Vision-Language Models Mistake Head Orientation for Gaze Direction: Nonverbal Conversation Cues
Pith reviewed 2026-05-19 10:47 UTC · model grok-4.3
The pith
Vision-language models rely on head orientation rather than eye appearance to infer gaze direction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By photographing 1,360 scenes in which a person gazes at one of several table objects while head orientation is directed toward the target, toward a distractor, or left unconstrained, the work shows that vision-language models infer gaze direction primarily from head orientation rather than from eye appearance, producing errors exactly when the two cues conflict.
What carries the argument
A custom dataset of 1,360 real-world photos that varies head orientation independently of gaze target to isolate reliance on head pose versus eye appearance.
If this is right
- VLMs will err on gaze inference whenever head direction conflicts with the true eye direction.
- The source of the error lies in the statistics of existing training data rather than in model architecture.
- Targeted finetuning on data that highlights eye cues can begin to reduce the reliance on head orientation.
- Technologies that interpret gaze targets will need to overcome this bias to support efficient, natural interactions with humans.
Where Pith is reading between the lines
- The same head-pose shortcut may affect other fine-grained visual judgments that require distinguishing coarse body cues from detailed facial features.
- Datasets containing deliberate mismatches between head pose and eye direction could be used to retrain models and measure whether the bias generalizes across architectures.
- These results suggest a broader need for training data that emphasizes eye-level signals in any social-scene understanding task.
Load-bearing premise
The controlled variation in head orientation across the 1,360 photos isolates the contribution of head direction from eye appearance without introducing other uncontrolled visual cues that the models might exploit.
What would settle it
If a vision-language model given only the eye region (head masked or cropped) reaches human-level accuracy on the same gaze targets, this would indicate that eye appearance is sufficient and head orientation is not the dominant cue used.
Figures


















read the original abstract
Where someone looks is a nonverbal communication cue that children and adults readily use. How well can Vision-Language Models (VLMs) infer gaze targets? To construct evaluation stimuli, we captured 1,360 real-world photos of scenes in which a person gazes at one of several objects on a table. Importantly, we also controlled the gazer's head orientation: sometimes it was directed toward the gaze target, sometimes toward a distractor object, and sometimes left unconstrained. We found a substantial performance gap between VLMs and humans, ruled out alternative explanations such as resolution and object-naming skills, and identified the main reason for the gap as VLMs inferring gaze direction using head orientation rather than eye appearance. Such a bias is likely due to data rather than architecture, as suggested by a proof-of-concept experiment finetuning a transformer-based vision model. Future work should investigate whether these findings hold broadly across various deep learning methods trained on existing data, and whether better data mitigates this problem for all architectures. Pinpointing the reason sets the stage for technologies that can interpret gaze targets to have more efficient interactions with humans.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates Vision-Language Models (VLMs) on inferring gaze targets from 1,360 real-world photos of a person gazing at objects on a table. Head orientation is controlled across three conditions (toward target, toward distractor, unconstrained) while collecting human baselines. The authors report a substantial VLM-human performance gap, rule out confounds such as resolution and object naming, and attribute the gap to VLMs relying on head orientation rather than eye appearance. A proof-of-concept finetuning experiment on a transformer vision model is included to suggest the bias is data-driven rather than architectural.
Significance. If the attribution to head-orientation reliance holds after tighter controls, the result is significant for human-AI interaction research: it isolates a concrete failure mode in processing nonverbal cues and points to data curation as a remedy. The use of real photos with explicit condition variation and human comparison strengthens the empirical contribution over purely synthetic benchmarks.
major comments (1)
- [Abstract / Stimulus Construction] Abstract and stimulus-construction description: the central claim that VLMs infer gaze from head orientation rather than eye appearance requires that the three head-orientation conditions vary head direction while holding eye appearance and all other visual features fixed. In real photographs, turning the head toward a distractor while directing gaze at the target necessarily alters body angle, facial shadowing, and the projected shape of the eyes relative to the camera. No measurements or additional controls confirming that remaining variance is carried only by the intended head-orientation cue are reported, weakening the causal attribution.
minor comments (1)
- [Abstract] The abstract states that resolution and object-naming confounds were ruled out but does not specify the exact tests, stimuli, or statistical thresholds used; adding these details would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for recognizing the empirical contribution of our real-world stimulus set and human baselines. We address the major comment on stimulus construction below, agreeing that additional quantification would strengthen the causal claims, and outline the planned revisions.
read point-by-point responses
-
Referee: [Abstract / Stimulus Construction] Abstract and stimulus-construction description: the central claim that VLMs infer gaze from head orientation rather than eye appearance requires that the three head-orientation conditions vary head direction while holding eye appearance and all other visual features fixed. In real photographs, turning the head toward a distractor while directing gaze at the target necessarily alters body angle, facial shadowing, and the projected shape of the eyes relative to the camera. No measurements or additional controls confirming that remaining variance is carried only by the intended head-orientation cue are reported, weakening the causal attribution.
