WISCA: A Consensus-Based Approach to Harmonizing Interpretability in Tabular Datasets
Pith reviewed 2026-05-19 10:17 UTC · model grok-4.3
The pith
WISCA consensus aligns with the most reliable individual interpretability method on synthetic tabular data
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
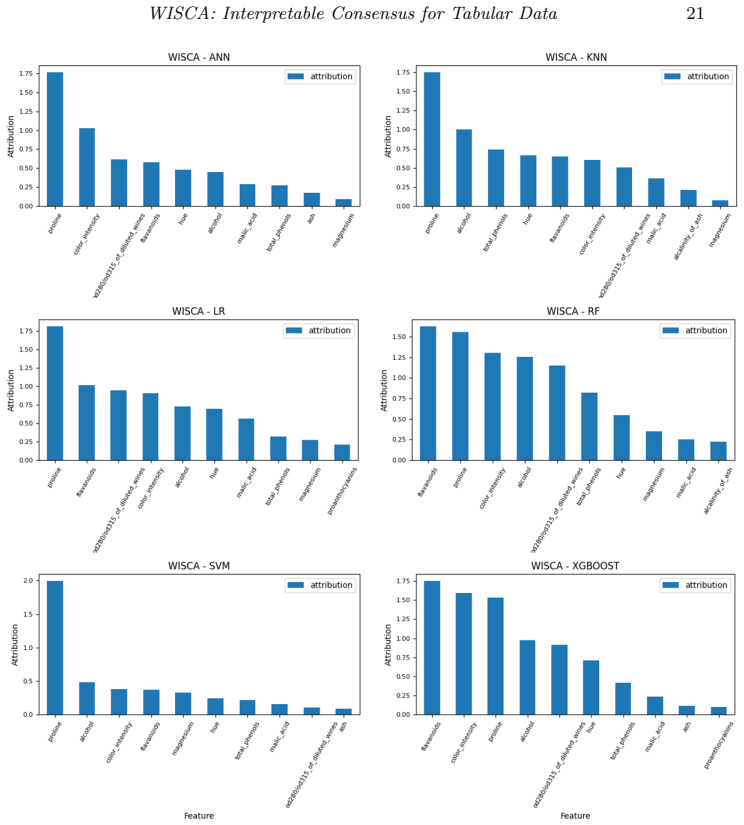
WISCA integrates class probability and normalized attributions to generate consensus explanations from various model-agnostic interpretability techniques. When applied to six ML models trained on six synthetic datasets with known ground truths, WISCA consistently aligned with the most reliable individual method, demonstrating the value of robust consensus strategies in improving explanation reliability.
What carries the argument
WISCA (Weighted Scaled Consensus Attributions), which weights and scales attributions using class probabilities to harmonize conflicting outputs from multiple interpretability algorithms.
Load-bearing premise
That alignment with the single most reliable individual method on synthetic data with known ground truth means the consensus explanations are higher quality in general.
What would settle it
Apply WISCA to a new synthetic dataset with known ground truth and observe whether it still aligns with the top individual method, or test it on real tabular data and measure agreement with downstream task performance or expert judgment.
Figures










read the original abstract
While predictive accuracy is often prioritized in machine learning (ML) models, interpretability remains essential in scientific and high-stakes domains. However, diverse interpretability algorithms frequently yield conflicting explanations, highlighting the need for consensus to harmonize results. In this study, six ML models were trained on six synthetic datasets with known ground truths, utilizing various model-agnostic interpretability techniques. Consensus explanations were generated using established methods and a novel approach: WISCA (Weighted Scaled Consensus Attributions), which integrates class probability and normalized attributions. WISCA consistently aligned with the most reliable individual method, underscoring the value of robust consensus strategies in improving explanation reliability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces WISCA (Weighted Scaled Consensus Attributions), a novel consensus method that combines class probabilities with normalized attributions from multiple model-agnostic interpretability techniques. The authors train six ML models on six synthetic tabular datasets with known ground-truth feature attributions, generate explanations via established methods and WISCA, and report that WISCA consistently aligns with whichever individual method recovers the ground truth most reliably.
