Ivaxi Sheth and Samira Ebrahimi Kahou. Auxiliary losses for learning generalizable concept- based models. Advances in Neural Information Processing Systems, 2023
work page 2023
-
[55]
A closer look at the intervention procedure of concept bottleneck models
Sungbin Shin, Yohan Jo, Sungsoo Ahn, and Namhoon Lee. A closer look at the intervention procedure of concept bottleneck models. In International Conference on Machine Learning. PMLR, 2023
work page 2023
-
[56]
Colidr: Concept learning using aggre- gated disentangled representations
Sanchit Sinha, Guangzhi Xiong, and Aidong Zhang. Colidr: Concept learning using aggre- gated disentangled representations. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2024
work page 2024
-
[57]
Ao Sun, Yuanyuan Yuan, Pingchuan Ma, and Shuai Wang. Eliminating information leakage in hard concept bottleneck models with supervised, hierarchical concept learning. ArXiv, 2024
work page 2024
-
[58]
Stochastic concept bottleneck models
Moritz Vandenhirtz, Sonia Laguna, Riˇcards Marcinkeviˇcs, and Julia V ogt. Stochastic concept bottleneck models. Advances in Neural Information Processing Systems, 2024
work page 2024
-
[59]
C. Wah, S. Branson, P. Welinder, P. Perona, and S. Belongie. The caltech-ucsd birds-200-2011 dataset. Technical Report CNS-TR-2011-001, California Institute of Technology, 2011. 12
work page 2011
-
[60]
Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms, 2017
Han Xiao, Kashif Rasul, and Roland V ollgraf. Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms, 2017
work page 2017
-
[61]
A study of face obfuscation in imagenet
Kaiyu Yang, Jacqueline H Yau, Li Fei-Fei, Jia Deng, and Olga Russakovsky. A study of face obfuscation in imagenet. In International Conference on Machine Learning. PMLR, 2022
work page 2022
-
[62]
Yue Yang, Artemis Panagopoulou, Shenghao Zhou, Daniel Jin, Chris Callison-Burch, and Mark Yatskar. Language in a bottle: Language model guided concept bottlenecks for interpretable image classification. In Conference on Computer Vision and Pattern Recognition, 2023
work page 2023
-
[63]
On completeness-aware concept-based explanations in deep neural networks
Chih-Kuan Yeh, Been Kim, Sercan Arik, Chun-Liang Li, Tomas Pfister, and Pradeep Ravikumar. On completeness-aware concept-based explanations in deep neural networks. Advances in neural information processing systems, 2020
work page 2020
-
[64]
Post-hoc concept bottleneck models
Mert Yuksekgonul, Maggie Wang, and James Zou. Post-hoc concept bottleneck models. In International Conference on Learning Representations, 2023
work page 2023
-
[65]
Benchmarking and enhancing disentanglement in concept-residual models
Renos Zabounidis, Ini Oguntola, Konghao Zhao, Joseph Campbell, Simon Stepputtis, and Katia Sycara. Benchmarking and enhancing disentanglement in concept-residual models. ArXiv, 2023
work page 2023
-
[66]
A survey on causal discovery: Theory and practice
Alessio Zanga, Elif Ozkirimli, and Fabio Stella. A survey on causal discovery: Theory and practice. International Journal of Approximate Reasoning, 2022
work page 2022
-
[67]
Mateo Espinosa Zarlenga, Pietro Barbiero, Gabriele Ciravegna, Giuseppe Marra, Francesco Giannini, Michelangelo Diligenti, Frederic Precioso, Stefano Melacci, Adrian Weller, Pietro Lio, et al. Concept embedding models. In Advances in Neural Information Processing Systems, 2022. 13 A Structured Neural Networks for Concept-Concept and Concept-Task Relationsh...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.