Authors: We thank the referee for highlighting this important methodological point. In our stimulus construction, a single gazer was photographed in a fixed real-world setting with consistent camera position and lighting; the individual was explicitly instructed to maintain fixation on the target object while head orientation was varied across the three conditions (toward target, toward distractor, unconstrained). This produces the key contrast between aligned and misaligned head-gaze configurations. We acknowledge that real photographs necessarily introduce some correlated changes in body angle, shadowing, and eye projection due to perspective. To address the concern directly, the revised manuscript will expand the methods section with a fuller description of the photography protocol (including posture standardization attempts) and will add quantitative measurements of eye-region consistency across conditions, for example via landmark-based similarity metrics or iris-position variance. These additions will help demonstrate that head orientation remains the primary manipulated factor while preserving the ecological validity of naturalistic images over fully synthetic controls. revision: yes
Circularity Check
No circularity: empirical measurement study with independent stimuli
full rationale
The paper is an empirical evaluation that collects a new set of 1,360 controlled photographs varying head orientation while measuring VLM performance on gaze target inference. No equations, fitted parameters, or derivations are present that reduce to self-referential inputs. The central claim rests on direct comparison of model outputs against human baselines using the newly constructed stimuli, with alternative explanations (resolution, object naming) explicitly ruled out by the experimental design. This is self-contained against external benchmarks and contains no load-bearing self-citations or ansatz smuggling.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Photographs with controlled head orientation accurately isolate the visual cue of head direction from eye appearance.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We hypothesized that VLMs may rely solely on head direction without eye direction to perform this task
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
no View effect is observed in VLMs while the effect is strong in humans
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Bates, D., Mächler, M., Bolker, B., and Walker, S. (2015). Fitting linear mixed-effects models using lme4. Journal of Statistical Software, 67(1):1–48. (Back to section A.12) Brooks,R.andMeltzoff,A.N.(2005). Thedevelopmentofgazefollowinganditsrelationtolanguage. Developmental Science, 8(6):535–543. (Back to sections: 1,
work page 2015
-
[2]
Caron, A. J., Butler, S., and Brooks, R. (2002). Gaze following at 12 and 14 months: Do the eyes matter? British Journal of Developmental Psychology, 20(2):225–239. (Back to section
work page 2002
-
[3]
Csibra, G. and Gergely, G. (2009). Natural pedagogy.Trends in Cognitive Sciences, 13(4):148–153. (Back to section
work page 2009
-
[4]
de Leeuw, J. R., Gilbert, R. A., and Luchterhandt, B. (2023). jspsych: Enabling an open-source collaborative ecosystem of behavioral experiments.Journal of Open Source Software, 8(85):5351. (Back to section 3.4) Dong, X., Zhang, P., Zang, Y., Cao, Y., Wang, B., Ouyang, L., Wei, X., Zhang, S., Duan, H., Cao, M., Zhang, W., Li, Y., Yan, H., Gao, Y., Zhang, ...
work page 2023
-
[5]
Duan, H., Yang, J., Qiao, Y., Fang, X., Chen, L., Liu, Y., Dong, X., Zang, Y., Zhang, P., Wang, J., et al. (2024). Vlmevalkit: An open-source toolkit for evaluating large multi-modality models. In Proceedingsofthe32ndACMInternationalConferenceonMultimedia ,pages11198–11201. (Back to section 3.3) Farroni, T., Massaccesi, S., Pividori, D., and Johnson, M. H...