Significance. A well-supported consensus procedure for tabular interpretability could help reconcile conflicting explanations in scientific and high-stakes settings. The use of synthetic data with explicit ground truth provides a controlled test bed, which is a methodological strength. However, the absence of quantitative metrics, statistical tests, or results on real data limits the immediate significance of the reported findings.
major comments (2)
- [Abstract] Abstract: the central empirical claim that WISCA 'consistently aligned with the most reliable individual method' is stated without any quantitative metrics, error bars, statistical tests, or description of how the 'most reliable' method was identified on the six synthetic datasets. This makes it impossible to assess the magnitude or reliability of the reported alignment.
- [Evaluation] Evaluation section: the argument that alignment with the single best individual explainer on these particular synthetics constitutes improved explanation quality rests on an untested premise; no stability, fidelity, or human-grounded metrics on non-synthetic tabular data are provided to test whether the consensus adds robustness beyond simply reproducing the best individual method.
minor comments (2)
- [Method] Clarify the precise formula for weighting and scaling in WISCA (e.g., how class probability is combined with normalized attributions) and whether any hyperparameters are involved.
- [Results] Add a table or figure summarizing the quantitative agreement scores (e.g., rank correlation or attribution error) between WISCA and each individual method across the six datasets.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below, indicating where we agree and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim that WISCA 'consistently aligned with the most reliable individual method' is stated without any quantitative metrics, error bars, statistical tests, or description of how the 'most reliable' method was identified on the six synthetic datasets. This makes it impossible to assess the magnitude or reliability of the reported alignment.
Authors: We agree that the abstract would benefit from greater specificity. The manuscript identifies the most reliable method by direct comparison of each explainer's feature attributions against the known ground-truth importances in the synthetic datasets. In the revision we will update the abstract to report key quantitative results (e.g., mean alignment percentage or rank correlation with the best individual method across the six datasets) and note that reliability was assessed via fidelity to ground truth. revision: yes
-
Referee: [Evaluation] Evaluation section: the argument that alignment with the single best individual explainer on these particular synthetics constitutes improved explanation quality rests on an untested premise; no stability, fidelity, or human-grounded metrics on non-synthetic tabular data are provided to test whether the consensus adds robustness beyond simply reproducing the best individual method.
Authors: The synthetic setting with explicit ground truth is used precisely to enable objective identification of the best individual method; WISCA is shown to match that method's output without access to the ground truth. This constitutes a controlled test of whether consensus can reliably recover high-fidelity explanations. We acknowledge that additional evidence on real data would be valuable and will expand the evaluation section to include stability metrics (consistency of attributions across repeated model trainings) while adding an explicit limitations paragraph on the absence of real-world tabular results. revision: partial
Circularity Check
No circularity: empirical alignment on synthetic ground-truth data
full rationale
The paper evaluates the proposed WISCA consensus method by training models on six synthetic datasets with known ground-truth feature attributions, applying multiple model-agnostic explainers, and measuring alignment of the consensus output with the single best individual explainer. This constitutes a direct empirical comparison against an external benchmark rather than any derivation, fitting step, or self-referential definition. No equations, self-citations, uniqueness theorems, or ansatzes are invoked that reduce the central claim to the paper's own inputs by construction. The evaluation is therefore self-contained and falsifiable via the provided synthetic ground truths.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Synthetic datasets with known ground truths accurately reflect the behavior of interpretability methods on real tabular data.
invented entities (1)
-
WISCA (Weighted Scaled Consensus Attributions)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
WISCA Formulation. WISCA ... ϕ(f) = ∑ ϕ′(f) / (N * π(s,m)) ... parabolic correction factor π(p) = 1−4p(1−p)
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat.equivNat unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
hit rate metric P = ∑ h(xi)/i / ∑ 1/i
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
six synthetic datasets ... known ground truths ... Expected Explanation column
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Aeberhard, S., Forina, M. (1992). Wine. UCI Machine Learning Repository. DOI: https://doi.org/10.24432/C5PC7J. Altmann, A., Toloşi, L., Sander, O., Lengauer, T. (2010). Permutation importance: a cor- rected feature importance measure.Bioinformatics, 26(10), 1340–1347.https://doi.org/ 10.1093/bioinformatics/btq134. Ayad, H.G., Kamel, M.S. (2007). Cumulativ...