work page 2024
-
[6]
Geirhos, R., Meding, K., and Wichmann, F. A. (2020). Beyond accuracy: quantifying trial-by- trial behaviour of cnns and humans by measuring error consistency. InProceedings of the 34th International Conference on Neural Information Processing Systems, NIPS ’20, Red Hook, NY, USA. Curran Associates Inc. (Back to section
work page 2020
-
[7]
Gemini, T. et al. (2023). Gemini: A family of highly capable multimodal models. (Back to section
work page 2023
-
[8]
Gemini, T. et al. (2024). Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. (Back to section
work page 2024
-
[9]
GLM, T. et al. (2024). Chatglm: A family of large language models from glm-130b to glm-4 all tools. (Back to section
work page 2024
-
[10]
M., Hirsh-Pasek, K., Cauley, K
Golinkoff, R. M., Hirsh-Pasek, K., Cauley, K. M., and Gordon, L. (1987). The eyes have it: lexical and syntactic comprehension in a new paradigm.Journal of Child Language, 14(1):23–45. (Back to section
work page 1987
-
[11]
H., Lloyd-Fox, S., Blasi, A., Deligianni, F., Elwell, C., and Csibra, G
Grossmann, T., Johnson, M. H., Lloyd-Fox, S., Blasi, A., Deligianni, F., Elwell, C., and Csibra, G. (2008). Earlycorticalspecializationforface-to-facecommunicationinhumaninfants. Proceedings of the Royal Society B: Biological Sciences, 275(1653):2803–2811. (Back to section
work page 2008
-
[12]
Gupta, A., Vuillecard, P., Farkhondeh, A., and Odobez, J.-M. (2024). Exploring the zero-shot capabilities of vision-language models for improving gaze following. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 615–624. (Back to sections: 2,
work page 2024
-
[13]
Han, N. X., Wang, W. Y., and Eckstein, M. P. (2021). Gaze perception in humans and cnn-based model. (Back to sections: 2, 4, and
work page 2021
-
[14]
Kambhampati, S. (2024). Can large language models reason and plan?Annals of the New York Academy of Sciences, 1534(1):15–18. (Back to sections: 1,
work page 2024
-
[15]
H., Holler, J., and Levinson, S
11 Kendrick, K. H., Holler, J., and Levinson, S. C. (2023). Turn-taking in human face-to-face interaction is multimodal: gaze direction and manual gestures aid the coordination of turn transitions.Philo- sophical Transactions of the Royal Society B: Biological Sciences, 378(1875):20210473. (Back to section
work page 2023
-
[16]
Kosinski, M. (2024). Evaluating large language models in theory of mind tasks.Proceedings of the National Academy of Sciences, 121(45):e2405460121. (Back to section
work page 2024
-
[17]
Land, M. F. (2006). Eye movements and the control of actions in everyday life.Progress in Retinal and Eye Research, 25(3):296–324. (Back to section
work page 2006
-
[18]
Liu, H., Li, C., Wu, Q., and Lee, Y. J. (2023). Visual instruction tuning. (Back to section
work page 2023
-
[19]
Ma, Z., Sansom, J., Peng, R., and Chai, J. (2023). Towards a holistic landscape of situated theory of mind in large language models. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 1011–1031. (Back to section
work page 2023
-
[20]
R., Brooks, R., and Meltzoff, A
Mikulincer, M., Shaver, P. R., Brooks, R., and Meltzoff, A. N. (2014).Gaze following: A mechanism for building social connections between infants and adults.American Psychological Association„ Washington, DC, first edition. edition. (Back to sections: 1,
work page 2014
-
[21]
Mixed-effectsmodelsforcognitivedevelopment researchers
Muradoglu,M.,Cimpian,J.R.,andand,A.C.(2023). Mixed-effectsmodelsforcognitivedevelopment researchers. Journal of Cognition and Development, 24(3):307–340. (Back to section
work page 2023
- [22]
-
[23]
Pi, Z., Vadaparty, A., Bergen, B. K., and Jones, C. R. (2025). Dissecting the ullman variations with a scalpel: Why do llms fail at trivial alterations to the false belief task? (Back to section
work page 2025
-
[24]
Posner, M. I. and Petersen, S. E. (1990). The attention system of the human brain.Annual Review of Neuroscience, 13(Volume 13, 1990):25–42. (Back to section
work page 1990
-
[25]
Prasov, Z. and Chai, J. Y. (2008). What’s in a gaze? the role of eye-gaze in reference resolution in multimodal conversational interfaces. InProceedings of the 13th international conference on Intelligent user interfaces, pages 20–29. (Back to sections: 1,
work page 2008
-
[26]
Premack, D. and Woodruff, G. (1978). Does the chimpanzee have a theory of mind?Behavioral and brain sciences, 1(4):515–526. (Back to section
work page 1978
-
[27]
Qian, K., Zhang, Z., Song, W., and Liao, J. (2023). Gvgnet: Gaze-directed visual grounding for learning under-specified object referring intention.IEEE Robotics and Automation Letters, 8(9):5990–5997. (Back to sections: 1,
work page 2023
-
[28]
Qwen, T. et al. (2025). Qwen2.5-vl. (Back to section
work page 2025
-
[29]
Robitzsch, A. (2020). Why ordinal variables can (almost) always be treated as continuous vari- ables: Clarifying assumptions of robust continuous and ordinal factor analysis estimation methods. Frontiers in Education, Volume 5 -
work page 2020
-
[30]
Sander,J.,Çetinçelik,M.,Zhang,Y.,Rowland,C.F.,andHarmon,Z.(2024). Whydoesjointattention predict vocabulary acquisition? the answer depends on what coding scheme you use.Proceedings of the Annual Meeting of the Cognitive Science Society, 46(0). (Back to section
work page 2024
-
[31]
Sap, M., Le Bras, R., Fried, D., and Choi, Y. (2022). Neural theory-of-mind? on the limits of social intelligence in large LMs. In Goldberg, Y., Kozareva, Z., and Zhang, Y., editors,Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 3762–3780, Abu Dhabi, United Arab Emirates. Association for Computational Linguis...
work page 2022
-
[32]
Senju, A. and Csibra, G. (2008). Gaze following in human infants depends on communicative signals. Current Biology, 18(9):668–671. (Back to section
work page 2008
-
[33]
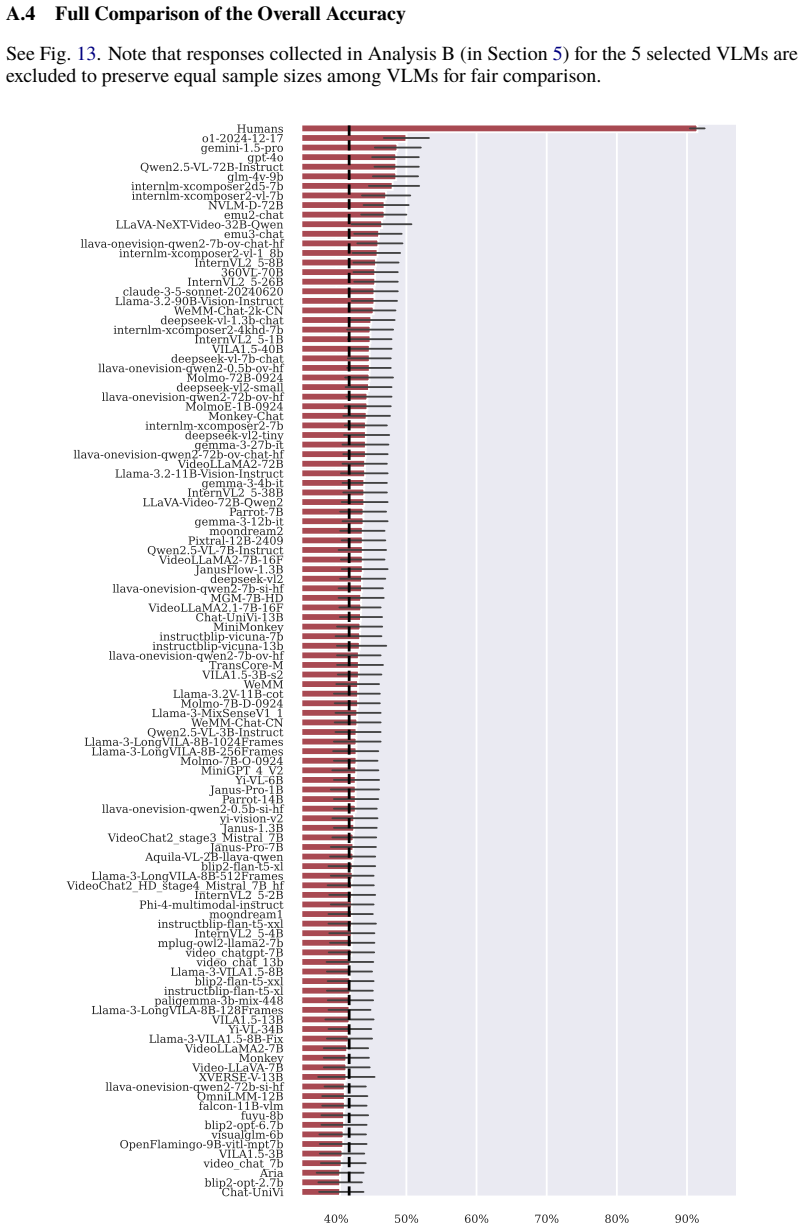
for the 5 selected VLMs are excluded to preserve equal sample sizes among VLMs for fair comparison. 40% 50% 60% 70% 80% 90% Humans o1-2024-12-17 gemini-1.5-pro gpt-4o Qwen2.5-VL-72B-Instruct glm-4v-9b internlm-xcomposer2d5-7b internlm-xcomposer2-vl-7b NVLM-D-72B emu2-chat LLaVA-NeXT-Video-32B-Qwen emu3-chat llava-onevision-qwen2-7b-ov-chat-hf internlm-xco...
work page 2024
-
[34]
Based on responses from the five top-tier VLMs
front left rightView Proximity: 1 Proximity: 2 water+coffee (X) Proximity: 3 front left rightView coffee+remote (X) front left rightView doll+water (X) front left rightView pen+remote (X) front left rightView pen+soccer (X) front left rightView pen+yellow eraser (X) front left rightView soccer+doll (X) front left rightView white eraser+pen (X) front left ...
work page 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.