-
[2]
Banegas-Luna, A.J., Pérez-Sánchez, H. (2022). SIBILA: High-performance computing and inter- pretable machine learning join efforts toward personalised medicine in a novel decision-making tool. arXiv. Bennetot, A., Donadello, I., El Qadi El Haouari, A., Dragoni, M., Frossard, T., Wagner, B., Sar- ranti, A., Tulli, S., Trocan, M., Chatila, R., Holzinger, A....
-
[3]
Linardatos, P., Papastefanopoulos, V., Kotsiantis, S. (2020). Explainable ai: A review of machine learning interpretability methods.Entropy, 23(1),
work page 2020
-
[4]
Lundberg, S.M., Lee, S.I. (2017). A unified approach to interpreting model predictions.Adv. Neur. In.,
work page 2017
-
[5]
Molnar, C. (2022). Interpretable Machine Learning: A Guide for Making Black Box Models Explainable (2nd ed.). https://christophm.github.io/interpretable-ml-book. Mothilal, R.K., Sharma, A., Tan, C. (2020). Explaining machine learning classifiers through diverse counterfactual explanations. In: Proceedings of the 2020 Conference on Fairness, Accountability...
-
[6]
Rainio, O., Teuho, J., Klén, R. (2024). Evaluation metrics and statistical tests for machine learning. Sci. Rep., 14(1),
work page 2024
-
[7]
Rajkomar, A., Dean, J., Kohane, I. (2019). Machine learning in medicine.New Engl. J. Med., 380(14), 1347–1358. Ribeiro, M.T., Singh, S., Guestrin, C. (2016). Why Should I Trust You?: Explaining the Predic- tions of Any Classifier. In:Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, New York, pp. 1135...
work page 2019
-
[8]
Rosenfeld, A. (2021). Better metrics for evaluating explainable artificial intelligence. In:Proceed- ings of the 20th International Conference on Autonomous Agents and Multiagent Systems. International Foundation for Autonomous Agents and Multiagent Systems, Richland, SC, pp. 45–50. Rudin, C., Chen, C., Chen, Z., Huang, H., Semenova, L., Zhong, C. (2022)....
-
[9]
Steyaert, S., Pizurica, M., Nagaraj, D., Khandelwal, P., Hernandez-Boussard, T., Gentles, A.J., Gevaert, O. (2023). Multimodal data fusion for cancer biomarker discovery with deep learning. Nat. Mach. Intell., 5(4), 351–362. Stirnberg, R., Cermak, J., Kotthaus, S., Haeffelin, M., Andersen, H., Fuchs, J., Kim, M., Petit, J.E., Favez, O. (2021). Meteorology...
work page 2023
-
[10]
revealed with explainable machine learning.Atmos Chem. Phys., 21(5), 3919–3948. Strumbelj, E., Kononenko, I. (2014). Explaining prediction models and individual predictions with feature contributions.Knowl. Inform. Syst., 41.3, 647–665. Sundararajan, M., Taly, A., Yan, Q. (2017). Axiomatic attribution for deep networks. In: Precup, D., Teh, Y.W. (Eds.),Pr...
work page 2014
-
[11]
Waljee, A.K., Higgins, P.D.R. (2010). Machine learning in medicine: a primer for physicians. Am. J. Gastroenterol., 105(6), 1224–1226. Yang, C.C. (2022). Explainable artificial intelligence for predictive modeling in healthcare.J. Healthc. Inform. Res., 6(2), 228–239. Zamani, M.G., Nikoo, M.R., Niknazar, F., Al-Rawas, G., Al-Wardy, M., Gandomi, A.H. (2023...
work page 2010
-
[12]
Zhou, J., Gandomi, A.H., Chen, F., Holzinger, A. (2021). Evaluating the quality of machine learning explanations: A survey on methods and metrics.Electronics, 10(5),
work page 2021
-
[13]
A.J. Banegas-Luna is an Associate Professor in Computer Science at Universi- dad Católica de Murcia (UCAM), Spain. He earned his Ph.D. in Computer Sci- ence from UCAM in 2019, specializing in the application of high-performance computing (HPC) to biological and chemical contexts. His research focuses on computer-aided drug discovery and the use of artific...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.